
- 1软件测试面试八股文——基础篇
- 2面试官:Zookeeper是什么,它有什么特性与使用场景?,java高级面试题和答案_zk的使用场景是什么?面试
- 3python:实现 canny边缘检测算法(附完整源码)_canny边缘检测算法python30行
- 4架构揭秘:「东方证券」业务中台架构探索_基金公司+产品中心+系统建设+架构
- 5http请求和http响应详细解析
- 6MySQL运维09-慢查询日志_mysql 慢查询日志配置
- 7解析 NSS 错误 -5938 (PR_END_OF_FILE_ERROR)_pr end of file error
- 8大突破!本地大模型接入微软Autogen,多专家Agent共事成现实!支持llama2+chatglm,附代码!_llm agent可本地化
- 9学习Spring基础知识_spring学习要多久
- 10[Python]以下哪个方式可以创建一个空的集合?A.set()B.{}C.[]D.() 已知:s=set(‘abcd‘),向集合对象s中增加新元素,不可以采用哪些形式( )。A.s.add(‘ef‘_以下哪个指令能建立一个集合( )。
EfficientVMamba
赞
踩
本文提出了EfficientVMamba,一种轻量级的状态空间网络架构,它巧妙地结合了全局和局部信息提取的优势,解决了模型准确性与计算效率之间的权衡问题。通过融合基于扩张的的选择性扫描和有效的跳跃采样,EfficientVMamba确保了全面的全局感受野覆盖,同时最小化计算负担。

具体来说,Efficient-VMamba通过有效的跳过采样,集成了基于空洞的选择性扫描方法,这些构成了旨在利用全局和局部表现特征的构建块。此外,作者还研究了SSM块与卷积的结合,并引入了一种结合了附加卷积分支的高效视觉状态空间块,进一步提升了模型性能。
实验结果表明,EfficientVMamba在降低计算复杂度的同时,在各种视觉任务上取得了具有竞争力的结果。例如,具有1.3G FLOPs的Efficient-VMamba-S,在ImageNet上将 1.5G FLOPs的Vim-Ti的准确度提高了5.6%。
