- 1Git—版本管理工具_版本管理工具介绍——git篇
- 2全国产的香橙派 AIpro AI开发硬件,对标nvidia jetson硬件。太香了_香橙派 百度飞桨
- 3手把手教你用LoRA训练自己的Stable Diffusion模型_stable diffusion lora
- 4KafKa 详细讲解_kafka发布订阅模式
- 5npm怎么设置超时时间_npm 设置超时时间
- 6【面试题】Golang 自动垃圾回收机制细节(第六篇)
- 7铁路防护RFID锁控系统设计解决方案_rfid防护
- 8go生成uuid_guuid
- 9如何评估媒体邀约宣传的效果
- 10“Unity 输入变得简单:触摸事件和鼠标交互指南”_unity onmousedown
自然语言处理 (第6 7课 神经网络与语言模型)_基于fnn的语言模型
赞
踩
一、学习目标
1.学习前馈神经网络实现语言模型
2.学习循环神经网络实现语言模型
3.长短时记忆网络
4.自注意力神经网络的语言模型
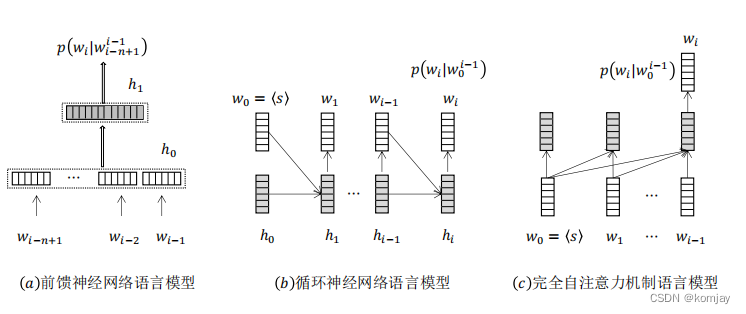
二、前馈神经网络(FNN)
1.前馈神经网络与n元文法模型的关系:
前馈神经网络就是使用神经网络技术实现n元文法模型的产物。故先回顾一下n元文法模型,每个词的出现的概率由其前n个词语决定,一个句子的概率就是所有词的累乘:
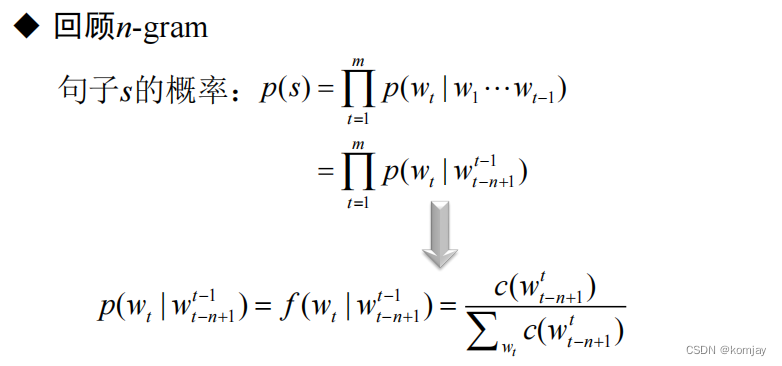
在前馈神经网络中,词的表示使用词向量来表示(词向量在后面会讲),我们在优化网络时,我们的词的词向量也会进行优化,准则就是用前n个词语来优化。
2.词向量:
如果我们有一个语料库,想想我们该如何表示他们从而让电脑认识。实际上,我们需要先建立一个词典,包含所有的词,神经网络是不能以词作为输入输出的,于是我们只能输入输出词在词典中的序号。转换为向量的话,就是:如果有n个词,那我们设置n维向量,当前词是一个第i个,则其n维向量的第i位为1,其他位为0。n维向量就是词向量,而这种编码方式就是我们的one-hot编码:

