
- 1赛灵思 Xilinx PG213 - UltraScale+ 器件 Integrated Block for PCI Express v1.3 产品指南(中文版) (v1.3)
- 2数字集成电路仿真实验与设计——基于FPGA的DDS信号源设计_dds信号源设计课程设计
- 3GIT 是干啥的_git是干什么的
- 4CDH Disk Balancer 磁盘数据均衡_cdh disk.balancer
- 5大数据_Hbase-API访问_Java操作Hbase_MR-数据迁移-代码测试---Hbase工作笔记0017_hbase 通过mr 迁移
- 6数据库选型以及表设计的基本原则_数据库选型依据
- 7如何理解python中面向对象的函数式编程_如何理解函数式编程?
- 89.8k star!一款小而美的开源物联网操作系统:RT-Thread_rt-thread操作系统
- 9安全等保评测-什么是“等保“?_等保测评
- 10『Python』题集⒋_python 字符串切片 题目 csdn
激光雷达:感知算法进展 2022-2023
赞
踩
https://zhuanlan.zhihu.com/p/658139560
作者:知乎@巫婆塔里的工程师
编辑:3D视觉工坊
1 前言
专栏之前介绍了激光雷达感知的两个常见任务:目标检测和点云语义分割,以及2021年之前相关的感知算法。同时,这几篇文章也对激光雷达感知的一些基础概念进行了介绍。
[1]激光雷达:3D物体检测算法
[2]激光雷达:基于RangeView的3D物体检测算法
[3]激光雷达:点云语义分割算法
以上几篇文章,在「3D视觉从入门到精通」知识星球内,也有做相应分享。
近两年来,随着激光雷达成本的逐渐降低,越来越多的量产车辆上已经部署了一个甚至多个激光雷达。量产应用对激光雷达感知算法提出了更高的要求:一方面需要提高在各种复杂场景下的感知精度,另一方面也要降低计算量并可以同时处理多个感知任务。
本文重点对2022年以来的激光雷达感知算法进行总结,分别从特征提取,时序融合,注意力机制,多任务网络以及离线处理这5个方面对研究进展进行分类介绍。此外,为了进行定量分析,本文也会介绍目前两个常用的激光雷达数据库:nuScenes和Waymo Open Dataset。
2 基准测试
在激光雷达研究的早期阶段,最常用的数据库是KITTI。这个数据库规模较小,数据的采集也不具备多样性,早期的时候主要用于学术界的研究工作。2020年以来,为了更好的评测面向量产的感知系统,工业界构建了两个更大规模的数据库:NuScenes和Waymo Open Dataset,其数据量比KITTI高出两个量级。
2.1 nuScenes
nuScenes的数据是在新加坡和波士顿两个城市的真实交通环境下采集的,覆盖面积大约5平方公里,包含1000个序列,每个序列长度为20秒。采集的数据类型包括可见光图像,激光雷达点云,毫米波雷达点云和地图。
nuScenes数据库采用1个激光雷达采集360°视野的数据,每帧大约34K个点。数据总量大约400K帧(帧率为20Hz),其中40K帧有标注信息(也就是每0.5秒标注一个关键帧)。标注的3D物体总量大约为1.4M,包含23个类别。
nuScenes中3D目标检测任务的性能指标主要有两个:mAP和NDS。
mAP(mean Average Precision)是目标检测中常用的性能指标,它对Precision-Recall(P-R)曲线进行采样,计算每个类别出平均的Precision。在计算P-R曲线时,需要匹配算法预测的物体框和标注的真值物体框。nuScenes中采用BEV视图下物体框的2D中心点距离来进行匹配,而不是传统的Intersection-of-Union(IoU),这样可以提高小物体的匹配率。
NDS(nuScenes Detection Score)在mAP的基础上,增加了物体框预测质量的指标。这些指标包括物体框的位置,大小,朝向,速度以及其它属性。与mAP相比,NDS可以更全面的评价3D目标检测算法的优劣。
2.2 Waymo Open Dataset (WOD)
WOD的数据是在美国的多个城市道路场景下采集的,覆盖面积大约76平方公里,包含1150个序列,每个序列长度为20秒。采集的数据类型包括可见光图像和激光雷达点云。
