
热门标签
热门文章
- 1Githack下载安装教程 windows_githack安装过程
- 2【开发环境】Windows下搭建TVM编译器_windows下使用tvm
- 3python深度学习stadardscalar fit_transform数据处理、contrib使用、Session多种创建、in_top_k、argmax、equal、cas、extend map_pythonstandardscaler().fit_transform在做什么
- 4不使用+-*/计算两个数的和
- 5C语言与Linux系统文件操作函数大全_linux c语音 open 二进制文件
- 6Unix下 压缩和解压缩命令_hp unix 解压zip
- 731. linux中firewalld的图形化管理和命令的使用_firewalld 进入图形界面配置的命令 。
- 8python安装好后在哪里打开_python安装后的目录在哪里
- 9centos 7 中没有iptables 和service iptables save 指令使用失败问题解决方案_no package iptables-service available.
- 10【Yi-34B-Chat-Int4】使用4个2080Ti显卡11G版本,运行Yi-34B模型,5年前老显卡是支持的,可以正常运行,速度 21 words/s,vllm要求算力在7以上的显卡就可以
当前位置: article > 正文
MIT-BEVFusion系列九--CUDA-BEVFusion部署4 c++解析pytorch导出的tensor数据
作者:不正经 | 2024-02-29 20:08:31
赞
踩
MIT-BEVFusion系列九--CUDA-BEVFusion部署4 c++解析pytorch导出的tensor数据
该系列文章与qwe、Dorothea一同创作,喜欢的话不妨点个赞。
在create_core方法结束后,我们的视角回到了main.cpp中。继续来看接下来的流程。本章的重点在于pytorch导出的tensor数据的解析。
创建流
流用于表示一系列的命令(如内存传输命令和核函数执行命令)在 GPU 上的执行顺序。流中的命令按照它们被插入的顺序在 GPU 上执行,但不同流中的命令可以并行执行。这里主要用于更新数据、推理和可视化时使用。
打印 engine 信息
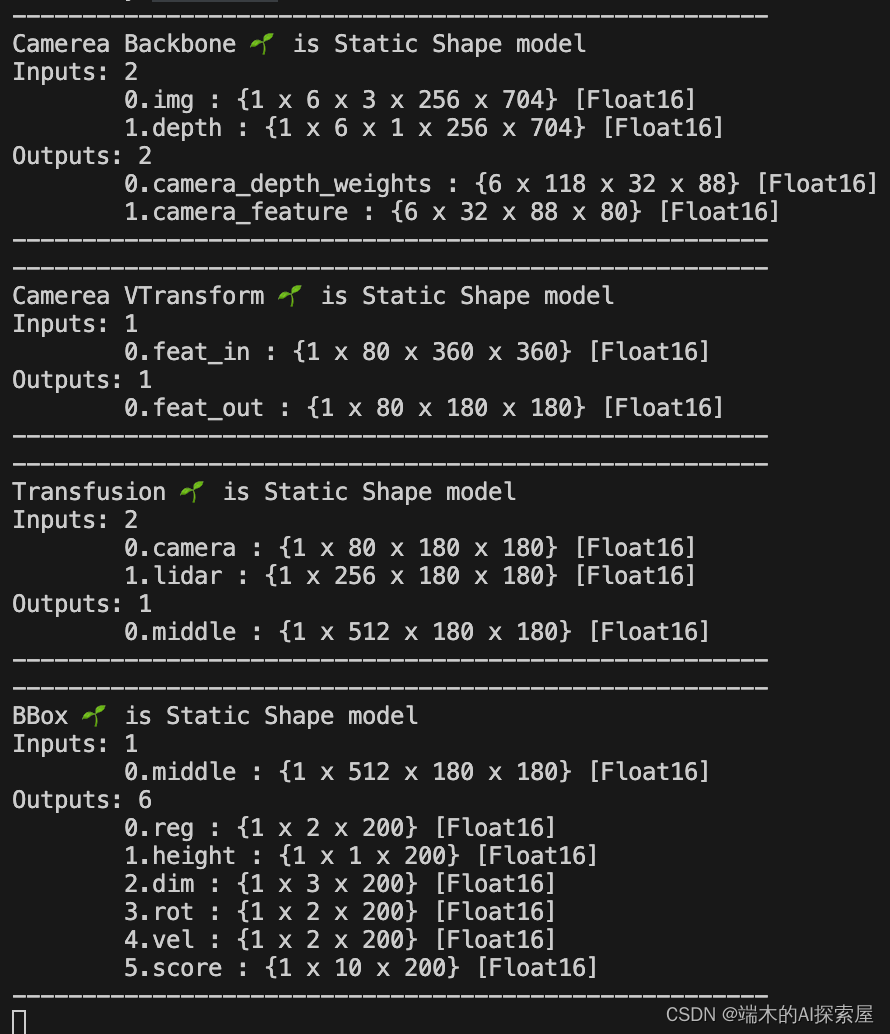
这里会打印出执行CUDA-BEVFusion时,终端打印的信息中的网络信息。
从这里我们能清楚的看到一下几点:
- 1)当前网络属于哪个部分。
- 2)网络输入和输出的个数,数据形状
输出的网络数量与onnx数量是一一对应的。
