
- 1**紧凑型URL安全UUID:为你的项目瘦身的利器**
- 2运行 moveit_planning_execution.launch 报错_could not find the planner configuration 'none' on
- 3【EI会议】2024年光电信息、光学工程与机器视觉国际学术会议(OIOEMV 2024)_光电信息会议
- 4【Flink 核心篇】Flink 的八种分区策略(源码解读)_flink分区策略
- 5Java文档搜索引擎总结_搜索引擎项目总结
- 6python使用cv2无法打开图片(路径错误)_cv2使用相对路径打开图像错误
- 7论文阅读--5G 若干关键技术评述_论文精读 5g 知乎
- 8区块链专刊了解一下?顶级期刊TII GE力荐的区块链专刊
- 9[003-02-10].第10节:Docker环境下搭建Redis主从复制架构
- 10爱芯元智AX650N部署yolov8s 自定义模型_爱芯650n
人工智能 | BP神经网络_bp神经网络模型
赞
踩
BP(back propagation)神经网络是1986年由Rumelhart和McClelland为首的科学家提出的概念,是一种按照误差逆向传播算法训练的多层前馈神经网络,是应用最广泛的神经网络模型之一。
上面这段是官方对BP神经网络的定义,只有这句“按照误差逆向传播算法训练的多层前馈神经网络”点出了BP神经网络的特点,需要理解的重点按照先后顺序排列如下:
1. 多层神经网络是什么?
2. 误差如何定义?
3. 算法用哪个?
4. 逆向和前馈是什么?
5. 如何训练?
一、最简单的神经网络——感知机
“神经元”这个概念来自于生物学,在人工智能领域引申成了一种类比,指的是连接输入和输出的最小单位,当输入达到一定水平或者有一定类型的输入产生时,神经元就给出输出。所以,神经元可以看成是只有输入和输出的数学模型。
最简单的神经网络可以只包含一个神经元,如下图1所示,这种网络通常被称为感知机(Perceptron)。感知机是一种二分类算法,由Frank Rosenblatt在1957年提出,它是神经网络和机器学习领域中的一个基础模型。
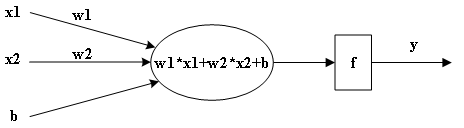
图1 最简单的神经网络
图中x是输入,w是权重,b是偏置,经过一个激活函数f得到最终输出y,图中只画出了2路输入,实际可以有n路输入,感知机的输出y可以通过公式(1)计算:
(1)
二、多层神经网络的灵魂——激活函数
神经元不是独立存在的,它们彼此之间也有联系,多个神经元联系在一起构成了神经网络,网络级联起来,就构成了多层神经网络,以最简单的两层神经网络为例,其结构如下图2所示:
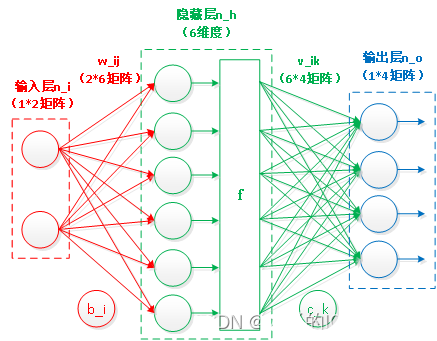
图2 两层神经网络
n_i:输入层的节点数
n_h:隐藏层的节点数
n_o:输出层的节点数
x_j:输入层的第 j 个节点的值
w_ij:连接输入层节点j和隐藏层节点i的权重
b_i:隐藏层节点i的偏置
z_i:隐藏层节点i的加权和
a_i:隐藏层节点i的激活值
v_ik:连接隐藏层节点i和输出层节点k的权重
c_k:输出层节点k的偏置
z_k:输出层节点k的加权和
a_k:输出层节点k的激活值,即网络的预测输出
t_k:目标输出值
不考虑激活函数,这个两层的神经网络是由两个线性方程构成的(如公式2所示),因为一系列线性方程的运算最终都可以用一个线性方程表示,所以这两层神经网络等同于一层神经网络,这样的神经网络是解决不了多少问题的。
(2)
因此网络中引入了激活函数,加入激活函数之后,公式(2)就变成了公式(3)和(4):
(3)
(4)
这样网络中就有了非线性因素,这样就可以应用到非线性模型中,常用的激活函数有以下几种:
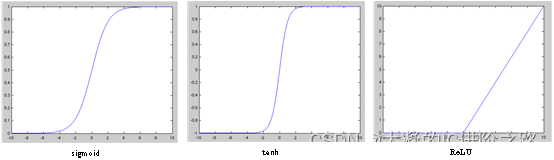
图3 常用的激活函数
Sigmoid:当输入趋近于正无穷/负无穷时,输出无限接近于1/0。
(5)
tanh:与Sigmoid函数很像,tanh输出是[-1,1],是0均值的,实际应用中会比Sigmoid好。