这里推荐关注:国内三个3D视觉方向公众号:3D视觉工坊、计算机视觉工坊、3DCV
WOD数据库采用1个中距和4个近距激光雷达,每帧大约177K个点。数据总量大约230K帧(帧率为10Hz),全部包含标注数据。标注的3D物体总量大约为12M,包含4个类别。
WOD中目标检测有3D和BEV两个任务,其中3D任务输出3D物体框, 而BEV任务输出俯视平面上带有方向的2D物体框。两个任务都采用AP(Average Precision)和APH(AP with Heading)两个指标,其中APH在AP的基础上额外考虑的目标框朝向的预测精度。同时,AP和APH会在两个不同的难度LEVEL_1和LEVEL_2下进行计算,难度是由标注者和物体统计值来决定。与nuScenes相比,WOD的评测指标没有考虑除了朝向以外的其它属性。
3 特征提取
对于激光雷达感知任务来说,从非结构化的点云数据中提取目标物体的三维特征是关键的步骤之一。点云特征提取可以在“Point”或者“Voxel”上进行。前者直接处理原始点云数据,代表的方式是PointNet和PointNet++。后者将点云转换成3D网格后再进行处理,代表性的方式是VoxelNet。
3D网格是结构化数据,因此更加适合卷积神经网络和并行处理。由于点云的稀疏性,网格的大部分区域都是空的,尤其是远距离的区域。基于Voxel的方法通常都会采用稀疏卷积来进行特征提取,从而避免浪费计算资源去处理空的网格。因此,如何设计有效的稀疏卷积是激光雷达感知的一个重要研究方向。
即使采用了稀疏卷积,3D网格处理仍然是非常费时的。因此,很多方法在3D稀疏卷积之后,会将3D网格压缩到BEV视图,也就是压缩了高度信息,变成了2D网格。这样也有便于利用现有的head结构,去完成各种下游任务。
Focal Sparse Conv [1]
如下图所示,稀疏卷积有两种基本形式:Regular和Submanifold。前者就是一般的卷积操作,因此卷积后的结果会变得稠密。后者则只是在输入有值的位置才有输出,因此可以保证卷积结果的稀疏性。Regular稀疏卷积的问题在于破坏了特征的稀疏性,导致后续操作的计算量增大,而且特征会变得模糊,不利于保留有用信息。Submanifold卷积保证了稀疏性,但是却限制了点和点之间的信息流动,也就是限制了特征提取的感受野。由于两种稀疏卷积各有优缺点,基于Voxel的主干网络中一般会同时采用这两种操作。
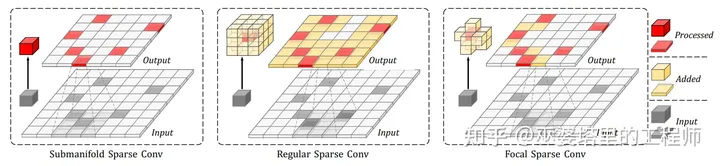
上述两种稀疏卷积对于输出点的定义是固定的,Focal稀疏卷积则动态的定义了输出点的位置。具体来说,Focal稀疏卷积增加了一个分支在每个3x3x3的卷积区域预测“重要”的位置,只有在这些位置上才会有输出。因此,输出点的定义是动态的,是由输入数据决定的。
在主干网络的设计中,每个阶段都包含以上3种不同的稀疏卷积,而Focal稀疏卷积被用在每个阶段的最后一层上。
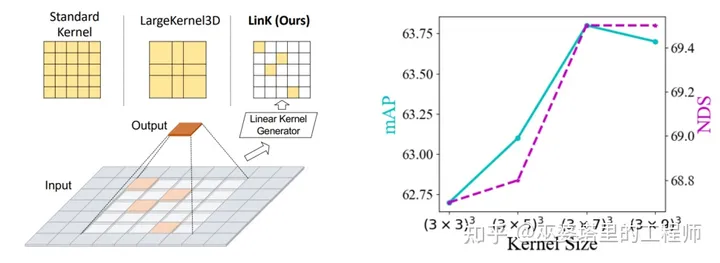
LargeKernel3D [2]
与2D卷积一样,感受野的大小对于3D卷积来说也是非常重要。对于卷积操作来说,扩大感受野最直接的方式就是采用较大的卷积核,比如7x7。但是,2D卷积的计算量与卷积核的大小成平方关系,因此很多方法中采用depthwise卷积来降低计算量。对于3D卷积来说,计算量更与卷积核大小成立方关系,而且depthwise这种操作也并不适合稀疏卷积操作。因此,如何降低3D大卷积核的计算量,就成了一个很有意义的研究课题。此外,3D大卷积核的参数也更多,而点云数据库的规模通常又比图像数据库小,所以如何利用有限的数据来学习这些卷积核参数也是需要解决的问题。
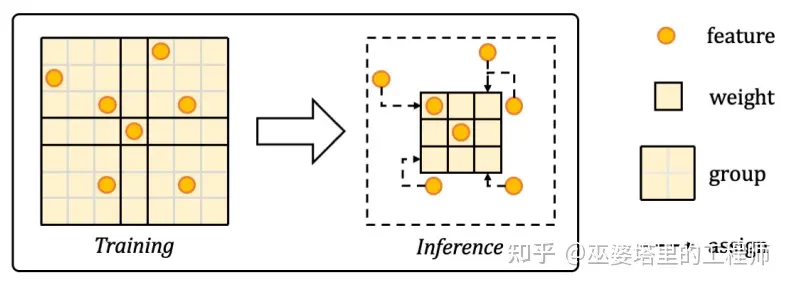
在LargeKernel3D这个工作中,作者提出将卷积区域划分为不同的group,每个group内共享卷积权重。比如在下图中, 7x7的卷积区域被划分成了3x3共计9个group,每个group内的卷积权重是共享的。在推理阶段,我们可以用3x3的卷积来完成这个操作,只不过采样的特征位置覆盖了更大的区域(7x7)。
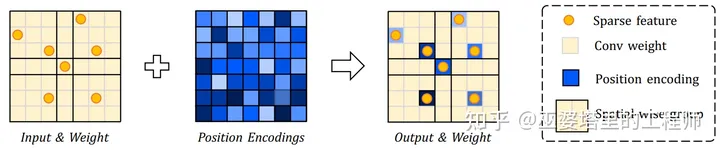
