
- 1Spring Boot整合RabbitMQ详细教程_springboot整合rabbitmq
- 2未来已来!体验AI数字人客服系统带来的便利与智慧
- 3【python】tkinter+pyserial实现串口调试助手_串口调试工具 python
- 4数据库MongoDB启动方式(3种) - 方法总结篇_如何启动mongodb
- 5通过虚拟机安装Ubuntu系统到移动硬盘_vmware虚拟机移动到移动硬盘
- 6基于MATLAB的ZF、MMSE、THP线性预编码误码率仿真_zf预编码matlab代码
- 7自然语言处理(NLP)—— 置信度(Confidence)_感知层的置信度
- 8自然语言处理的实体识别:命名实体识别与关系抽取_使用自然语言处理进行人物关系抽取
- 9Python Tkinter教程之Event篇(1)_python tk event
- 10代码随想录day1 Java版
大模型日报3月19日_clarity upscaler
赞
踩
资讯
研究
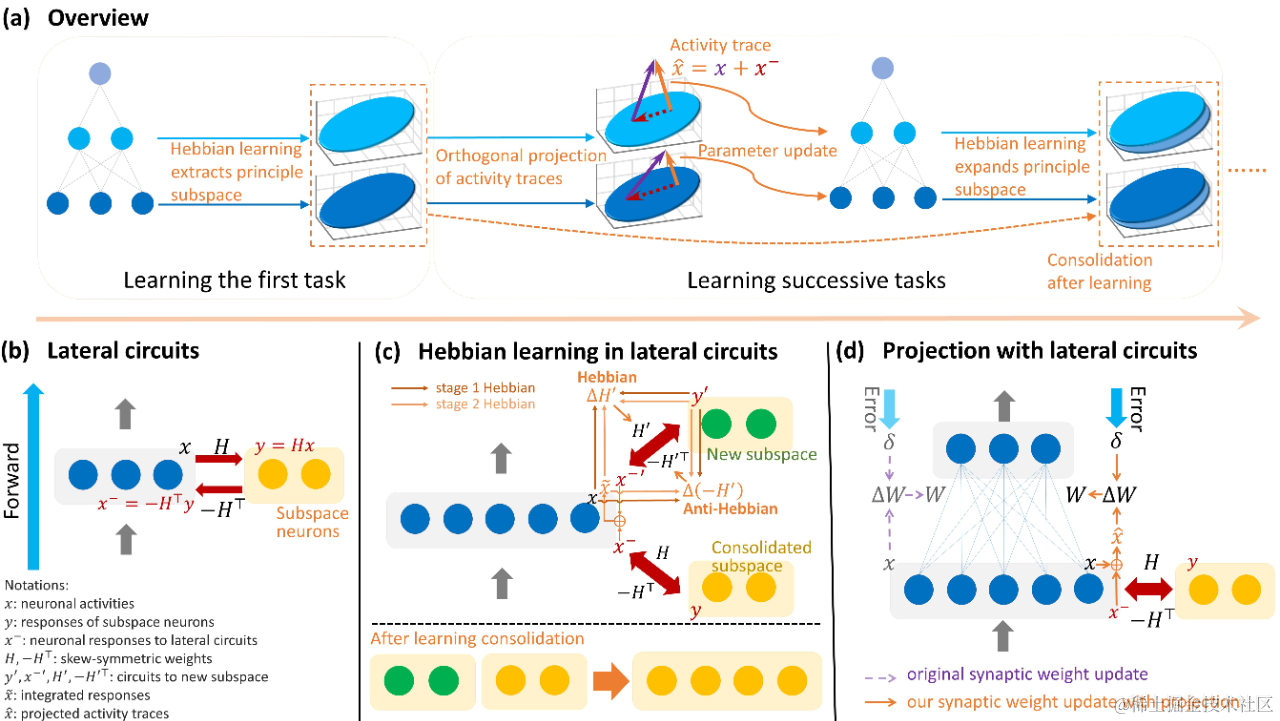
ICLR 2024 | 连续学习不怕丢西瓜捡芝麻,神经形态方法保护旧知识
https://mp.weixin.qq.com/s/-inS55h-MSUX51Kj061big
来自北京大学林宙辰教授团队的研究者们提出了一种新的基于赫布学习的正交投影的连续学习方法,其通过神经网络的横向连接以及赫布与反赫布学习,以神经形态计算的方式提取神经元活动的主子空间并对突触前神经元的活动迹进行投影,实现了连续学习中对旧知识的保护。HLOP 首次展示了更有数学保障的正交投影的思想能够如何在神经元运算中实现,以及横向神经回路和赫布学习等生物特性可能如何支持神经计算系统的高级能力。论文被机器学习顶会 ICLR 2024 接收。
保真度高达~98%,广工大「AI+光学」研究登Nature子刊,深度学习赋能非正交光复用
https://mp.weixin.qq.com/s/Wjc9FVFRb7-EI0TJv5prYg
