
热门标签
热门文章
- 1Java后端每日面试题(day2)
- 2初识 Microsoft Defender Antivirus 微软杀毒软件与病毒签名_microsoft defender antivirus是什么
- 3Hadoop应用案例分析:在Yahoo的应用
- 4python程序设计基础:面向对象程序设计_程序设计基础对象
- 50基础在ROS系统中实现RRT算法(二)xacro语法以及完整使用_check that: - your xml is well-formed - you have t
- 6git push到远程怎么撤销?_git push撤销远程
- 7iOS 18 中全新 SwiftData 重装升级,其中一个功能保证你们“爱不释手”_swiftdata是什么
- 8基于Hadoop的数据仓库Hive安装_datanucleus.metadata: metadata has jdbc-type of nu
- 9Python基于大数据的微博的舆论情感分析,微博评论情感分析可视化系统,附源码_微博评论情感分析数据可视化
- 102024年最全【面试】聊聊那些年我们大学校招遇到的面试题(1),头条面试高频算法题
当前位置: article > 正文
机器学习算法之KNN分类算法【附python实现代码!可运行】_机器学习knn分类
作者:一键难忘520 | 2024-06-22 10:02:58
赞
踩
机器学习knn分类
一、简介
在机器学习中,KNN(k-Nearest Neighbors)分类算法是一种简单且有效的监督学习算法,主要用于分类问题。KNN算法的基本思想是:在特征空间中,如果一个样本在特征空间中的k个最相邻的样本中的大多数属于某一个类别,则该样本也属于这个类别。KNN算法是一种基于实例的学习,或者说是局部逼近和将所有计算推迟到分类之后进行的惰性学习。
二、算法原理
KNN算法的主要步骤如下:
- 计算距离:给定一个训练数据集,对新的输入实例,在训练数据集中找到与该实例最邻近的k个实例(邻居)。这里的“邻近”通常是通过计算距离来确定的,常用的距离度量方式包括欧氏距离、曼哈顿距离、余弦距离等。
- 确定类别:根据这k个邻居的类别信息,通过多数投票法等方式进行预测。也就是说,选择k个邻居中出现次数最多的类别作为预测结果。(少数服从多数)
三、优缺点
KNN算法的优点包括:
- 思想简单,易于理解和实现。
- 对异常值不敏感,因为只与少数几个最近的邻居有关。
- 适用于多分类问题。
- 由于KNN方法主要靠周围有限的邻近的样本,而不是靠判别类域的方法来确定所属类别的,因此对于类域的交叉或重叠较多的待分样本集来说,KNN方法较其他方法更为适合。
然而,KNN算法也存在一些缺点:
- 计算量大,特别是对于大规模数据集,计算每个新实例与所有训练实例的距离可能需要很长时间。
- 需要存储整个训练数据集,以便对新实例进行分类。因此,如果训练数据集很大,可能需要大量的存储空间。
- 对k值的选择敏感。k值选择过小可能导致过拟合,选择过大可能导致欠拟合。
- 当样本分布不平衡时,如一个类的样本容量很大,而其他类样本容量很小时,有可能导致当输入一个新样本时,该样本的K个邻居中大容量类的样本占多数。
四、python代码实现(案例)
在python代码中,使用scikit-learn库中的鸢尾花(Iris)数据集,这是一个包含三个类别(Setosa、Versicolour、Virginica)和四个特征(花萼长度、花萼宽度、花瓣长度、花瓣宽度)的经典数据集。
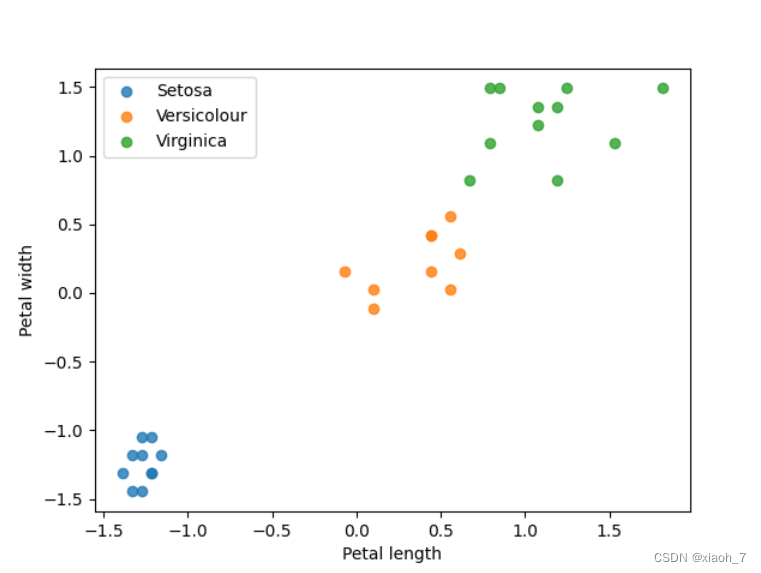
import matplotlib.pyplot as plt # 导入matplotlib库用于绘图 import numpy as np # 导入numpy库用于数值计算 from sklearn import datasets # 导入sklearn库中的datasets模块用于加载数据集 from sklearn.model_selection import train_test_split # 导入train_test_split函数用于划分数据集 from sklearn.preprocessing import StandardScaler # 导入StandardScaler类用于数据标准化 from sklearn.neighbors import KNeighborsClassifier # 导入KNeighborsClassifier类用于创建KNN分类器 from sklearn.metrics import classification_report, confusion_matrix # 导入分类报告和混淆矩阵计算函数 # 加载鸢尾花数据集 iris = datasets.load_iris() # 加载鸢尾花数据集 X = iris.data # 获取特征数据 y = iris.target # 获取标签数据 # 数据集分割为训练集和测试集 X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.2, random_state=42) # 划分数据集为80%的训练集和20%的测试集 # 数据标准化 scaler = StandardScaler() # 创建一个StandardScaler对象 X_train_scaled = scaler.fit_transform(X_train) # 对训练集进行标准化处理 X_test_scaled = scaler.transform(X_test) # 对测试集进行标准化处理,使用训练集得到的均值和标准差 # 初始化KNN分类器并训练(使用所有四个特征) knn = KNeighborsClassifier(n_neighbors=3) # 创建一个KNN分类器对象,设置邻居数为3 knn.fit(X_train_scaled, y_train) # 使用训练集数据训练KNN分类器 # 使用测试集进行预测 y_pred = knn.predict(X_test_scaled) # 使用训练好的KNN分类器对测试集进行预测 # 打印分类报告和混淆矩阵 print(classification_report(y_test, y_pred)) # 打印分类报告,包括精确度、召回率、F1值等 print(confusion_matrix(y_test, y_pred)) # 打印混淆矩阵,展示各类别的分类情况 # 可视化结果(只选择两个特征进行二维可视化) # 这里我们选择花瓣长度和花瓣宽度作为特征 # 注意:由于数据已经标准化,所以这里的可视化主要是为了展示分类效果,而不是真实的花瓣长度和宽度 plt.scatter(X_test_scaled[y_test == 0, 2], X_test_scaled[y_test == 0, 3], label='Setosa', alpha=0.8) # 绘制Setosa类别的散点图 plt.scatter(X_test_scaled[y_test == 1, 2], X_test_scaled[y_test == 1, 3], label='Versicolour', alpha=0.8) # 绘制Versicolour类别的散点图 plt.scatter(X_test_scaled[y_test == 2, 2], X_test_scaled[y_test == 2, 3], label='Virginica', alpha=0.8) # 绘制Virginica类别的散点图 # 添加图例和轴标签 plt.xlabel('Petal length (scaled)') # 这里的'Petal length'是标准化的花瓣长度 plt.ylabel('Petal width (scaled)') # 这里的'Petal width'是标准化的花瓣宽度 plt.legend() # 添加图例 plt.show() # 显示图像 # 保存图像 plt.savefig('knn_iris_visualization.png') # 将图像保存为'knn_iris_visualization.png'文件

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
以上代码需要以下环境包,如果没有可以先行安装
pip install numpy matplotlib scikit-learn
- 1
实验结果
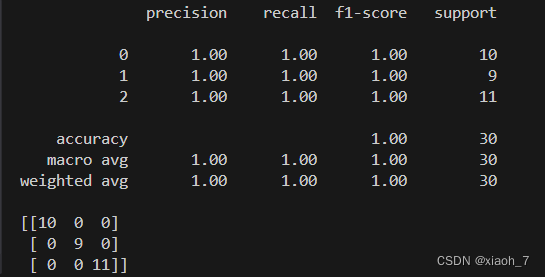
结果可视化
五、应用与总结
KNN算法在各个领域都有广泛的应用,包括但不限于图像识别、文本分类、推荐系统等。例如,在图像识别中,可以使用KNN算法来识别手写数字、人脸等;在文本分类中,可以使用KNN算法来对新闻、评论等进行分类。KNN分类算法是一种简单而有效的机器学习算法,它通过计算新实例与训练数据集中实例的距离来进行分类。虽然它存在一些缺点,但在许多情况下仍然是一种很好的选择。
版权声明
本博客内容仅供学习交流,转载请注明出处。
声明:本文内容由网友自发贡献,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:【wpsshop博客】
推荐阅读
相关标签

