
- 1oVirt虚拟化部署_ovirt部署云桌面
- 2平凉市全国计算计算机,甘肃省平凉市2018年3月计算机等级考试公告
- 3透视数字人克隆直播系统:科技革新下的全新互动体验
- 4OSPF协议原理简析
- 5linux tar 7z,.tar.gz和.gz或.tar.7z和.7z有什么区别?
- 6Spark 【RDD基础编程(一)RDD的创建、转换操作】_rdd的创建 -java 第1关:集合并行化创建rdd
- 72024年最全git 安装、创建仓库、常用命令、克隆下载、上传项目(1),大厂大数据开发核心面试题出炉_快速安装git
- 8neo4j 图数据库使用教程_neo4j查看数据库
- 9Android Studio 报错:Failed to create Jar file xxxxx.jar
- 10HarmonyOS APP 开发入门_鸿蒙仓颉编程语言入门,HarmonyOS鸿蒙 面试_仓颉编程入门
Hadoop 安装与使用:大数据处理的基石_安装 hadoop
赞
踩
导语:Hadoop 是一个开源的分布式计算平台,广泛应用于大数据处理和分析。本文将为您介绍 Hadoop 的安装步骤以及基本使用方法,帮助您快速上手 Hadoop,并在项目中发挥其强大的功能。
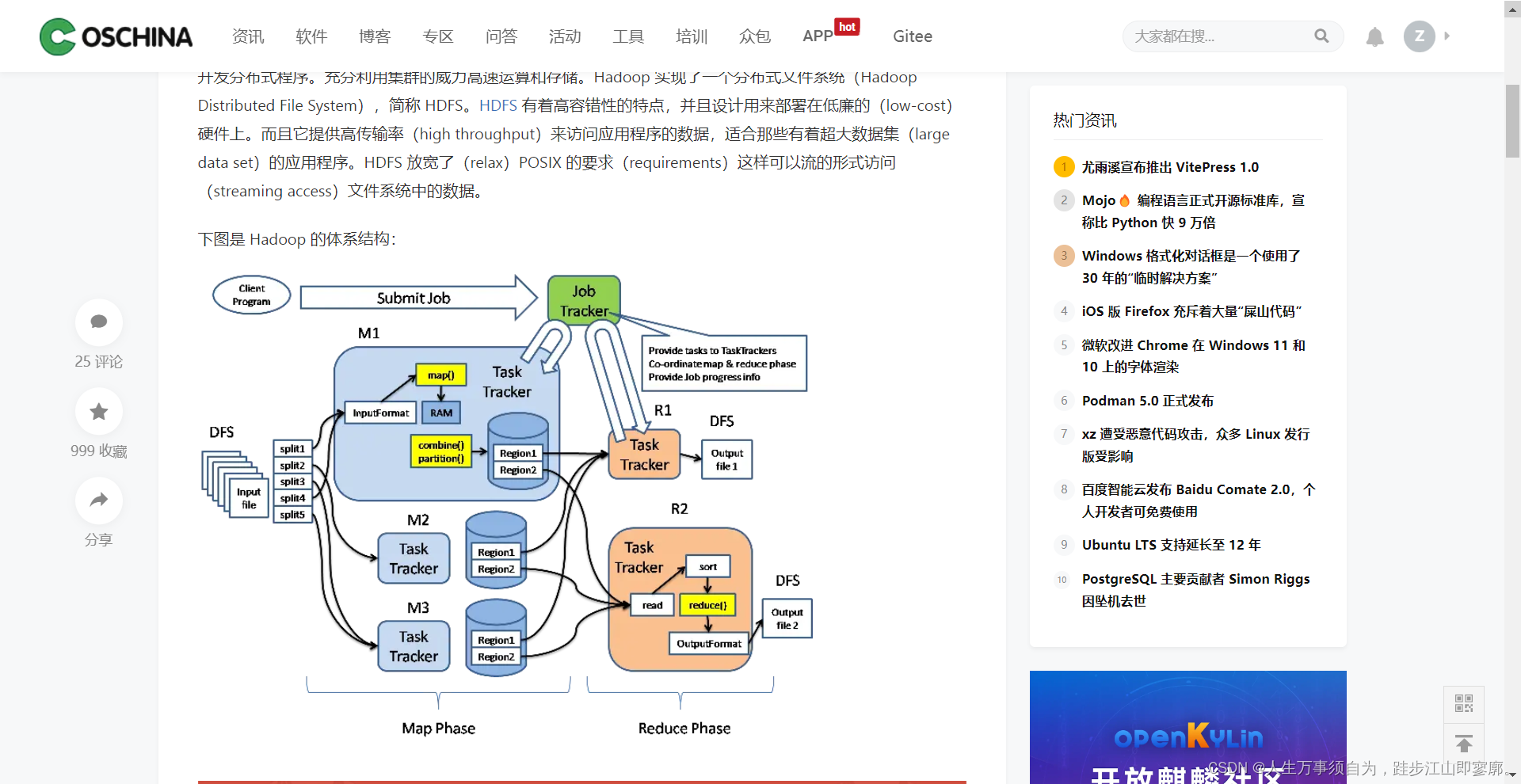
正文:
一、Hadoop 简介
Hadoop 是一个开源的分布式计算平台,由 Apache 软件基金会维护。它基于 Google 的 MapReduce 编程模型,提供了一个可扩展、可靠的分布式计算框架,适用于大数据处理和分析。
二、Hadoop 安装步骤
1. 准备环境
确保您的环境中已安装 Java 1.7 或更高版本。
2. 下载 Hadoop
访问 Hadoop 官方网站(http://hadoop.apache.org/)下载适合您操作系统的 Hadoop 安装包。
3. 解压 Hadoop 安装包
将下载的 Hadoop 安装包解压到指定目录。
4. 配置 Hadoop 环境变量
在系统环境变量中添加 Hadoop 解压后的目录路径。
5. 配置 Hadoop 配置文件
在 Hadoop 安装目录的 `etc/hadoop` 目录中,修改 `hadoop-env.sh`、`yarn-env.sh` 和 `hadoop-site.xml` 文件,配置 Hadoop 环境变量和 HDFS 参数。
6. 启动 Hadoop
在 Hadoop 安装目录的 `sbin` 目录中,运行以下命令启动 Hadoop 集群:
-
- ./start-all.sh
三、Hadoop 基本使用
1. 创建文件夹
在 Hadoop 集群中,使用以下命令创建文件夹:
-
- hdfs dfs -mkdir /user/hadoop
2. 上传文件
将本地文件上传到 Hadoop 集群中的指定路径:
-
- hdfs dfs -put /path/to/local/file /user/hadoop/
3. 执行 MapReduce 任务
在 Hadoop 集群中,使用以下命令执行 MapReduce 任务:
-
- hadoop jar /path/to/mr-job.jar com.example.MyMapper com.example.MyReducer /input/path /output/path
4. 查看任务状态
使用以下命令查看 Hadoop 集群中任务的执行状态:
-
- yarn application -list
四、总结
通过本文的介绍,您应该已经了解了 Hadoop 的安装步骤和基本使用方法。在实际应用中,熟练掌握这些知识点,可以帮助您更高效地使用 Hadoop,实现大数据处理和分析。
结语:
Hadoop 是一个功能强大的分布式计算平台,适用于大数据处理和分析。通过本文的介绍,您应该已经掌握了 Hadoop 的基本安装和使用方法。无论您是初学者还是有一定经验的开发者,都应该熟练掌握这些知识点,以便在项目中发挥 Hadoop 的强大功能。希望本文的内容能对您有所帮助,让您的数据处理之路更加顺畅!

