
- 1SQL学习之替换函数replace()的使用_replace函数
- 2linux最新内核4.19,Linux Kernel 4.19首个维护版本更新发布 主要新特性介绍
- 3实战:使用Docker与Rust开发高性能服务
- 4pyqt开发环境python3.3+pyqt4.8.5+eric5.40安装配置_pyqt汇集了qt的跨平台应用框架和python库的跨平台解释语言
- 5多模态大模型-CogVLm 论文阅读笔记_cogvlm论文
- 6原本mybatis需要手动提交事务,Spring 与 Myabatis 整合后,为什么就是自动提交事务_mybatis-plus 每次都要手动提交吗
- 7《Clock Domain Crossing》 翻译与理解(5)多信号跨时钟域传输_jaspergold clock domain crossing verification app
- 8瀑布模型,v模型与双V模型_软件v型开发及双v
- 9tomcat是干嘛的_tomcat有什么用
- 10Python语言基础_python基础语言
LLM - 使用 Langchain 实现本地 Naive RAG_llm langchain 本地
赞
踩

目录
一.引言
上一篇博客介绍了当下 RAG 的一些发展情况,主要有 Naive RAG、Advanced RAG 以及 Modular RAG,本文通过 Python langchain 库实现一个本地 RAG 的 demo,主要是体会 RAG 搜索增强的流程。本文主要聚焦 Langchain 本地知识库的构建,后续的 LLM 推理因为本机显存的限制,大家可以参考之前推理的博客。

Tips 本文主要从三个方面介绍本地知识库的构建:
- 构建本地 Langchain 知识库
- 缓存本地 Langchain 知识库
- 读取缓存 Langchain 知识库
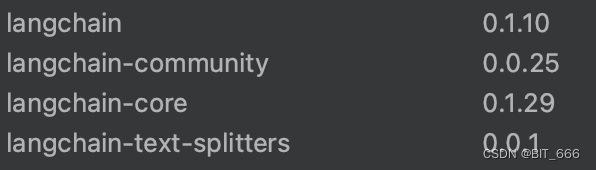
由于 Langchain 库的更新比较快,有一些 API 的引入方式与用法稍有出入,博主这里的 python 版本为 3.8.6,Langchain 相关 package 版本如下:
二.构建本地 Langchain 库
1.Doc 知识文档
由于是构建本地知识库,所以我们需要获得各个内容的文档,这里我们整理了几篇汽车的新闻作为本地知识库的内容,主要是零跑、理想、小鹏、蔚来汽车的相关新闻。

以 lx.txt 为例,其包含新闻的全部文本:
2.Split 文档切分
对于通用文本,这里建议使用 RecursiveCharacterTextSplitter 分割器进行文本切分。
- from langchain_community.document_loaders import TextLoader
- from langchain_community.embeddings import HuggingFaceEmbeddings
- from langchain_community.vectorstores.chroma import Chroma
- from langchain_text_splitters import RecursiveCharacterTextSplitter
-
-
- # 读取原始文档
- raw_documents_lp = TextLoader('/Users/xxx/langchain/LocalDB/lp.txt', encoding='utf-8').load()
- raw_documents_lx = TextLoader('/Users/xxx/langchain/LocalDB/lx.txt', encoding='utf-8').load()
-
- # 分割文档
- text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=0)
- documents_lp = text_splitter.split_documents(raw_documents_lp)
- documents_lx = text_splitter.split_documents(raw_documents_lx)
- documents = documents_lp + documents_lx
- print("documents nums:", documents.__len__())

