- 1深度网络 Fine-tuning方法简介_nllb-200 fine-tuing
- 2docker技术(五)--仓库以及镜像推送到仓库_docker 普通用户不能推送镜像了吗
- 3 关于MySQL的lock wait timeout exceeded解决方案
- 4【uniapp,样式,登录】【微信小程序】获取用户昵称和头像 新规则 写法,以及获取手机号登录_uni 小程序获取用户昵称
- 5HarmonyOS NEXT Beta 版开发者及先锋用户招募(第一期)报名答题题库(持续更新中,仅供学习分享使用)_harmonyos next beta 版报名答题-先锋用户
- 6mybatis
标签 - 7STM32F103单片机制作的智能小车_stm32f103智能小车设计总结
- 8Hive sql 常见面试题-会话划分问题_sql会话划分问题
- 9【Python机器学习】决策树算法对泰坦尼克号人员幸存预测_决策树泰坦尼克号生存预测python
- 10Flink数据统计UV、PV统计(三种写法)_pv统计方式
业界大盘点!文本相关性在搜广推三大场景中的应用!
赞
踩
卷友们好,我是rumor。
NLP最赚钱的落地莫属搜索、广告、推荐三大场景了,今天我们就向钱看,来了解下作为NLP算法工程师,怎样在互联网最主要的三个场景里发光发热,同时蹭得一份业绩。

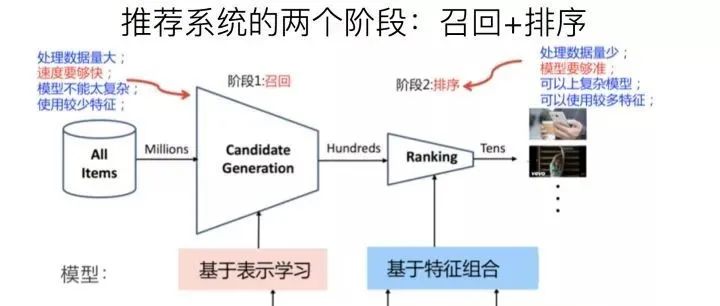
搜广推这三个场景的架构都差不多,主要就是通过对内容/商品的召回和排序,来优化Query-Doc的匹配结果。可以将这个过程分为三部分:
Doc的理解:现在的候选Doc/Item是各种模态的,比如视频、商品、图片、文本,但不管哪种形式,文本都是其中的重要一种,可以利用阅读理解、信息抽取、文本匹配打标签等技术加深对内容的理解
Query的理解:在搜索、广告中输入都是真实的Query,可以基于NLP进行意图、分词、NER等各种解析,而推荐中则是把User当作Query,这时可以把用户历史消费的内容作为用户兴趣,这件又回归到了Doc理解
Query-Doc相关性:通过用户行为、用户信息、时空信息、上述的Query和Doc理解等海量特征来找出符合用户需求的结果。搜索和广告是命题作文,其中文本层面的Query-Doc很重要,而推荐中内容信息则可以解决用户、物品冷启动问题,也起着不可或缺的作用
本文主要聚焦于Query-Doc文本相关性的应用调研,该相关性分数作为特征,对召回以及排序结果都有很大影响。(不是不想讲别的,光文本相关性我就刷了十几篇业界干货,肝要爆掉了,别的就下次一定吧hhh)


 另外,我们还建立了自然语言处理、推荐搜索、智能对话、知识图谱等方向的讨论组,欢迎大家加入讨论(人数达到上限,添加下方好友手动邀请),注意一定备注喔!
另外,我们还建立了自然语言处理、推荐搜索、智能对话、知识图谱等方向的讨论组,欢迎大家加入讨论(人数达到上限,添加下方好友手动邀请),注意一定备注喔!
业界方案大赏
之前写过一篇文本匹配的综述,但当真正涉及到应用时跟业务的阶段、流量、资源都有很大关系,简单的字面匹配其实就能满足不少需求。
蘑菇街
蘑菇街在最初的迭代时,通过频率、tfidf、BM25、布尔模型、空间向量模型、语言模型等统计方式抽取了文本的稠密特征,输入到树模型进行相关性打分就能得到不错的效果。同时他们也加入了Q-D的交互特征,也就是对Query、Doc进行同义词扩展后,计算重合ngram term占Query term和Doc term的比例。但字面匹配的可扩展性较差,需要好的同义词表提升泛化性能,因此下一个阶段就是引入词向量。蘑菇街在19年也尝试了用tfidf筛选出核心词,并对Query、Doc的核心词进行Self-Attention计算再融合,得到更好的文本相关性结果,将佣金收入提升了5.56%。
接下来到了深度学习时代,各厂门都开始不满足字面匹配的相关性,因为这个方案需要大量的人工特征工程以及同义词、停用词的挖掘,这时便出现了著名的DSSM模型。
小米移动搜索
小米采用的方案是在人工GBDT的方案基础上融合C-DSSM的结果,利用大规模用户行为数据进行训练,提升了长尾Query的查询效果。