自从AlexNet被提出以来,深度神经网络在计算机视觉领域取得了重大突破。然而,这些模型通常比较重,需要大量的计算资源。为了解决这个问题,对于计算能力有限的实际应用来说,轻量级架构至关重要。在本文中,作者提出了一种基于状态空间模型的效能网络,旨在平衡准确性和计算效率。
代码:https://github.com/TerryPei/EfficientVMamba
1 Introduction
卷积网络,如ResNet,Inception,EfficientNet等模型,以及基于Transformer的网络,例如Swin-Transformer,Beit,和Resformer,已被广泛应用于视觉任务中,包括图像分类、检测和分割,取得了显著成果。最近,Mamba,一种基于状态空间模型(SSMs)的网络,在诸如语言建模的序列建模任务中展示了与Transformers相媲美的性能。受到这一启发,一些工作开创性地将SSMs引入到视觉任务中。在这些方法中,Vmamba 通过引入一种SS2D方法,从多个方向扫描图像以保持2D空间依赖性,从而脱颖而出。
然而,这些不同架构所实现的令人印象深刻的性能通常来自于模型规模的扩大,这在资源受限的设备上应用它们构成了一个关键挑战。为了追求轻量级模型,许多研究致力于在保持有竞争力的性能的同时减少视觉模型的资源消耗。早期关于高效卷积神经网络(CNNs)的工作主要集中于使用有效的组卷积,轻量级跳跃连接等方法来简化原始的卷积块。

在本文中,回顾了之前提到的SSMs中的线性缩放复杂度,作者受到启发,通过将SSMs融入模型设计中,以在轻量级视觉模型中获取高效的全球捕获能力。其卓越性能在图1中得到了展示。作者通过首先引入跳过采样机制实现这一点,该机制减少了在空间维度上需要扫描的标记数量,并在保持标记间的全局感受野的同时,节省了SSMs序列建模中的多次计算成本,如图2所示。
 另一方面,考虑到卷积在只需要局部表示的情况下提供了更高效的特征提取方式,作者在原有的全局SSM分支旁边增加了一个卷积分支,并通过通道注意力模块SE对它们进行特征融合。最后,为了合理分配各种块类型的能力,作者在浅层和高分辨率层构建全局SSM块,而在深层采用高效的卷积块(MobileNetV2块)。通过在图像分类、目标检测和语义分割任务上的实验,最终的网络的效率SSM计算和卷积的有效整合,与之前的基于CNN和ViT的轻量级模型相比,展示了显著的改进。