这里加载零跑与理想的文档,如果文档多的同学直接 os.path 遍历 for 循环添加即可,我们最终得到的是多个通过 text_splitter 分割的 document 文档。其主要包含 page_content 和 metadata 两个属性,前者包含分割后的文本块 Chunk,后者包含一些元信息,主要是文档内容来源。
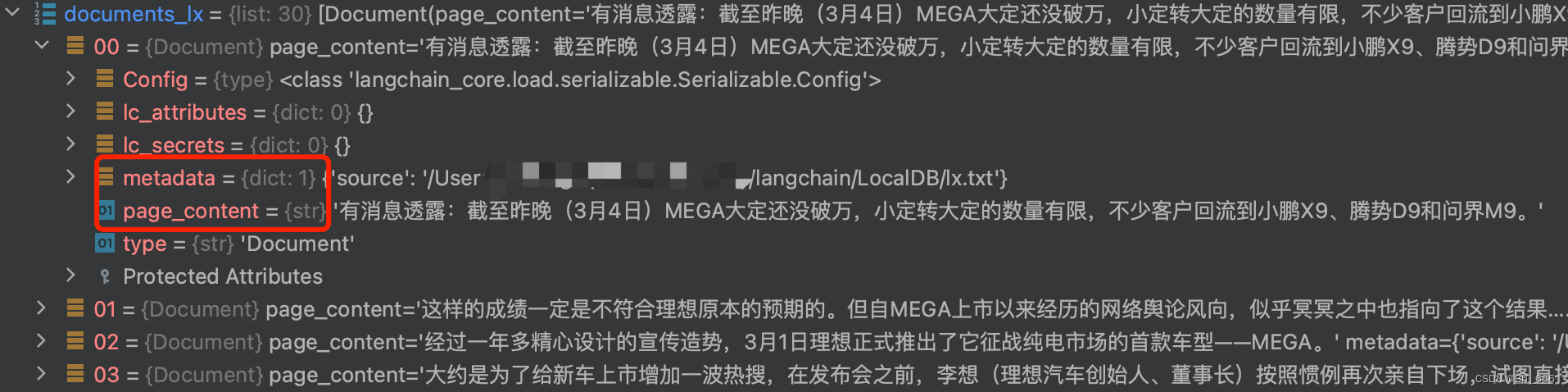
运行上述代码后会得到分割后文档数量,其中 chunk_size 代表每个块的保留大小,chunk_overlap 代表前后 content 是否有重叠,类似滑动窗口一样。
documents nums: 75
3.Encode 内容编码
由于需要通过向量存储与检索 Top-K,所以需要对应的编码器生成对应 content 的 Embedding,这里我们选择通过 HuggingFaceEmbeddings 方法来生成文本的 Embedding。
- # 生成向量(embedding)
- embedding_model_dict = {
- "mini-lm": "/Users/xxx/model/All-MiniLM-L6-V2"
- }
- EMBEDDING_MODEL = "mini-lm"
- embeddings = HuggingFaceEmbeddings(model_name=embedding_model_dict[EMBEDDING_MODEL])
由于网络连接的问题,这里博主建议把模型下载到本地文件夹中直接加载,登录 HuggignFace 官网 https://huggingface.co/sentence-transformers/ 可以检索到多个文本编码的模型:
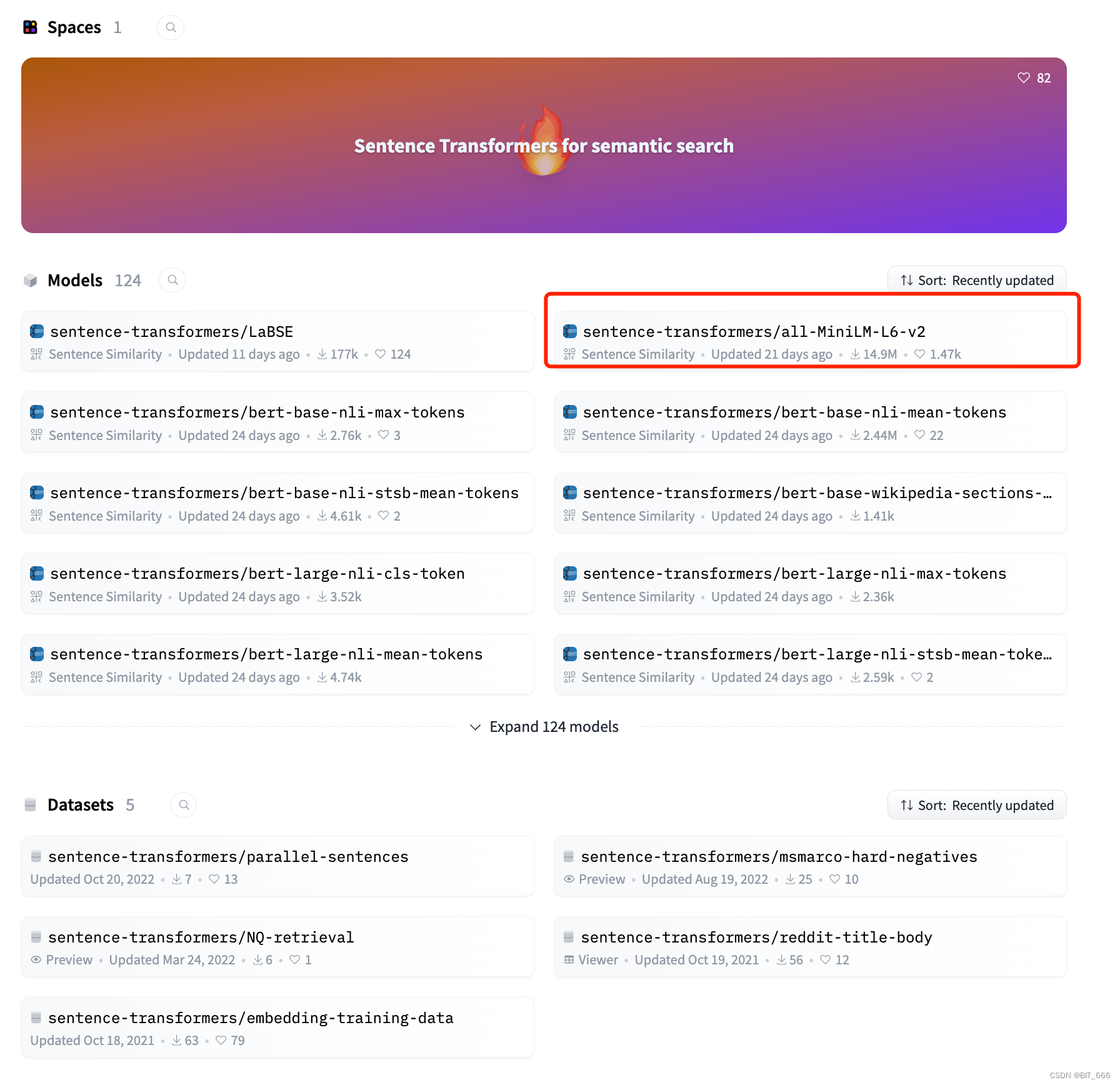
这里我们选择轻量级的 all-MiniLM-L6-v2 作为 Embedding 编码的模型,手动一个一个下载或者挂着镜像用 API 下载都可以:
执行完毕后我们获得一个可以编码的 Embedding 模型:

4.Similar 本地库构建
- db = Chroma.from_documents(documents, embedding=embeddings)
-
- # 检索
- query = "理想汽车怎么样?"
- docs = db.similarity_search(query, k=5)
-
- # 打印结果
- for doc in docs:
- print("===")
- print("metadata:", doc.metadata)
- print("page_content:", doc.page_content)
通过本地分割好的文档 documents 与指定的 embedding 模型我们构建本地 Langchain DB,通过 query 与 sim_search API 进行 Top-k 文本的获取,得到的 doc 我们可以获取其 metadata 即来源以及其对应的文本:
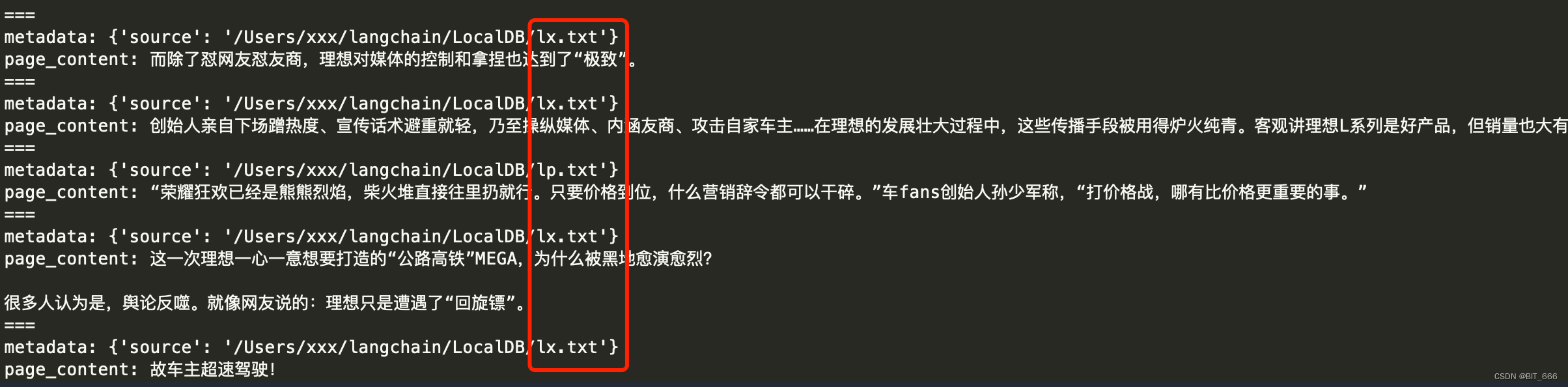
可以看到 5 条中有 4 条来自 lx.txt 即理想的文档,而一条来自 lp.txt 即零跑汽车,基于这些 page_content,我们还需要做清洗、合并等处理才能得到最终的增强信息,对用户的原始 Query 进行扩展得到最终的 Prompt 再输入 LLM 得到回复。
三.缓存本地 Langchain 库
如果不想每次都处理加载文档再构建 DB 可以预先处理并把 DB 做本地的 cache,用的时候直接读取 cache 加载即可。
- def persist():
- raw_documents_news = TextLoader('/Users/xxx/langchain/lx.txt', encoding='utf-8').load()
- text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=0)
- documents_news = text_splitter.split_documents(raw_documents_news)
- embedding_model_dict = {
- "mini-lm": "/Users/xxx/model/All-MiniLM-L6-V2"
- }
- EMBEDDING_MODEL = "mini-lm"
- # 初始化 huggingFace 的 embeddings 对象
- embeddings = HuggingFaceEmbeddings(model_name=embedding_model_dict[EMBEDDING_MODEL])
- db = Chroma.from_documents(documents_news, embeddings, persist_directory="./local_cache")
- db.persist()
- print("Save Success ...")
执行后在 cache 对应文件下生成如下文件即为成功:
缓存大小为 2mb:
![]()
四.读取本地 Langchain 库
1.Load 读取缓存
- embedding_model_dict = {
- "mini-lm": "/Users/xxx/model/All-MiniLM-L6-V2"
- }
- EMBEDDING_MODEL = "mini-lm"
- # 初始化 huggingFace 的 embeddings 对象
- embeddings = HuggingFaceEmbeddings(model_name=embedding_model_dict[EMBEDDING_MODEL])
- db = Chroma(persist_directory="/Users/xxx/langchain/local_cache", embedding_function=embeddings)
同样需要加载 embedding 模型,但是 doc 内容直接从 cache 中获取,通过 persist_directory 方法获取 Chroma Database。
2.Similar 预测
- # 检索
- query = "理想汽车"
- docs = db.similarity_search(query, k=5)
-
- # 打印结果
- for doc in docs:
- print("===")
- print("metadata:", doc.metadata)
- print("page_content:", doc.page_content)
-
- exit(0)