由于每个group的特征是共享的,卷积后会对局部区域的特征产生模糊的效果,也就是说group内的空间信息丢失了。为了解决这个问题,作者进一步提出了采用位置编码来保留空间信息。如下图所示,2D空间编码与输入特征相加以后,再进行上述基于空间划分的卷积操作。
LinK [3]
该工作也是为了解决如何在Voxel上应用大卷积核的问题,但是考虑了更大的卷积核尺寸,比如21x21。与LargeKernel3D中的做法不同,LinK并没有采用固定的空间划分,而是根据输入数据来动态的生成稀疏的卷积核,同时也利用重叠区域来减小计算量。推导过程公式较多,需要详细了解的话请参考原文。
MDRNet [4]
从3D网格转换到2D的BEV网格,可以采用Pooling或者卷积操作,但无论哪种方式都是静态的,也就是说对网格所有位置的操作都是一样的。这种静态的方式会导致丢失复杂的3D几何特征。MDRNet中提出了一种动态的方式(如下图d所示),通过稀疏卷积处理以后的3D网格数据来预测每个2D网格上的一个高度分布,也可以认为是动态的加权求和权重(w)。
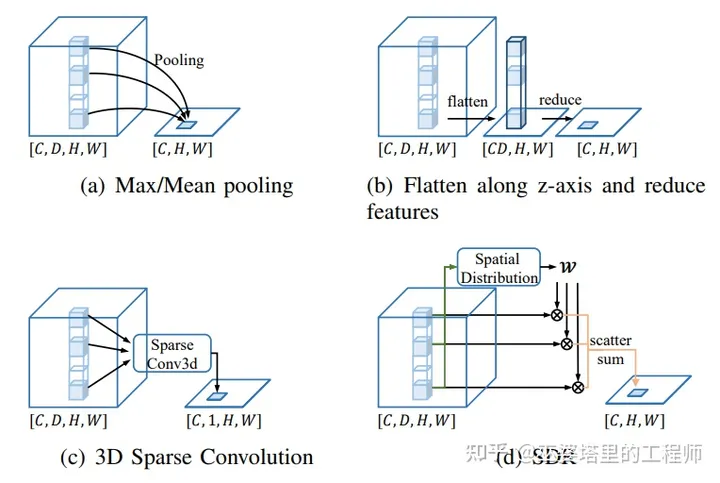
MDRNet是在多个分辨率上进行高度压缩的。每个尺度的3D网格都可以按照上面介绍的动态加权求和方式来得到相应的BEV网格。多个尺度的BEV网格融合以后再送给后续的head模块。

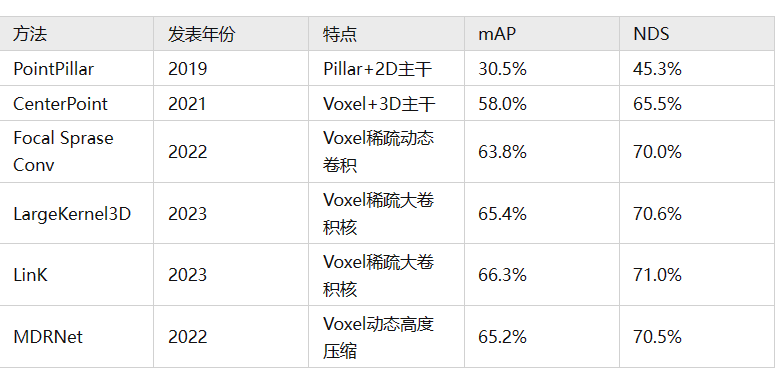
下表基于nuScenes数据集的3D目标检测任务,对比了以上介绍的特征提取方法,以及两个基准方法PointPillar和CenterPoint。
4 时序融合
自动驾驶系统输入的是时间上连续的数据,比如连续的图像帧或者点云帧。之前介绍视觉BEV的文章中已经提到,时序融合可以在很大程度上提升感知系统的准确率。在激光雷达感知的研究中,早期的工作主要利用单帧信息,将注意力放在点云特征提取上。但是,从近期的一些工作来看,点云的时序融合也逐渐成为了研究的热点。
DynStatF [5]
融合多帧点云最直接的办法就是把多帧的点合并到一起,当然这里我们需要根据自车运动将前几帧点云变换到当前帧的坐标系下。通过这种方式,对于静态目标来说理论上我们可以对齐多帧的点云。但是,由于点云测量的不确定性以及自车运动估计的误差,多帧的点云很难精确对齐。此外,运动目标也会导致多帧点云出现模糊(拖尾)的现象。
为了解决上述问题,DynStatF提出同时采用多帧和单帧(当前帧)点云。其中,当前帧点云负责提供精确(没有模糊)的位置信息,而多帧点云负责提供时序信息。单帧和多帧的结合通过局部交叉注意力的方式来完成,参见下图中的NCA模块。具体来说,单帧特征作为query,而多帧特征作为key和value。这里所说的特征是指经过处理后的BEV网格特征,因此DynStatF是一种基于网格的时序融合方法。NCA的输出兼具了单帧的位置精度和多帧的时序信息,并且后面会再跟原始的多帧特征做一个拼接,作为最终的特征。
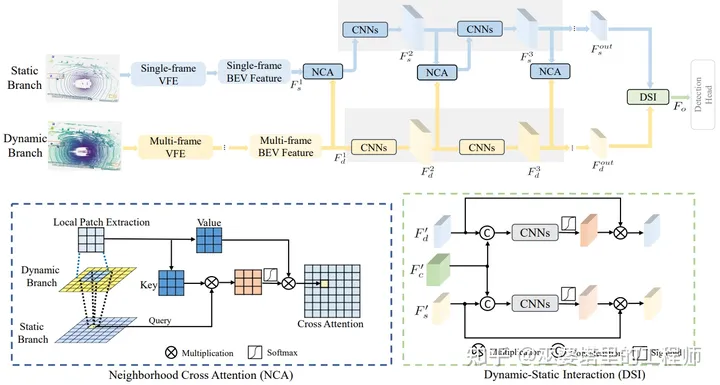
通过增加上述时序融合模块,两个基准方法PointPillar和CenterPoint的NDS指标可以分别提高3.9%和2.2%。
MGTANet [6]
该方法提出在短时(0.5秒)和长时(1.5秒)两个时间尺度上进行融合。短时融合在Voxel上进行,多帧点云根据自车运动对齐合并之后,被分配到Voxel的网格中。之后,在每个网格中计算当前帧点和历史帧点特征上的差异,以此来描述该网格的运动特征。包含短时运动信息的Voxel特征被压缩为BEV特征之后,再进行长时融合。长时融合首先也要根据自车运动将静态物体对齐,然后通过可变形卷积来对齐运动目标。最后,多帧点云再通过一个复杂的交叉注意力模块来进行合并,最终输出一个融合后的BEV特征图送给下游任务。
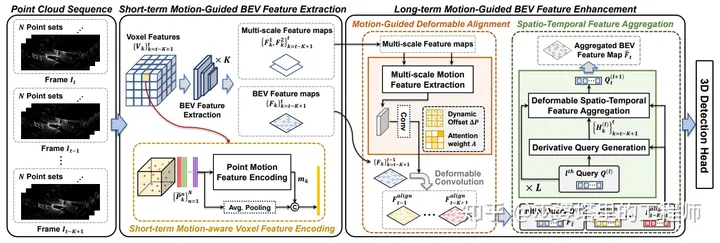
通过增加上述时序融合模块,CenterPoint的NDS指标可以提高3.9%。
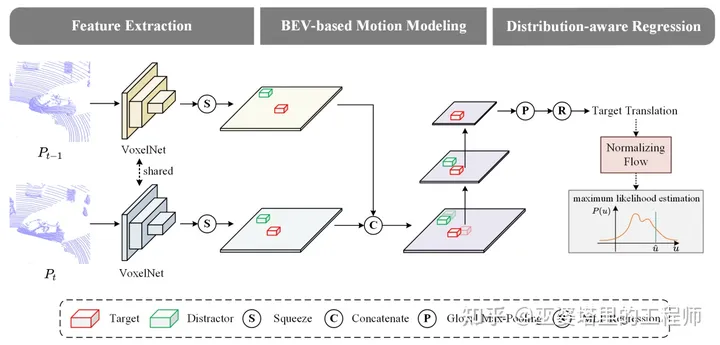
BEVTrack [7]
该方法要解决的问题是基于点云的单目标跟踪,其核心是通过相邻帧的点云数据来预测目标的运动。这里我们忽略跟踪的部分,只看一下多帧融合的部分。
