
- 1gmssl国密sm2(生成密钥对-私钥签字-证书验签)_gmssl sm2身份验证
- 2uni-app中使用echarts教程_uniapp echarts
- 3STL源码剖析 容器 stl_list.h
- 4- Docker 常用命令_docker run -p 80:80
- 5Unity UGUI RawImage RenderTexture完美解决方案_unity里的rawimage怎么用纯色背景
- 6定制化你的应用外观:gradio的自定义主题功能_gradio theme
- 7python编程用什么笔记本,做python哪个电脑品牌好
- 8keras loss loss_weight 作用要点总结
- 9维纳滤波及其简单实现_维纳滤波公式
- 10Unity中协程与线程的区别_unity协程和线程的区别
AI,机器学习(模式识别),深度学习的区别与联系_模式识别、机器学习、深度学习的关系
赞
踩
引言
"互联网+"已经发展的差不多了,应有尽有,空间不大,下个浪潮会不会是"AI+"?那么作为一个普通程序员,在已有C++/ java / python这样的语言技能栈的前提下,我们该如何拥抱变化,如何向人工智能(AI)靠拢?
AI,机器学习,深度学习?
近两年科技领域有些火热名词常常会被我们津津乐道,诸如"人工智能"、"模式识别"、"机器学习"、"深度学习"等。
还记得2016年Google DeepMind的AlphaGo打败了韩国的围棋大师李世乭九段,那时候在媒体描述DeepMind胜利的时候,将人工智能(AI)、机器学习(machine learning)和深度学习(deep learning)都用上了。这三者在AlphaGo击败李世乭的过程中都起了作用,但它们说的并不是一回事。
在现实生活中,我们也常常把这几个概念混淆。那么这些概念之间的关系又是怎样的呢?在回答这个问题之前,我们先来看2004年至今,人工智能、机器学习、深度学习、模式识别这些热点词汇在web搜索上的趋势分布。
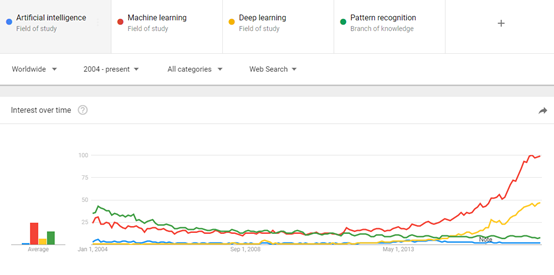
从上面这副统计图我们可以发现:
1)机器学习就像是一个真正的冠军一样持续昂首而上;
2)模式识别一开始主要是作为机器学习的代名词;
3)模式识别正在慢慢没落和消亡;
4)深度学习是个崭新的和快速攀升的领域
5)人工智能一直不愠不火
接下来我们再来看2016年至今两年内,人工智能的趋势分布:

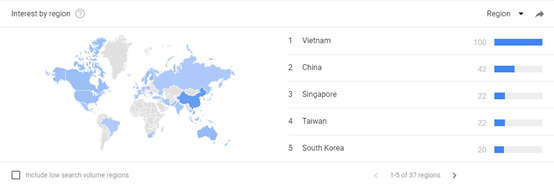
由上图我们可以得出,人工智能在亚洲诸如:越南、中国、新加坡、韩国等地颇受欢迎。
其实看了上面两组统计图,相信大家心中都有了个底了。那么接下来,我们就切入正题,来分析下人工智能、机器学习、深度学习间的关系。
首先,我们用一幅图片来解释下这三者间的关系:

如上图,人工智能是最早出现的,也是最大、最外侧的同心圆;其次是机器学习,稍晚一点;最内侧,是深度学习,当今人工智能大爆炸的核心驱动。
五十年代,人工智能曾一度被极为看好。之后,人工智能的一些较小的子集发展了起来。后来70年代、80年代、90年代初,模式识别兴起了,那时候的智能信号处理真的火(CVPR),再接着是机器学习,然后是深度学习。深度学习又是机器学习的子集。深度学习造成了前所未有的巨大的影响。
概念的提出到走向繁荣
1956年,几个计算机科学家相聚在达特茅斯会议(Dartmouth Conferences),提出了"人工智能"的概念。
过去几年,尤其是2015年以来,人工智能开始大爆发。很大一部分是由于GPU的广泛应用,使得并行计算变得更快、更便宜、更有效。当然,无限拓展的存储能力和骤然爆发的数据洪流(大数据)的组合拳,也使得图像数据、文本数据、交易数据、映射数据全面海量爆发。
人工智能应该是一个最老的术语了,同时也是最含糊的。它在过去50年里经历了几度兴衰。当你遇到一个说自己是做人工智能的人,你可以有两种选择:要么摆个嘲笑的表情,要么抽出一张纸,记录下他所说的一切。
人工智能—为机器赋予人的智能
早在1956年夏天那次会议,人工智能的先驱们就梦想着用当时刚刚出现的计算机来构造复杂的、拥有与人类智慧同样本质特性的机器。这就是我们现在所说的"强人工智能"(General AI)。这个无所不能的机器,它有着我们所有的感知(甚至比人更多),我们所有的理性,可以像我们一样思考。
人们在电影里也总是看到这样的机器:友好的,像星球大战中的C-3PO;邪恶的,如终结者。强人工智能现在还只存在于电影和科幻小说中,原因不难理解,我们还没法实现它们,至少目前还不行。
我们目前能实现的,一般被称为"弱人工智能"(Narrow AI)。弱人工智能是能够与人一样,甚至比人更好地执行特定任务的技术。例如,Pinterest上的图像分类;或者Facebook的人脸识别。
这些是弱人工智能在实践中的例子。这些技术实现的是人类智能的一些具体的局部。但它们是如何实现的?这种智能是从何而来?这就带我们来到同心圆的里面一层,机器学习。
机器学习—一种实现人工智能的方法
在90年代初,人们开始意识到一种可以更有效地构建模式识别算法的方法,那就是用数据(可以通过廉价劳动力采集获得)去替换专家(具有很多图像方面知识的人)。因此,我们搜集大量的人脸和非人脸图像,再选择一个算法,然后冲着咖啡、晒着太阳,等着计算机完成对这些图像的学习。这就是机器学习的思想。
在21世纪中期,机器学习成为了计算机科学领域一个重要的研究课题,计算机科学家们开始将这些想法应用到更大范围的问题上,不再限于识别字符、识别猫和狗或者识别图像中的某个目标等等这些问题。研究人员开始将机器学习应用到机器人(强化学习,操控,行动规划,抓取)、基因数据的分析和金融市场的预测中。另外,机器学习与图论的联姻也成就了一个新的课题---图模型。每一个机器人专家都"无奈地"成为了机器学习专家,同时,机器学习也迅速成为了众人渴望的必备技能之一。然而,"机器学习"这个概念对底层算法只字未提。我们已经看到凸优化、核方法、支持向量机和Boosting算法等都有各自辉煌的时期。再加上一些人工设计的特征,那在机器学习领域,我们就有了很多的方法,很多不同的思想流派,然而,对于一个新人来说,对特征和算法的选择依然一头雾水,没有清晰的指导原则。但,值得庆幸的是,这一切即将改变……
深度学习—一种实现机器学习的技术
人工神经网络是深度学习的起源
人工神经网络(Artificial Neural Networks)是早期机器学习中的一个重要的算法,历经数十年风风雨雨。神经网络的原理是受我们大脑的生理结构——互相交叉相连的神经元启发。但与大脑中一个神经元可以连接一定距离内的任意神经元不同,人工神经网络具有离散的层、连接和数据传播的方向。
例如,我们可以把一幅图像切分成图像块,输入到神经网络的第一层。在第一层的每一个神经元都把数据传递到第二层。第二层的神经元也是完成类似的工作,把数据传递到第三层,以此类推,直到最后一层,然后生成结果。
每一个神经元都为它的输入分配权重,这个权重的正确与否与其执行的任务直接相关。最终的输出由这些权重加总来决定。
我们以识别stop标志牌为例

可以将图片"分割"成如下一些特性:八边形的外形、旧火车般的红颜色、鲜明突出的字母、交通标志的典型尺寸和静止不动运动特性等等。神经网络的任务就是给出结论,它到底是不是一个停止标志牌。神经网络会根据所有权重,给出一个经过深思熟虑的猜测——"概率向量"。
这个例子里,系统可能会给出这样的结果:86%可能是一个停止标志牌;7%的可能是一个限速标志牌;5%的可能是一个风筝挂在树上等等。然后网络结构告知神经网络,它的结论是否正确。
其实在人工智能出现的早期,神经网络就已经存在了,但神经网络对于"智能"的贡献微乎其微。主要问题是,即使是最基本的神经网络,也需要大量的运算。神经网络算法的运算需求难以得到满足。
不过,还是有一些虔诚的研究团队,以多伦多大学的Geoffrey Hinton为代表,坚持研究,实现了以超算为目标的并行算法的运行与概念证明。但也直到GPU得到广泛应用,这些努力才见到成效。
我们回过头来看这个停止标志识别的例子。神经网络是调制、训练出来的,时不时还是很容易出错的。它最需要的,就是训练。需要成百上千甚至几百万张图像来训练,直到神经元的输入的权值都被调制得十分精确,无论是否有雾,晴天还是雨天,每次都能得到正确的结果。
那么扯了这么多的神经网络,那么深度学习在哪里呢?大家可以看个2012年吴恩达(Andrew Ng)在Google实现了神经网络学习到猫的样子的采访语音。
Ng的突破在于,把这些神经网络从基础上显著地增大了。层数非常多,神经元也非常多,然后给系统输入海量的数据,来训练网络。在吴教授这里,数据是一千万YouTube视频中的图像。Ng为深度学习(deep learning)加入了"深度"(deep)。这里的"深度"就是说神经网络中众多的层。
对于深度学习,还存在很多没有解决的问题。既没有完整的关于深度学习有效性的理论,也没有任何一本能超越机器学习的指南或者书。另外,深度学习不是万能的,它有足够的理由能日益流行,但始终无法接管整个世界。不过,只要你不断增加你的机器学习技能,你的饭碗无忧。但也不要对深度框架过于崇拜,不要害怕对这些框架进行裁剪和调整,以得到和你的学习算法能协同工作的软件框架。未来的Linux内核也许会在Caffe(一个非常流行的深度学习框架)上运行,然而,伟大的产品总是需要伟大的愿景、领域的专业知识、市场的开发,和最重要的:人类的创造力。


