
- 1机器学习之学习路径、学习方法、常用工具、Python、Numpy、pandas、sklearn、Tensorflow、Pytorch、Git入门教学大纲_python机器学习教程及代码
- 2鸿蒙:Harmony开发基础知识详解
- 3【java毕业设计】基于javaEE+原生Servlet+MySql的物流信息网站设计与实现(毕业论文+程序源码)——物流信息网站_servlet_mysql物流信息网的设计与实现参考文献
- 4程序人生——Java泛型和反射的使用建议
- 5家校通Android源码,基于Android的家校通系统设计与实现
- 6深度学习3:机器学习类型及应用_被称为第三类学习机器的是
- 7Python -- Pyecharts: Faker生成模拟数据_faker.guangdong_city
- 8壁式框架内力计算_框剪结构框架部分倾覆力矩规范法与轴力法合理性讨论
- 9一口气看完人工智能发展与ChatGPT_chatgpt与人工智能的发展
- 10鸿蒙(HarmonyOS)项目方舟框架(ArkUI)之Image图片组件_鸿蒙渲染image
Stable Diffusion原理_stable diffusion在训练的时候是一步预测噪声的吗
赞
踩
一、Diffusion扩散理论
1.1、 Diffusion Model(扩散模型)
Diffusion扩散模型分为两个阶段:前向过程 + 反向过程
- 前向过程:不断往输入图片中添加高斯噪声来破坏图像
- 反向过程:使用一系列马尔可夫链逐步将噪声还原为原始图片
前向过程 ——>图片中添加噪声
反向过程——>去除图片中的噪声
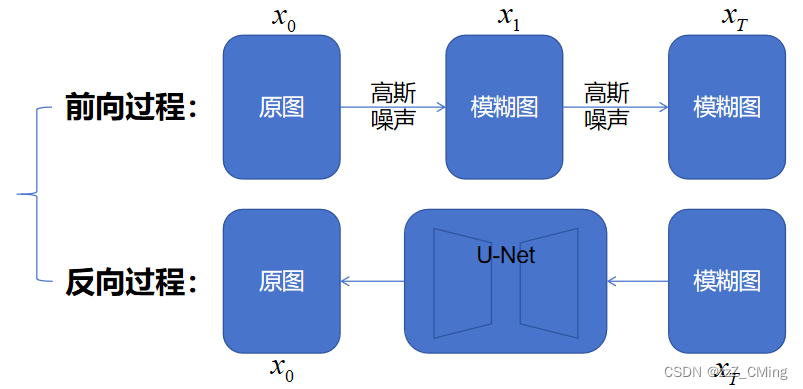
1.2、 训练过程:U-Net网络
在每一轮的训练过程中,包含以下内容:
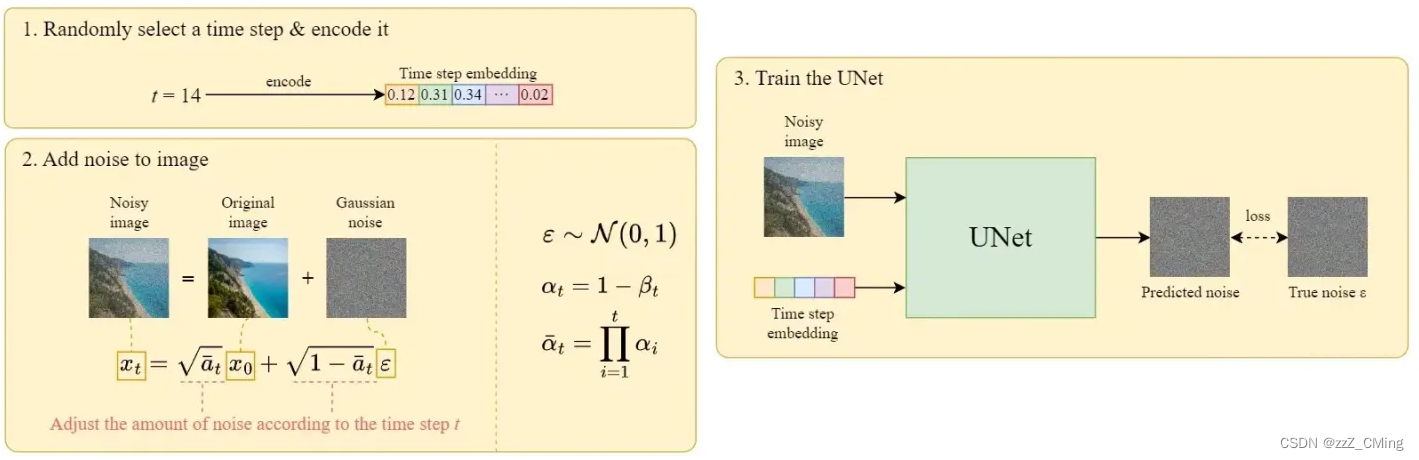
- 每一个训练样本对应一个随机时刻向量time step,编码时刻向量t转化为对应的time step Embedding向量;
- 将时刻向量t对应的高斯噪声ε应用到图片中,得到噪声图Noisy image;
- 将成组的time step Embedding向量、Noisy image注入到U-Net训练;
- U-Net输出预测噪声Predicted noise,与真实高斯噪声True noise ε,构建损失。
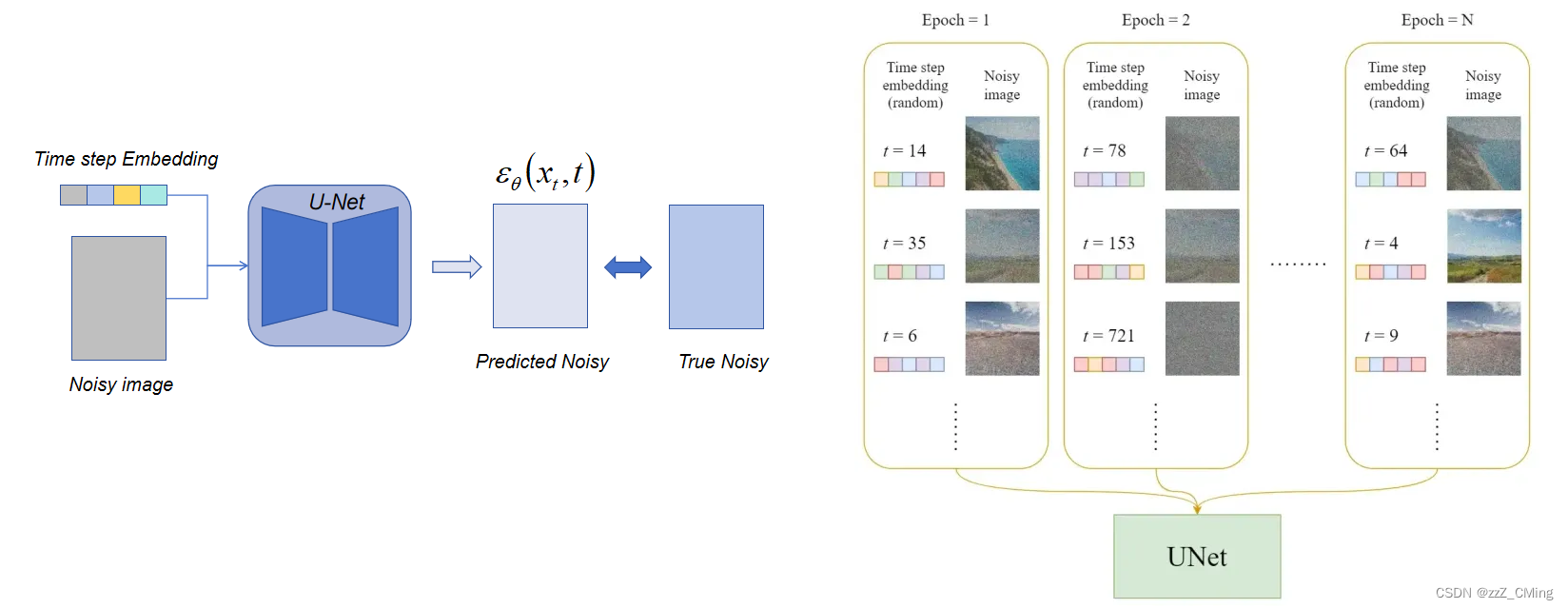
下图是每个Epoch详细的训练过程:

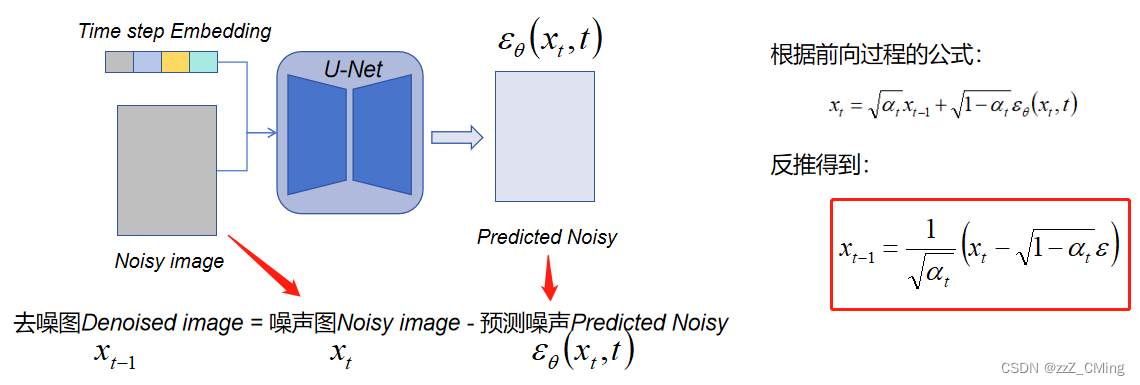