BEVTrack中的多帧融合其实非常简单,就是把前后两帧的数据做一个拼接,然后利用不同stride的卷积操作来提取时空信息。这种操作非常直接,因此可以看作时序融合的一个baseline的方法。
5 注意力机制
注意力机制和Transformer近几年发展迅速,在语言大模型上已经取得了非常大的成功,比如chatGPT。同时,类似的方法也被用于视觉任务,比如物体检测,同样也获得了很好的效果,大有取代CNN之势。
专栏之前推出了一系列文章介绍注意力机制及其在自动驾驶视觉感知中的应用。
环境感知中的注意力机制(一)
环境感知中的注意力机制(二)
环境感知中的注意力机制(三)
视觉传感器:BEV感知综述
与视觉感知相比,Transformer在激光雷达感知中的应用相对较晚。与图像不同,点云是一种非结构化的数据。一般来说,点云数据可以表示为点视图和网格视图。
如果采用点视图,也就是说直接处理原始的点,我们可以把点云中的每一个点看作一个Token,那么自注意力机制可以非常顺利的应用到点云数据之上。这时点云中所有点互相之间都会有影响,也就是说提取的是全局注意力。这样做虽然可以获得最大的感受野,但是当点云规模较大时计算量也会急剧上升,这与视觉领域面临的问题是一样的。因此,有的研究者提出采用局部的注意力,用类似PointNet++中的方法将点云进行层级化的聚类,注意力的计算只局限在每一层的局部聚类中。这样做可以有效的降低计算量,同时层级化聚类也可以保证局部和全局信息都会被提取。这与前面介绍的Swin-Transfomer有异曲同工之处。
如果采用网格视图,也就是说预先把点云转成网格的形式,那么这就与图像格式非常类似了,视觉领域中的自注意力方法理论上说都可以直接拿过来用。当然,这里的网格数据是比较稀疏的,为了提高计算效率,网格处理中常用的稀疏卷积也可以被应用到自注意力的计算中来。
下面来介绍Transformer在激光雷达感知中的几个典型应用。
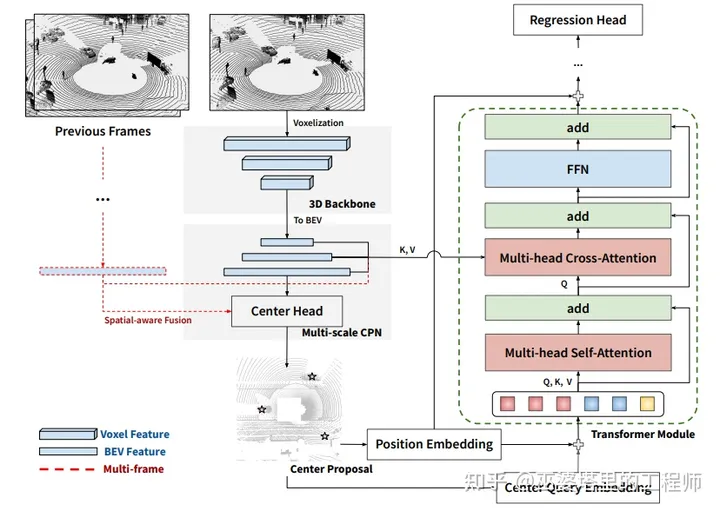
CenterFormer [8]
该方法基于网格视图,首先将点云量化到Voxel,然后进行多尺度的3D特征提取,最后特征被压缩到BEV视图。这中特征提取的方式与CenterPoint基本一致。虽然没有采用Transformer的encoder,该方法的特征提取中包含了基于CBAM的通道和空间注意力模块。
目标检测模块采用了类似DETR的稀疏query,同时也采用了与DETR4D中类似的目标query初始化策略。也就是在BEV特征上通过一个CenterHead来提供目标的初始位置,这些位置处的BEV特征则作为query。这些query再通过交叉注意力来从多尺度的BEV特征提取信息。为了降低计算量,这里并没有采用全局注意力,而是采用了两种局部注意力方式。一种是固定3x3的邻域,另一种是可变形注意力。这里的交叉注意力也可以作用在历史帧的BEV特征上(与当前帧坐标对齐),以此增加时序信息。
此外,CenterFormer还增加了基于IoU的损失,并采用Fade Augmentation。CenterFormer在WOD上的mAPH L2指标可以达到75.6%,比CenterPoint的71.9%有了显著的提升。
SphereFormer [9]
由于激光雷达扫描线的发散性,其点云也具有近处稠密,远处稀疏的分布特点。普通的卷积操作具有固定的感受野大小,因此很难提取远距离点的邻域信息,即使是累积多层卷积也很难获得较大的感受野。对于这个问题,一方面可以采用金字塔结构在低分辨率上提取特征,另一方面也可以采用前面介绍的大卷积核来扩大感受野。不过,这两种方法本质上说还是局部的感受野,无法从根本上解决问题。
专栏之前的一篇文章介绍了RangeView的点云表示方法,其主要思想是按照激光射线的水平和垂直排布,划分不同的网格,将点云量化到这些2D网格中去,形成一幅伪图像。在这个RangeView图像上,目标会呈现远小近大的现象,这与普通的相机图像是一样的。这样一来,普通的局部卷积操作也可以覆盖远处的物体。但是,这种方法还是没有解决近处和远处特征分布不一致的问题。
SphereFormer提出采用类似RangeView的网格/窗口划分方式,并在一个窗口内对所有的点进行自注意力操作。这样每个点都可以获得大范围的邻域上下文信息。这里的自注意力计算也考虑到了点与点的相对距离。