显然这种办法问题很多,主要有两个:
(1)任意两个词之间都无法进行相似度计算,这是不合理的,显然地,枯燥和乏味两个词是很相似的;
(2)维度太高,如果我们的词语太多,我们的n维向量那可太大了,占用计算机资源就太多了。
于是,我们想建立下图这样的词向量:
(1)维度低,向量种的每个元素是连续的,而不是0-1的;
(2)相似的词是聚集在一块的。
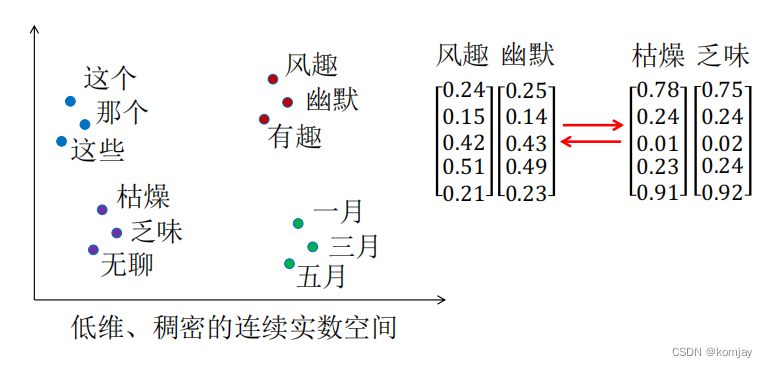
这就是我们前馈神经网络的任务,原理是:用前n个词语的词向量来确定当前词的词向量。
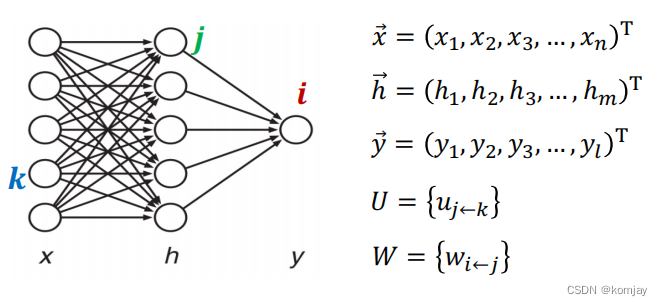
3.前馈神经网络的成员:
在了解整体运行过程前,我们先了解一下前馈神经网络的成员,或者说计算步骤
(1)输入层x:在FNN中,我们将前n个词的词向量统合到一个向量中,作为x。
隐藏层h:对x进行线性组合得到的输出
输出层y:对h进行线性组合得到的输出
第一层参数U:对x进行线性组合的参数
第二层参数W:对h进行线性组合的参数
(2)计算:
线性组合:我们看h层的第一元素h1,x层所有的元素都会指向它,原理就是:对这些元素使用u进行加权后,在累计加和到h1中,同理也可求解hj和yi。
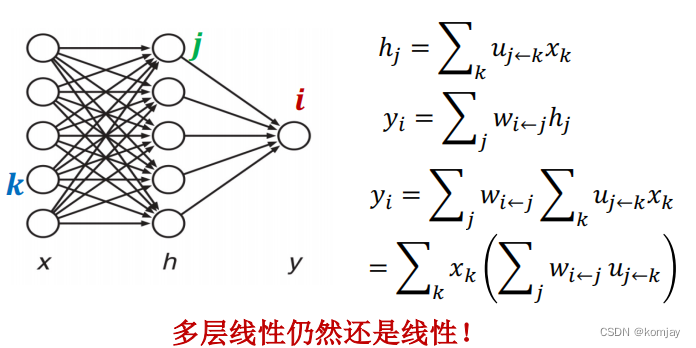
非线性函数激活:我么得到h1后,并不是直接再将h进行线性组合得到y,而是输入到一个f函数中:
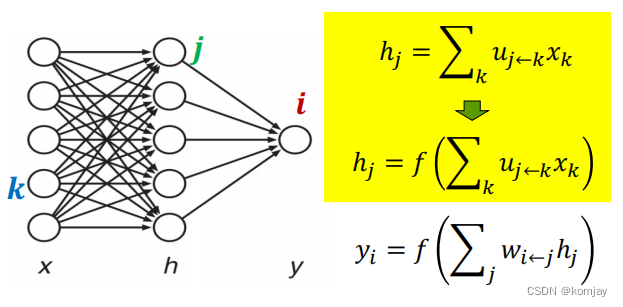
那f函数是什么?是非线性激活函数,常用的激活函数有:(这些激活函数都有些特性,我们直接用就行)