另一方面,考虑到卷积在只需要局部表示的情况下提供了更高效的特征提取方式,作者在原有的全局SSM分支旁边增加了一个卷积分支,并通过通道注意力模块SE对它们进行特征融合。最后,为了合理分配各种块类型的能力,作者在浅层和高分辨率层构建全局SSM块,而在深层采用高效的卷积块(MobileNetV2块)。通过在图像分类、目标检测和语义分割任务上的实验,最终的网络的效率SSM计算和卷积的有效整合,与之前的基于CNN和ViT的轻量级模型相比,展示了显著的改进。


作者引入了一个双路径模块,它结合了作者的高效扫描策略以捕获全局特征以及一个卷积分支以高效提取局部特征,并搭配一个通道注意力模块来平衡全局特征与局部特征的融合。此外,作者提出了一种更优的SSM和CNN块分配方式,即在早期高分辨率阶段推广使用SSM以实现更好的全局捕获,而在低分辨率阶段采用CNN以提高效率。
作者在图像分类、目标检测和语义分割任务上进行了大量实验。图1中展示的结果和图解表明,EfficientVMamba有效地减少了模型的FLOPs,同时与现有的轻量级模型相比,取得了显著的性能提升。
2 Related Work
Light-weight Vision Models
近年来,视觉任务领域主要由卷积神经网络(CNNs)和视觉Transformer(ViT)架构主导。将这些架构轻量化以提升效率的研究方向已成为实际且充满前景的途径。对于CNNs来说,在提高图像分类准确度方面已取得了显著进展,如ResNet,RegNet,DenseNet等有影响力的架构的发展所示。这些进展不仅在准确性上设定了新基准,同时也提出了对轻量化架构的需求。这种需求通过基于因式分解的各种方法得到了解决,使得CNNs更加适合移动设备。
例如,Xception引入的可分离卷积在这方面起了重要作用,促成了如MobileNets,ShuffleNetv2,ESPNetv2,MixConv,MNASNet,和GhostNets等先进的轻量级CNN的发展。这些模型不仅用途广泛,而且相对容易训练。在CNN之后,Transformers在诸如图像分类、目标检测和自动驾驶等视觉任务中获得了显著的关注,迅速成为主流方法。
