- 1AndroidStudio中设置简体字繁体字的切换_android 设置简繁体
- 2IDEA如何创建原生maven子模块
- 3git回退上一个版本_git 回滚上一个版本
- 42024年不能错过的12个开发者网站_devv官网
- 5(十)并发集合——CopyOnWrite集合_并发如何使用copyonwrite
- 6阿里内推五面:一面+二面+三面+交叉面+HR面,常见面试题目及答案_一面二面三面都面试什么
- 7深度强化学习落地方法论(5)——状态空间篇_强化学习状态空间
- 8使用 CRF 做中文分词_crf分词
- 9PaddleOCR 2.6版本 训练私人数据集详细教程_paddleocr训练自己的数据集
- 10如何在 VsCode 中从 Github 运行 Flutter 项目到您的系统并在您的设备中安装 Flutter App?_vs code怎么运行flutter工程
DenseNet讲解(Tensorflow-2.6.0实现结构)_densenet tensorflow
赞
踩
1.论文地址
https://arxiv.org/pdf/1608.06993.pdf
2.DenseNet结构

3.ResNet与DenseNet的对比
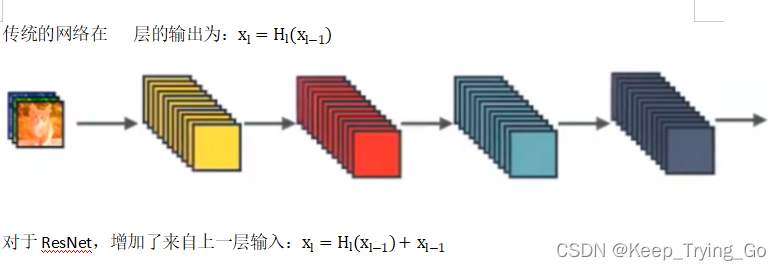
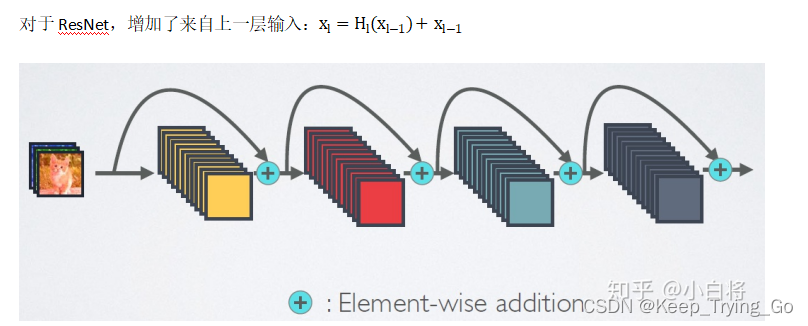
(1)ResNet(深度残差网络,Deep residual network)
通过建立前面层与后面层之间的“短路连接”,有助于训练过程中的梯度反向传播,防止梯度消失,从而可以训练更深的的网络。
关于ResNet结构讲解参考博文:
https://mydreamambitious.blog.csdn.net/article/details/124203294
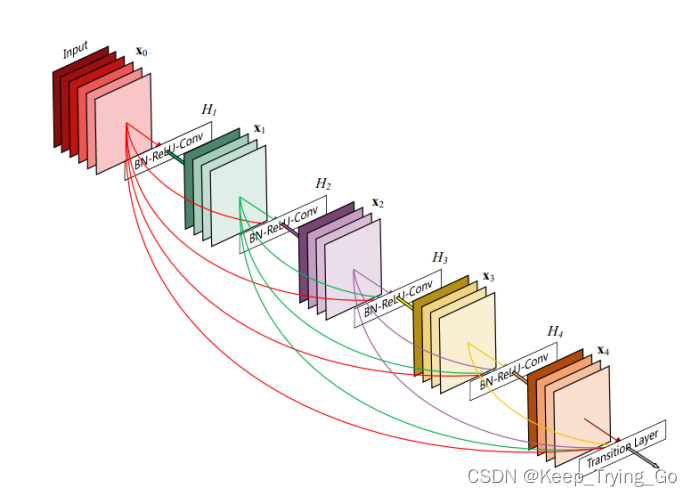
(2)DenseNet
采用密集连接机制,也就当前层连接前面所有的层,每一层会与前面的所有层在channel维度上连接(concat)在一起,实现特征重用,作为下一层的输入。
注:DenseNet这样做不仅减缓了梯度消失的现象,也可以在参数与计算量更少的情况下实现比ResNet更好的性能。
4.公式理解(传统CNN,ResNet,DenseNet)
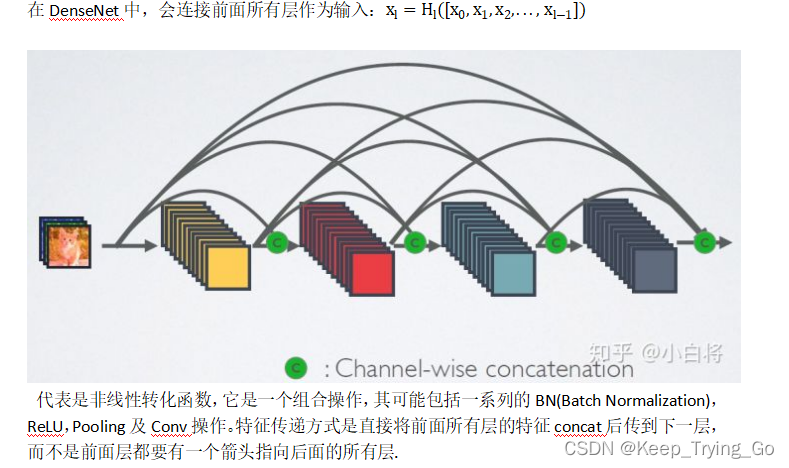
5.网络结构讲解
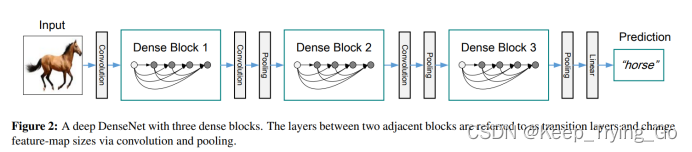
(1)DenseNet的连接方式
DenseNet的密集连接方式需要特征图大小保持一致,所以在DenseNet中使用了DenseBlock+Transition的结构。
(2)DenseBlock模块
DenseBlock是包含了很多层的模块,每一个层特征图大小相同,层与层之间采用密集连接方式:
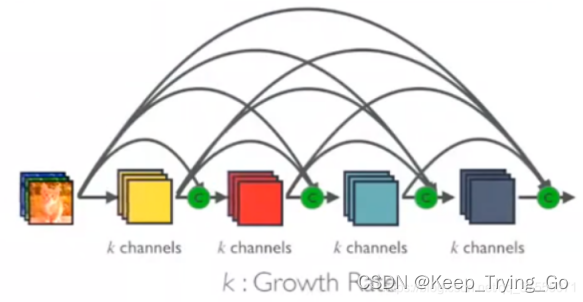
A.在DenseBlock中,各个层的特征图大小一致,可以在channel维度上连接。DenseBlock中的非线性组合函数采用的是BN+ReLU+3x3 Conv的结构。
B.假定输入层的特征图的channel数为k0,DenseBlock中各个层卷积之后均输出k个特征图,即得到的特征图的channel数为k,那么l层输入的channel数为k0+(l−1)k, 我们将k称之为网络的增长率(growth rate)。
