
热门标签
热门文章
- 1建议博客园搭个威客平台,可行的发展方向和盈利方向
- 2Kafka【应用 01】Offset Explorer Kafka 的终极 UI 工具安装+简单上手+关键特性测试(一篇学会使用 Offset Explorer)(1)_kafkaui
- 3使用Git和小乌龟——git did not exit cleanly (exit code 128) 报错
- 4Linux中Apache网站基于Http服务的访问限制(基于地址/用户)_apache 限制访问ip
- 5怎样使用git add命令将当前修改的两个乃至多个文件一次性全部加入暂存区,不包括未跟踪的文件_git add.后没有全部进入缓存区
- 6【Unity】Kafka、Mqtt、Wesocket通信_unity kafka
- 7Redis在数据聚合中的应用:实现实时的数据汇总与分析
- 8K-Means算法详解_k-means算法识别恢复区
- 9python xml 解析_python解析xml
- 10Android性能优化---Trace工具分析代码(application)执行时间_trace32测试代码执行时间
当前位置: article > 正文
全网首发,Llama3 实测 RTX 4090 性能_4090 llama3
作者:一键难忘520 | 2024-07-09 18:57:14
赞
踩
4090 llama3
前言
自从 Llama3 模型发布以来,它在多个领域引起了极大的关注,并激发了众多基于该模型的演示应用程序的开发。这些应用程序的表现和效果不仅依赖于 Llama3 模型自身的对话能力、逻辑推理和上下文理解等核心特性,而且在实际部署和运行中,它们的表现也极大地受到计算资源的制约。
