
- 1Unity3D 游戏数据本地化存储与管理详解
- 2生成对抗网络(GAN)_对抗网络 共享特征
- 3python+jieba+wordcloud实现超酷的词云_jieba分词后如何使用jupyter输出
- 4go + uniapp 通过 微信 code 获取 appid 等信息 无废话_uniapp获取微信code
- 5go语言有没有简单的流程引擎_go 流程引擎
- 6Mysql---C#在cmd中使用mysqldump导出sql文件
- 7论文阅读【时间序列分析1】Reconstructing Nonlinear Dynamical Systems from Multi-Modal Time Series_多模态时间序列
- 8yolov5调试common.py出现importerror: cannot import name ‘tryexcept‘ from ‘utils‘_cannot import name 'tryexcept' from 'utils
- 9Android:漫画APP开发笔记之ListView中图片按屏幕宽度缩放_android listview可缩放
- 10基于 Nginx Ingress + 云效 AppStack 实现灰度发布
实战:循环神经网络与文本内容情感分类_基于循环神经网络的文本情感分类
赞
踩
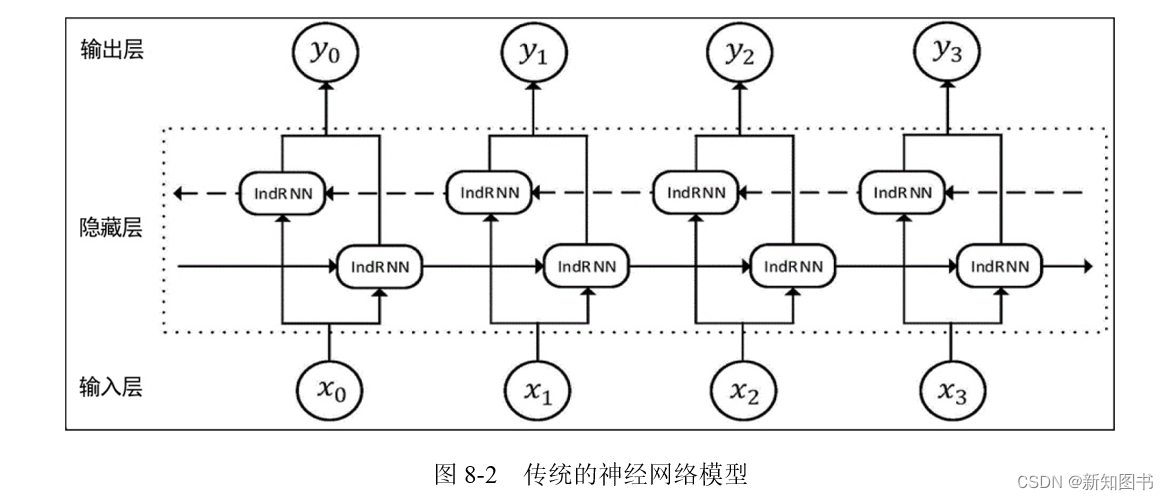
在传统的神经网络模型中,是从输入层到隐含层再到输出层,层与层之间是全连接的,每层之间的节点是无连接的。但是这种普通的神经网络对于很多问题却无能为力。例如,你要预测句子的下一个单词是什么,一般需要用到前面的单词,因为一个句子中前后单词并不是独立的,即一个序列当前的输出与前面的输出也有关。
具体的表现形式为网络会对前面的信息进行记忆并应用于当前输出的计算中,即隐藏层之间的节点不再是无连接的,而是有连接的,并且隐藏层的输入不仅包括输入层的输出,还包括上一时刻隐藏层的输出,这种传统的神经网络模型如图8-2所示。
8.2.1 基于循环神经网络的中文情感分类准备工作
在讲解循环神经网络的理论知识之前,最好的学习方式就是通过实例实现并运行对应的项目,本小节将带领读者完成一下循环神经网络的情感分类实战的准备工作。
1. 数据的准备
首先是数据集的准备工作。在本节中,我们需要完成的是中文数据集的情感分类,因此事先准备了一套已完成情感分类的数据集,读者可以参考本书配套代码中dataset目录下的chnSenticrop.txt文件确认一下。此时我们需要完成数据的读取和准备工作,其实现代码如下:
- max_length = 80 #设置获取的文本长度为80
- labels = [] #用以存放label
- context = [] #用以存放汉字文本
- vocab = set()
- with open("../dataset/cn/ChnSentiCorp.txt", mode="r", encoding="UTF-8") as emotion_file:
- for line in emotion_file.readlines():
- line = line.strip().split(",")
-
- # labels.append(int(line[0]))
- if int(line[0]) == 0:
- labels.append(0) #由于在后面直接采用PyTorch自带的crossentroy函数,因此这里直接输入0,否则输入[1,0]
- else:
- labels.append(1)
- text = "".join(line[1:])
- context.append(text)
- for char in text: vocab.add(char) #建立vocab和vocab编号
-
- voacb_list = list(sorted(vocab))
- # print(len(voacb_list))
- token_list = []
- #下面是对context内容根据vocab进行token处理
- for text in context:
- token = [voacb_list.index(char) for char in text]
- token = token[:max_length] + [0] * (max_length - len(token))
- token_list.append(token)

2. 模型的建立
接下来可以根据需求建立模型。在这里我们实现了一个带有单向GRU和一个双向GRU的循环神经网络,代码如下:
- class RNNModel(torch.nn.Module):
- def __init__(self,vocab_size = 128):
- super().__init__()
- self.embedding_table = torch.nn.Embedding(vocab_size,embedding_dim=312)