C.因为每一层都接受前面所有层的特征图,即特征传递方式是直接将前面所有层的特征concat后传到下一层,一般情况下使用较小的K(比如12),要注意这个K的实际含义就是这层新提取出的特征(特征图大小)。
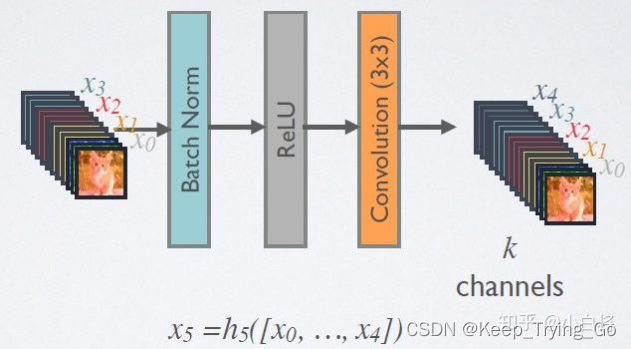
D.Dense Block采用了激活函数在前、卷积层在后的顺序,即BN-ReLU-Conv的顺序,这种方式也被称为pre-activation。通常的模型relu等激活函数处于卷积conv、批归一化batchnorm之后,即Conv-BN-ReLU,也被称为post-activation。作者证明,如果采用post-activation设计,性能会变差。
如下图解:
(3)bottleneck层
A. 由于后面层的输入会非常大,DenseBlock内部可以采用bottleneck层来减少计算量,主要是原有的结构中增加1x1 Conv,即
B. BN+ReLU+1x1 Conv+BN+ReLU+3x3 Conv
称为DenseNet-B结构。其中1x1 Conv得到4k个特征图它起到的作用是降低特征数量,从而提升计算效率。
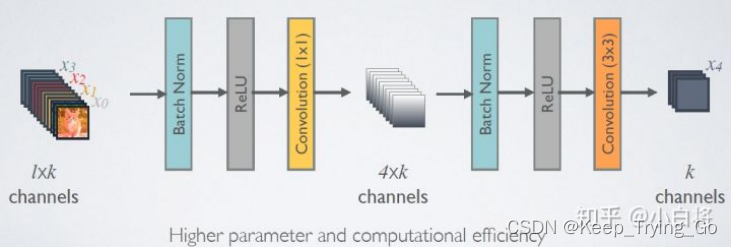
每一个Bottleneck输出的特征通道数是相同的。
这里1×1卷积的作用是固定输出通道数,达到降维的作用,1×1卷积输出的通道数通常是GrowthRate的4倍。当几十个Bottleneck相连接时,concat后的通道数会增加到上千,如果不增加1×1的卷积来降维,后续3×3卷积所需的参数量会急剧增加。
比如,输入通道数64,增长率K=32,经过15个Bottleneck,通道数输出 为64+15x32=544,
如果不使用1×1卷积,第16个Bottleneck层参数量是3x3x544x 32=156672,
如果使用1×1卷积,第16个Bottleneck层参数量是1x1x544x128+3x3x128x32=106496,可以看到参数量大大降低。

注:表示是在1x1卷积核使用filters为4xk个数。

注:表示是在denseblock模块中的3x3卷积的卷积核个数使用当前block的输入filters个数。
(4)Transition层
A.它主要是连接两个相邻的DenseBlock,并且降低特征图大小。Transition层包括一个1x1的卷积和2x2的AvgPooling,结构为
BN+ReLU+1x1 Conv+2x2 AvgPooling.
B.Transition层可以起到压缩模型的作用。假定Transition的上接DenseBlock得到的特征图channels数为 m ,Transition层可以产生个特征(通过卷积层),其中是压缩系数(compression rate)。当Θ=1时,特征个数经过Transition层没有变化,即无压缩,而当压缩系数小于1时,这种结构称为DenseNet-C,一般使用Θ=0.5。对于使用bottleneck层的DenseBlock结构和压缩系数小于1的Transition组合结构称为DenseNet-BC。

6.实现结果对比
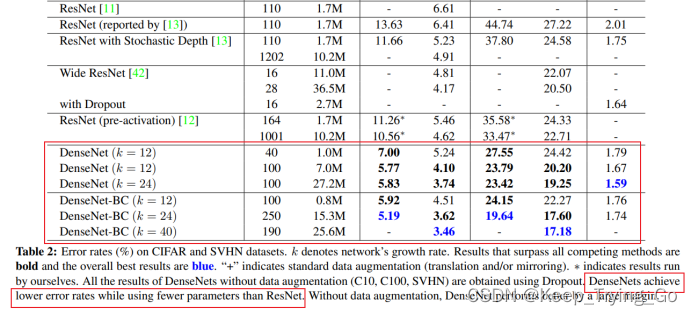
从图表中也可以看到,相比于ResNet,DenseNet不仅使用更少的参数量,而且效果还要比ResNet要好(DenseNet错误率比ResNet更低)。
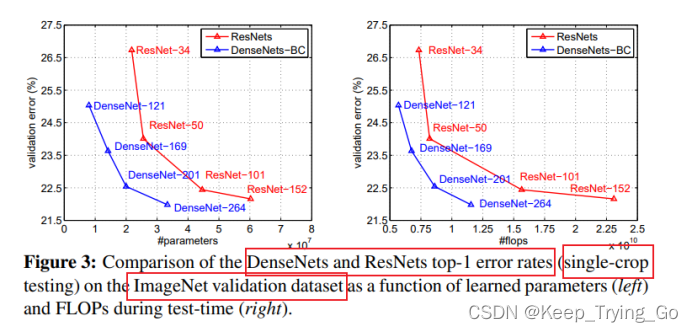
从上面的两张图表可以看到ResNet和DenseNet的在相同错误的情况下参数量和FLOPS(浮点运算量)的对比,DenseNet的效果明显比ResNet的效果要好。
