
- 1IT学习之路指引从入门到精通的暑假学习计划_一个暑假可以精通python吗?
- 2基于python爬虫酒店数据可视化和酒店推荐系统设计与实现(django框架)_python 酒店数据分析_基于酒店建立一个内容推荐系统
- 3前端自动化测试(二)Vue Test Utils + Jest_vue+jest 测试api
- 4( 教程 ) 微信公众号做淘宝优惠券自动查券返利机器人怎么设置?_如何做一个微信自动查询的功能
- 5HttpUtil工具
- 6HTML5实现我的音乐网站源码_带音乐播放的个人页html源码
- 7计算机学院北航算法作业,北航《算法与数据结构》在线作业一(BUAA algorithms and data structures online homework).doc...
- 8聊天机器人之实体命名标识和槽位取值的关系_对话机器人 槽位识别取值bool型
- 9Django之操作MySQL_django mysql
- 10用故事绘就生活:探索星火绘镜Typemovie的艺术魅力
【Keras计算机视觉OCR】文字识别算法中DenseNet、LSTM、CTC、Attention的讲解(图文解释 超详细)_ocr attention
赞
踩
觉得有帮助麻烦点赞关注收藏~~~
一、OCR文字识别的概念
利用计算机自动识别字符的技术,是模式识别应用的一个重要领域。人们在生产和生活中,要处理大量的文字、报表和文本。为了减轻人们的劳动,提高处理效率,从上世纪50年代起就开始探讨文字识别方法,并研制出光学字符识别器。
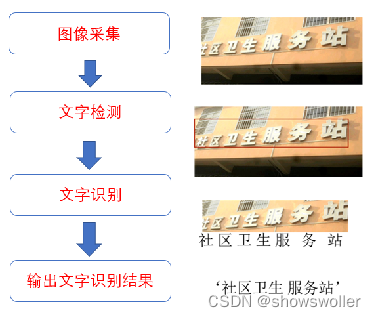
OCR(Optical Character Recognition)图像文字识别是人工智能的重要分支,赋予计算机人眼的功能,可以看图识字。如图6-1所示,图像文字识别系统流程一般分为图像采集、文字检测、文字识别及结果输出四个部分。
二、文字识别算法
卷积神经网络是图像识别的主要方法,也同样适用于字符的识别,但文本识别不同于其他的图像识别,文本行的字符间是一个序列,彼此之间也有一定关系,同一文本行上的不同字符可以互相利用上下文信息,因此可以采用处理序列的方法例如循环神经网络来表示,CNN和RNN两种网络相结合可以提高识别精度,CNN用来提取图像的深度特征,RNN用来对序列的特征进行识别,以符合文本序列的性质,从而形成统一的端到端可训练模型
下面将介绍DenseNet+LSTM+CTC的结合方式 将特征提取 序列预测和解码集成到一个统一的网络模型中
1:基于DenseNet网络模型的序列特征提取
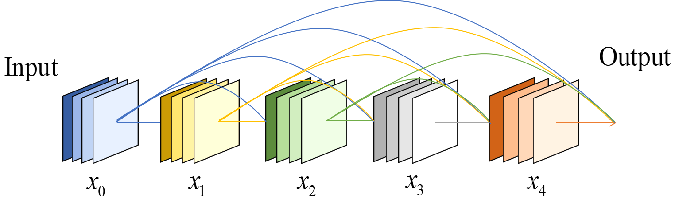
DenseNet是一种有效的图像识别算法,该网络的优点在于减轻了深层网络梯度消失问题,增强了特征图的传播利用率,减少了模型参数量,在ResNet的基础上进一步加强了特征图之间的连接,构造了一种具有密集连接方式的卷积神经网络
