
- 1Nginx应用(搭建网站、设置权限、用户认证)_nginx 权限验证
- 2gitee配置ssh公钥免密登录_gitee ssh
- 3服务器部署测试环境回顾与改进建议
- 4如何在服务器上安装宝塔面板
- 5应用程序无法正常启动0xc000007b请点击确定关闭应用程序_0xc000007b应用程序无法正常启动
- 6c# --WPF学习之路(一)_c# wpf
- 7能ping通,但打不开网页解决方案_能ping通打不开网页
- 8Linux(ubuntu)下编程方面-杂项_libgtkglext1
- 9配置服务器通过公司代理地址连接公网YUM源_如何使用代理服务器访问公网yum源
- 10/lib64/libc.so.6: version `GLIBC_2.7' not found 解决方案
postgresql 数据库 INSERT 或 UPDATE 大量数据时速度慢的原因分析_sqlsugar 大数据插入还是慢
赞
踩
postgresql 数据库 INSERT 或 UPDATE 大量数据时速度慢的原因分析

前言
最近这段时间一直使用pg 数据库插入更新大量的数据,发现pg数据库有时候插入数据非常慢,这里我对此问题作出分析,找到一部分原因,和解决办法。
一 死元祖过多
提起pg数据库,由于他的构造,就不得不说他的元祖。
1.1 什么是元祖?
在Postgresql做delete操作时,数据集(也叫做元组 (tuples))是没有立即从数据文件中移除的,仅仅是通过在行头部设置xmax做一个删除标记。update操作也是一样的,在postgresql中可以看作是先delete再insert;
这是Postgresql MVCC的基本思想之一,因为它允许在不同进程之间只进行最小的锁定就可以实现更大的并发性。这个MVCC实现的缺点当然是它会留下被标记删除的 元组( dead tuples),即使在这些版本的所有事务完成之后。
1.2 死元祖过多的危害
如果不清理掉那些dead tuples(对任何事务都是不可见的)将会永远留在数据文件中,浪费磁盘空间,对于表来说,有过多的删除和更新,dead tuples很容易占绝大部分磁盘空间。而且dead tuples也会在索引中存在,更加加重磁盘空间的浪费。这是在PostgreSQL中常说的膨胀(bloat)。自然的,需要处理的数据查询越多,查询的速度就越慢。
1.3 查询死元祖情况
1.3.1 查询那些表的死元祖过多
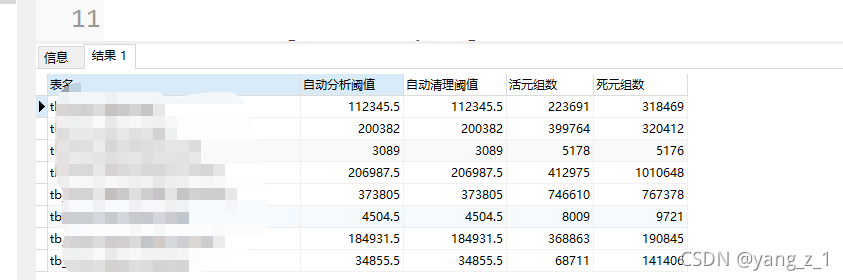
1、查询当前数据库表已经达到自动清理条件的表及相关信息
SELECT
c.relname 表名,
(current_setting('autovacuum_analyze_threshold')::NUMERIC(12,4))+(current_setting('autovacuum_analyze_scale_factor')::NUMERIC(12,4))*reltuples AS 自动分析阈值,
(current_setting('autovacuum_vacuum_threshold')::NUMERIC(12,4))+(current_setting('autovacuum_vacuum_scale_factor')::NUMERIC(12,4))*reltuples AS 自动清理阈值,