阿里妈妈
阿里妈妈也采用了DSSM进行广告语义匹配,但他们在应用中发现pairwise loss会导致Q-D预测结果偏向正太分布:

这就导致阈值对召回结果有很大影响,不同天的Query召回集合变动很大,给广告效果带来了不确定性。因此他们改为拟合伯努利分布,使预测结果成哑铃的形状,降低阈值对截断的影响。同时为了弥补DSSM缺少交互的缺点,他们在中间加入了Q-D的attention交互计算,最终新的方案在各个指标上都超越了DSSM。

京东电商搜索
当然,文本相关性也可以不单独作为一个特征,而是直接融合到召回中。京东电商搜索则是分别给Query和商品建立了一个encoder,在输入Query文本、商品名称的同时融合其他特征进行计算,比如用户基础信息、历史行为、商品品牌、品类等:

值得注意的是,左侧的Query编码器采用了multi-head机制,用于捕获不同的语义,比如品牌属性、商品属性等,丰富Query的表示。
阿里飞猪
阿里飞猪和京东采取的融合方案相似,不同的是他们更关注Doc的理解,提前对商品的目的地和类目id进行了编码,作为Doc侧的输入:

当然,讲NLP肯定少不了BERT。
知乎搜索
作为重内容的社区,知乎在他们的搜索召回和排序中都有用到BERT,在召回中会分别对Query和Doc编码,通过向量检索的方式召回候选,同时在二轮精排也会用交互式的小BERT进行相关性计算:

数据才是天花板
上面介绍了字面匹配和语义匹配各阶段的模型,但在应用场景中,数据才是真正的天花板,模型只是在不断拟合上线而已。训练数据的构造在文本相关性任务中是十分重要的。
把用户点击的数据当作正例是无可后非的,但一个很常见的错误就是把召回结果中未点击的内容作为负例。腾讯全民K歌的分享中指出,在召回和排序这两个步骤中我们的视角是不一样的,召回阶段的视角是内容全集,同时未点击也不意味着就不是好结果,所以更好的做法是在全局范围内进行随机负采样,实践的效果也证明这样会更好。

但单纯的随机负例也有问题,就是可能会把相关商品变成负例,降低结果与Query的相关性。京东电商搜索采用的方案是按一定比例将随机负例与batch negatives相融合,因为batch内的doc都有对应的batch query作为正例,打散的话更大概率与当前正例不相关,之后再通过控制参数来平衡召回结果的多样性与相关性。

知乎搜索还提出了一种hard负例的挖掘方法,就是将query和doc映射到一个空间中,再对doc进行聚类,这样就可以找到与query相近的类别,从其中采样一些较难的负例。或者也可以参考阿里飞猪的做法,在一个类目或者目的地下随机选择负例,提升训练数据的难度。

当然有资源的话最好还是进行人工标注,而搜广推数据量那么大,都标注肯定是不可能的,需要更高效的问题样本发现机制。阿里文娱基于Q-Learning的思想,对于线上预测较差的样本,再用一层模型进行挖掘,把低置信度的样本、或者高置信度但和线上预测不一致的样本拿去给人工标注,这样就可以快速迭代出问题集并有针对性地优化:

线上怎么用呢
上文终于费劲吧啦地把模型训出来了,然而怎么用还是问题,之所以不是所有厂都用BERT,主要还是因为代价太大。虽然Doc的表示都可以离线预测好存起来,但Query来了真心受不了。
第一种解决方案就是把模型做小。
上文中介绍的知乎搜索直接把BERT用到了二轮精排中,因此他们的做法是基于Roberta-large进行蒸馏,采用Patient-KD方式,将12层蒸馏到了6层。同时他们也对BERT表示模型进行了维度压缩,在不影响线上效果的情况下,将768维压缩到了64维,减少了存储空间占用。

阿里文娱只用到基于表示的方案,因此他们蒸馏了一个非对称的双塔模型,并且在doc端采用multi-head方式来减少指标衰减。

第二种解决方案就是把数据尽可能存起来。
360搜索广告在训练阶段用了16层transformer,因此在应用到线上时选择了离线的方式,先从日志中挖出一部分Q-D对,进行相关性预测,再通过CTR预测进行过滤,把最终结果存储到线上KV系统。