(6)
ReLU:全称是Rectified Linear Units,当输入小于0时,输出为0,当输入大于0时,输出等于输入。
(7)
以上3个激活函数挑一个放进图2中,一个两层神经网络就搭建好了,如果是已经训练好的网络,也就是说已经得到了稳定的w_ij、b_i、v_ik和c_k,那么该网络就可以投入使用了,用户自定义输出,网络给出答案,但是如果是正在建设中的网络,此时w_ij、b_i、v_ik和c_k是未知的,则还需要经过“训练”这一步。
三、误差——训练的标杆
神经网络是没有智商的,它需要经过多次“学习”才可以作出正确的判断,那如何确认学习的是否正确呢?当然是和标准答案做对比,就像考试一样,答对了加分,答错了扣分。为了衡量输出离标准答案有多远,定义“误差”作为学习标准,误差越小说明学习效果越好。
从图2可以想到,假设标准答案是t=(1,0,0,0),则输出ak和标准答案之间的误差为(ak-tk),但是一般会写成式(8)的样子,前面的1/2是为了求导后抵消平方的,这个E也被称为损失函数(Loss Function)。
(8)
到这里,神经网络的训练任务就变成了,找到一组最佳的w和b,使得E最小。要让E能调整w和b,这就需要往前一层一层的传递某种变量,用专业的词来说就是“逆向”和“前馈”。
此外,图2中不同的激活函数得到的结果是不一样的,如果选择sigmoid,输出范围为[0,1],如果选择tanh,输出是[-1,1],如果选择ReLU,输出是[0,+∝],这意味着,为了匹配不同的输出,标准答案还得改格式?
倒也不用这么麻烦,把输出统一成指定格式就可以了。
常用的做法是在输出这里使用Softmax函数把输出映射到(0,1)区间,也就是概率范围,最终得到类似(0.85,0.1,0.02,0.03)这样的结果,0.85比其他三个都大,说明结果可信。使用概率不仅可以得到结果,还能知道最优解是多少,Softmax函数如(9)所示:
(9)
用(9)求出的结果中,所有元素的和一定为1,且每个元素可以代表概率值,此时图2中的神经网络可以进化一下,把“逆向”、“前馈”和Softmax都加进去,图2变成了图4。
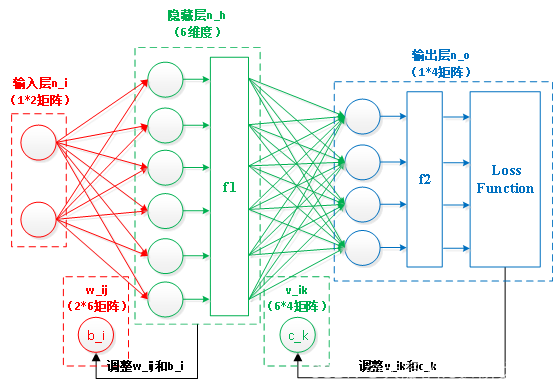
图4 完整的BP神经网络
这就是一个完整的BP神经网络了,它包含正向的计算,和逆向的参数调整,每逆向调整完一次参数再正向做一次计算,重复这个过程,直到损失函数E达到最小值,就获得了稳定的w_ij、b_i、v_ik和c_k,训练结束。但是如何获得损失函数E的最小值?最简单的方法是用梯度下降算法。
四、梯度下降——寻求最优解
图2是个两层的网络,用曲面更容易理解梯度下降的意义。假设楼主带着一个铅球去爬山,到了山顶上,先把铅球沾满粉笔灰然后往山下一扔,粉笔灰描绘出的路径就是铅球最快到达山底的路线,这就是神经网络梯度下降追求的最优路径。就算楼主自己往山下走,也不会走出比铅球更佳的路径,这是为什么呢?因为受重力影响,铅球大概率是沿着坡度最陡的角度下去的,这个最陡的方向,就是神经网络中梯度下降想找到的参数的调整方向。
现在要用数学来描述这个过程,就是是对损失函数E分别求w_ij、b_i、v_ik和c_k的一阶导,得到输出层和隐藏层的误差梯度:
(10)
接下来就可以得到输出层和隐藏层的权重和偏置,其中η为学习率,它的意思是每次更新多少进参数中,前面的负号是因为现在要求的是下降的梯度,它是梯度上升的反方向。
(11)
(12)
从(11)和(12)的公式可以看出,w_ij只和输出层有关,但是v_ik不仅和输出层有关,还和隐藏层有关,另外公式中的f1、f2求导和选择的激活函数有关,选择哪个激活函数,就套用其求导结果。
五、总结
到这里已经可以重新描述BP神经网络的定义了,官方的说法是“按照误差逆向传播算法训练的多层前馈神经网络”,白话版是“拥有2个以上的权重矩阵,通过最小化误差多次调整权重,最终获得稳定参数的可定制的黑盒子”。“可定制”指的是网络中的输入输出个数、隐藏层数、激活函数和寻求最优解的算法都是可以根据实际情况选择的。