通道之间的正交性在光复用中扮演着关键的角色。它确保了不同通道之间的信号不会相互干扰,从而实现了高效的数据传输。因此,光复用系统可以同时传输多个通道的数据,提高了光纤的利用率。然而,它不可避免地施加了复用容量的上限。在此,广东工业大学通感融合光子技术教育部重点实验室开发一种基于深度神经网络的多模光纤(MMF)上的非正交光复用,称为散斑光场检索网络(Speckle light field retrieval network,SLRnet),它可以学习包含信息编码的多个非正交输入光场与其对应的单强度输出之间的复杂映射关系。通过原理验证实验,SLRnet 可以有效解决 MMF 上非正交光复用的不适定问题,可以利用单发散斑输出明确地检索由相同偏振、波长和空间位置介导的多个非正交输入信号,保真度高达 ~ 98%。这一研究为利用非正交通道实现高容量光复用迈出了重要一步。该研究不仅将激发光学和光子学领域的各种潜在应用,还将激发信息科学与技术更广泛学科的探索。

产业
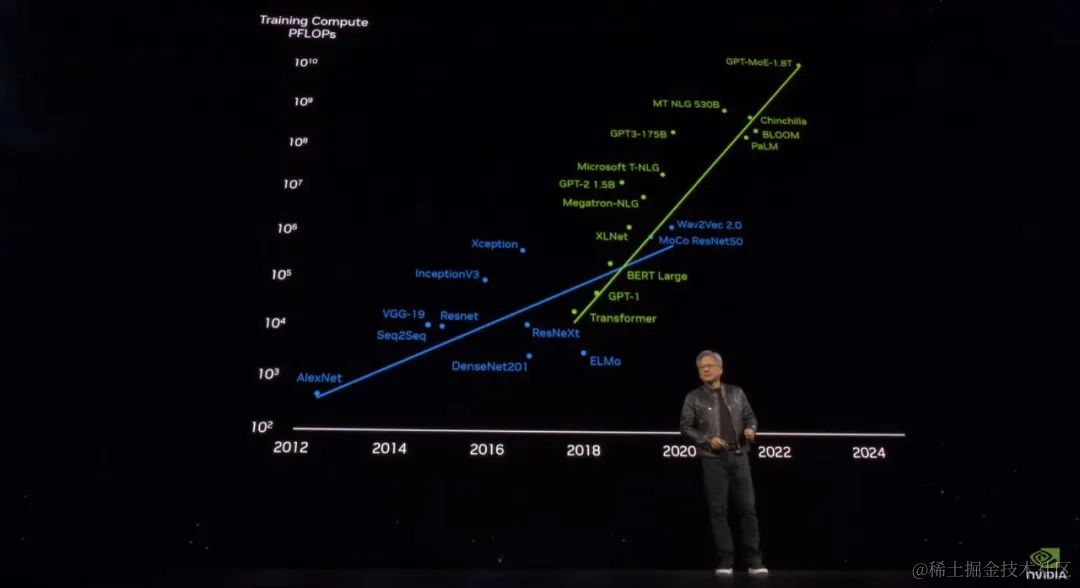
英伟达吞噬世界!新架构超级GPU问世,AI算力一步提升30倍
https://mp.weixin.qq.com/s/EsFkd_isPz2J5wap6KaF5A
「这不是演唱会。你们是来参加开发者大会的!」老黄出场时,现场爆发出了巨大的欢呼声。今天凌晨四点,加州圣何塞,全球市值第三大公司英伟达一年一度的 GTC 大会开始了。今年的 GTC 大会伴随着生成式 AI 技术爆发,以及英伟达市值的暴涨。相对的是,算力市场也在升温,硬件和软件方面的竞争都在加剧。而英伟达带来的产品,再次将 AI 芯片的标杆推向了难以想象的高度。「通用计算已经失去动力,现在我们需要更大的模型,我们需要更大的 GPU,更需要将 GPU 堆叠在一起。」黄仁勋说道。「这不是为了降低成本,而是为了扩大规模。」黄仁勋提到,大模型参数量正在呈指数级增长,此前 OpenAI 最大的模型已经有 1.8T 参数,需要吞吐数十亿 token。即使是一块 PetaFLOP级的 GPU,训练这样大的模型也需要 1000 年才能完成。这句话还透露了一个关键信息:GPT-4 的实际参数量应该就是 1.8 万亿。为了帮助世界构建更大的 AI,英伟达必须首先拿出新的 GPU,这就是 Blackwell。此处老黄已有点词穷了:「这是块非常非常大的 GPU!」Blackwell 的发布意味着,近八年来,AI 算力增长了一千倍。一些网友看完发布会惊叹:Nvidia eats world!