4.前向计算
我们以一个例子来讲一下:
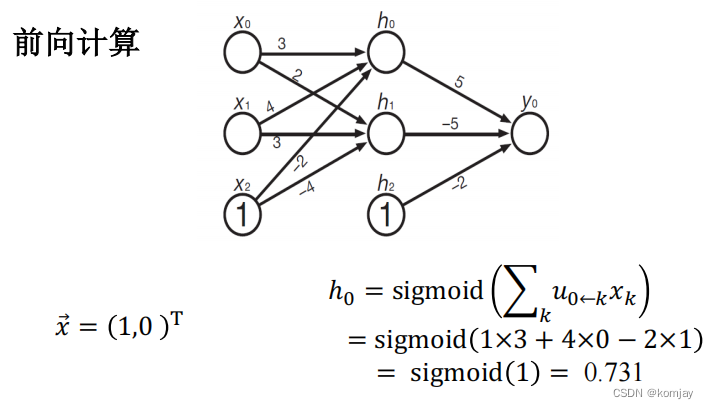
x层是输入层,包含3个元素,x0和x1根据数据输入,x2恒为1,网络中的数字代表网络参数U和W,用于线性组合计算,选用的激活函数是sigmoid函数,最后输出y可以先认为是一个得分(区间是0~1)。左下是计算h0的过程。
最后可得结果(黄色部分):
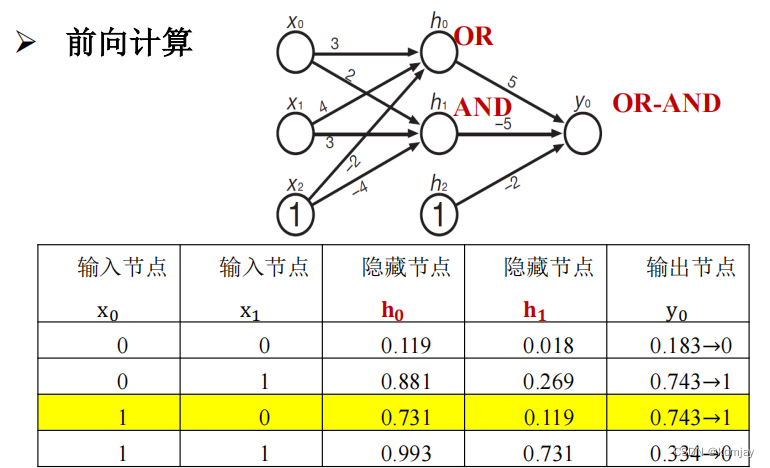
代入别的数据x,可以发现这是一个异或计算器。
5.反向传播:
反向传播的目标是调整网络中的线性组合参数,即U和W。首先先看几个数据:
yi是最后输出(由于输出层只有一个节点)y=yi;
s是对h线性组合计算结果;
yi是对si的取sigmoid。这个yi就是第一条式子的yi;
E是计算误差的式子,ti是真实值,yi是预测值,计算二者的平方误差,这里的累加是合理写法,因为实际网络输出层包含多个节点,这里的输出层只有一个节点,比较特殊。
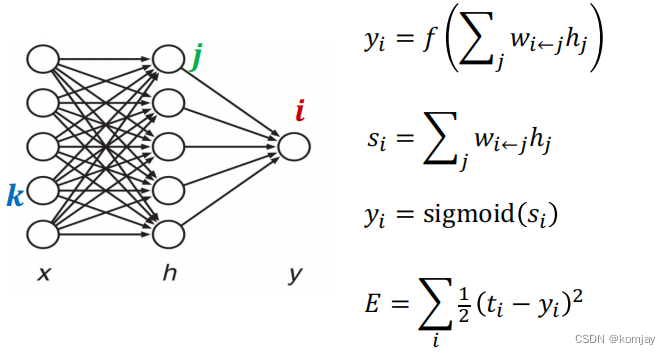
我们误差用E来计算,我们要调整的参数是w,于是我们对E求w的偏导(黄色部分,运用的链式法则):
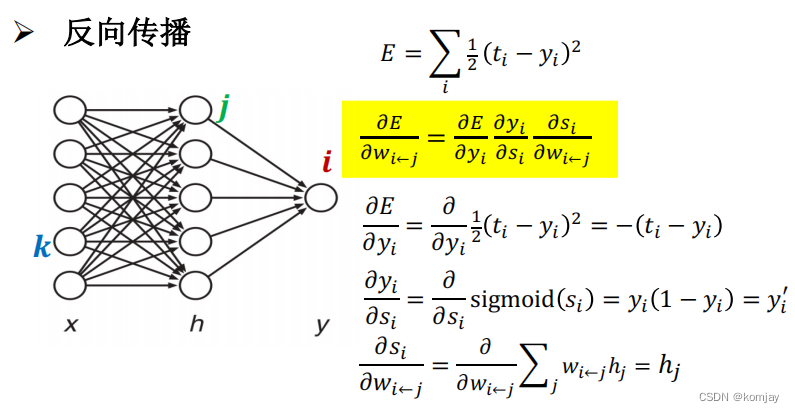
我们也能算出最后的结果(黄色部分):
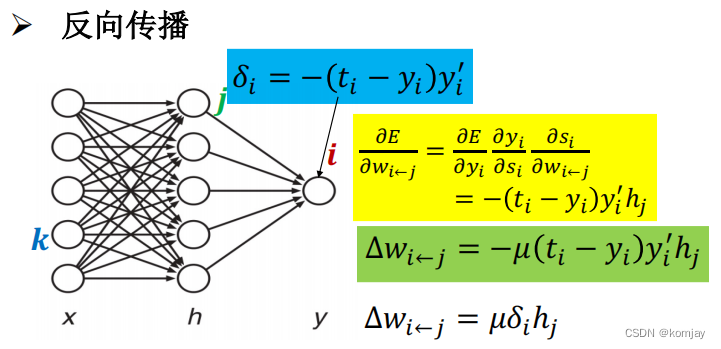
这就是我们梯度,然后我们设置学习率μ来控制w的变化速度(绿色部分),于是新的w=w-Δw。蓝色部分用δ来代替这部分是为了方便计算后面层的参数u的优化。
对u的参数进行优化,也可得到调整的步长:
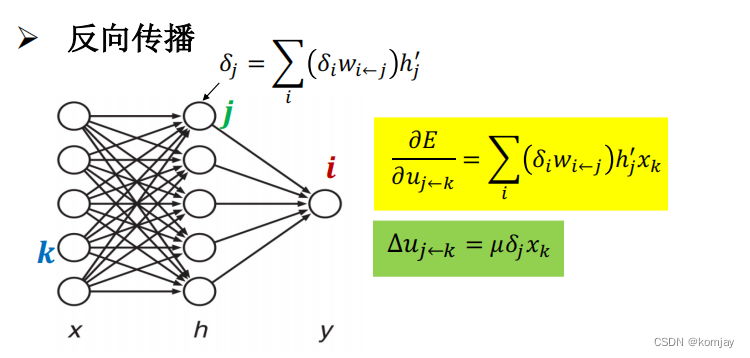
6.FNN语言模型
(1)look-up表:
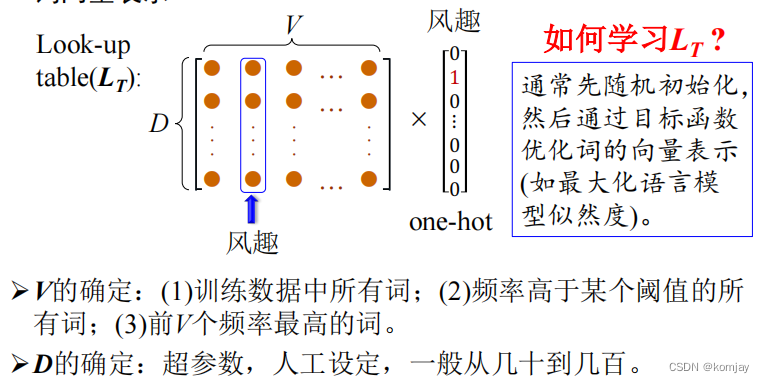
look-up表实际上就是所有单词的词向量的表,一开始时是随机生成的,后面会通过模型进行优化。
(2)FNN语言模型前向过程:
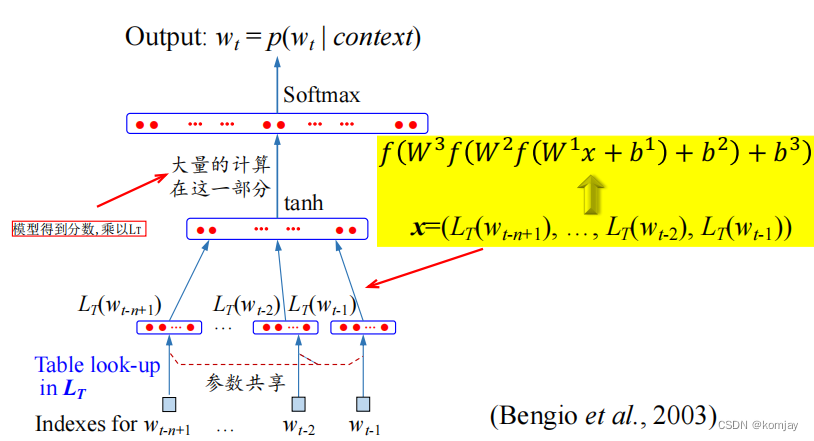
首先了解我们的目标是什么:我们输入前n个词语,即content,最后输出最高概率的wt作为下个词与。
然后从下往上看,最底层是content中各词的序号,通过look-up表,得到词向量,所有向量进行拼接,得到一个整合的向量。之后使用神经网络得到输出分数。再之后将分数乘look-up表,得到n维向量,是所有词的最终得分,通过softmax将这些分数归一化到0-1的区间内,得到最后概率。选择概率最高的词作为我们的输出。
(3)例子说明:
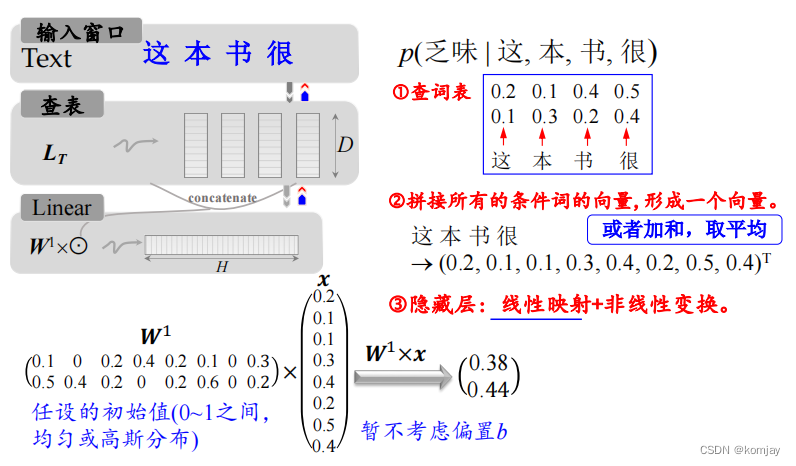
假设我们的look-up表是一个2x5000的矩阵,即有5000个单词,每个词用二维词向量来表示,然后我们要求“这本书很”之后是“乏味”的概率:

然后通过查词表、拼接,进行线性计算,得到一个二维结果:
再进行非线性变换:
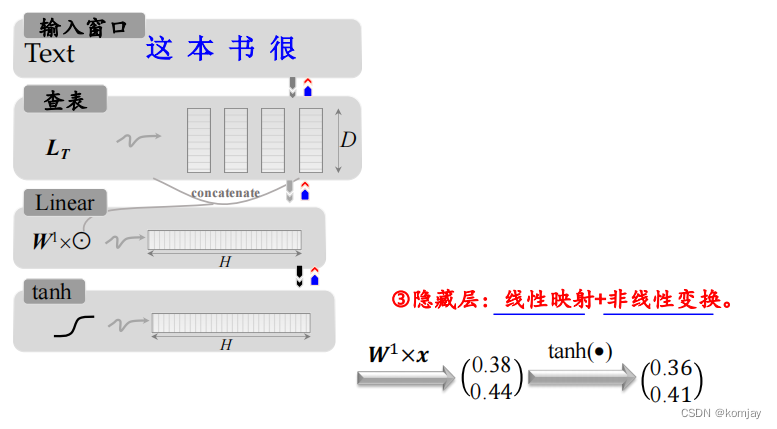
最后得到(0.36,0.41)其实该包有一定含义:由于我们的单词用两位数据来表示,得到的二维数据说明词向量两个维度的权重。于是我们乘上look-up表得到各个词的分数:

得到的分数实际上就可以来判断下个词是哪个词更合理,但为了标准化,我们使用softmax对其进行归一化,使分数变成概率。这样,我们不仅可以求解出“乏味”出现的概率,所有词的概率都能得到。如果判断对了,那自然是好,如果判断错了,就可以通过反向传播更新模型参数。
7.总结