- self.gru = torch.nn.GRU(312,256) # 注意这里输出有两个:out与hidden,out是序列在模型运行后全部隐藏层的状态,而hidden是最后一个隐藏层的状态
- self.batch_norm = torch.nn.LayerNorm(256,256)
-
- self.gru2 = torch.nn.GRU(256,128,bidirectional=True) # 注意这里输出有两个:out与hidden,out是序列在模型运行后全部隐藏层的状态,而hidden是最后一个隐藏层的状态
-
- def forward(self,token):
- token_inputs = token
- embedding = self.embedding_table(token_inputs)
- gru_out,_ = self.gru(embedding)
- embedding = self.batch_norm(gru_out)
- out,hidden = self.gru2(embedding)
-
- return out
这里要注意的是,对于GRU进行神经网络训练,无论是单向还是双向GUR,其结果输出都是两个隐藏层状态,即out与hidden。这里的out是序列在模型运行后全部隐藏层的状态,而hidden是此序列最后一个隐藏层的状态。
在这里我们使用的是2层GRU,有读者会注意到,在我们对第二个GRU进行定义时,使用了一个额外的参数bidirectional,这个参数用来定义循环神经网络是单向计算还是双向计算的,其具体形式如图8-3所示。
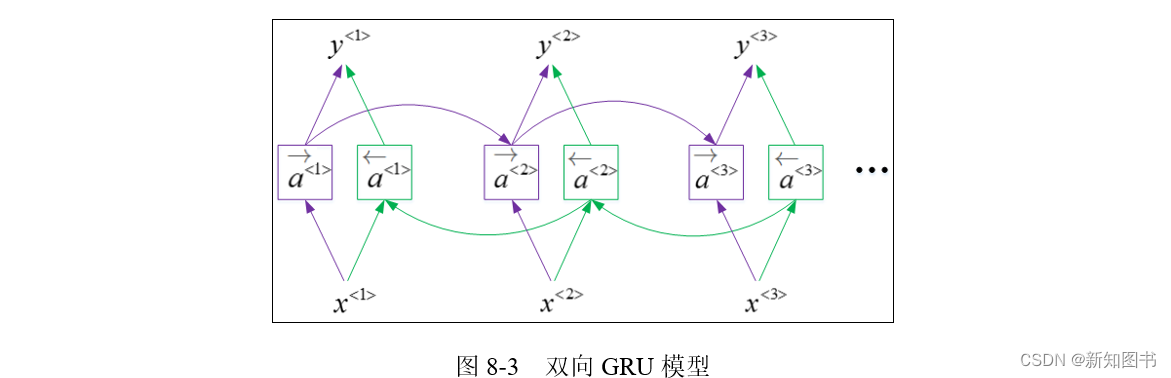
从图8-3中可以很明显地看到,左右两个连续的模块并联构成了不同方向的循环神经网络单向计算层,而这两个方向同时作用后生成了最终的隐藏层。
8.2.2 基于循环神经网络的中文情感分类
上一小节完成了循环神经网络的数据准备以及模型的建立,下面我们可以对中文数据集进行情感分类,完整的代码如下:
- import numpy as np
-
- max_length = 80 #设置获取的文本长度为80
- labels = [] #用以存放label
- context = [] #用以存放汉字文本
- vocab = set()
-
- with open("../dataset/cn/ChnSentiCorp.txt", mode="r", encoding="UTF-8") as emotion_file:
- for line in emotion_file.readlines():
- line = line.strip().split(",")
-
- # labels.append(int(line[0]))
- if int(line[0]) == 0:
- labels.append(0) #由于在后面直接采用PyTorch自带的crossentroy函数,因此这里直接输入0,否则输入[1,0]
- else:
- labels.append(1)
- text = "".join(line[1:])
- context.append(text)
- for char in text: vocab.add(char) #建立vocab和vocab编号
-
- voacb_list = list(sorted(vocab))
- # print(len(voacb_list))
- token_list = []
- #下面的内容是对context根据vocab进行token处理
- for text in context:
- token = [voacb_list.index(char) for char in text]
- token = token[:max_length] + [0] * (max_length - len(token))
- token_list.append(token)
-
- seed = 17
- np.random.seed(seed);np.random.shuffle(token_list)
- np.random.seed(seed);np.random.shuffle(labels)
-
- dev_list = np.array(token_list[:170])
- dev_labels = np.array(labels[:170])
-
- token_list = np.array(token_list[170:])
- labels = np.array(labels[170:])
-
- import torch
- class RNNModel(torch.nn.Module):
- def __init__(self,vocab_size = 128):
- super().__init__()
