
- 1springboot+layui +ueditor前端及后端完整开发案例_layui ueditor
- 2shell脚本中使用自定义命令之五---执行脚本变成交互式_shell脚本执行后success进行自定义
- 3coco128数据集下载连接
- 4linux文件的删除_linux删除文件
- 5k8s中job与cronjob使用详解_k8s job应用场景
- 6k8s:Pod 基础概念_k8s新版本 底层容器
- 7微服务---Redis实用篇-黑马头条项目-优惠卷秒杀功能(使用redis的消息队列对秒杀进行异步优化)_如何使用队列为用户发放优惠券
- 8@PostConstruct 注解,解决工具类静态方法需要依赖注入_postconstruct 依赖注入
- 9Kafka生产者客户端详解_kafka client
- 10数学建模【神经网络】
VOC数据集简介与制作_制作voc数据集
赞
踩
一、VOC数据集简介
1.1 VOC的任务
PASCAL VOC 挑战赛主要有 Object Classification (分类)、Object Detection(检测)、Object Segmentation(分割)、Human Layout、Action Classification 这几类子任务。
分类:在测试图像预测是否为二十个分类之一,正确分类
检测:在测试图像上预测二十个分类对象的有无与位置信息
分割:对每个对象与类别生成像素级别的分割标签,确定像素是为目标20个分类或者背景。
此外Pascal VOC还提供一些很有意思的标注数据包括Action Classification (行为识别)、Human Layout(人体Layout分析)等。
行为识别:预测图像中人的行为动作
Person Layout:检测人与其各个身体组成部分,如果手、脚、头等

1.2 数据构成
PASCAL VOC 2007 和 2012 数据集总共分 4 个大类:vehicle、household、animal、person,总共 20 个小类(加背景 21 类),预测的时候是只输出下图中黑色粗体的类别。
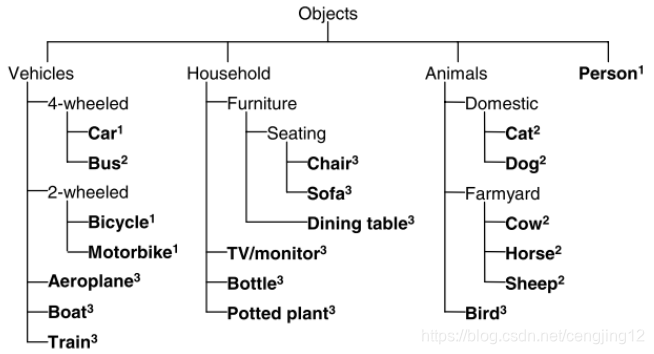
目前目标检测常用的是 VOC2007 和 VOC2012 数据集,因为二者是互斥的。
VOC2007 和 VOC2012 目标检测任务中的训练、验证和测试数据统计如下表所示

trainval是train和val的合并。
1.3 组织结构
以 VOC 2012为例,解压后的文件为:
. └── VOCdevkit #根目录 └── VOC2012 #不同年份的数据集,这里只下载了2012的,还有2007等其它年份的 ├── Annotations #存放xml文件,与JPEGImages中的图片一一对应,解释图片的内容等等 ├── ImageSets #该目录下存放的都是txt文件,txt文件中每一行包含一个图片的名称,末尾会加上±1表示正负样本 │ ├── Action │ ├── Layout │ ├── Main #存放的是分类和检测的数据集分割文件 │ └── Segmentation ├── JPEGImages #存放源图片 ├── SegmentationClass #存放的是图片,语义(class)分割相关 └── SegmentationObject #存放的是图片,实例(object)分割相关 ├── Main │ ├── train.txt 写着用于训练的图片名称, 共 2501 个 │ ├── val.txt 写着用于验证的图片名称,共 2510 个 │ ├── trainval.txt train与val的合集。共 5011 个 │ ├── test.txt 写着用于测试的图片名称,共 4952 个

