
- 1win10远程桌面连接-出现身份验证错误解决方法_authentication error! right click on forts -> prop
- 2Spark Partition方式_spark repartition 能保证同一个key的数据分配到一起
- 3CSS选择符和可继承属性
- 4苹果电脑关于网络参数的查询_macos ifconfig
- 5计算机网络——网络传输优化实战_tcp syncookies
- 6kafka数据库oracle对比,互联网行业“中年”危机_kafka数据库类似的数据库
- 7古墓丽影:暗影缺少winmm.dll文件无法启动全方位深入解决方案介绍_古墓丽影暗影win11无法启动
- 800后说我不会自动化测试,3个问题直接给他问趴下..._100条自动化测试脚本需要多少工程师执行
- 9[转载]静态成员函数能不能同时也是虚函数?
- 10CANoe -选项卡 和 功能区_canoe快捷键
吊打 CLIP 平均10个点,Meta 多模态通用模型 FLAVA真香啊_metaclip 参数量
赞
踩

厉害了!作者将单一模型运用于三个不同领域的不同任务,结构简单且训练直观,还能有着出色的表现。
自Transformer横空出世,从NLP到CV,再到今天的多模态,无数基于Transformer的模型被应用于各类任务,似乎真的印证了当年文章的标题“Transformer is ALL you need”。然而,纯粹的NLP任务有BERT、RoBERTa,CV任务有ViT,多模态任务又有VLBERT、OSCAR,虽然都是基于Transformer的结构,但是仍然是针对不同任务设计不同模型,那么“万能”的Transformer能否构建出一个统合各类任务的模型,实现真的的一个模型解决所有问题呢?
干货推荐
- 比 PyTorch 的官方文档还香啊,吃透PyTorch中文版来了
- 赶快收藏,PyTorch 常用代码段PDF合辑版来了
- Github大盘点:2021年最惊艳的38篇AI论文