- self.embedding_table = torch.nn.Embedding(vocab_size,embedding_dim=312)
- self.gru = torch.nn.GRU(312,256) # 注意这里输出有两个:out与hidden,out是序列在模型运行后全部隐藏层的状态,而hidden是最后一个隐藏层的状态
- self.batch_norm = torch.nn.LayerNorm(256,256)
-
- self.gru2 = torch.nn.GRU(256,128,bidirectional=True) # 注意这里输出有两个:out与hidden,out是序列在模型运行后全部隐藏层的状态,而hidden是最后一个隐藏层的状态
-
- def forward(self,token):
- token_inputs = token
- embedding = self.embedding_table(token_inputs)
- gru_out,_ = self.gru(embedding)
- embedding = self.batch_norm(gru_out)
- out,hidden = self.gru2(embedding)
-
- return out
-
- #这里使用顺序模型的方式建立了训练模型
- def get_model(vocab_size = len(voacb_list),max_length = max_length):
- model = torch.nn.Sequential(
- RNNModel(vocab_size),
- torch.nn.Flatten(),
- torch.nn.Linear(2 * max_length * 128,2)
- )
- return model
-
- device = "cuda"
- model = get_model().to(device)
- model = torch.compile(model)
- optimizer = torch.optim.Adam(model.parameters(), lr=2e-4)
-
- loss_func = torch.nn.CrossEntropyLoss()
-
- batch_size = 128
- train_length = len(labels)
- for epoch in (range(21)):
- train_num = train_length // batch_size
- train_loss, train_correct = 0, 0
- for i in (range(train_num)):
- start = i * batch_size
- end = (i + 1) * batch_size
-
- batch_input_ids = torch.tensor(token_list[start:end]).to(device)
- batch_labels = torch.tensor(labels[start:end]).to(device)
-
- pred = model(batch_input_ids)
-
- loss = loss_func(pred, batch_labels.type(torch.uint8))
-
- optimizer.zero_grad()
- loss.backward()
- optimizer.step()
-
- train_loss += loss.item()
- train_correct += ((torch.argmax(pred, dim=-1) == (batch_labels)).type(torch.float).sum().item() / len(batch_labels))
-
- train_loss /= train_num
- train_correct /= train_num
- print("train_loss:", train_loss, "train_correct:", train_correct)
-
- test_pred = model(torch.tensor(dev_list).to(device))
- correct = (torch.argmax(test_pred, dim=-1) == (torch.tensor(dev_labels).to(device))).type(torch.float).sum().item() / len(test_pred)
- print("test_acc:",correct)
- print("-------------------")
在上面代码中,我们顺序建立循环神经网络模型,在使用GUR对数据进行计算后,又使用Flatten对序列embedding进行平整化处理;而最后的Linear是分类器,作用是对结果进行分类。具体结果请读者自行测试查看。
本文节选自《PyTorch语音识别实战》,获出版社和作者授权发布。