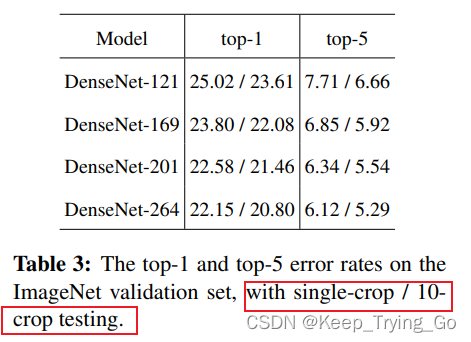
在TOP-1和TOP-5错误率上,采用裁剪出10个图片进行验证,最后综合10张图片的结果比使用单张图片的效果都要好(相当于进行了数据增强)。
7.DenseNet的优缺点
(1)更强的梯度流动
由于密集连接方式,DenseNet提升了梯度的反向传播,使得网络更容易训练。由于每层可以直达最后的误差信号,实现了隐式的“deep supervision”。误差信号可以很容易地传播到较早的层,所以较早的层可以从最终分类层获得直接监管(监督)。
减轻了vanishing-gradient(梯度消失)过程中的梯度消失问题,在网络深度越深的时候越容易出现,原因就是输入信息和梯度信息在很多层之间传递导致的,而现在这种dense connection相当于每一层都直接连接input和loss,因此就可以减轻梯度消失现象,这样更深网络不是问题。
(2)使用1x1的卷积减少了参数量
关于1x1卷积的作用
https://mydreamambitious.blog.csdn.net/article/details/123027344
(3)保存了低维度的特征
对于在标准的卷积网络中而言,最终输出只会利用提取最高层次的特征;然而对于DenseNet,它使用了不同层次的特征,倾向于给出更平滑的决策边界。这也解释了为什么训练数据不足时DenseNet表现依旧良好。
(4)DenseNet的不足之处
在于由于需要进行多次Concatnate操作,数据需要被复制多次,显存容易增加得很快,需要一定的显存优化技术。另外,DenseNet是一种更为特殊的网络,ResNet则相对一般化一些,因此ResNet的应用范围更广泛。
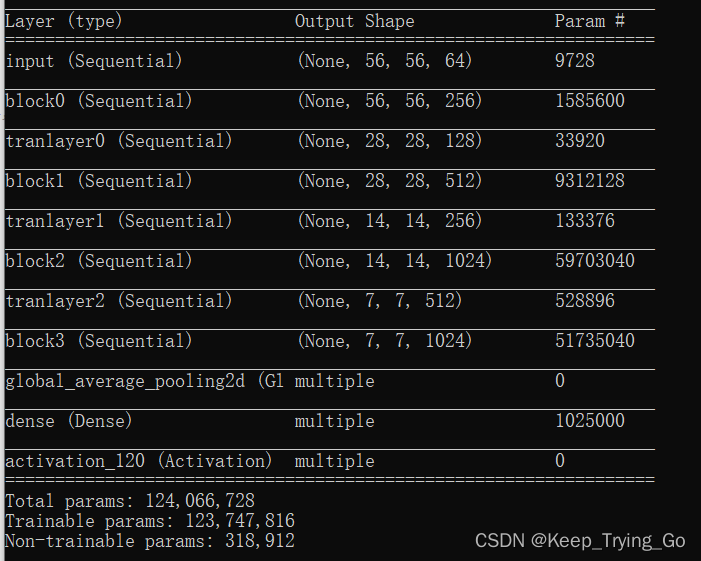
8.Tensorflow实现网络结构
import os import keras import numpy as np import tensorflow as tf from tensorflow.keras import layers from tensorflow.keras.models import Model from tensorflow.keras.preprocessing import image #搭建DenseNetBlock模块 class DenseNetBlock(tf.keras.Model): def __init__(self,input_features,growth_rate): super(DenseNetBlock, self).__init__() #BN-ReLU-Conv self.batch1 = layers.BatchNormalization() self.relu1=layers.Activation('relu') self.conv1=layers.Conv2D(4*input_features,kernel_size=[1,1],strides=[1,1],padding='same') self.batch2=layers.BatchNormalization() self.relu2=layers.Activation('relu') self.conv2=layers.Conv2D(growth_rate,kernel_size=[3,3],strides=[1,1],padding='same') def