至此,我们讲完了FNN模型在语言模型的应用。那么这样的模型有没有什么弊端?显然是有的:因为每次取前n个单词作为输入,这样的历史信息太少。例如“这本书太枯燥了,实在是太乏味了”,“枯燥”和“乏味”两次是很相关的,但我们使用4元文法模型时,“乏味”却无法与“枯燥”联系上。
于是我们思考,能不能对所有的历史信息进行建模?这就是循环神经网络RNN。
二、循环神经网络(RNN)
1.RNN的构成与前向计算过程:
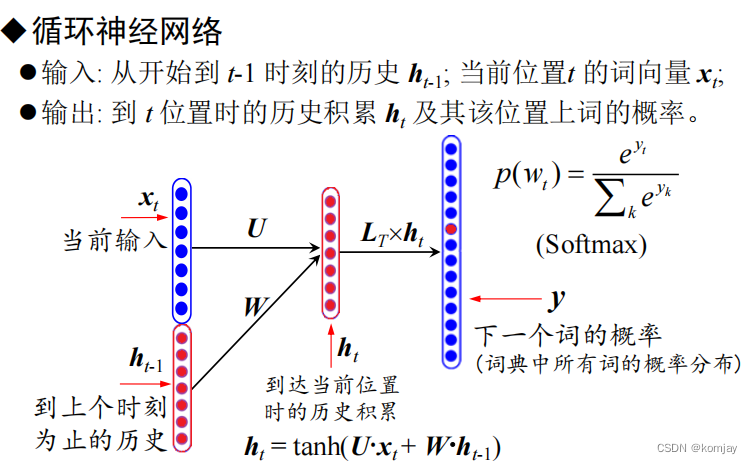
相比于FNN,RNN多了一个ht,其包含的信息是前t的词的信息累计,即历史信息。我们的模型参数也就有了两个部分,W是对h进行线性组合,U是对x的线性组合,二者合并再选择tanh作为激活函数生成当前时刻的信息总和。最后,统计完所有历史信息后用这个信息进行计算概率。
2.反向传递计算过程:随时间反向传播算法(BPTT)
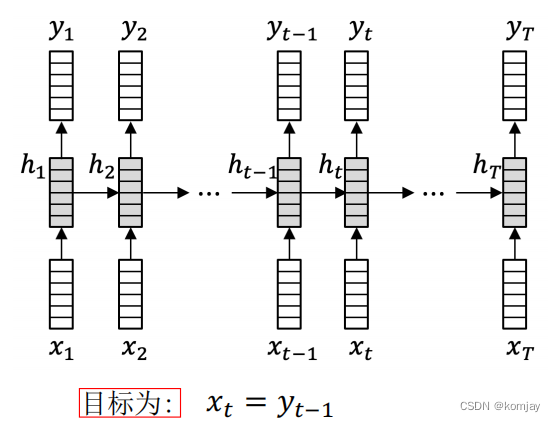
对于每个时刻的历史信息,我们都可以计算出其对下个词的预测即Yt。所以,我们的目标就是让Yt等于Xt+1,优化的对象是W和U。
(ps. 与FNN一样,我们首先要确定我们的损失函数,计算误差值有多少,然后求损失函数对W的偏导数,对U的偏导数,最后用学习率作为步长让W和U沿梯度下降方向变化,最终迭代多步使损失值最小。)
接下来就是先确定损失函数:

首先要了解清楚,我们的模型最后输出的是一个n维向量,n为单词总数,n维向量里的元素代表下个单词的概率,即公式中的p(g(ht)c)。观察公式,可以知道损失函数类似于计算信息熵,整体是大于0的,当损失下降时,p(g(ht)c)在不断提升,这符合我们的认知。
接下来就是寻找梯度下降方向,从而我们可以通过迭代,使模型不断优化。寻找下降方向就是对损失函数求偏导:

由于我们要优化的是W,就是用W求L的偏导,采用链式法则进行展开,然后分成三个部分,分别求解,前两个是好求解的,原公式为:
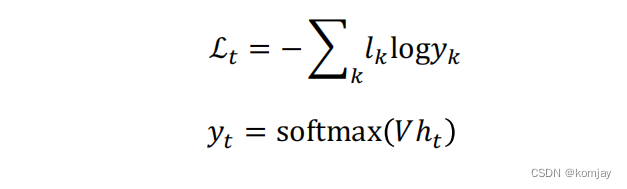
关键是求解第三部分,首先,可以先写成以下形式:
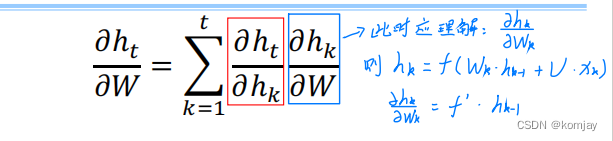
其中蓝色部分也是好求的,即剩下红色部分,由于ht的原始公式里不一定有hk,所以还是要使用链式法则:

整合所有部分,就得到我们最后的梯度下降方向:
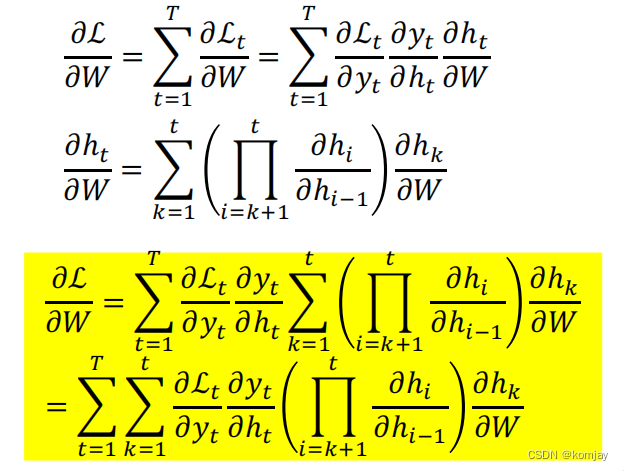
于是我们就可以更新新的模型参数(η是学习率):
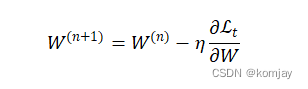
同理,我们对U模型参数也是如此,其梯度下降方向为:
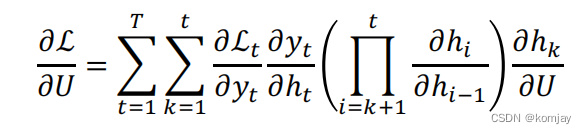
3.总结
通过了解RNN模型的前向计算过程和反向传递过程,我们的模型可以实现读取所有的历史信息,以预测下一个词是什么,而这样的模型也存在着问题,那就是梯度爆炸和梯度消失的问题,例如,当我们预测第100个词时,我们第一个词的信息已经乘上了1次U矩阵和99次的W矩阵,如果W矩阵小于1,那么这个词的信息会接近于0(梯度消失),如果W矩阵大于1,那么这个词的信息会越来越大(梯度爆炸)。(有人会疑惑,梯度不是反向才有吗?是的,以上是从前向来说明,反向也是有这样的问题,总结而言就是次方数太多导致的)
于是我们想让模型可以记住一些词,但避免这些信息被乘上多次W。前人提出了长短时记忆网络LSTM(Long-Short-Term-Memory)。
三、长短时记忆网络(LSTM)
1.我们这里只简单讲一下LSTM的几个结构和作用,具体的运行过程就不详述了。网络结构如下:
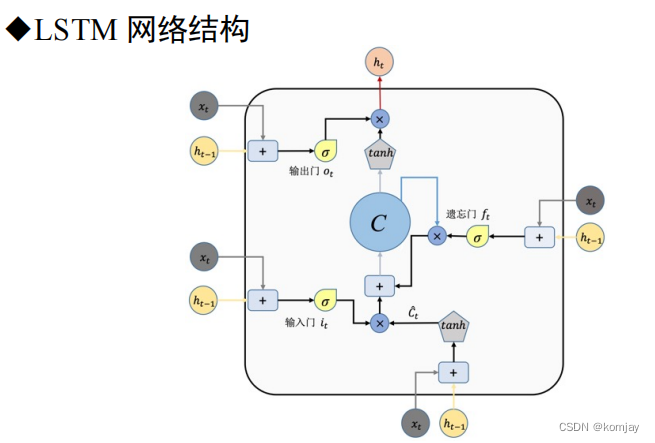