- 我最喜欢的10个顶级数据科学资源,kaggle、TDS、arXiv…
今天文章的作者就关注到了当前各个模型的局限,提出了一个适用于NLP+CV+多模态的模型FLAVA,可运用于三种领域共计35个任务,且都有着出色的表现。
论文题目:
FLAVA: A Foundational Language And Vision Alignment Model
论文链接:
https://arxiv.org/abs/2112.04482
 介绍
介绍
文章标题中,作者称模型为“Foundational”,他们不希望借助各种奇技淫巧的Tricks,而是通过尽可能简单的结构,配合直观的的训练手段,达到涵盖NLP、CV、多模态的目的。
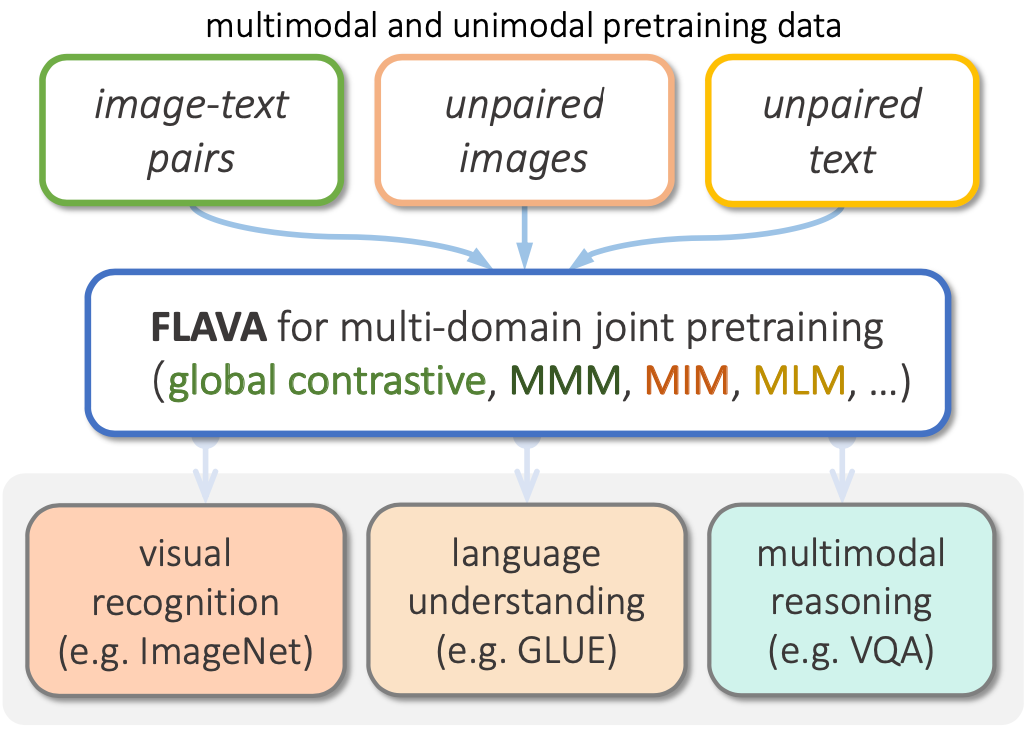
FLAVA基于三种不同的输入:
-
匹配的图片-文本
-
单独文本
-
单独图片
解决三个领域的问题:
-
NLP:语言理解(如GLUE)
-
CV:视觉识别(如ImageNet)
-
多模态:多模态解释(如VQA)
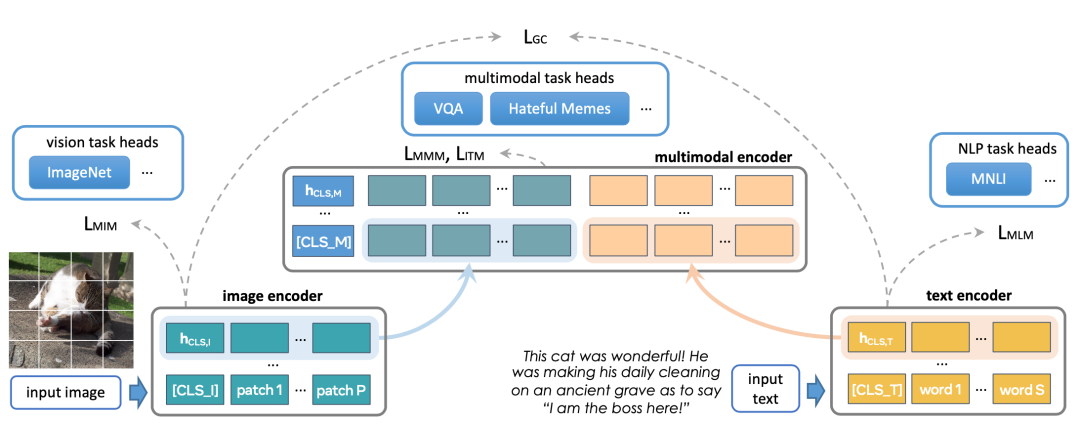
图片编码器(Image Encoder)
FLAVA直接借用既有模型ViT的结构,同时仿照ViT的处理方法,分割图片进行编码。在ViT输出的隐状态上,FLAVA利用单一模态数据集中的图片进行Masked Image Modeling。首先,利用dVAE将图片转化为类似词向量的token;再参照BEiT,对masked隐状态进行分类,即利用周围图片分块,预测masked的图片属于dVAE划分的哪一类,这样在图片上也可以像BERT那样做mask modeling。
文本编码器(Text Encoder)
FLAVA在文本部分多处理就相对简单,作者采取常见的Masked Language Modeling,对一部分masked token进行预测,和其他方法对区别在于,FLAVA没有采用BERT之类纯文本语言模型的结构,而是和图片编码器一样,使用了ViT的结构,不过因为是不同的模态,自然采用了不同的模型参数。