打印结果

内部流程
print的具体实现在下方。
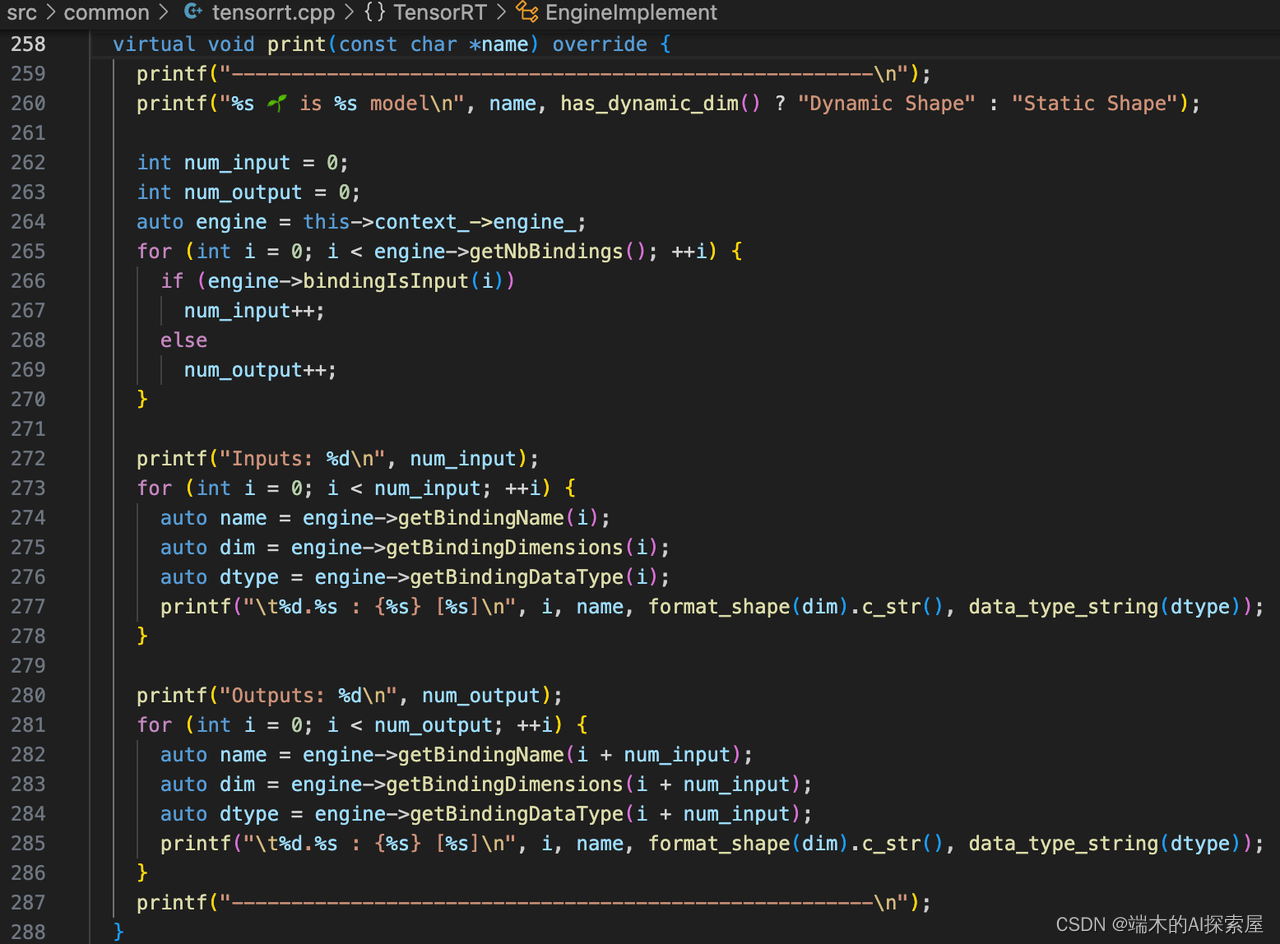
这部分用于打印这四个 engine 的信息,包含模型名称和绑定点的信息(输入输出是否为动态形状,输入输出节点索引、名称、维度和类型)。
启动计时功能
是否计时,这里设置为true

core是CoreImplement的一个实例,而CoreImplement继承了类Core

在类Core中set_timer是一个纯虚方法。

用于后续判断是否打印推理时每个模块的用时。
加载变换矩阵并更新数据(重要)
nv::Tensor、nv::format是 Nvidia 提供在src/common中的工具- 下图 246 行之 249 行,加载一系列准备好的矩阵参数。
- 下图所加载的
.tensor后缀的文件,均是从pytorch中导出,保存的二进制文件。


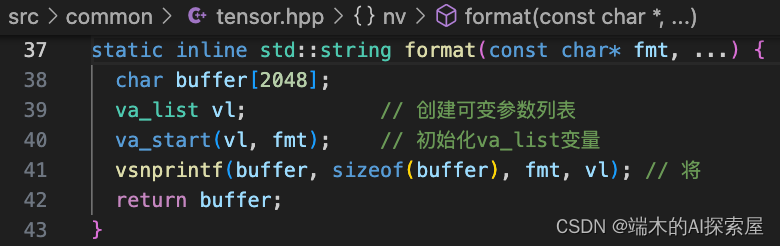
- 格式化字符串传入:调用
nv::format函数,传入格式字符串"%s/camera2lidar.tensor"和data指针。这里的%s是一个占位符,用于指示将在这个位置插入一个字符串。 - 变量参数处理:在