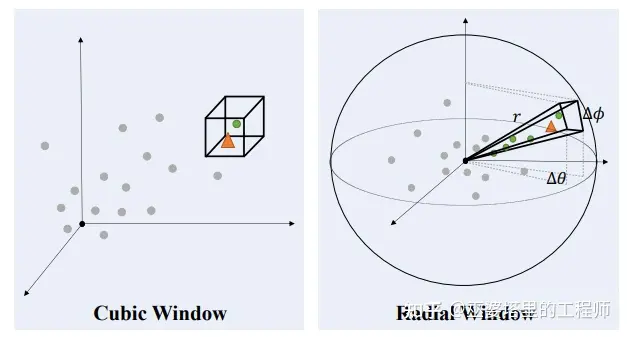
Radial窗口划分方式主要是为了提取远距离目标的大范围邻域信息。但是对于近距离目标来说,其局部邻域的信息就可以用来判断它的类别,较大的感受野有时反而会带来副作用。因此,SphereFormer提出同时采用Radial和Cubic两种窗口划分方式来处理,得到的特征进行拼接,由网络动态的选择采用哪种方式。
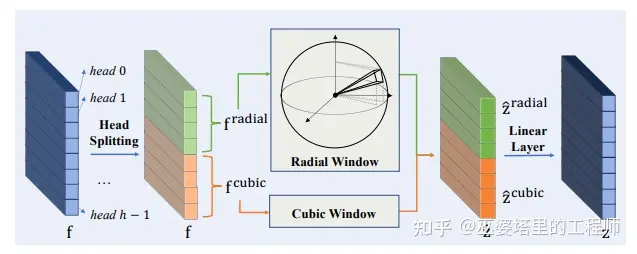
作为一种点特征的增强方式,SphereFormer可以很容易的嵌入到不同的网络框架中,完成不同的感知任务。SphereFormer在nuScenes的语义分割任务上取了的SOTA的效果(mIoU=81.9%),尤其是在远距离区域的提升非常明显。同时,在物体检测任务上,SphereFormer的NDS可以达到68.5%。
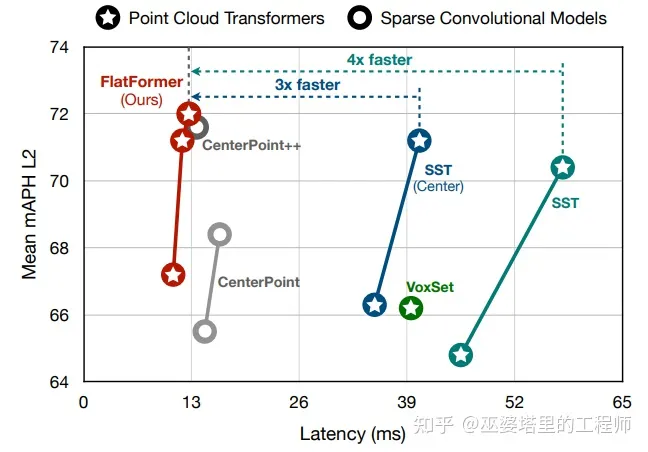
FlatFormer [10]
Transformer可以在激光雷达感知中的多个模块中应用:提取点特征(比如SphereFormer),BEV特征提取(比如SST[11]),目标检测(比如CenterFormer)等。在点特征或者BEV特征提取部分,采用Transformer结构是具有一定难度的。
如果采用点结构,全局的注意力只能用在小规模点云上(比如小于1k个点),局部注意力虽然可以降低计算量,但是寻找邻域的操作以及将点云转换成邻域结构,都是非常费时的。单单是特征提取部分就已经超过了CenterPoint这类基于3D稀疏卷积方法的总体耗时。
如果采用BEV网格结构,可以利用类似Swin-Transformer中的窗口机制来降低计算量。但是BEV网格依然是很稀疏的,每个窗口中的有效的网格数量差别很大,因此需要进行padding操作来对齐。此外,窗口的划分操作也会耗费计算时间。仅仅是这些数据准备的操作也已经超过了CenterPoint的总体耗时。
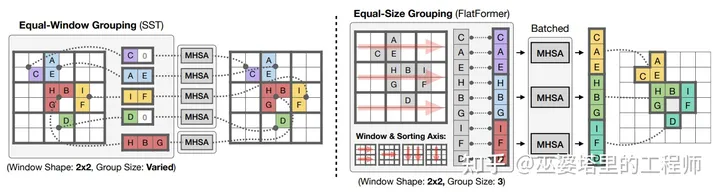
FlatFormer采用BEV网格结构和窗口注意力,但是窗口采用了特殊的设计来提高计算效率。具体来说,BEV网格按照行优先或者列优先的顺序进行Flatten操作(也就是FlatFormer名字的由来)。在生成的网格序列上划分多个长度一致的1维窗口,并在窗口计算标准的多头注意力。这种窗口划分只需要一个reshape的操作,并不改变数据在内存中的分布,因此是非常有效的。
为了保证信息在窗口之间的流动,FlatFormer给网格增加偏移量,这样就可以让同一个网格被划分到不同的窗口中去。此外,基于行优先和列优先的划分交替进行,也可以保证信息的流动。这种基于Flatten的划分方式,虽然效率很高,但是有时会破坏窗口的局部性,也就是说可能有距离很远的网格被划分到一个窗口中。不过,窗口注意力操作可以一定程度上减小这个问题带来的影响。
6 多任务网络
专栏之前的文章分别介绍了基于激光雷达点云的物体检测和语义分割。在车端的感知系统中,由于算力和内存的限制,每个任务单独运行一个网络是不现实的。同时,从之前的介绍中我们也可以看到,不同任务的网络结构是有相似之处的,比如点特征提取,点云网格化,主干网络,时序融合等。因此,多个任务可以通过共享一些网络模块,在同一个网络中实现,从而降低整体的资源消耗。
多任务网络设计的关键点在于保证多个任务不会“互相掣肘”,而要让他们尽量“互相促进”。这就要求共享和独享模块之间的平衡,同时也要平衡多个任务的损失函数权重。
LidarMTL [12]
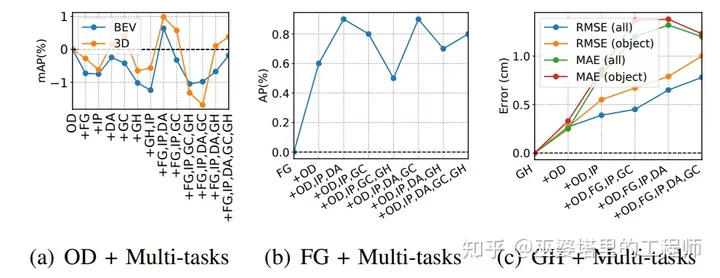
该方法同时处理6个任务:object detection (OD), foreground point classification (FG), intra-object part location regression (IP), object-free drivable area classification (DA), ground area classification (GC), ground height estimation (GH). 其中,OD是目标检测任务(其中包括分类和物体框回归),FG/DA/GC是点云分类任务,IP/GH是点云回归任务。