3.Add 添加文档
本地库存在更新慢的情况,读取缓存后如果有新的 doc 可以调用 db.add 方法添加,随后再执行查询,下面我们在 cache 的基础上引入小鹏汽车 xp.txt 的信息,并预测新的 query。
- # 添加文档
- text_splitter = RecursiveCharacterTextSplitter(chunk_size=100, chunk_overlap=0)
- raw_documents_xp = TextLoader('/Users/xxx/langchain/LocalDB/xp.txt', encoding='utf-8').load()
- documents_news = text_splitter.split_documents(raw_documents_xp)
- db.add_documents(documents_news)
加载本地 Langchain 库后,我们可以继续将新增的本地 doc 添加至 DB 中,下面我们再测试下,这次寻找与新增小鹏汽车相关的信息:
- # 检索
- query = "小鹏汽车"
- docs = db.similarity_search(query, k=5)
-
- # 打印结果
- for doc in docs:
- print("===")
- print("metadata:", doc.metadata)
- print("page_content:", doc.page_content)
-
- exit(0)
xp.txt 里小鹏汽车的关键字比较多,所以匹配下来 metadata 都指向 xp.txt,不存在之前 lx 检索到 lp 的情况:

五.总结
上面简单测试了基于 Doc 构建本地 Langchain 库的一些方法,关于更细粒度的 Langchain 和 RAG,还涉及到很多细节的点,包括对 query 的清洗与处理,对文档的清理与筛选,对 Langchain 结果的取舍与合并以及 LLM Prompt 的构建,这些细致的点大家可以一一扩散提高搜索的效果。
Tips:
Langchain 中文 API 介绍: https://www.wpsshop.cn/w/不正经/article/detail/221551