英伟达 GTC 大会不仅有 AI 芯片,还有 AI for Science
https://mp.weixin.qq.com/s/3UvokVFkr6a6s_uqZ_bPvA
北京时间 2024 年 3 月 18 日上午,NVIDIA 在 GTC 大会的媒体吹风会上透露,NVIDIA 有众多 AI for Scinece 领域的战略内容在布局,包括健康医疗、生命科学、物理学、地球科学等多个 AI 交叉领域。

支持百亿参数大模型、卢伟冰现场官宣小米首发,高通骁龙8s Gen3发布
https://mp.weixin.qq.com/s/eBbn8rfxLzC6zrw9dIPVqQ
高通最强手机芯片骁龙 8 Gen3 迎来了一款与它同源的「旗舰级」产品。3 月 18 日,高通正式推出了第三代骁龙 8s 移动平台(骁龙 8s Gen3),凭借旗舰级的 CPU、GPU 和 AI 性能,全方位支持了强大的终端侧生成式 AI 功能、始终感知的 ISP、超沉浸的移动游戏体验、突破性连接能力和无损高清音频。当然,大家最为关心的恐怕是哪家手机厂商会率先搭载这款旗舰芯片。在活动现场,小米集团总裁、小米品牌总经理卢伟冰官宣小米 Civi 4 Pro 将全球首发骁龙 8s Gen3。同时,红米 Redmi 也会推出搭载这款芯片的产品系列。

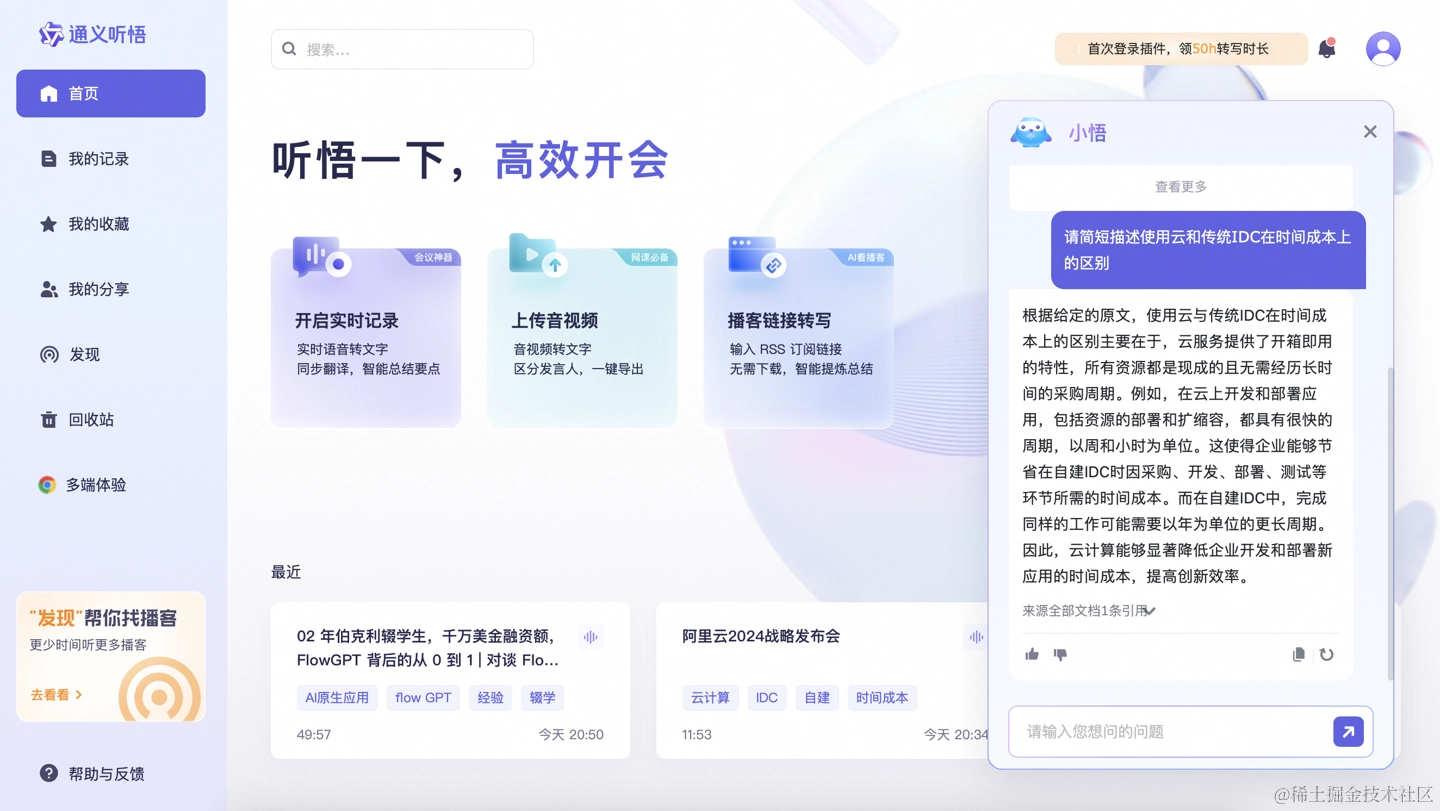
阿里大模型产品“通义听悟”升级:超长视频自由问,还会做思维导图
https://www.ithome.com/0/756/690.htm
今日阿里大模型产品“通义听悟”发布多项新功能,上线音视频问答助手“小悟”、一键 AI 改写、思维导图生成等六大功能。通义听悟接入通义千问大模型,融合了十多项 AI 功能,包括转写、翻译、角色分离、全文摘要、章节速览、发言总结、PPT 提取等,并支持标重点、记笔记。通义听悟本次升级上新了六大功能点,其中最重磅的是音视频问答助手“小悟”,关键信息直接“问”出来。小悟通过多语言 Query 处理、长篇章文本理解、指令演化框架优化及检索增强生成算法,在业内首次实现对超长音视频的单记录、跨记录、多语言自由问答,支持内容问答的音视频时长和文件数均突破业界上限。