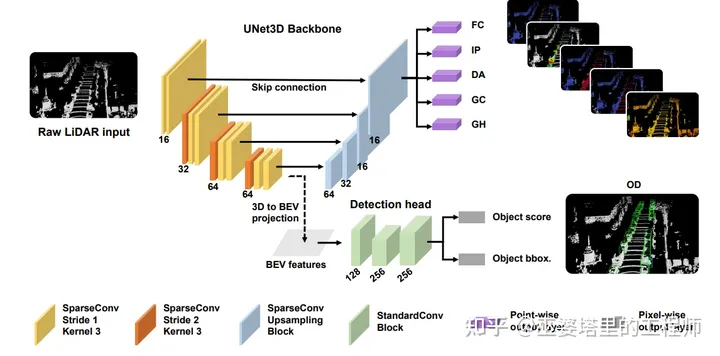
在网络结构方面,多个任务共享一个3D多分辨率主干网络。之后,OD分支采用低分辨率的3D网格特征,并将其压缩到BEV,而点云分类和回归任务则在3D主干上采用FPN结构,在原始分辨率的3D特征上进行下一步计算。
在多任务损失函数加权方面,作者尝试了多种方法,包括固定权重,网格搜索,基于任务不确定性的权重[13]。不过,实验得出的结论是,虽然计算量很大,但是只有网格搜索会小幅度的提升各个任务的准确率,而基于不确定的方法几乎不起作用。
下图是多任务和单任务准确率的对比。我们可以看到,在多任务网络中,单个任务的准确率有时会受到一些影响,但是幅度很小。考虑到多任务网络带来的大幅资源消耗降低,准确率的轻微下降是可以接受的。
LidarMultiNet [14]
该方法分为两个阶段,第一阶段把3D物体检测和点云语义分割融合到一个网络结构里,在此基础上第二阶段完成了全景分割分割任务。多任务学习的部分主要在于第一阶段,所以这里我们忽略掉全景分割的部分。
与LidarMTL类似,3D物体检测和点云语义分割共享了基于Voxel的3D主干网络。为了保证计算效率,这个3D主干网络只采用了第3节中介绍的Submanifold稀疏卷积。但是这种稀疏卷积无法提取领域点的信息,也就是说感受野受到限制。因此,在主干网络的最底层(最低分辨率),Voxel特征被压缩到BEV,并进行多分辨率的卷积操作,以提取领域信息,扩大感受野。BEV特征之后在映射回稀疏的Voxel,并与主干网络的Voxel特征进行融合。
物体检测分支只在BEV特征上进行,而点云分割分支则在Voxel特征上进行,但其实也利用BEV的特征。物体检测分支的GT是物体框,同时也用BEV分割作为附加任务来辅助学习。BEV分割和点云分割都是用基于Voxel的GT来进行监督学习。多任务的损失函数加权同样采用了[13]中提出的基于任务不确定性的方案。
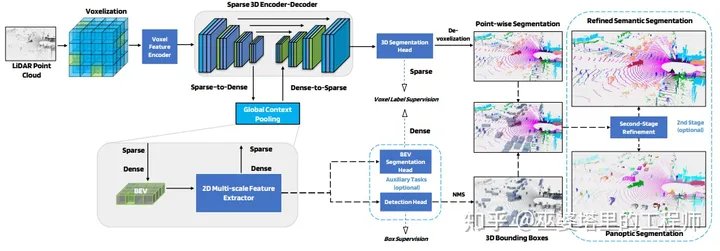
WOD上的实验表明了该方法在点云语义分割上的有效性,但是物体检测和全景分割的效果还有待验证。
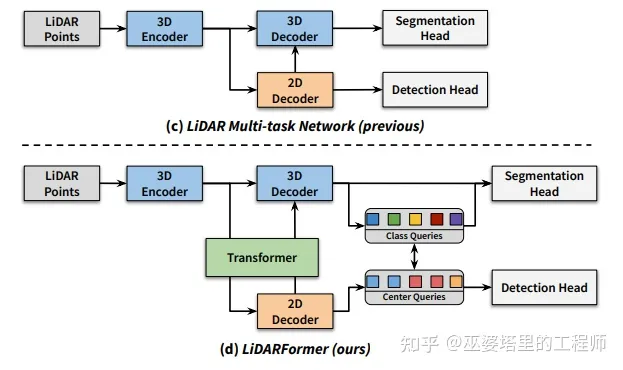
LiDARFormer [15]b
该方法可以看作LidarMultiNet的升级版本,其特点主要在于采用transformer来建立Voxel和BEV特征之间的联系,以及多个任务之间的联系。
如上所述,多个任务之间的联系由类别和中心两组query来建立。两组query合并以后作为统一的query,分别在Voxel和BEV特征上进行交叉注意力计算。
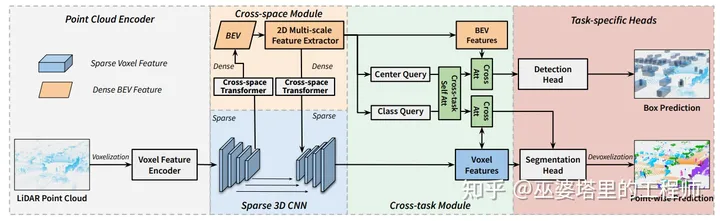
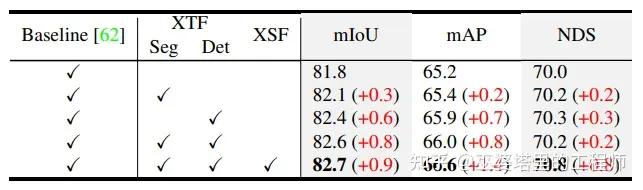
LiDARFormer在nuScenes的检测和分割任务上都获得很好的效果:检测NDS为72.4%,分割mIoU为81.0%. 此外,从下表的对比也可以看出LiDARFormer相对于LidarMultiNet的提升,其中XTF是Cross-Task Transformer,XSF是Cross-Space Transformer。
7 离线处理
作为感知系统的重要传感器,激光雷达一方面可以用于在线系统,另一方面也经常被用于离线标注,为其他传感器提供真值。我们之间介绍的方法都是属于在线的,也就是说需要运行在车端进行实时感知的。对于离线方法来说,输入数据可以是整个点云序列(不用考虑时间上的因果关系),模型也可以设计的更大更复杂,以保证最好的检测准确率。此外,离线的处理还包括数据增广,困难样本挖掘等数据方面的工作。
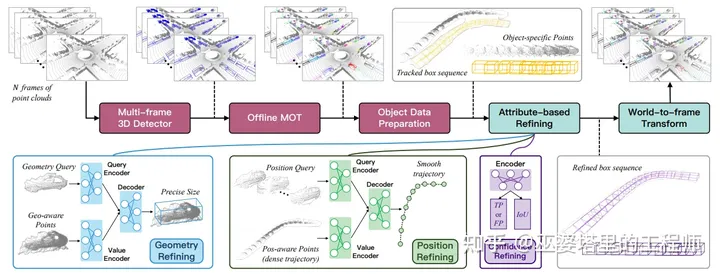
DetZero [16]
论文中提出了一种离线的3D目标检测方法。这个方法主要分为两步:首先是物体检测和跟踪,生成物体的track,然后是对物体的属性进行细化,比如物体框的位置,大小和置信度。
物体检测采用的是CenterPoint,并做了3个扩展以提高检测准确率:1)叠加5帧点云作为输入;2)基于点密度的Voxel特征;3)Test Time Augmentation (TTA),包括推理时的点云旋转,多模型融合。跟踪部分采用的也是离线跟踪的方法,并且按照时间顺序和倒序进行两次跟踪,并融合跟踪结果。
