
热门标签
热门文章
- 1在Python中,创建字典_造字典 x=10,y=20 python
- 2【AI+搜索】不可错过的AI搜索工具:让信息触手可及!_search with ai
- 3爬山算法详解
- 4python读取字典类型的文本文件_python 类似于字典的文本怎么
- 5【AI大模型应用开发】从CoT到ToT,再到ReAct,提升大模型推理能力的方式探索(含代码)_大模型 思维图cot
- 6网络协议安全:SSL/TLS协议详解,SSL协议执行原理、报文格式解析,Wireshark抓包分析SSL协议_ssl报文格式
- 7激光雷达:感知算法进展 2022-2023
- 8hive索引_hive 索引类型
- 9EMNLP 2020 可解释性推理
- 10大数据、云计算、人工智能的融合应用分析_大数据与人工智能云计算的技术融合分析 麻进玲
当前位置: article > 正文
ChatTTS完美部署_chattts部署
作者:一键难忘520 | 2024-06-20 08:40:04
赞
踩
chattts部署
一、项目工程下载
2noise/ChatTTS: ChatTTS is a generative speech model for daily dialogue. (github.com)
直接git clone即可!(直接down包,解压)
二、模型下载
测试了两种,直接编写代码下载即可!最简单方便。
- #SDK模型下载
- from modelscope import snapshot_download
- model_dir = snapshot_download('pzc163/chatTTS')
不写绝对路径就会保存在这个位置
C:\Users\Administrator\.cache\modelscope\hub\pzc163下载完之后移动到自己的工程下,目录如下:
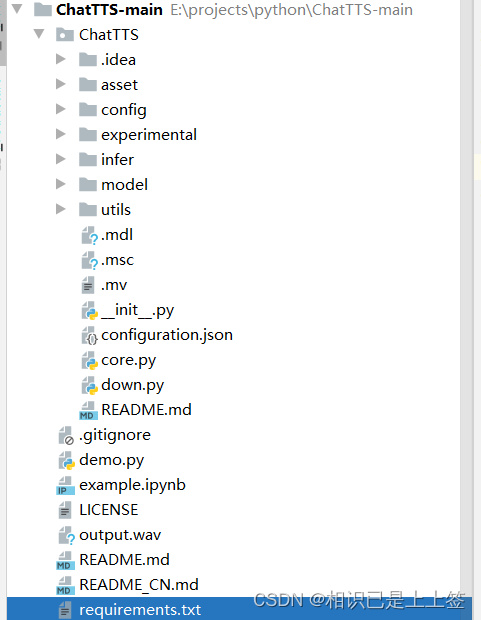
三、环境安装
需要安装下面的库
- omegaconf~=2.3.0
- torch~=2.1.0
- tqdm
- einops
- vector_quantize_pytorch
- transformers~=4.41.1
- vocos
如果是新的环境,就直接全部安装,如果本身有一些库就自行pip install就可以。
全部安装运行:
pip install -r requirements.txt四、运行Demo.py并保存结果
- import scipy
-
- import ChatTTS
- from IPython.display import Audio
-
- chat = ChatTTS.Chat()
- chat.load_models(source='local', local_path='ChatTTS')
-
- params_infer_code = {'prompt':'[speed_5]', 'temperature':.3}
- params_refine_text = {'prompt':'[oral_2][laugh_0][break_6]'}
-
- texts = ["四川美食可多了,[uv_break] 有麻辣火锅、宫保鸡丁、麻婆豆腐、[uv_break] 担担面、回锅肉、夫妻肺片等, [uv_break] 每样都让人垂涎三尺。"]
-
- wav = chat.infer(texts, \
- params_refine_text=params_refine_text, params_infer_code=params_infer_code)
-
- #texts = ["This is a test of the ChatTTS script. Peter Piper picked a peck of pickled peppers. Red leather. Yellow leather. Red leather. Yellow leather. Red leather. Yellow leather.",]
-
- # wavs = chat.infer(texts, use_decoder=True)
- Audio(wav[0], rate=24_000, autoplay=True)
- scipy.io.wavfile.write(filename = "output.wav", rate = 24_000, data = wav[0].T)

五、报错情况
windows会报错,需要改ChatTTS/core.py,第75行。
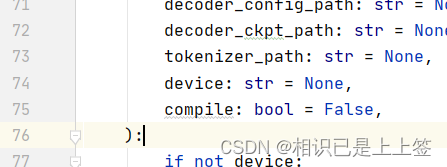
compile: bool = False,结语:以上内容仅供学习使用!!!
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/一键难忘520/article/detail/739231
推荐阅读
- 动态设置列的显示和隐藏html部分
[详细] -->赞
踩
相关标签