format函数内部,函数首先定义一个字符数组buffer[2048]作为存储结果的缓冲区。然后,它使用va_list vl初始化可变参数列表,并通过va_start(vl, fmt)宏开始访问这些参数。 - 字符串格式化:使用
vsnprintf函数,将data指针所指向的字符串(即"example-data")和格式字符串合并。vsnprintf根据格式字符串"%s/camera2lidar.tensor"替换%s为data指向的字符串,因此格式化后的字符串将变为"example-data/camera2lidar.tensor"。 - 安全检查和内存管理:
vsnprintf函数使用sizeof(buffer)确保不会向buffer写入超出其容量的数据,从而避免缓冲区溢出。这是一个重要的安全特性,确保即使格式化的字符串非常长,也不会导致内存损坏。
5. 返回结果:格式化后的字符串存储在buffer中。format函数最后将buffer转换为std::string类型并返回这个字符串。
- 加载结果,以 加载camera2lidar 为例:
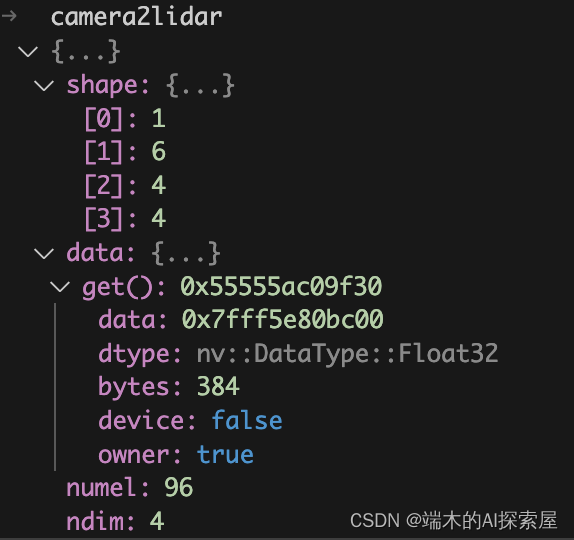
通过上图,我们就可以发现,.tensor后缀的文件存储的数据,可以分为数据头,和数据两个部分。
数据头,即描述数据信息的属性,例如shape、numel、ndim。描述数据的信息。
数据,即具体的数据的起始地址。