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
1.3.1 Annotations
其中xml主要介绍了对应图片的基本信息,如来自那个文件夹、文件名、来源、图像尺寸以及图像中包含哪些目标以及目标的信息等等,xml内容如下:
<annotation> <folder>VOC2007</folder> <filename>000001.jpg</filename> # 文件名 <source> <database>The VOC2007 Database</database> <annotation>PASCAL VOC2007</annotation> <image>flickr</image> <flickrid>341012865</flickrid> </source> <owner> <flickrid>Fried Camels</flickrid> <name>Jinky the Fruit Bat</name> </owner> <size> # 图像尺寸, 用于对 bbox 左上和右下坐标点做归一化操作 <width>353</width> <height>500</height> <depth>3</depth> </size> <segmented>0</segmented> # 是否用于分割,1有分割标注,0表示没有分割标注。 <object> <name>dog</name> # 物体类别 <pose>Left</pose> # 拍摄角度:front, rear, left, right, unspecified <truncated>1</truncated> # 目标是否被截断(比如在图片之外),或者被遮挡(超过15%) <difficult>0</difficult> # 检测难易程度,这个主要是根据目标的大小,光照变化,图片质量来判断,0表示不是,1表示是 <bndbox> <xmin>48</xmin> <ymin>240</ymin> <xmax>195</xmax> <ymax>371</ymax> </bndbox> </object> <object> <name>person</name> <pose>Left</pose> <truncated>1</truncated> # 是否被标记为截断,0表示没有,1表示是 <difficult>0</difficult> <bndbox> <xmin>8</xmin> <ymin>12</ymin> <xmax>352</xmax> <ymax>498</ymax> </bndbox> </object> </annotation>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
1.3.2 ImageSets
ImageSets包含如下四个子文件夹:Action、Layout、Main、Segmentation。里面是标注类别的每个文件列表信息:
- Action中是所有具有Action标注信息图像文件名的txt文件列表,
- Layout中的txt文件表示包含Layout标注信息的图像文件名列表,
- Main文件夹中包含20个类别每个类别一个txt文件,每个txt文件都是包含该类别的图像文件名称列表,
- Segmentation则是包含语义分割信息图像文件的列表。
在main中针对每个类别都有个三个文件,分别为:
- CLASSNAME_train.txt
- CLASSNAME_trainval.txt
- CLASSNAME_val.txt
以CLASSNAME = aeroplane为例,main中的三个文件分别为:
- aeroplane_train.txt
- aeroplane_trainval.txt
- aeroplane_val.txt
每个类别txt文件里面的内容格式为 :图像文件名 + 空格 + 标记,以aeroplane_train.txt中的举例如下:
2008_000290 0
2008_000291 1
2008_000297 -1
其中2008_000290、2008_000291、2008_000297表示三张图像文件名
- 0 表示图像中包含aeroplane对象但是难识别样本
- 1 表示图像中包含aeroplane
- -1 表示图像中不包含aeroplane
1.3.3 JPEGImages
所有的原始图像文件,格式必须是JPG格式,这个要特别注意!如果你打算使用VOC2012格式生成数据,那么原始图像格式在采样时候请用JPG格式保存,避免后期生成使用tensorflow工具生成的时候出错。
1.3.4 SegmentationClass
所有分割的图像标注,分割图像安装每个类别标注的数据
1.3.5 SegmentationObject
所有分割的图像标注,分割图像安装每个类别每个对象不同标注的数据
1.4 提交格式
1.4.1 Classification Task
每一类都有一个 txt 文件,里面每一行都是测试集中的一张图片,前面一列是图片名称,后面一列是预测的分数。
# comp1_cls_test_car.txt, 内容如下
000004 0.702732
000006 0.870849
000008 0.532489
000018 0.477167
000019 0.112426- 1
- 2
- 3
- 4
- 5
- 6
1.4.2 Detection Task
每一类都有一个 txt 文件,里面每一行都是测试集中的一张图片,每行的格式为: ,confidence 用来计算 mAP
# comp3_det_test_car.txt,内容如下
# comp3:只允许用所给训练数据,comp4:允许使用外部数据
000004 0.702732 89 112 516 466
000006 0.870849 373 168 488 229
000006 0.852346 407 157 500 213
000006 0.914587 2 161 55 221
000008 0.532489 175 184 232 201- 1
- 2
- 3
- 4
- 5
- 6
- 7
1.5 评估标准
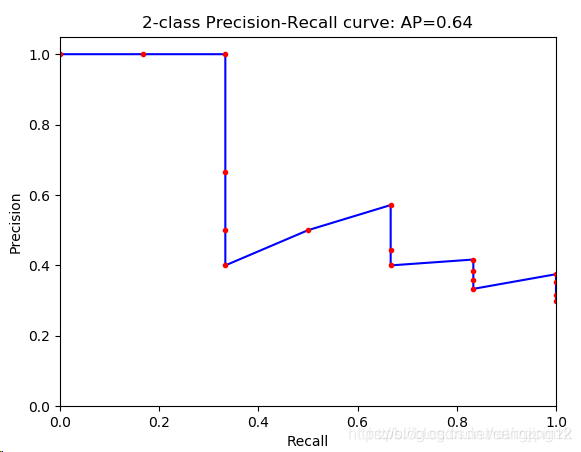
PASCAL的评估标准是 mAP(mean average precision)。下面是一个二分类的 P-R 曲线(precision-recall curve),对于 PASCAL 来说,每一类都有一个这样的 P-R曲线,P-R 曲线下面与 x 轴围成的面积称为 average precision,每个类别都有一个 AP,20个类别的 AP 取平均值 就是 mAP。
2 VOC数据集的制作
在我们训练Faster-RCNN/SSD模型时,有些数据集需要我们自己制作的,接下来我就说一说如何自己制作一个VOC数据集。
2.1 创建数据集文件夹
handvoc是你自己数据集的名字,在该目录下有第三个文件夹如下所示。
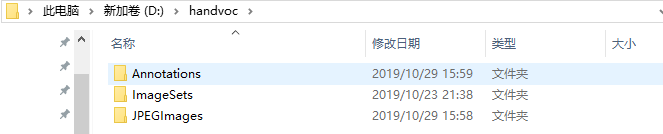
其中ImgeSets下还有一个Main文件夹