物体属性的细化分为三个模块,分别用来细化物体的大小,位置和置信度。有了物体的track以后,就可以把物体框内的点云分割出来,并且按照物体框的几何信息(中心和朝向)进行对齐,这样就可以叠加整个track上物体的点云,形成更加稠密的表示。这种增强的物体特征表示可以用来修正物体框的大小。大小修正的过程对每个track只用做一遍,因为物体的大小是固定不变的。对于位置来说,track中的每一个时刻都需要进行修正。文章中的做法是,对于track中的每一时刻t,随机采样多个其他时刻,并将对应物体的点云变换到t时刻的坐标下进行对齐,再进行位置偏差的回归。离线的检测和跟踪算法具有很高的召回率,但是输出的track中会有很多错误,需要进行置信度的修正。这个过程与大小的修正类似,也是对整个track做一次就可以了。
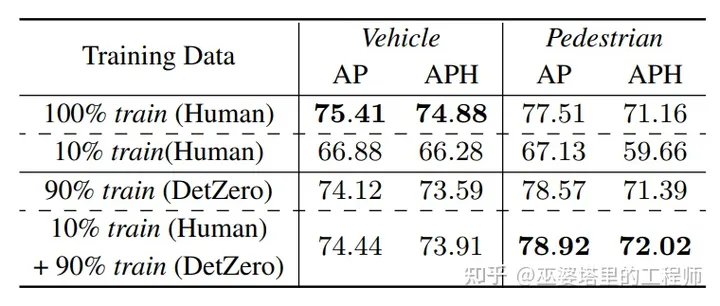
在实验部分,作者对比了采用自动标注和人工标注训练的差异。采用90%的自动标注和10%的人工标注进行混合训练,就可以达到100%人工标注的效果,在行人检测上甚至超过了100%人工标注训练的模型。即使是只采用自动标注,在行人检测上的效果也超过了人工标注。这说明对于小目标来说,自动标注的准确率是更高的,尤其是在远距离的区域。
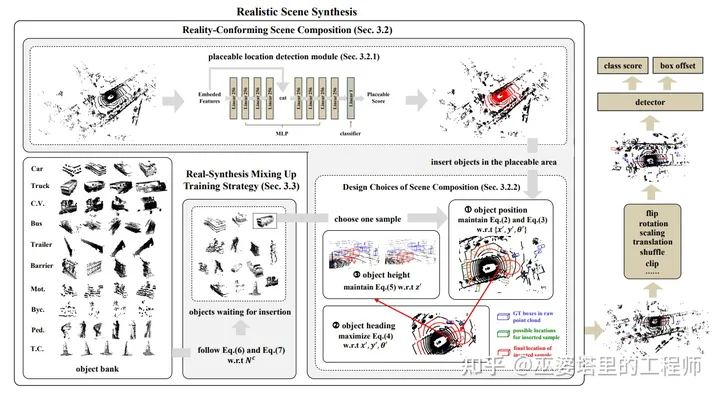
Real-Aug [17]
自动标注可以解决GT的获取问题,但是用来训练的数据本身经常会存在多样性不够的问题。尤其是激光雷达的数据库,规模与图像数据库相比都小很多。而且,由于传感器的特性不同(比如线数),数据库的通用性也不是很好。这就导致我们无法像视觉感知那样,采用一个海量的数据库去预训练一个模型,用来提取通用底层视觉特征。退一步说,即使不考虑海量数据库,构建一个多样性相对较好的中等规模数据库也不是一项简单的任务,需要花费大量的时间进行数据采集,以保证各种场景,各种物体类都有均衡的分布。
改善这个问题的一个思路是进行数据增广。传统的数据增广方法,包括对场景进行平移,镜像,旋转,属于非合成的方式,因为通过这种方式得到的其实还是真实的数据。这种方法可以在一定程度上增加场景的多样性,但是不会改变目标的分布。另外一种方法是合成新的场景,比如说将实际场景中的目标放置到新的位置。这种方法可以改变场景中的目标分布,但是需要考虑的是如何保证场景的真实性。
为了避免生成不真实的场景,Real-Aug中提出几种设计思路。首先,增加的目标只被放置在可行驶的区域。这个设计虽然有些保守,但是可行驶区域对于感知算法来说才是最关键的。其次,在可行驶区域内新增目标的位置,高度,朝向都必须与先验分布相吻合。最后,在训练过程中,新增目标的数量会逐渐降低。在模型训练的初期,大量新增的目标会帮助特征学习。而在模型训练的后期,新增目标减少,更接近真实场景,这样可以更好的学习上下文关系。
在KITTI数据库上,Real-Aug可以将SECOND模型的3D mAP整体提高4.7%。对于数量较少的目标,比如自行车来说,提升效果更加明显,达到8.1%。在更大规模的nuScenes数据集上,CenterPoint模型的NDS也可以被提高6.1%。
FocalFormer3D [18]
该方法提出采用一种Cascade的方式来移除(通过masking)模型已经检测到的目标,从而将注意力放到比较难而且非常重要的漏检上来。这种方式类似于Hard Sample Mining和Focal Loss,但不同的是采用了多阶段的形式。FocalFormer3D严格来说并不算是离线处理,因为推理阶段也采用了多阶段的结构。
参考文献
—END—[1] Chen et al., Focal Sparse Convolutional Networks for 3D Object Detection, 2022.
[2] Chen et al., LargeKernel3D: Scaling up Kernels in 3D Sparse CNNs, 2023.
[3] Lu et al., LinK: Linear Kernel for LiDAR-based 3D Perception. 2023.