OpenAI GPT商店发展缓慢:多数GPT没有用户,开发者信心受损
https://new.qq.com/rain/a/20240319A00N1V00
据国外媒体报道,借助ChatGPT取得的巨大成功,OpenAI首席执行官山姆·奥特曼(Sam Altman)在去年秋天宣布推出GPT商店。类似于苹果iPhone与开发者的共赢模式,OpenAI曾希望第三方开发人员能够利用该公司的技术,向ChatGPT用户开发和销售对话式AI应用。然而在奥特曼宣布推出GPT商店4个月之后,一些通过该商店提供聊天机器人的开发者表示,他们对自己的产品缺少用户感到失望。开发者还表示,在用户分析方面,他们几乎没有得到OpenAI的支持。OpenAI还限制非ChatGPT付费用户访问GPT商店,并且也不允许开发者对GPT收费。向应用开发人员(包括为GPT商店开发应用的开发人员)出售分析工具的基里尔·德莫奇金(Kirill Demochkin)说:“人们觉得OpenAI已经放弃了GPT商店。”

Hinton、Bengio等联合中国专家达成AI安全共识:AI系统不应违反红线
https://mp.weixin.qq.com/s/qeiZ1zkFoK4XZInBRGHRHw
现阶段,人工智能的发展速度已经超出了人们最初的预想,用 AI 工具写文章、编代码、生成图片、甚至是生成一段电影级别的视频…… 这些在以前看似非常艰难的任务,现在只需用户输入一句提示就可以了。我们在感叹 AI 带来惊艳效果的同时,也应该警惕其带来的潜在威胁。在此之前,很多知名学者以带头签署公开信的方式应对 AI 带来的挑战。现在,AI 领域又一封重磅公开信出现了。上周在颐和园召开的「北京AI国际安全对话」,为中国和国际AI安全合作首次搭建了一个独特平台。这次会议由智源研究院发起,图灵奖得主Yoshua Bengio和智源学术顾问委员会主任张宏江担任共同主席,Geoffrey Hinton、Stuart Russell 、姚期智等三十余位中外技术专家、企业负责人开展了一次关于 AI Safety 的闭门讨论。这次会议达成了一项 Bengio、Hinton 与国内专家共同签名的《北京 AI 安全国际共识》。