通过数据的读取,我们可以大致看一下作者是如何设计的。
内部实现
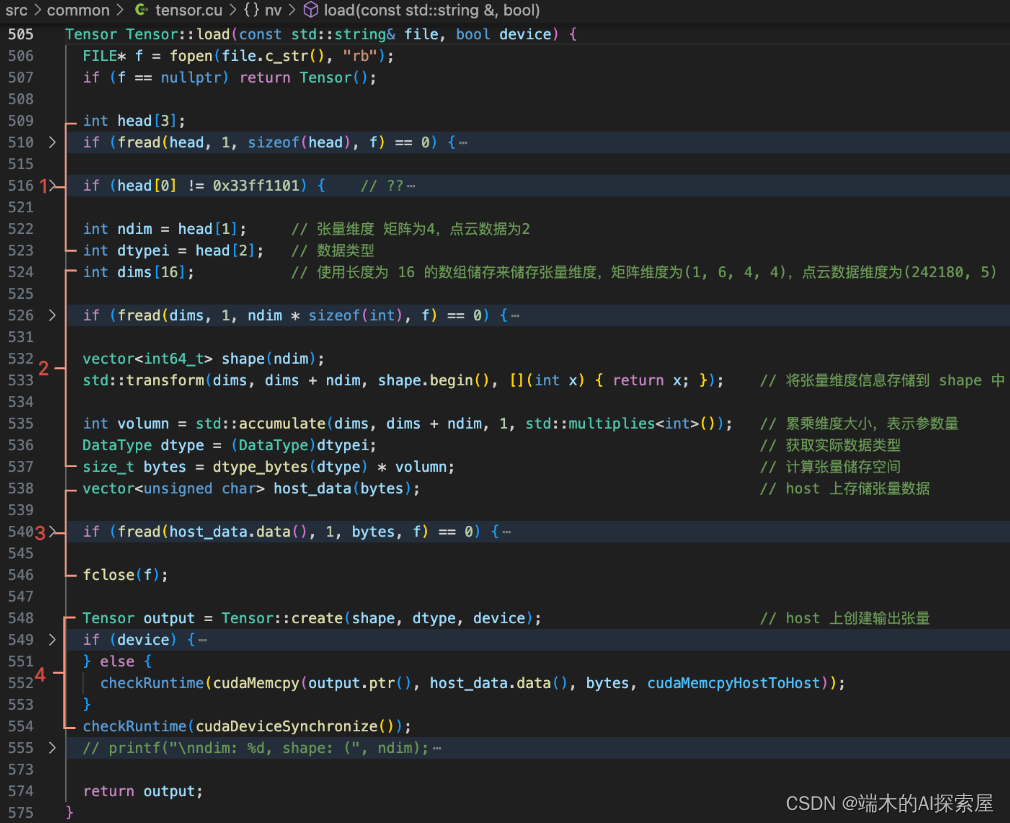
- 取文件前 3 个 int 字节大小的内容,第一个是 magic_number,类似识别码,第二个表示数据维度数量(ndims),第三个表示数据类型 id。
- 使用
dims来存储每个维度的数值,使用shape来储存形状,用于后续创建Tensor。计算矩阵的总参数量volumn,然后通过每个数据占用空间dtype和总参数量volumn来计算储存矩阵数据需要的空间bytes。 - 读取文件中的数据,在
host上使用容器host_data来储存。 - 在
host上创建Tensor对象,并将数据拷贝到output中。

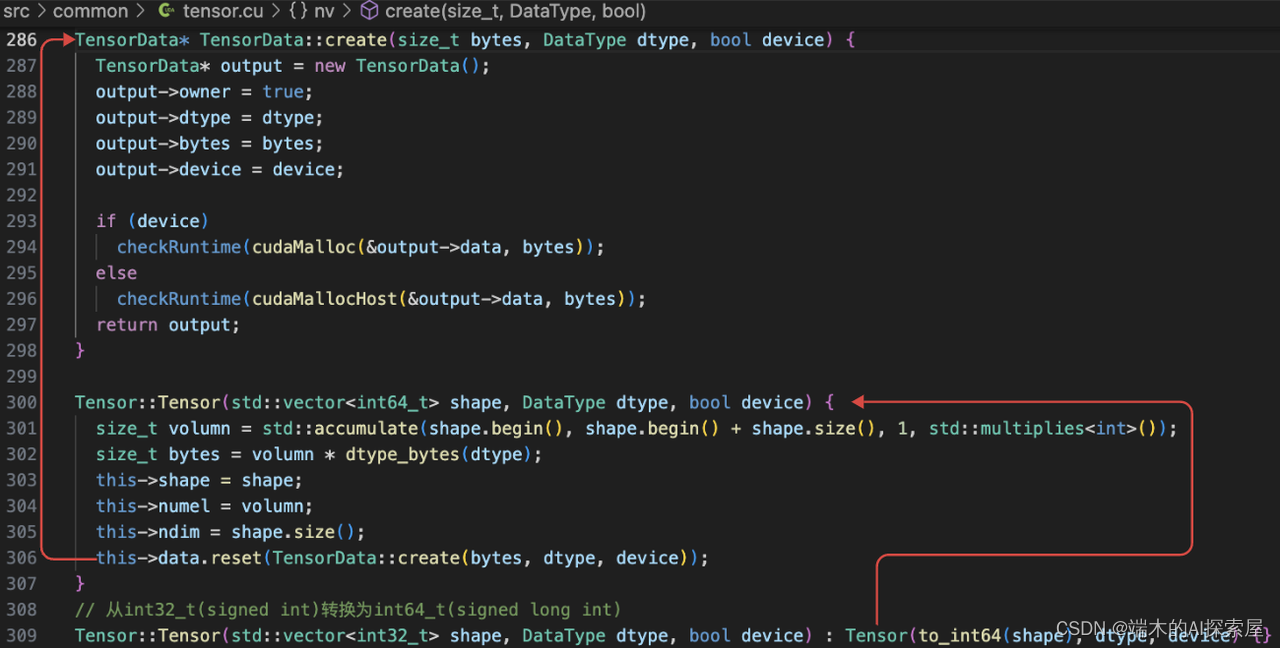
- 小结:
-
- nvidia这个仓库的src/common中的tensor解析比较重要,
nv::Tensor是一个通用的pytorch与c++数据联通的桥梁,值得一看。
- nvidia这个仓库的src/common中的tensor解析比较重要,
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/不正经/article/detail/168056?site
推荐阅读
相关标签