reltuples::DECIMAL(19,0) 活元组数,
n_dead_tup::DECIMAL(19,0) 死元组数
FROM
pg_class c
LEFT JOIN pg_stat_all_tables d
ON C.relname = d.relname
WHERE
c.relname LIKE'tb%' AND reltuples > 0
AND n_dead_tup > (current_setting('autovacuum_analyze_threshold')::NUMERIC(12,4))+(current_setting('autovacuum_analyze_scale_factor')::NUMERIC(12,4))*reltuples;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
2、查询当前正在进行自动清理的表及相关信息
SELECT
c.relname 对象名称,
l.pid 进程id,
psa.STATE 查询状态,
psa.query 执行语句,
now( ) - query_start 持续时间
FROM
pg_locks l
INNER JOIN pg_stat_activity psa ON ( psa.pid = l.pid )
LEFT OUTER JOIN pg_class C ON ( l.relation = C.oid )
WHERE psa.query like 'autovacuum%' and l.fastpath='f'
ORDER BY query_start asc;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
3、查询自动清理的历史统计信息
SELECT relname 表名, seq_scan 全表扫描次数, seq_tup_read 全表扫描记录数, idx_scan 索引扫描次数, idx_tup_fetch 索引扫描记录数, n_tup_ins 插入的条数, n_tup_upd 更新的条数, n_tup_del 删除的条数, n_tup_hot_upd 热更新条数, n_live_tup 活动元组估计数, n_dead_tup 死亡元组估计数, last_vacuum 最后一次手动清理时间, last_autovacuum 最后一次自动清理时间, last_analyze 最后一次手动分析时间, last_autoanalyze 最后一次自动分析时间, vacuum_count 手动清理的次数, autovacuum_count 自动清理的次数, analyze_count 手动分析此表的次数, autoanalyze_count 自动分析此表的次数, ( CASE WHEN n_live_tup > 0 THEN n_dead_tup :: float8 / n_live_tup :: float8 ELSE 0 END ) :: NUMERIC ( 12, 2 ) AS "死/活元组的比例" FROM pg_stat_all_tables WHERE schemaname = 'public' ORDER BY n_dead_tup::float8 DESC;

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