这里我们发现,有好几个xt和ht-1,实际上是同一个,而唯一的输出就是ht,这个ht与RNN的ht同理,主要的不同在于:RNN只有两个参数W和U,而在LSTM中,定义了遗忘门、输入门、输出门,每个门有一个模型参数,从而实现关注主要单词的能力。也可以知道,这个网络结构就是RNN的一个步骤,一个记忆单元。
2.遗忘门:
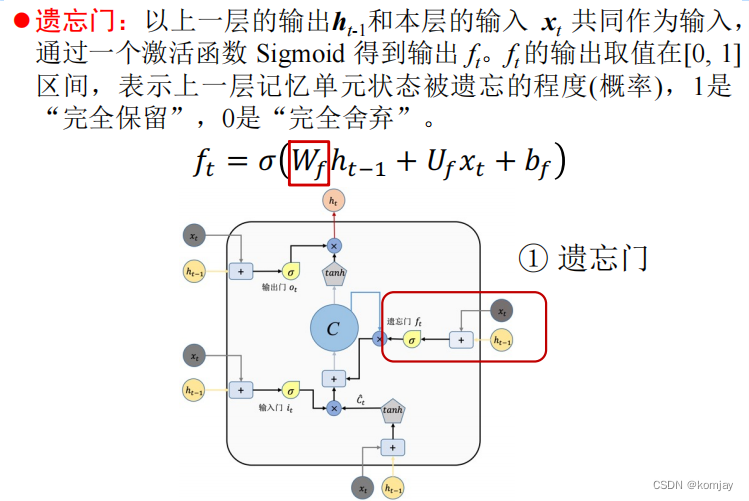
Wf、Uf、bf就是遗忘门的权重,其作用就是控制遗忘上一层记忆单元的程度。
3.输入门:
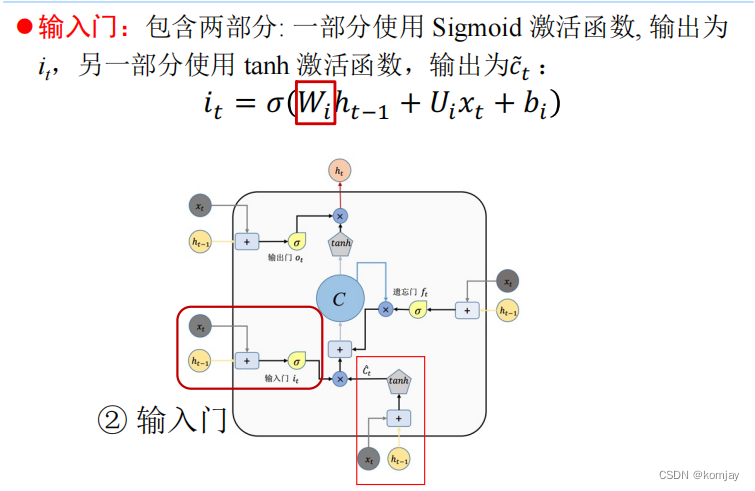
输入门由两部分构成,两部分大体相同,只有参数和激活函数不同(不如说,所有的门都是大体相同,只是参数不同,激活函数有两类)。
4.输出门:
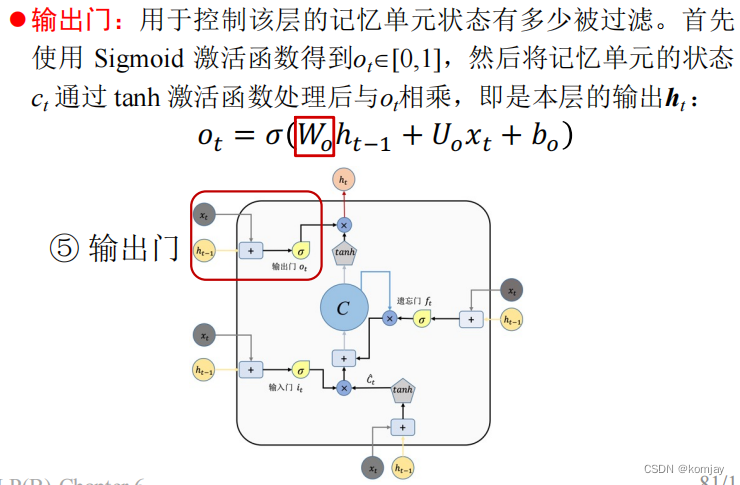
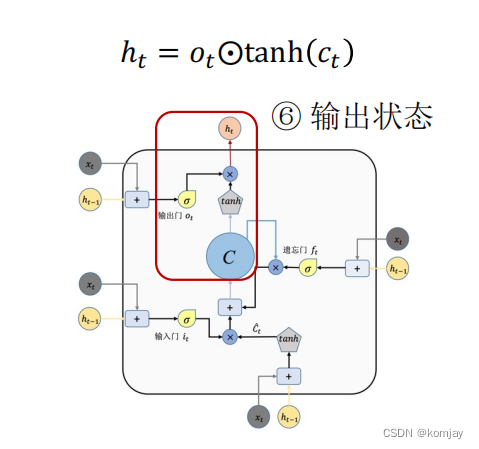
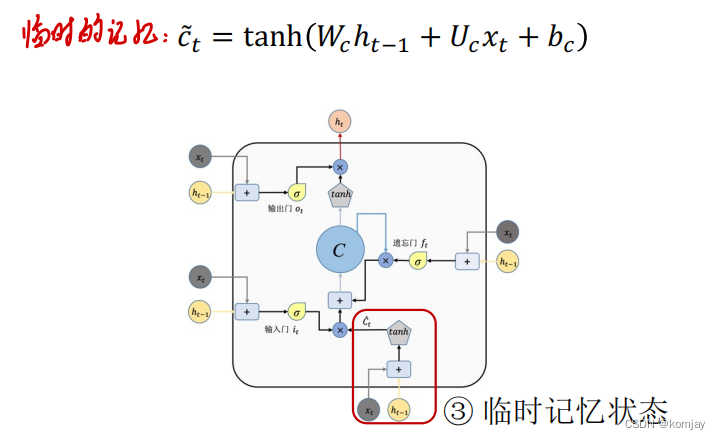
大体的结构的计算过程都是一样,原本RNN的两个参数变成LSTM的4对参数(b这个参数表示进U中)。于是我们记忆单元计算过程如下:
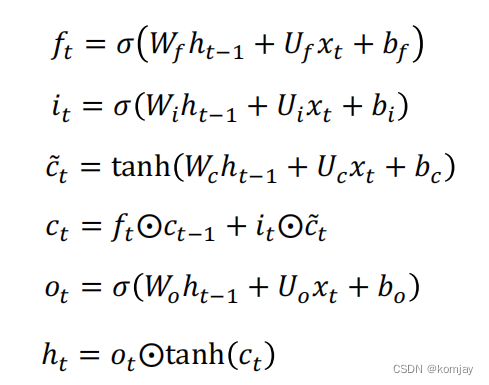
5.我们最关注的是,LSTM能不能帮助我们解决梯度爆炸和梯度消失的问题。RNN的梯度爆炸和梯度消失的问题出现在黄色部分中:
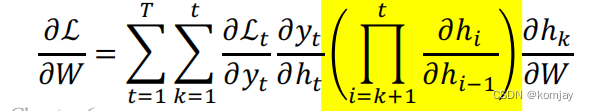
LSTM中的ct是相当于RNN中的ct,我们写出其公式和求导结果:
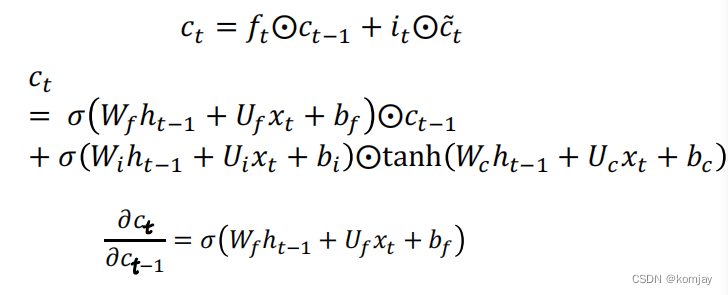
可以发现:

LSTM的反向传递过程比RNN麻烦得多,这里就不详述了。那么LSTM有没有问题呢?显然是有的,举个例子,一个句子100个词,我要预测第100个词是什么,人扫了一眼发现第一个词是最关键的,而LSTM也能做到这一步,但为了记住这第一个词,它会把后面的98个词都遗忘掉才行(不然就会退化成RNN)。显然,这是不合理的。
于是我希望有个模型有选择性地记忆哪些单词,记忆的比重是多少的模型,前人提出了自注意力神经语言模型(self-attention Neural Language Model)。
四、自注意力神经语言模型
1.自注意力的机制相比于前几个就更为抽象了,建议大家就不要纠结其中原理,了解其计算步骤即可。具体内容后续课程会细讲。
2.用一个例子来讲解其流程:
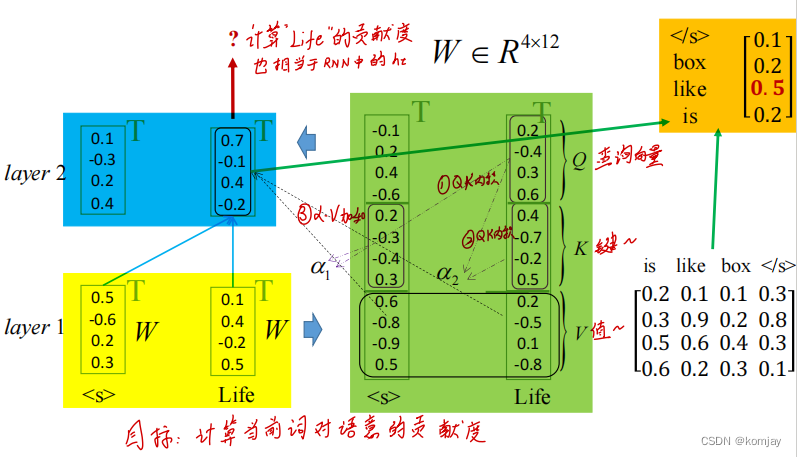
总体的流程是黄->绿->蓝->橙。我们目前的输入是“< s > Life”,我们要预测下一个词是什么。
(1)黄色是两个词的初始词向量,使用三个矩阵Wq,Wk,Wv(这就是我们的模型参数)将词向量转化为3个向量Q,K,V三个向量,绿色部分。
(2)绿色部分是使用词之间的三个向量进行计算,计算步骤标注在图中,从而得到蓝色部分。
(3)通过蓝色的得分,与词向量表点乘,计算出各个词的得分,即橙色部分。挑选分数最大作为下一个词。
3.见上图,只有一层计算,显然,我们layer 2的输出还可以进行layer 1的计算。从而实现多层堆叠
4.多头自注意力机制:由于我们的模型参数只有Wq,Wk,Wv三个,显然,我们可以设计多组模型参数,由于语言模型的不确定性,我们可能迭代出多个不同模型参数,从而将这多组模型参数称为头,在确定最后的输出时,我们就有多个依据。而这样的设计,使得语言模型也能使用类似CNN的效果,不同的头就像CNN的卷积核,这也是为什么现在的语言模型都在使用自注意力机制。GPT-4用的原理也是自注意力机制,只是它的头非常多,模型参数非常大,于是又称:大模型。
五、本章小结