call(self,inputs,training=None): x=self.batch1(inputs) x=self.relu1(x) x=self.conv1(x) x=self.batch2(x) x=self.relu2(x) x=self.conv2(x) x=tf.concat([ x,inputs ],axis=3) return x #搭建Transition 模块 class TransitionLayer(tf.keras.Model): def __init__(self,input_features): super(TransitionLayer, self).__init__() self.batch=layers.BatchNormalization() self.relu=layers.Activation('relu') self.conv=layers.Conv2D(input_features,kernel_size=[1,1],strides=[1,1],padding='same') self.avgpool=layers.AveragePooling2D(pool_size=[2,2],strides=[2,2],padding='same') def call(self,inputs,training=None): x=self.batch(inputs) x=self.relu(x) x=self.conv(x) x=self.avgpool(x) return x #DenseNet class DenseNet121(tf.keras.Model): def __init__(self,growth_rate,input_features,num_layers,num_classes): super(DenseNet121, self).__init__() self.growth_rate=growth_rate self.num_layers=num_layers #输入部分 self.Inputs=keras.Sequential([ layers.Conv2D(input_features, kernel_size=[7, 7], strides=[2, 2], padding='same'), layers.BatchNormalization(), layers.Activation('relu'), layers.MaxPool2D(pool_size=[3,3],strides=[2,2],padding='same') ],name='input') #We refer the DenseNet with θ <1 as DenseNet-C, and we set θ = 0.5 self.densenetblock1=self.DenseNetBlocks(num_layers[0],input_features,0) input_features=input_features+num_layers[0]*self.growth_rate self.transition1=self.transitionlayer(input_features//2,0) input_features=input_features//2 self.densenetblock2 = self.DenseNetBlocks(num_layers[1], input_features,1) input_features = input_features + num_layers[1] * self.growth_rate self.transition2 = self.transitionlayer(input_features // 2,1) input_features = input_features // 2 self.densenetblock3 = self.DenseNetBlocks(num_layers[2], input_features,2) input_features = input_features + num_layers[2] * self.growth_rate self.transition3 = self.transitionlayer(input_features // 2,2) input_features = input_features // 2 self.densenetblock4 = self.DenseNetBlocks(num_layers[3], input_features,3) input_features = input_features + num_layers[3] * self.growth_rate #输出部分 self.avgpool=layers.GlobalAveragePooling2D() self.dense=layers.Dense(num_classes) self.softmax=layers.Activation('softmax') def DenseNetBlocks(self,blocks,input_features,k): densenetblocks=keras.Sequential([],name='block'+str(k)) for i in range(blocks): densenetblocks.add( DenseNetBlock(input_features+i*self.growth_rate,self.growth_rate) ) return densenetblocks def transitionlayer(self,input_features,k): tranlayer=keras.Sequential([],name='tranlayer'+str(k)) tranlayer.add(TransitionLayer(input_features)) return tranlayer def call(self,inputs,training=None): x=self.Inputs(inputs) x=self.densenetblock1(x) x=self.transition1(x) x=self.densenetblock2(x) x=self.transition2(x) x=self.densenetblock3(x) x=self.transition3(x) x=self.densenetblock4(x) x=self.avgpool(x) x=self.dense(x) x=self.softmax(x) return x model_denseNet=DenseNet121(growth_rate=32,input_features=64,num_layers=[6,12,24,16],num_classes=1000) model_denseNet.build(input_shape=(None,224,224,3)) model_denseNet.summary() if __name__ == '__main__': print('pycharm')

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
- 123
- 124
- 125
- 126
- 127