在现实世界的应用场景中,一定规模的语言模型,尤其是像 Llama3 这样复杂的模型,需要大量的计算资源来支持其运行。这包括但不限于处理能力(CPU 或 GPU)、内存、存储空间以及网络带宽。训练一个规模较大的模型,尤其是在深度学习和自然语言处理领域,不可避免地会对这些计算资源提出巨大的需求。
这种对计算资源的高需求不仅增加了经济成本,也带来了一系列工程上的挑战。例如,为了有效地训练和部署这些模型,需要设计高效的算法来优化资源使用,开发更强大的硬件加速器,以及构建更健壮的分布式计算系统。此外,还需要考虑模型的可扩展性和容错性,确保在面对硬件故障或其他意外情况时,模型的训练和应用不会受到太大影响。
测试指标
我们选择了在 LLM 推理领域炙手可热的 4090 作为平台,对 Llama3 在 4090 上的表现进行了详细的测试。
通过控制变量法,以输入/输出长度作为变量,测试 Llama3 在 4090 平台运行时的延时与总吞吐量,以及 QPS 和耗时。
测试结果
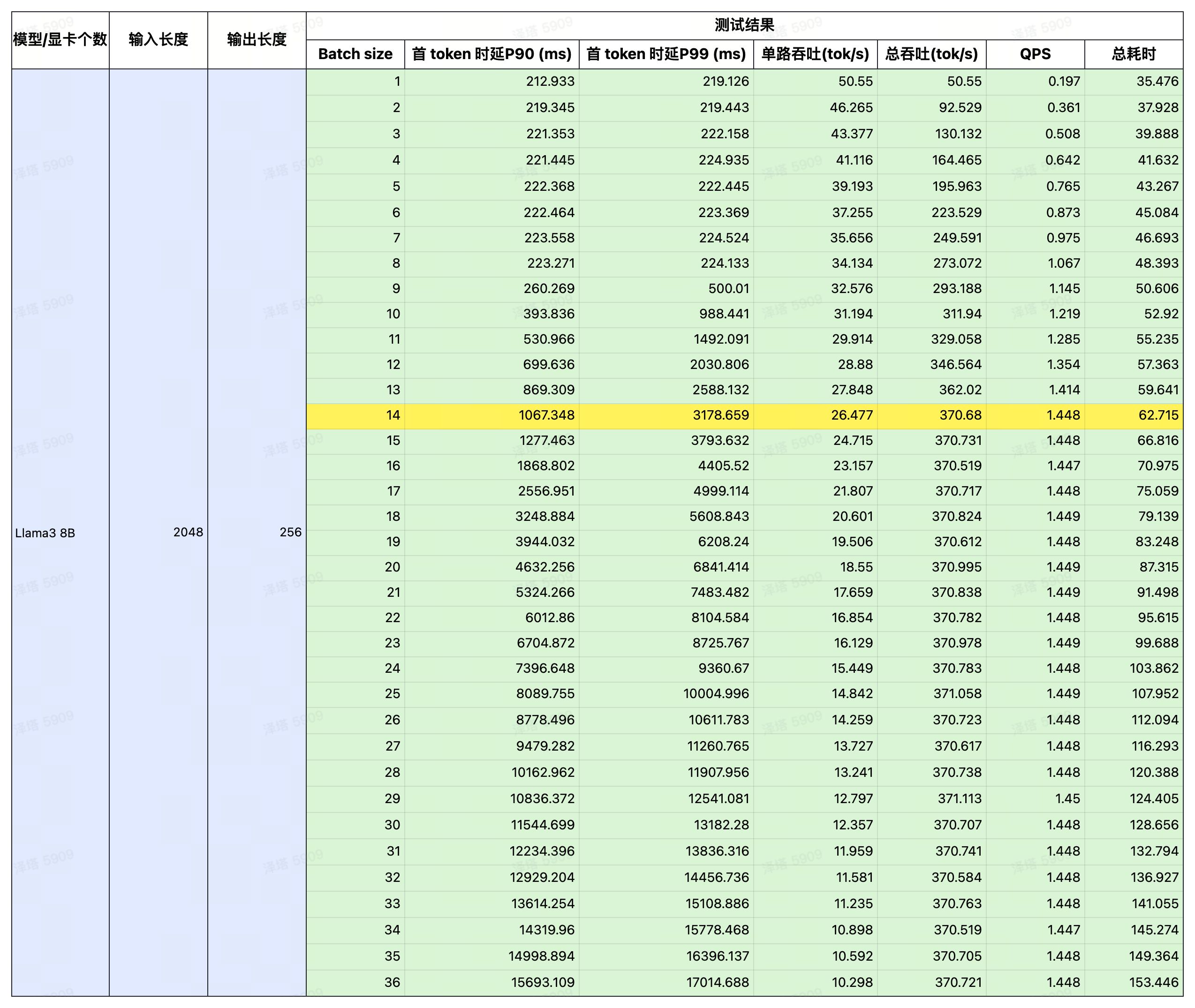
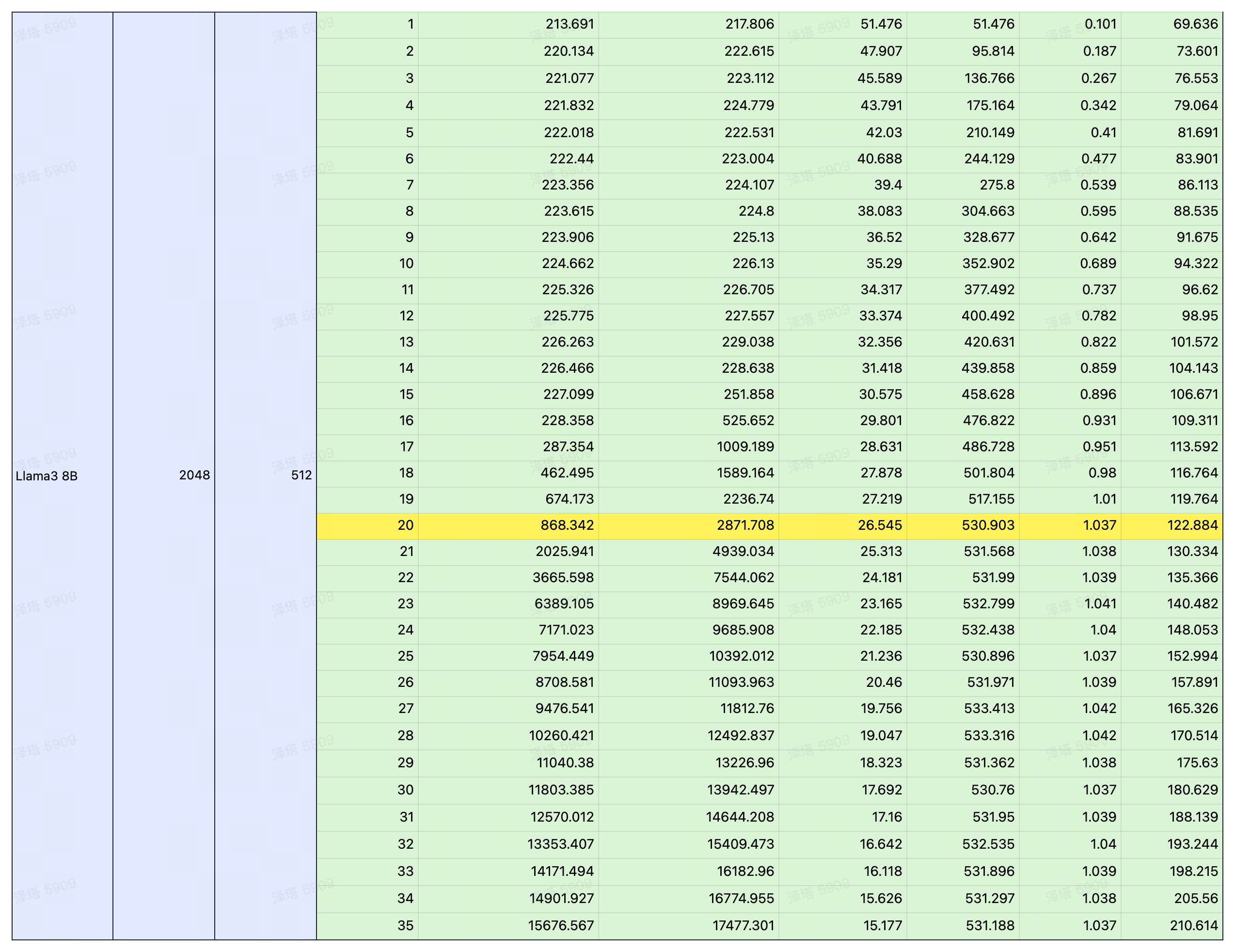
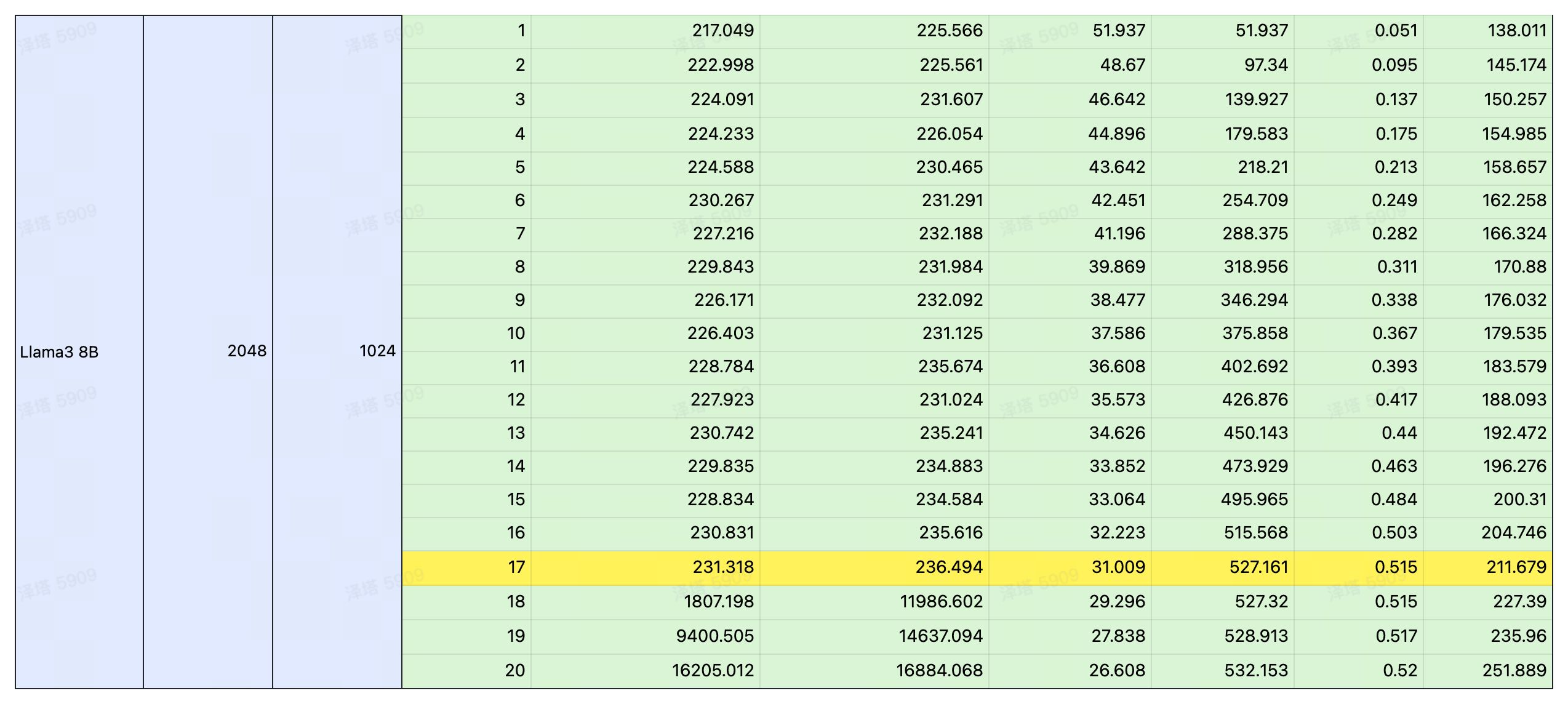
注:黄色部分为性能极限,在此基础上若再增加并发,吞吐量也不会提升。若想获取更详细的数据,请扫码联系。
总结
经过测试,我们将 Llama3 8B 在 4090 平台上的表现总结成这一张图。可以看到在不同 IO 场景下,Llama3 QPS 的极限如何。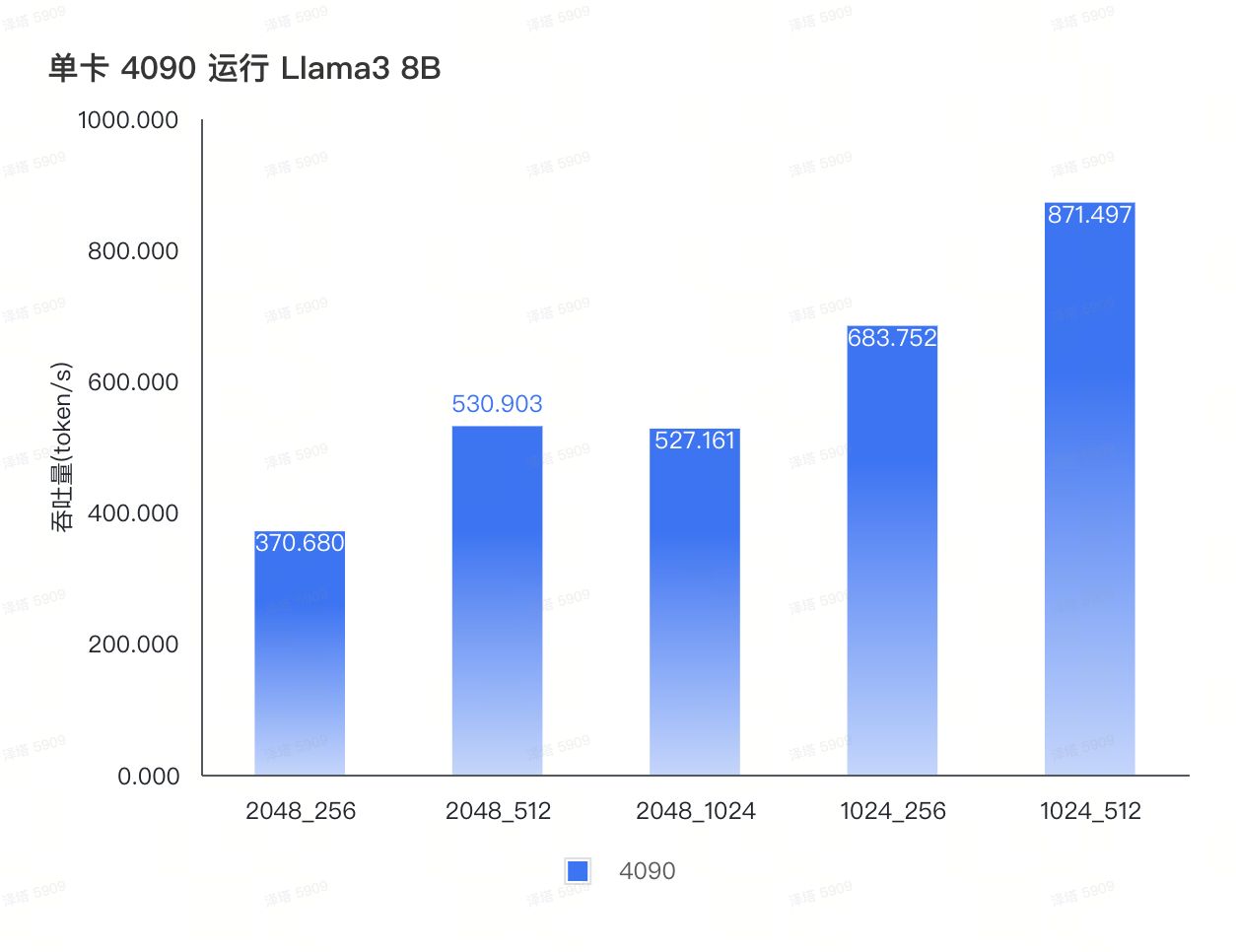
扫描下方二维码,立即试用~

声明:本文内容由网友自发贡献,转载请注明出处:【wpsshop博客】
推荐阅读
相关标签

