
- 1基于单片机的智能手环系统设计_手环加速度传感器计步测距算法
- 2云服务器(ubuntu)安装stable diffusion-安装记录_ubuntu安装stable-diffusion
- 3YOLOv5核心基础知识讲解_yolov5江大白
- 4最长公共子串(子序列)、最长递增子序列、最长回文子串等问题_最长递增子序列lis、最大连续子序列和、最大连续子序列乘积
- 5vue3第三节(v-model 执行原理)
- 6配置 服务器 +安装系统 dell_dell服务器装系统
- 7个人玩航拍,如何申请无人机空域?
- 8Linux系统安装/卸载软件(tar/rpm/dpkg)的总结
- 9基于numpy.einsum的张量网络计算
- 10华为OD招聘_华为od目标院校
PYTORCH-KALDI语音识别工具包_pykaldi
赞
踩
PYTORCH-KALDI语音识别工具包
Mirco Ravanelli1,Titouan Parcollet2,Yoshua Bengio1 *
Mila, Universit´e de Montr´eal , ∗CIFAR Fellow
LIA, Universit´e d’Avignon
目录
本内容部分原创,因作者才疏学浅,偶有纰漏,望不吝指出。本内容由灵声讯音频-语音算法实验室整理创作,转载和使用请与“灵声讯”联系,联系方式:音频/识别/合成算法QQ群(696554058)
摘要
开源软件的实用性在主流语音识别和深度学习的普及中扮演着重要的角色。例如,Kaldi是目前用于开发最先进的语音识别器的既定框架。 PyTorch被用来采用Python语言构建神经网络,并且由于其简单性和灵活性,最近在机器学习社区中产生了巨大的兴趣。
PyTorch-Kaldi项目旨在弥合这些流行工具包之间的差距,且试图继承Kaldi的效率和PyTorch的灵活性。 在这些软件之间它不仅接口简单,而且还嵌入了一些用于开发现代语音识别器的有用功能。例如,该代码专门设计用于自然插入用户定义的声学模型。作为替代方案,用户可以利用多个预先实现的神经网络,这些神经网络可以使用直观的配置文件进行定制。 PyTorch-Kaldi支持多种特征和标签流以及神经网络的组合,可以使用复杂的神经架构。该工具包与丰富的文档一起公开发布,旨在在本地或HPC群集上正常工作。
在多个数据集和任务上进行的实验表明,PyTorch-Kaldi可以有效地用于开发现代最先进的语音识别器。
关键词:语音识别,深度学习,Kaldi,PyTorch。
1.引言
在过去几年中,我们目睹了自动语音识别(ASR)技术的逐步改进和成熟[1,2],这些技术已经达到了前所未有的性能水平,现在已被全球数百万用户使用。
深度学习正在发挥这一技术突破的关键作用[3],这有助于战胜先前基于高斯混合模型(GMM)的语音识别器。除了深度学习外,其他因素在该领域的发展中也发挥了作用。许多与语音相关的项目,如AMI [4](数据集名称)和DIRHA [5]以及CHiME [6],Babel和Aspire等语音识别挑战,都极大地促进了ASR的发展。 Librispeech [7]等大型数据集的公开发布也为建立通用的评估框架和任务发挥了重要作用。
在其他因素中,开源软件的开发,如HTK [8],Julius [9],CMU-Sphinx,RWTH-ASR [10],LIA-ASR [11]以及最近的Kaldi工具包[12]进一步帮助推广ASR,使得新型ASR应用研究和开发变得更加容易。
Kaldi目前是最受欢迎的ASR工具包。它依赖于有限状态转换器(FST)[13],并为有效地实施最先进的语音识别系统提供了一组C ++库。此外,该工具包包括一全套使用方法,涵盖了所有最流行的语音语料库。在开发ASR这种特定软件的同时,一些通用的深度学习框架,如Theano [14],TensorFlow [15]和CNTK [16],已经在机器学习社区中得到普及。这些工具包在神经网络设计中提供了极大的灵活性,可用于各种深度学习应用。
PyTorch [17]是一个新型的python包,它通过适当的自动梯度计算程序实现了基于GPU的张量计算,并促进了神经架构的设计。 它的一个有趣特性在于其现代和灵活的设计,即自然就支持动态神经网络。实际上,计算图是在运行时动态构建的,而不是静态编译的。