不过这种方案只限于数据量可以承受的场景,也可以把两种方式进行融合,将一些高频Query提前存好,剩下的长尾Query用小模型预测。
我们的业务不一样
上述的介绍主要还是集中在搜索、广告场景下,因为推荐场景没有query,花样会更多一些,也会利用其他很多特征,基本上都是把文本作为一个维度来训练相关性模型。下面再介绍两个我在业界分享中看到的相关性改进方法,一起开开眼。
百度凤巢
对于搜索广告这种命题作文来说,召回阶段最重要的目标就是Q-D相关性,但这个优化目标其实跟最终的ctr是有gap的,尤其是在广告场景中,最终影响收益的指标和ctr有很强的关系。所以百度凤巢团队提出了MOBIUS系统,将ctr预估引入到搜索召回阶段:

最单纯的想法是直接在召回阶段以ctr为目标进行训练,但由于ctr目标本身的问题,很可能将相关性不高的广告预测为正例。MOBIUS提出了一个数据增强模块,先从日志里捞一批Q-D对,再用相关性模型进行打分,找出相关性低的pair作为badcase,让最终的模型预测。这样模型从二分类变成了三分类,就具备了过滤不相关case的能力,将相关性预测与ctr预测较好地融合在了一起。
陌陌
陌陌有个场景是根据用户发布的动态推荐相似的内容,这个动态不仅有文本,也有图像,我觉得可借鉴的点是他们利用用户提供的文本和图像内容训练了两个编码器,很好地把文本和图像映射到了一个空间内。
具体的做法是,利用用户发表的图文动态,训练一个双塔模型:
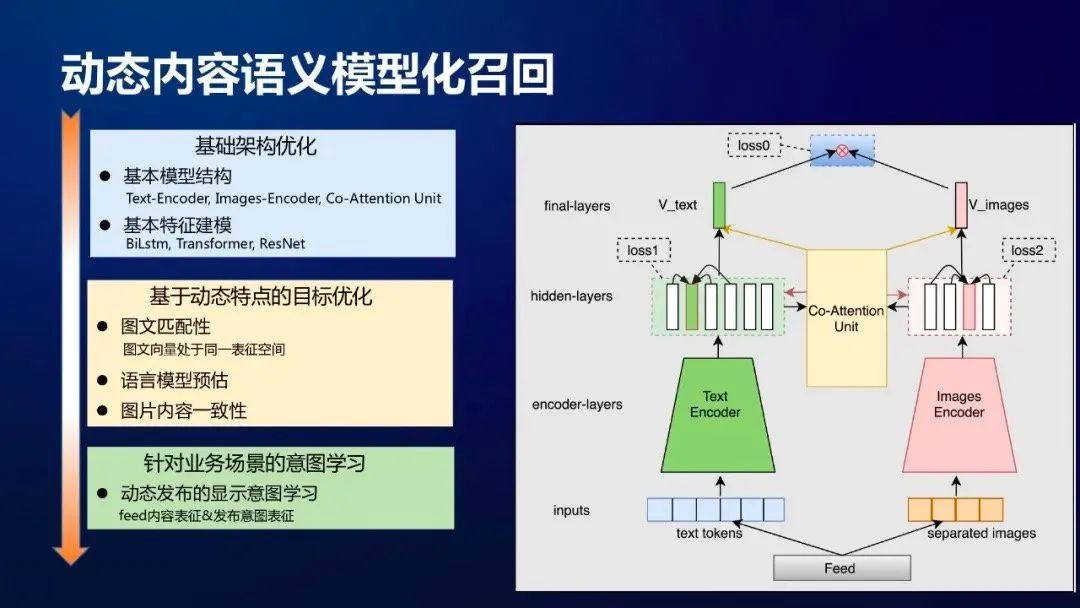
模型两个塔分别对文本和图像编码,有三个loss:
图文匹配
文本语言模型
图片内容一致性:有的动态包含多张图片,我们认为多张图片在表达一个意思
基于这个双塔模型的内容召回起到了很好的线上效果:

总结
在社会上混得越久,越觉得技术只是工具,自己在工作中总拿着模型找问题,却不思考问题本身对于业务的重要程度。今年也开始反思,在巩固好个人能力的同时转变思维,由技术驱动转为问题驱动,真正去深入到具体场景、解决重要的实际问题。
最近刷业界分享其实觉得蛮有意思的,可以发现在电商、本地生活、社交、内容领域都有不同的业务特点,也发现很多idea可以借鉴到自己的项目中。后续会继续学习NLP在实际场景的落地,参考文献中列了不少干货,祝大家学习愉快。

参考资料
文本相关性在蘑菇街搜索推荐排序系统中的应用
- END -



从 SimCLR 到 BarLow Twins ,一文了解自监督学习不断打脸的认知发展史