Transformers的轻量化版本是通过多种方法实现的。在训练方面,采用了复杂的数据增强策略和技术,如Mixup,CutMix和RandAugment,这在CaiT和DeiT-III等模型中可以看到,它们在不依赖大型专有数据集的情况下展示了卓越的性能。从架构设计角度来看,努力集中在优化自注意力输入分辨率和设计计算成本较低的关注机制上。诸如PVT-v1模仿CNN的特征图金字塔,Swin-T和LightViT的分层特征图和移位窗口机制,以及在Deformable DETR中引入(多尺度)可变形注意力模块等创新,都是这些进展的例证。还有针对ViTs的NAS。
State Space Models
状态空间模型(SSM)是一系列架构的集合,它封装了一种序列到序列的转换,有潜力处理具有长依赖关系的标记,但由于其计算量和内存使用较高,训练起来具有挑战性。然而,近年来的研究使深度状态空间模型逐渐与CNN和Transformer竞争。特别是,S4采用了一种正常加低秩(NPLR)表示,通过利用Woodbury恒等式进行矩阵求逆,有效地计算卷积核。然后Mamba 通过输入特定的参数化和可扩展、硬件优化的算法增强了SSM,使得在处理语言和基因组学中的长序列时设计更简单、效率更高。在SSM成功的基础上,应用该框架到计算机视觉任务的研究激增。
S4ND首次将SSM模块引入视觉任务,便于将1D、2D和3D的视觉数据作为连续信号进行建模。Vmamba 开创了一种基于mamba的视觉 Backbone 网络和跨扫描模块,以解决由于1D序列和多通道图像之间的差异引起的方向敏感性问题。同样,Vim 通过利用双向状态空间建模,在没有图像特定偏见的情况下,为视觉任务引入了一种有效的状态空间模型,用于依赖数据的全局视觉上下文。Mamba Backbone 网络在各类视觉任务中的出色表现激发了一系列研究,专注于将基于Mamba的模型适配到特定的视觉应用。