PyTorch-Kaldi项目的重点是在弥合Kaldi和PyTorch1之间的间隙。我们的工具包在PyTorch中实现声学模型,同时使用Kaldi执行特征提取,标签/对齐计算和解码,使其适合开发最先进的DNN-HMM语音识别器。 PyTorch-Kaldi本身支持多种DNN,CNN和RNN模型。还支持深度学习模型,声学特征和标签之间的组合,从而能够使用复杂的神经架构。例如,用户可以在CNN,LSTM和DNN之间使用级联,或者并行运行共享一些隐藏层的多个模型。用户还可以探索不同的声学特征,上下文持续时间,神经元激励(例如,ReLU,leaky ReLU),标准化(例如,batch [18]和layer normalization[19]),成本函数,正则化策略(例如,L2,丢失[20]通过简单的配置文件编辑,优化算法(例如,Adam [21],RMSPROP)和ASR系统的许多其他参数。
该工具包旨在使用户定义的声学模型的集成尽可能简单。在实践中,用户即使不完全熟悉复杂的语音识别流程,也可以在PyTorch-Kaldi中嵌入他们的深度学习模型并进行ASR实验。该工具包可以在本地计算机或者HPC集群上执行计算,并支持多GPU训练,支持恢复策略和自动数据分块。
在几个数据集和任务上进行的实验表明,PyTorch-Kaldi可以轻松开发出具有竞争力的最先进的语音识别系统。
2. PYTORCH-KALDI项目
最近使用python语言开发了一些其他语音识别工具包。例如,PyKaldi [22]是一个易于使用的Python包,它封装了c++写的Kaldi和OpenFst库。然而,与我们的工具包不同,PyKaldi的当前版本并没有提供几个以前实现的和已经使用的神经网络模型。 另一个python项目是ESPnet [23]。 ESPnet是一个端到端的语音处理工具包,主要侧重于端到端语音识别和端到端的文本到语音转换。 与我们项目的主要区别在于当前版本的PyTorch-Kaldi实现了混合DNN-HMM语音识别器。(www.github.com/mravanelli/pytorch-kaldi/ )

图1:PyTorch-Kaldi架构框图
PyTorch-Kaldi采用的架构框图如图1所示。主要脚本run_exp.py是用python编写的,用于管理ASR系统中涉及的所有阶段,包括特征和标签提取,训练,验证,解码和评分。该工具包将在以下小节中详细介绍。
2.1 配置文件
主脚本将INI格式中的配置文件作为输入,它由几部分组成。 其中,[Exp]部分指定了一些高级信息,例如用于实验的文件夹,训练时期的数量,随机种子。它还允许用户指定是否必须在CPU,GPU或多个GPU上进行实验。配置文件继续用[dataset*]部分表示,它用于指定有关要素和标签的信息,包括存储它们的路径,上下文窗口的特征[24]以及必须分割语音数据集的块数。神经网络模型在[architechure*]部分,而[model]部分定义了这些神经网络的组合方式。后一部分开发了一种由run_exp.py脚本自动解释的简单元语言。 最后,在[decoding]部分中定义了解码参数的配置文件
2.2特征
使用Kaldi原生提供的C++库(例如,compute-mfcc-feats,compute-fbank-feats,compute-plp-feats)执行特征提取,有效地提取最流行的语音识别特征。计算出的系数存储在二进制存档(扩展名为.ark)中,然后使用从kaldi-io-for-python项目继承的kaldi-io实用程序导入到python环境中。然后,通过函数load-chunk处理这些特征,该函数执行上下文窗口组合,移动以及均值和方差归一化。如前所述,PyTorch-Kaldi可以管理多个特征流。例如,用户可以定义利用MFCC,FBANK,PLP和fMLLR [25]系数组合的模型。
2.3 标签
用于训练声学模型的主要标签源自语音特征与音素状态序列之间的强制对齐过程,而这种序列是由Kaldi用语音决策树计算的且依赖于上下文。为了实现多任务学习,PyTorch-Kaldi支持多个标签。例如,可以联合加载上下文相关和上下文无关的任务,并使用后者执行单音素正则化[26,27]。也可以使用基于执行不同任务的神经网络生态系统的模型,如在语音增强和语音识别之间的联合训练的背景下[28,29]或在最近提出的深度神经合作网络的背景下进行的模型。
2.4 块和小批量组合
PyTorch-Kaldi自动将整个数据集拆分为多个块,这些块由从完整语料库中随机抽样的标签和特征组成。然后将每个块存储到GPU或CPU存储器中并由神经训练算法run_nn.py运行处理。该工具包在每个时期动态地组成不同的块。然后从它们中获得一组小批量的数据集。小批量集合由少数用于梯度计算和参数优化的训练样例组成。