多模态编码器(Multimodal Encoder)
在图片编码器和文本编码器之上,FLAVA添加了一层多模态编码器做模态融合,多模态编码器将前两者输出的隐藏状态作为输入,同样利用ViT的模型结构进行融合。
多模态预训练
在文本编码器和图片编码器中,FLAVA在单一模态上进行了预训练,在多模态预训练方面,FLAVA使用了三种多模态预训练任务:
-
对比学习:FLAVA利用图片编码器和文本编码器的隐藏状态,增大相匹配的图片-文本对之间的余弦相似度,减小非匹配的图片-文本对之间的余弦相似度。
-
Masked Multimodal Modeling:与图片编码器上的MIM类似,只不过改为利用多模态编码器的隐状态进行预测。
-
图片-文本匹配:与许多现有模型一样,FLAVA利用多模态编码器的[CLS]的隐状态,识别当前图片与文本是否匹配。
效果
从上述模型细节可以看出,无论是模型结构,还是预训练任务,文本与图片之间高度对称,同时也设计也十分直观。接下来看看在35个任务上的表现。
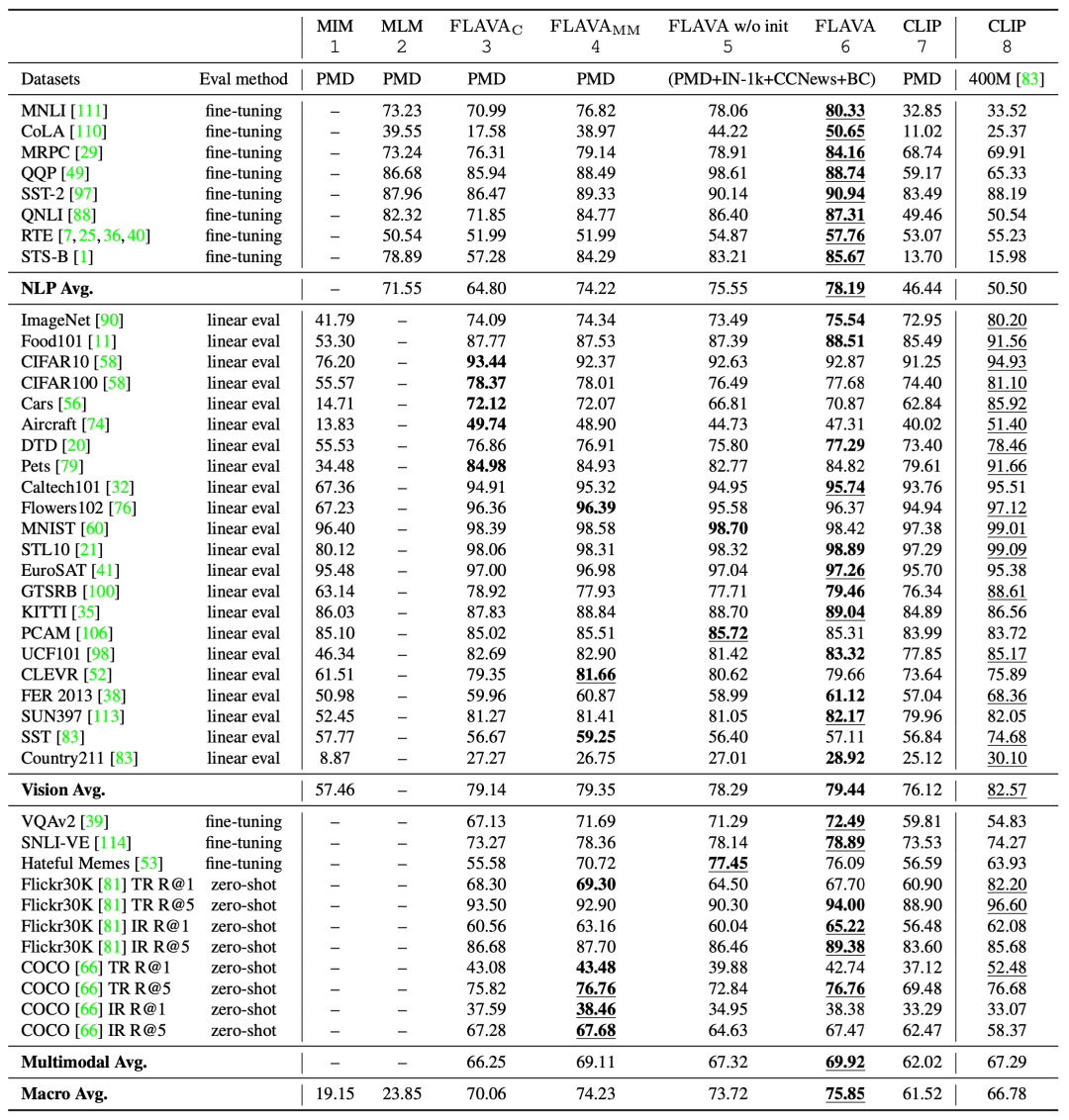
图中下划线表示最优结果,加粗表示在公开数据集上训练的最优结果。

从各个任务平均上看,FLAVA能够取得整体上的最优结果,多模态任务平均比CLIP高出2个百分点左右,整体平均比CLIP高出10个百分点左右。从具体任务上看,在不少任务上都取得了十分显著的提高,如STS-B数据集提高了69.69,MNLI数据集提高了46.81。
小结
不同于现有模型,FLAVA最大的特点,也可以说是创新点,在于作者实现了将单一模型运用于三个不同领域的不同任务,而且都有着不错的效果,虽然FLAVA并没有奇迹般在所有任务上都达到SOTA,但是整体性能上并不弱于现有模型,同时有着更广阔的运用场景,模型设计也没有各种奇技淫巧,这对未来研究通用模型有着很大的启发。