最近的工作如Vm-unet、U-Mamba和SegMamba 已经将基于Mamba的 Backbone 网络适配到了医学图像分割,集成了例如Vm-unet中的U形架构、U-Mamba中的编码器-解码器框架以及SegMamba中的全体积特征建模等独特特性。在图表示的领域,GraphMamba 将图引导的消息传递(GMB)与消息传递神经网络(MPNN)在Graph GPS架构中整合,增强了图嵌入的训练和上下文过滤。此外,GMNs 提出了一种全面的框架,包括标记化、可选的位置或结构编码、局部编码、标记序列化,并使用一系列双向Mamba层处理图。
3 Preliminaries
State Space Models (S4)

Selective State Space Models (S6)
Mamba 通过引入选择性状态空间模型 (S6) 来提高SSM的性能,允许连续参数随输入变化,增强序列间的选择性信息处理,这通过选择机制扩展了离散化过程:

4 Method
为了设计对资源受限设备友好的轻量级模型,作者提出了EfficientVMamba,其总结如图3所示。在4.1节中,作者引入了一种高效的选择性扫描方法来降低计算复杂性,并在4.2节中构建了一个块,该块同时考虑了全局和局部特征提取,集成了SSMs和CNNs。关于架构设计,4.4节深入探讨了针对不同模型尺寸量身定制的各种架构变体。
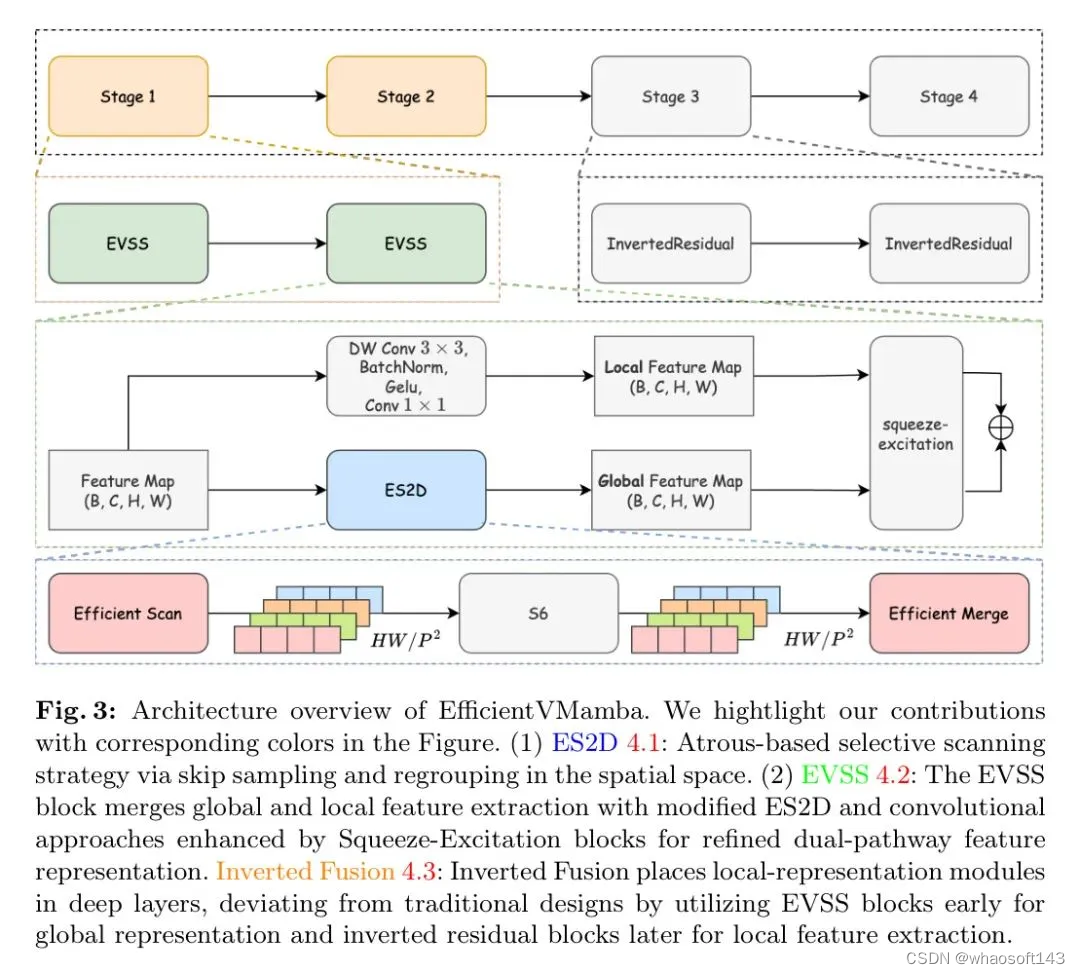
Efficient 2D Scanning (ES2D)
 在ES2D中,对全局空间特征图的重新分组涉及到将处理过的块组合起来,以重建特征图的全局结构。这种整合捕捉到更广泛的上下文信息,平衡特征提取中的局部细节和全局上下文。因此,作者的设计旨在简化扫描和合并模块,同时保持状态空间架构中全局集成的核心优势,目的是确保特征提取在空间轴上保持全面。
在ES2D中,对全局空间特征图的重新分组涉及到将处理过的块组合起来,以重建特征图的全局结构。这种整合捕捉到更广泛的上下文信息,平衡特征提取中的局部细节和全局上下文。因此,作者的设计旨在简化扫描和合并模块,同时保持状态空间架构中全局集成的核心优势,目的是确保特征提取在空间轴上保持全面。