[4] Huang et al., Rethinking Dimensionality Reduction in Grid-based 3D Object Detecti on, 2022.
[5] Ront et al., DynStatF: An Efficient Feature Fusion Strategy for LiDAR 3D Object D etection, 2023.
[6] Koh et al., MGTANet: Encoding Sequential LiDAR Points Using Long Short-Term Motio n-Guided Temporal Attention for 3D Object Detection, 2022.
[7] Yang et al., BEVTrack: A Simple Baseline for 3D Single Object Tracking in Bird's-Eye View, 2023.
[8] Zhou et al., CenterFormer: Center-based Transformer for 3D Object Detection, 2022.
[9] Lai et al., Spherical Transformer for LiDAR-based 3D Recognition, 2023
[10] Liu et al., FlatFormer: Flattened Window Attention for Efficient Point Cloud Transformer, 2023.
[11] Fam et al., Embracing Single Stride 3D Object Detector with Sparse Transformer, 2022.
[12] Feng et al., A Simple and Efficient Multi-task Network for 3D Object Detection and Road Understanding, 2021.
[13] Kendall et al., Multi-task learning using uncertainty to weigh losses for scene geometry and semantics, 2018
[14] Ye et al., LidarMultiNet: Unifying LiDAR Semantic Segmentation, 3D Object Detection, and Panoptic Segmentation in a Single Multi-task Network, 2022.
[15] Zhou et al., LiDARFormer: A Unified Transformer-based Multi-task Network for LiDAR Perception, 2023.
[16] Ma et al., DetZero: Rethinking Offboard 3D Object Detection with Long-term Sequential Point Clouds, 2023.
[17] Zhan et al., Real-Aug: Realistic Scene Synthesis for LiDAR Augmentation in 3D Object Detection, 2023.
[18] Chen et al., FocalFormer3D : Focusing on Hard Instance for 3D Object Detection, 2023.
高效学习3D视觉三部曲
第一步 加入行业交流群,保持技术的先进性
目前工坊已经建立了3D视觉方向多个社群,包括SLAM、工业3D视觉、自动驾驶方向,细分群包括:
[工业方向]三维点云、结构光、机械臂、缺陷检测、三维测量、TOF、相机标定、综合群;
[SLAM方向]多传感器融合、ORB-SLAM、激光SLAM、机器人导航、RTK|GPS|UWB等传感器交流群、SLAM综合讨论群;
[自动驾驶方向]深度估计、Transformer、毫米波|激光雷达|视觉摄像头传感器讨论群、多传感器标定、自动驾驶综合群等。
[三维重建方向]NeRF、colmap、OpenMVS、MVSNet等。
[无人机方向]四旋翼建模、无人机飞控等。
除了这些,还有求职、硬件选型、视觉产品落地等交流群。
大家可以添加小助理微信: dddvisiona,备注:加群+方向+学校|公司, 小助理会拉你入群。

第二步 加入知识星球,问题及时得到解答
3.1 「3D视觉从入门到精通」技术星球
针对3D视觉领域的视频课程(三维重建、三维点云、结构光、手眼标定、相机标定、激光/视觉SLAM、自动驾驶等)、源码分享、知识点汇总、入门进阶学习路线、最新paper分享、疑问解答等进行深耕,更有各类大厂的算法工程人员进行技术指导。与此同时,星球将联合知名企业发布3D视觉相关算法开发岗位以及项目对接信息,打造成集技术与就业、项目对接为一体的铁杆粉丝聚集区,6000+星球成员为创造更好的AI世界共同进步,知识星球入口:「3D视觉从入门到精通」
学习3D视觉核心技术,扫描查看,3天内无条件退款
3.2 3D视觉岗求职星球
本星球:3D视觉岗求职星球 依托于公众号「3D视觉工坊」和「计算机视觉工坊」、「3DCV」,旨在发布3D视觉项目、3D视觉产品、3D视觉算法招聘信息,具体内容主要包括:
收集汇总并发布3D视觉领域优秀企业的最新招聘信息。
发布项目需求,包括2D、3D视觉、深度学习、VSLAM,自动驾驶、三维重建、结构光、机械臂位姿估计与抓取、光场重建、无人机、AR/VR等。
分享3D视觉算法岗的秋招、春招准备攻略,心得体会,内推机会、实习机会等,涉及计算机视觉、SLAM、深度学习、自动驾驶、大数据等方向。
星球内含有多家企业HR及猎头提供就业机会。群主和嘉宾既有21届/22届/23届参与招聘拿到算法offer(含有海康威视、阿里、美团、华为等大厂offer)。
发布3D视觉行业新科技产品,触及行业新动向。

第三步 系统学习3D视觉,对模块知识体系,深刻理解并运行
如果大家对3D视觉某一个细分方向想系统学习[从理论、代码到实战],推荐3D视觉精品课程学习网址:www.3dcver.com
科研论文写作:
基础课程:
[1]面向三维视觉算法的C++重要模块精讲:从零基础入门到进阶
[2]面向三维视觉的Linux嵌入式系统教程[理论+代码+实战]
工业3D视觉方向课程:
[1](第二期)从零搭建一套结构光3D重建系统[理论+源码+实践]
SLAM方向课程:
[1]深度剖析面向机器人领域的3D激光SLAM技术原理、代码与实战
[2]彻底剖析激光-视觉-IMU-GPS融合SLAM算法:理论推导、代码讲解和实战
[3](第二期)彻底搞懂基于LOAM框架的3D激光SLAM:源码剖析到算法优化
[4]彻底搞懂视觉-惯性SLAM:VINS-Fusion原理精讲与源码剖析
[5]彻底剖析室内、室外激光SLAM关键算法和实战(cartographer+LOAM+LIO-SAM)
机器人导航与路径规划
[1]移动机器人规划控制入门与实践:基于Navigation2
视觉三维重建:
[2]基于深度学习的三维重建MVSNet系列 [论文+源码+应用+科研]
自动驾驶方向课程:
[1] 深度剖析面向自动驾驶领域的车载传感器空间同步(标定)
[2] 国内首个面向自动驾驶目标检测领域的Transformer原理与实战课程
[4]面向自动驾驶领域的3D点云目标检测全栈学习路线!(单模态+多模态/数据+代码)
[5]如何将深度学习模型部署到实际工程中?(分类+检测+分割)
无人机:
[1] 零基础入门四旋翼建模与控制(MATLAB仿真)[理论+实战]