小批量集的聚集方式很大程度上取决于神经网络的类型。对于前馈模型,小批量集由随机移动特征和从块中采样的标签组成。对于周期性网络,小批量集合必须由完整的句子组成。然而,不同的句子可能具有不同的持续时间,使得制作相同大小的小批量集合需要零扩充。 PyTorch-Kaldi根据它们的长度按升序对语音序列进行排序(即,首先处理短句)。这种方法最大限度地减少了零扩充的需要,并证明有助于避免批量标准化统计数据的可能偏差。此外,已经证明有效果的是能略微提高性能并改善梯度的数值稳定性。
2.5 DNN声学建模
每个小批量集由PyTorch实现的神经网络来处理,该神经网络将特征作为输入,并将依赖于上下文的音素状态上的一组后验概率作为输出。该代码旨在轻松插入自定义模型。正如图2中公开的伪代码所写的那样,可以通过在neural_nets.py中添加新类来简单地定义新模型。该类必须由通过初始化指定参数的初始化方法,以及定义要执行的计算的正向方法组成。
(3 www.github.com/vesis84/kaldi-io-for-python )

作为替代方案,在工具包中原生地实现了许多预先定义的最先进的神经模型。当前版本支持标准MLP,CNN,RNN,LSTM和GRU模型。此外,它支持一些先进的循环架构,例如最近提出的Light GRU [31]和双正则化RNN [32]。 SincNet模型[33,34]也用于直接从语音波形实现语音识别。可以用实现随机搜索算法的程序来调整模型的超参数(例如学习速率,神经元数量,层数,丢失因子等)[35]。
2.6 解码和评分
在基于反馈HMM的Kaldi解码器之前,由神经网络产生的声学后验概率被它们的先验概率归一化了。解码器将声学分数与由n-gram语言模型导出的语言概率合并,并尝试使用波束搜索算法检索在语音信号中发出的单词序列。使用NIST SCTK评分工具包计算最终的字错误率(WER)分数。
3.实验设置
在以下小节中,描述了实验采用的语料库和DNN模型设置。
3.1语料库和任务
第一组实验是使用TIMIT语料库进行的,考虑到标准音素识别任务(与Kaldi s5匹配[12]一致)。
为了在更具挑战性的情景中验证我们的模型,还在DIRHA-English数据集[36,37]的远场谈话条件下进行了实验。训练基于最初的WSJ-5k语料库(由83名说话者的7,138个句子组成),这些语句受到在家庭环境中测量的一组冲激响应的污染[37]。测试阶段使用了数据集的实际部分进行的,其中包括由上述六位美国本土人士在上述环境中发出的409个WSJ句子。
使用CHiME 4数据集[6]进行了额外的实验,该数据集基于在四个嘈杂环境(公共汽车,咖啡馆,步行区和街道交叉点)中记录的语音数据。训练集由43个690个嘈杂的WSJ句子组成,这些句子由五个麦克风(安排在平板电脑上)录制,并由总共87个扬声器发出。在这项工作中考虑的测试集ET-real基于由四个发言者发出的1,320个真实句子,而子集DT-real已用于参数优化。 CHiME实验是基于单通道的设置[6]。
最后,使用LibriSpeech [7]数据集进行实验。我们使用由100小时组成的训练子集和用于参数搜索的dev-clean集。使用继承自Kaldi s5方法的fglarge解码图在test-clean部分上报告测试结果。

3.2 DNN设置
实验考虑了不同的声学特征,即39个MFCC(13个静态+Δ+ΔΔ),40个对数滤波器组特征(FBANKS),以及40个fMLLR特征[25](根据Kaldi中s5所述方法进行提取),使用25 ms的窗口(帧长)计算,重叠(帧移)为10 ms。根据Glorot的方案[38]初始化前馈模型,而使用正交矩阵初始化周期权重[39]。周期性丢失被用作正则化技术[40]。正如[41]中提出的那样,仅对前馈连接采用批量归一化。使用运行24个时期的RMSprop算法完成优化。在每个时期之后监测开发组的表现,并且当相对性能改善低于0.1%时,学习率减半。在开发数据集上调整模型的主要参数(即,学习速率,隐藏层数,每层隐藏神经元,丢失因子以及双正则化项λ)。
4.基线
在本节中,我们将讨论使用TIMIT,DIRHA,CHiME和LibriSpeech数据集获得的基线。作为对PyTorch-Kaldi工具包主要功能的展示,我们首先报告了对TIMIT进行的实验验证。