Efficient Visual State Space Block (EVSS)
基于高效选择扫描方法,作者引入了高效视觉状态空间 (EVSS) 块,该块旨在协同融合全局和局部特征表示,同时保持计算效率。它利用一个经SqueezeEdit修改的ES2D来捕获全局信息,并定制了一个卷积分支来提取关键的局部特征,两个分支都会经历随后的SqueezeExcitation (SE) 块。

Inverted Insertion of EfficientNet Blocks

Model Variants
为了充分证明作者提出模型的有效性,作者详细介绍了基于[61]中提到的普通结构所衍生的架构变体。这些变体被命名为EfficientVMamba-T,EfficientVMamba-S和EfficientVMamba-B,如表1所示,分别对应于模型的不同规模。
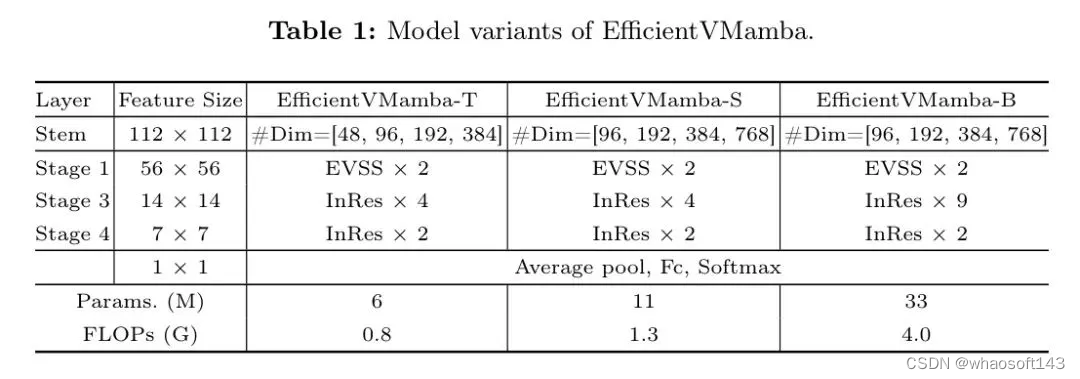
EfficientVMamba-T是最轻量级的,拥有600万参数,其次是拥有1100万参数的EfficientVMamba-S,而EfficientVMamba-B最为复杂,拥有3300万参数。在计算负载方面,以FLOPs衡量,模型的负载呈现出并行增长,EfficientVMamba-T为0.8G,EfficientVMamba-S为1.3G,EfficientVMamba-B为4.0G,这与它们的复杂度和特征大小直接相关。
5 Experiments
为了严格评估作者各种模型变体的性能,作者在第5.1节展示了图像分类任务的成果,在第5.2节探讨了目标检测性能,并在第5.3节探索了图像语义分割。在第5.4节,作者进一步进行了消融研究,全面检验了 atrous 选择性扫描的效果,SSM-Conv融合块的影响,以及将卷积块整合到模型不同阶段的意义。
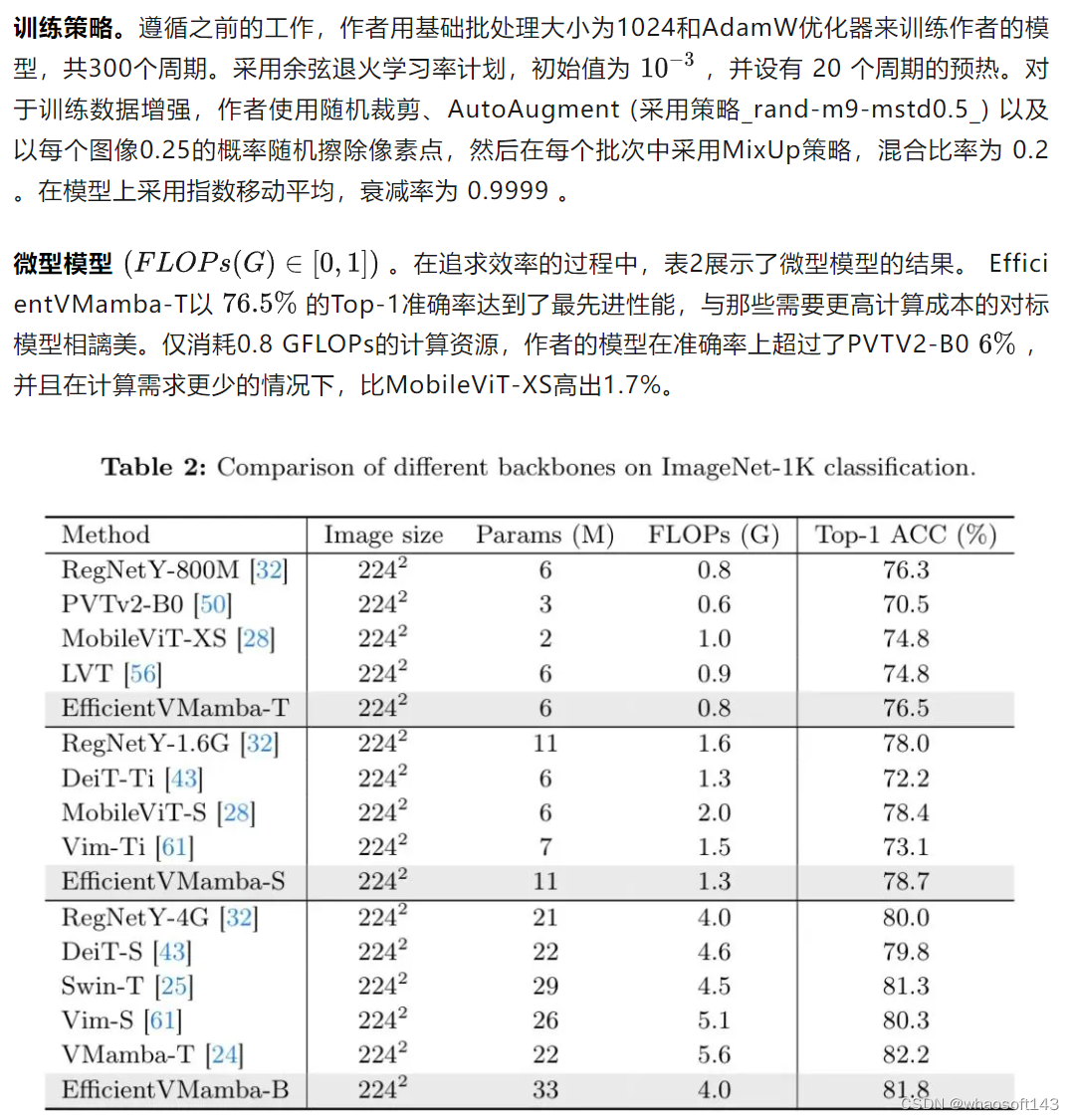
ImageNet Classification

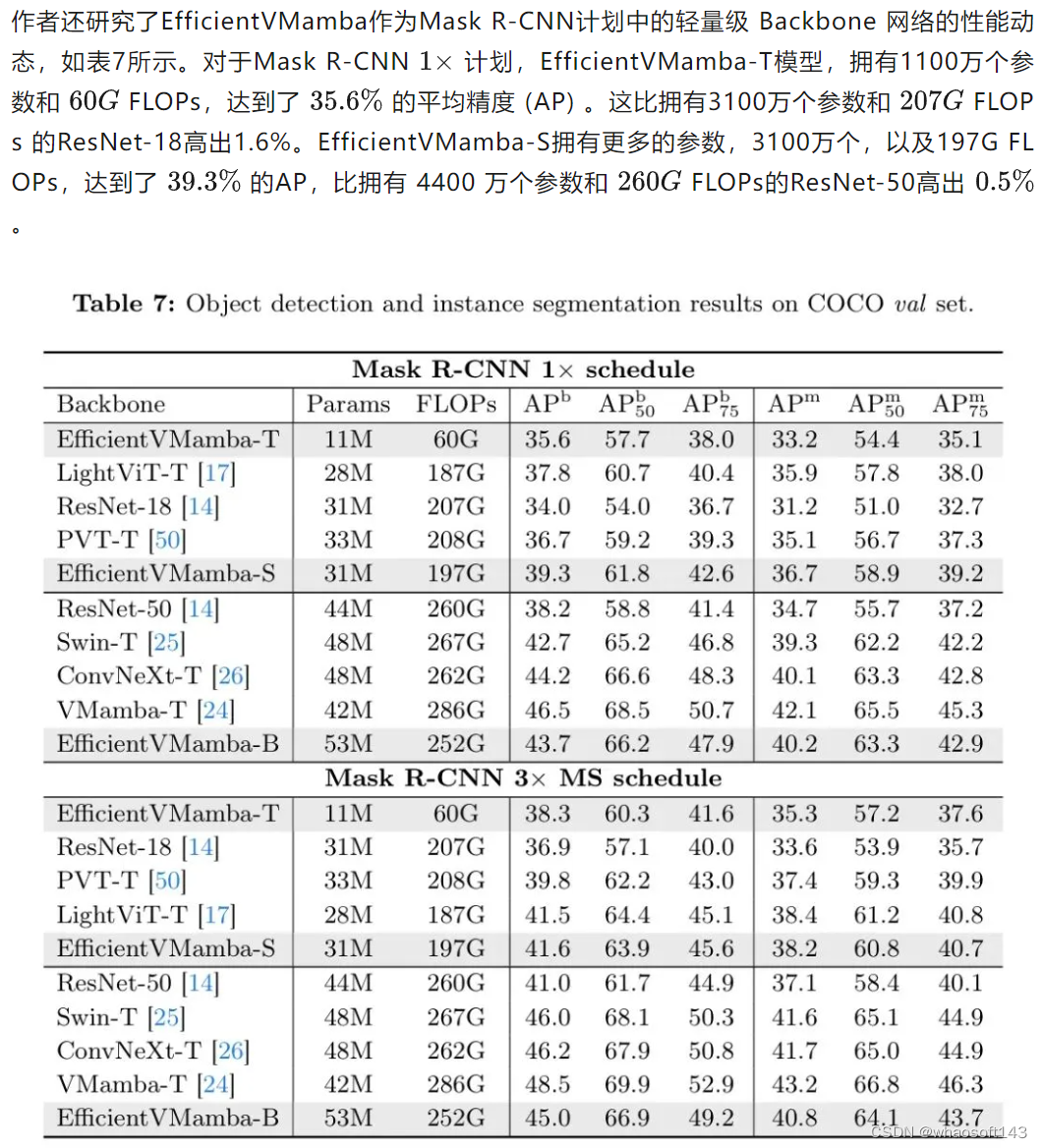
Object Detection

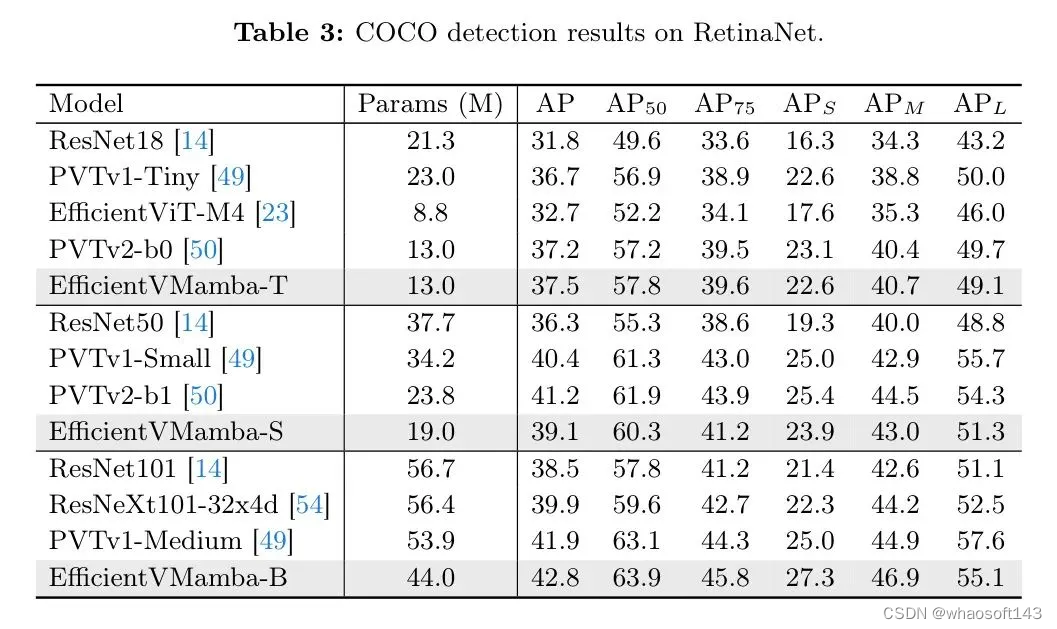