1.4 解决办法
1.4.1 修改参数,提高效率
大家可以根据实际修改pg数据库
具体参数介绍之后还会有一篇文章详细介绍

1.4.2 手动清理
有时候自动清理往往会因为各种原因实际效果达不到预期,这时候我们需要对某些死元祖过多的表进行手动清理
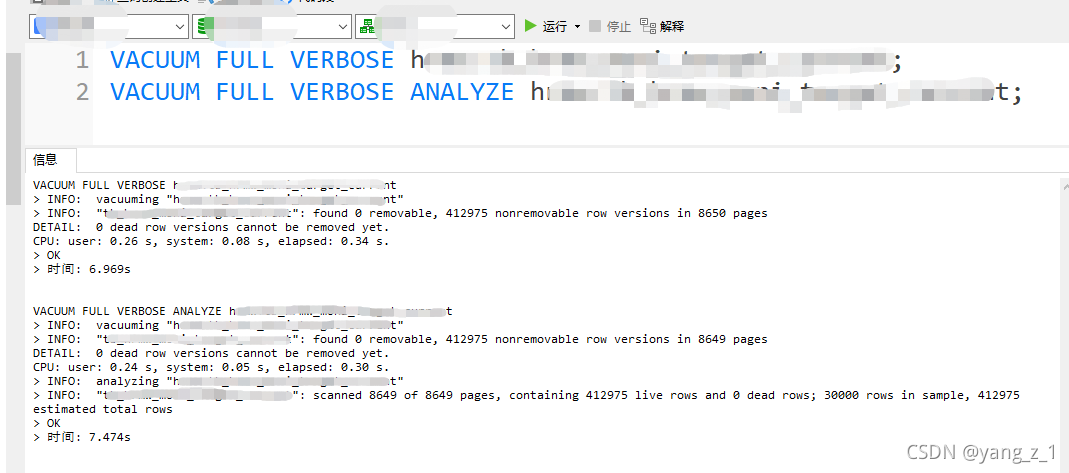
手动数据表收缩
VACUUM FULL VERBOSE 模式名.表名;
VACUUM FULL VERBOSE ANALYZE 模式名.表名;
- 1
- 2
结果如下
二 索引过多导致插入过慢
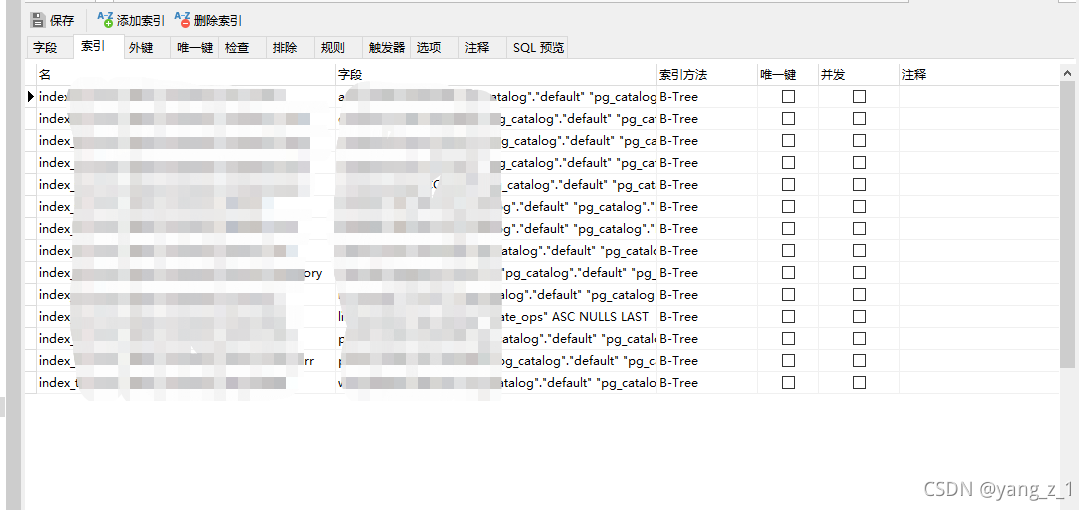
索引过多,虽会提高查询速度,但是插入数度就很慢,在大数据插入前最好能看一下表的索引。如果索引过多,建议删掉,插入或者更新数据后,再重新建索引。
查询索引:
select * from pg_indexes where tablename='表名';
- 1
三 触发器
如果一张表有触发器,你往上插入数据就会非常慢。所以要删除后插入在创建

- 查看触发器 :
SELECT * FROM pg_trigger;
- 1
- 查询某个表的触发器
SELECT event_object_table
,trigger_name
,event_manipulation
,action_statement
,action_timing
FROM information_schema.triggers
WHERE event_object_table = '表名'
ORDER BY event_object_table
,event_manipulation;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
四 死锁
数据插入慢或者停滞不前有可能是 死锁
1 查询等待与锁的进程、语句等信息
select w1.pid as 等待进程, w1.mode as 等待锁模式, w2.usename as 等待用户, w2.query as 等待会话, b1.pid as 锁的进程, b1.mode 锁的锁模式, b2.usename as 锁的用户, b2.query as 锁的会话, b2.application_name 锁的应用, b2.client_addr 锁的IP地址, b2.query_start 锁的语句执行时间 from pg_locks w1 join pg_stat_activity w2 on w1.pid=w2.pid join pg_locks b1 on w1.transactionid=b1.transactionid and w1.pid!=b1.pid join pg_stat_activity b2 on b1.pid=b2.pid where not w1.granted;
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
2、杀死造成锁的进程
--中断造成锁的session,回滚未提交事物
SELECT pg_terminate_backend(pid) FROM pg_stat_activity WHERE pid='62560'
- 1
- 2
- 3
如果仍然不能杀死会话,可以在操作系统层面,kill 掉