表1显示了使用不同特征的几个前馈和重复模型获得的性能。为了确保架构之间更准确的比较,针对每个模型和特征进行了不同的初始化种子的五个实验。该表因此报告平均音素错误率(PER)5。结果表明,正如预期的那样,由于扬声器适应过程,fMLLR功能优于MFCC和FBANKs系数。循环模型显着优于标准MLP模型,特别是在使用LSTM,GRU和Li-GRU架构时,通过乘法门(multiplicative gates)有效地解决梯度消失问题。使用Li-GRU模型[31]获得最佳结果(PER = 14.2%),该模型基于单个门,因此比标准GRU节省了33%的计算。

表2详细介绍了PyTorch-Kaldi中用于改善ASR性能的一些常用技术的影响。第一行(基线)报告使用基本的循环模型实现的性能,其中不采用诸如压差和批量归一化的强大技术。第二行突出显示在训练期间逐渐增加序列长度时实现的性能增益。在这种情况下,我们通过在100步(即,大约1秒的语音)截断语音句子开始训练,并且逐渐地在每个时期加倍最大序列持续时间。这种简单的策略通常可以提高系统性能,因为它鼓励模型首先关注短期依赖关系,并且只在稍后阶段学习长期关联。第三行显示了添加重复丢失时所实现的改进。与[40,41]类似,我们对所有时间步骤应用相同的压差掩模以避免梯度消失问题。相反,第四行显示了从批量标准化得到的好处[18]。最后,最后一行显示了在应用单音正则化时所达到的性能[27]。在这种情况下,我们通过两个softmax分类器采用多任务学习策略:第一个估计依赖于上下文的状态,而第二个预测单音目标。正如[27]中所观察到的,我们的结果证实该技术可以成功地用作有效的正则化器。
到目前为止讨论的实验是基于单个神经元的模型。在表3中,我们将最好的Li-GRU系统与基于前馈和循环模型组合的更复杂的架构进行比较,这些模型由一系列特征串联。据我们所知,后一系统实现的PER = 13.8%会在TIMIT测试集上产生最佳公开的性能。
以前的成就是基于Kaldi计算的特征。但是,在PyTorch-Kaldi中,用户可以使用自己的功能。表4显示了通过标准FBANKs系数或直接原始波形馈送的卷积模型获得的结果。基于原始样本的标准CNN与由FBANK特征馈送的CNN类似地执行。 SincNet [33]观察到性能提升,其语音识别的有效性首次突出显示。
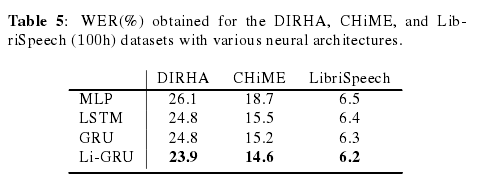
我们现在将实验验证扩展到其他数据集。 在这方面,表5显示了在DIRHA,CHiME和Librispeech(100h)数据集上实现的性能。 该表始终显示了Li-GRU模型的更好性能,证实了我们之前在TIMIT上取得的成就。 DIRHA和CHiME的结果显示了所提出的工具包在噪声条件下的有效性。 为了进行比较,在egs / chime4 / s5中提出了最佳Kaldi基线1ch的WER(%)= 18.1%。使用ESPnet训练的端到端系统达到WER(%)= 44.99%,确认端到端语音识别对声学条件的挑战是多么重要。 DIRHA代表了另一项非常具有挑战性的任务,其特点是存在相当大的噪音和混响。在此数据集上获得的WER = 23.9%表示迄今为止在单麦克风任务上发布的最佳性能。最后,使用Librispeech获得的性能优于所考虑的100小时子集的相应p-norm的Kaldi基线(W ER = 6.5%)。
5结论
本文描述了PyTorch-Kaldi项目,这是一项旨在弥合Kaldi和PyTorch之间间隙的新举措。该工具包核心是使ASR系统的开发更简单,更灵活,允许用户轻松插入其定制的声学模型。 PyTorch-Kaldi还支持神经网络架构,功能和标签的组合,允许用户使用复杂的ASR流水线。实验证实,PyTorch-Kaldi可以在一些流行的语音识别任务和数据集中实现最先进的结果。
目前版本的PyTorch-Kaldi已经公开发布,并附有详细的文档。该项目仍处于初始阶段,我们邀请所有潜在的贡献者参与其中。我们希望建立一个足够大的开发人员社区,以逐步维护,改进和扩展我们当前工具包的功能。未来,我们计划增加预先实施的模型数量,支持神经语言模型训练/重新训练,序列判别训练,在线语音识别以及端到端训练。
6.致谢
我们要感谢Maurizio Omologo,Enzo Telk和Antonio Mazzaldi的有益评论。这项研究部分得到了Calcul Qu'ebec和Compute Canada的支持。
本内容部分原创,因作者才疏学浅,偶有纰漏,望不吝指出。本内容由灵声讯音频-语音算法实验室整理创作,转载和使用请与“灵声讯”联系,联系方式:音频/识别/合成算法QQ群(696554058)