在高层次梯队中,拥有4400万参数的EfficientVMamba-B,获得了42.8%的AP,显著领先于ResNet101和ResNeXt101-32x4d,突显了即使参数量较小,作者的模型的高效性。值得注意的是,拥有1300万参数的PVTv2-b0获得了37.2%的AP,而EfficientVMamba-T紧随其后,这表明在相似的参数预算下具有竞争力的性能。关于与其他 Backbone 网络在Mask R-CNN上的比较,请参见附录。
Semantic Segmentation

Ablation Study
atrous选择性扫描的效果。作者在表5中实施了实验来验证atrous选择性扫描的有效性。从SS2D升级到ES2D显著降低了计算复杂度,从0.8 GFLOPs降低,同时保持了73.6%的竞争力准确度,比微小变体提高了1.5%。同样,在基本变体的情况下,利用ES2D的模型不仅将GFLOPs从VMamba-B的4.2降低到4.0,还显示出准确度从80.2%增加到80.9%。
结果表明,EfficientVMamba模型是通过跳过采样实现计算复杂度降低而保持全局感应场以保持竞争性能的关键因素之一。GFLOPs的降低也揭示了ES2D在显著降低计算开销的同时保持甚至提高模型准确度的有效性,证明了其在资源受限场景中的可行性。
SSM-Conv融合块的效果。 在SE块后集成卷积分支提升了作者模型的性能。对于小方差,添加局部融合特征提取将准确度从73.6%提升到75.1%。在EfficientVMamba-B的情况下,引入融合机制使准确度从80.9%提升到81.2%。
观察到的性能提升揭示了额外的卷积分支增强了局部特征提取。通过集成融合,模型可能从更多样化的特征集中受益,这些特征集捕捉了更广泛的空间细节,提高了模型的泛化能力,从而提升了准确度。这表明,策略性地添加这类分支可以有效地通过提供输入特征图的全面和更细微的响应领域来增强模型的性能。