推特
Jim Fan介绍GR00T:将使机器人能够理解多模态指令,如语言、视频和演示,并执行各种有用的任务
https://x.com/DrJimFan/status/1769860044324319658?s=20
今天是我们在物理世界中解决具身AGI的登月计划的开始。我非常兴奋地宣布GR00T项目,这是我们创建人形机器人学习通用基础模型的新倡议。GR00T模型将使机器人能够理解多模态指令,如语言、视频和演示,并执行各种有用的任务。我们正在与世界各地许多领先的人形机器人公司合作,以便GR00T可以在不同的机器人之间转移,并帮助生态系统繁荣发展。
GR00T诞生于NVIDIA的深度技术堆栈。我们在Isaac Lab(Omniverse Isaac Sim上的新人形机器人学习应用)中进行模拟,在OSMO(新的计算编排系统,用于扩展模型)上进行训练,并部署到Jetson Thor(新的边缘GPU芯片,旨在为GR00T提供动力)。
在Jensen的主题演讲中宣布,GR00T项目是新成立的GEAR实验室"基础智能体"路线图的基石。在GEAR,我们正在构建具有一般能力的智能体,它们可以学习在许多虚拟和现实世界中熟练地行动。看看你能否在视频中发现"GEAR";)加入我们登月之旅吧。
暂时无法在飞书文档外展示此内容
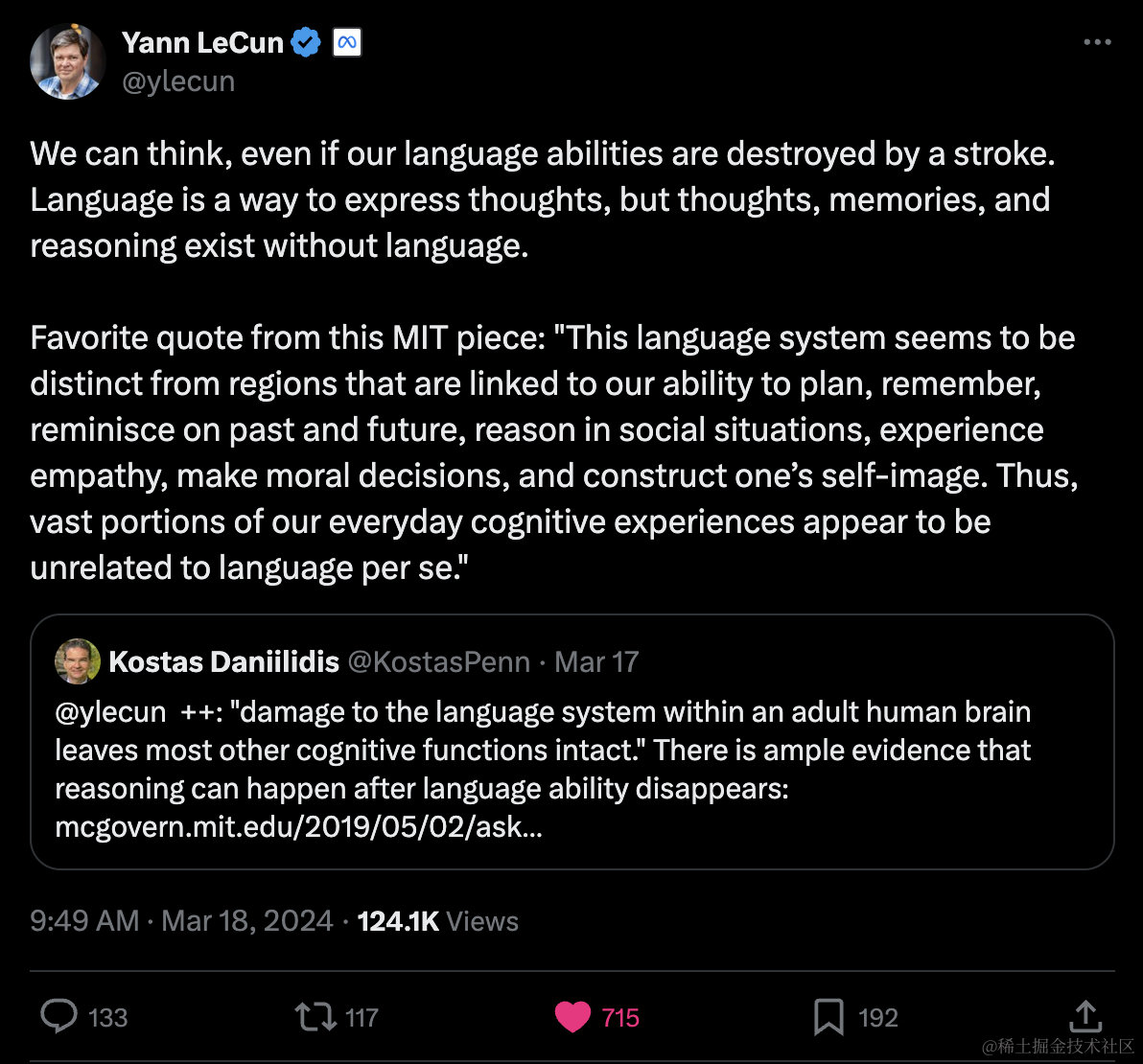
LeCun:即使我们的语言能力被中风破坏,我们仍然可以思考
https://x.com/ylecun/status/1769768065712177615?s=20
即使我们的语言能力被中风破坏,我们仍然可以思考。
语言是表达思想的一种方式,但思想、记忆和推理可以在没有语言的情况下存在。
我最喜欢这篇麻省理工学院文章中的一句话:"这个语言系统似乎与我们计划、记忆、回忆过去和未来、在社交情况下进行推理、体验同理心、做出道德决定以及构建自我形象的能力相关的区域是不同的。因此,我们日常认知经历的很大一部分似乎与语言本身无关。"
引用 Kostas Daniilidis