DenseNet网络模型的核心组成部分是密集连接模块,这个模块中任意两层之间均直接的连接,即网络中的第一层、第二层 第L-1层的输出都会作为第L层的输入,同时第L层的特征图也会直接传递给后面所有层作为输入
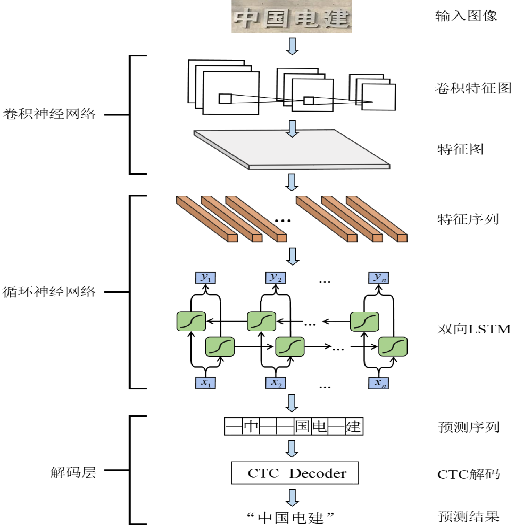
2:基于LSTM结构的上下文序列特征提取
文本行是一个序列,含有丰富的上下文信息,同一文本行中的不同字符可以互相利用上下文信息,这对于字符的识别具有重要的影响,一些模糊的字符在观察其上下文时更容易区分,在卷积网络之后,构建了一个循环网络,用于提取文本序列的上下文序列特征
双向LSTM能在访问之前信息的同时,访问字符之后的信息,故能从正反两个方向提取文本行中的语义信息,有助于文本行识别任务,因此 双向LSTM可以同时处理上文和下文信息来提取上下文序列特征
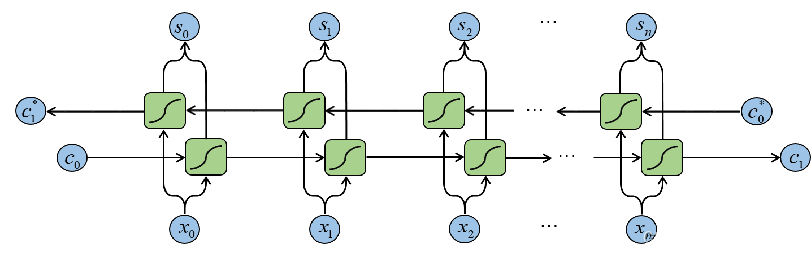
字符序列的解码方式
在文本识别网络模型中,LSTM输出的序列中的字符要与标签中字符的位置一一对应,若使用softmax函数作为损失函数进行训练,训练网络参数时需要在图像上标注出每个的位置信息,使用手工标注对其样本工作量非常大,所以需要解码使字符位置一一对应 下面介绍两种常用的机制
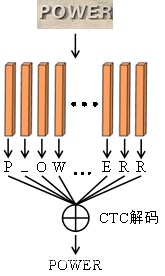
1:基于CTC解码机制
CTC机制常用于文字识别系统,解决序列标注问题中输入标签与输出标签的对齐问题,通过映射韩叔叔将其转换为预测序列,无序数据对齐处理,减少了工作量,被广泛用于图像文本识别的损失函数计算,多用于网络参数的优化
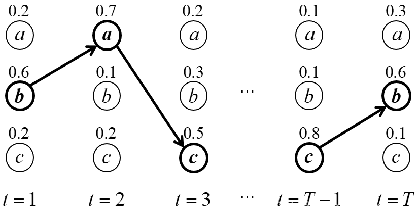
解码是模型在做预测的过程中将LSTM输出的预测序列通过分类器转换为标签序列的过程,解码过程中的分类方式为最优路径编码,输出计算概率最大的一条路径作为最终的预测序列,即在每个时间点输出概率最大的字符
2:Attention模型注意力机制解码方式
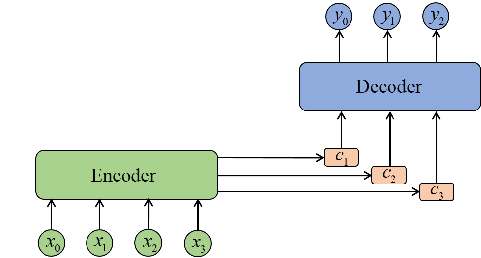
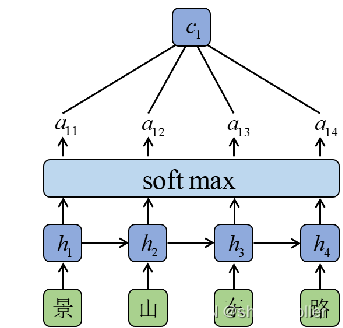
注意力机制被广泛用于序列处理Seq2Seq任务中,注意力模型借鉴了人类视觉的选择性注意力机制,其核心目标是从众多信息中选出对当前任务目标来说重要的信息,忽略其他不重要的信息
对含有文本的图片而言,文本识别输出的结果的顺序取决于文本行中字符的前后位置信息,引入注意力机制可以起到定位的作用,从而突出字符的位置信息,解决序列对齐问题,因此不需要标注文本的位置
Attention模型的原理是计算当前输入序列与输出序列的匹配程度,在产生每一个输出时,会充分利用输入序列上下文信息,对同一序列中的不同字符赋予不同的权重。
创作不易 觉得有帮助请点赞关注收藏~~~