不同阶段注入卷积块的比较。 在本文中,作者得到了一个有趣的观察,即基于SSM的模块EVSS在网络早期阶段更为有益。相比之下,之前关于轻量级ViTs的工作通常在网络的早期阶段注入卷积块,并在深层阶段采用Transformer块。如表6所示,作者比较了在EfficientVMamba-T的不同阶段注入卷积块的性能,结果表明,在深层阶段采用Inverted Residual块比在早期阶段表现更好。对于作者的轻量级VSSMs和ViTs之间相反现象的解释是,Transformer中的自注意力具有更高的计算复杂性,因此在高分辨率下的计算效率较低;而专为高效建模长序列设计的SSMs,在捕获高分辨率下的全局信息方面更为高效和有益。 whaosoft aiot http://143ai.com
6 Conclusion
本文提出了EfficientVMamba,一种轻量级的状态空间网络架构,它巧妙地结合了全局和局部信息提取的优势,解决了模型准确性与计算效率之间的权衡问题。通过融合基于扩张的的选择性扫描和有效的跳跃采样,EfficientVMamba确保了全面的全局感受野覆盖,同时最小化计算负担。

Appendix
Comparisons with Other Backbones on Mask R-CNN.

Comparisons with MobileNetV2 Backbone
作者比较了不同的架构,并揭示了在特定阶段集成作者的创新块EVSS与倒置残差(InRes)块的显著性能差异。这导致表8显示,在小型和基础变体中的所有阶段一致使用InRes可以获得良好的性能,基础变体的准确度显著达到81.4%。当EVSS被应用于所有阶段(MobileNetV2的策略)时,作者发现两种变体的准确度都有轻微下降,这表明架构一致性与计算效率之间存在细微的平衡。

作者融合方法结合了初期阶段的EVSS和后期阶段的InRes,将小型和基础变体的准确度分别提升到76.5%和81.8%。这种策略利用了EVSS在早期阶段的效率以及InRes在高级阶段的卷积能力,从而通过利用两种块类型的优势优化了网络性能,并且计算资源有限。
Limitations

然而,状态空间模型 (SSMs) 的计算设计本质上比卷积和自注意力机制都要复杂,这增加了高效并行处理的性能复杂性。未来在优化视觉状态空间模型 (SSMs) 的计算效率和可扩展性方面仍存在着有希望的研究潜力。