@ylecun ++: "成年人大脑中语言系统的损伤会使大多数其他认知功能保持完整。"有充分的证据表明,在语言能力消失后,推理仍然可以发生:https://mcgovern.mit.edu/2019/05/02/ask-the-brain-can-we-think-without-language/
DeepLearningAI:高效服务大语言模型,从头学习如何构建优化的大语言模型推理系统
https://x.com/AndrewYNg/status/1769761666143814122?s=20
在我们与 @predibase 合作推出的新短期课程"高效服务大语言模型(Efficiently Serving LLMs)"中,从头学习如何构建优化的大语言模型推理系统。该课程由 @TravisAddair 讲授。
无论你是在服务自己的大语言模型还是使用模型托管服务,本课程都将让你深入了解同时高效服务多个用户所需的优化。
-
了解大语言模型如何一次生成一个token的文本,以及KV缓存、连续批处理和量化等技术如何加速并优化服务多个用户的内存使用。
-
对这些大语言模型优化的性能进行基准测试,探索快速响应单个用户请求与同时服务多个用户之间的权衡。
-
使用低秩自适应(LoRA)等技术在单个设备上高效服务数百个独特的自定义微调模型,而不牺牲吞吐量。
-
使用Predibase的LoRAX框架,在真实的大语言模型服务器上看到优化技术的实际应用。
在此注册:https://deeplearning.ai/short-courses/efficiently-serving-llms
暂时无法在飞书文档外展示此内容
Pietro Schirano:Claude如何指挥子代理构建一个完整的绘图应用程序
https://x.com/skirano/status/1769775481245585883?s=20
Claude Opus协调子代理的能力绝对是疯狂的,值得更多关注。
看看Claude如何指挥子代理构建一个完整的绘图应用程序。
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