文件夹说明:
- JPEGImages中存放要训练的图片。
- Annotations中这XML信息,XML文件名与训练图片的文件名一一对应。
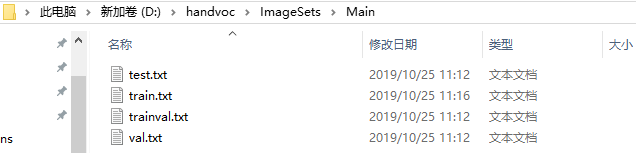
- ImageSets中存放文件夹Main,Main中存放四个txt文件,train存放着用于训练图片名字集合,test存放着用于测试的名字集合。
2.2 将训练图片放到JPEGImages
将选取的图片放置于放于目录:JPEGImages下,然后将图片重命名为VOC2007的“000005.jpg”形式。重命名的python代码为:
import os
path = "D:\\handvoc\\JPEGImages"
filelist = os.listdir(path) #该文件夹下所有的文件(包括文件夹)
count=0
for file in filelist:
print(file)
for file in filelist: #遍历所有文件
Olddir=os.path.join(path,file) #原来的文件路径
if os.path.isdir(Olddir): #如果是文件夹则跳过
continue
filename=os.path.splitext(file)[0] #文件名
filetype=os.path.splitext(file)[1] #文件扩展名
Newdir=os.path.join(path,str(count).zfill(6)+filetype) #用字符串函数zfill 以0补全所需位数
os.rename(Olddir,Newdir)#重命名
count+=1- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
更改名字之后的图片:
2.3 标注图片,标注文件保存到Annotations
使用labelImg进行标注,使用方法如下:https://editor.csdn.net/md/?articleId=107818472
链接: labelImg使用方法.
注意:标注自己的图片的时候,类别名称请用小写字母,比如汽车使用car,不要用Car 。若出现无法找到resources的错误,此时只需将resources.py复制到libs文件夹中即可。
2.4 生成ImageSets\Main里的四个txt文件
在ImageSets里再新建文件夹,命名为Main,在Main文件夹中生成四个txt文件,即:

- test.txt是测试集
- train.txt是训练集
- val.txt是验证集
- trainval.txt是训练和验证集
VOC2007中,trainval大概是整个数据集的50%,test也大概是整个数据集的50%;train大概是trainval的50%,val大概是trainval的50%。
txt文件中的内容为样本图片的名字(不带后缀),格式如下:
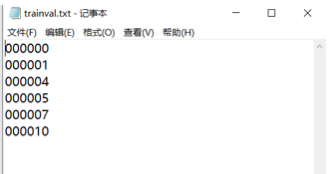
上面所占百分比可根据自己的数据集修改,如果数据集比较少,test和val可少一些。在自己的文件夹下生成自己数据集的代码如下:
import os import random trainval_percent = 0.8 train_percent = 0.6 xmlfilepath = 'D:\handvoc\Annatations' txtsavepath = 'D:\handvoc\ImageSets\Main' total_xml = os.listdir(xmlfilepath) num = len(total_xml) list = range(num) tv = int(num * trainval_percent) tr = int(tv * train_percent) trainval = random.sample(list, tv) train = random.sample(trainval, tr) ftrainval = open('D:\\handvoc\\ImageSets\\Main\\trainval.txt', 'w') ftest = open('D:\\handvoc\\ImageSets\\Main\\test.txt', 'w') ftrain = open('D:\\handvoc\\ImageSets\\Main\\train.txt', 'w') fval = open('D:\\handvoc\\ImageSets\\Main\\val.txt', 'w') for i in list: name = total_xml[i][:-4] + '\n' if i in trainval: ftrainval.write(name) if i in train: ftrain.write(name) else: fval.write(name) else: ftest.write(name) ftrainval.close() ftrain.close() fval.close() ftest.close()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
你要根据你的情况修改生成比例以及文件夹的位置。
- 直接上代码。
...... -->[详细] 赞
踩