1.3、 推理过程:反向扩散
噪声图Noisy image经过训练后的U-Net网络,会得到预测噪声Predicted Noisy,而:去噪图Denoised image = 噪声图Noisy image - 预测噪声图Predicted Noisy。(计算公式省略了具体的参数,只表述逻辑关系)
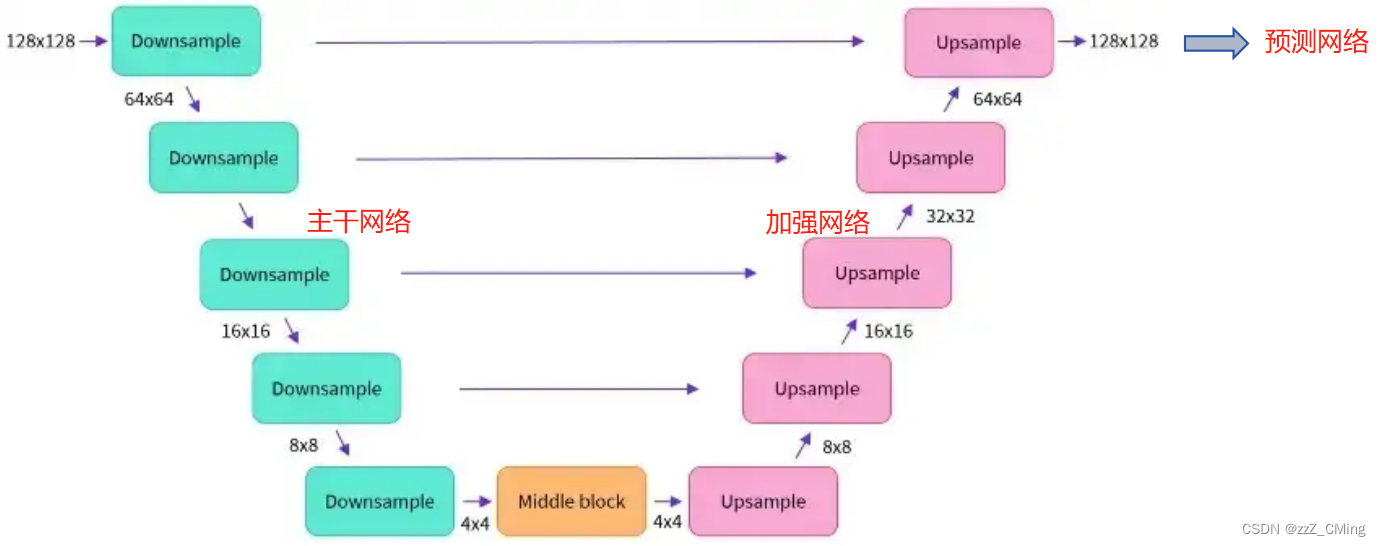
1.4、 补充:U-Net结构
U-Net的模型结构就是一个编-解码的过程,下采样Downsample、中间块Middle block、上采样Upsample中都包含了ResNet残差网络
1、主干网络做特征提取;2、加强网络做特征组合;3、预测网络做预测输出;
1.5、补充:DM扩散模型的缺点
- Diffusion Model是在原图上完成前向、反向扩散过程,计算量巨大;
- Diffusion Model只与时刻向量t产生作用,生成的结果不可控;
二、Stable Diffusion原理
为改善DM扩散模型的缺点,Stable Diffusion引入图像压缩技术,在低维空间完成扩散过程;并添加CLIP模型,使文本-图像产生关联。
2.1、Stable Diffusion的改进点
1. 图像压缩:DM扩散模型是直接在原图上进行操作,而Stale Diffusion是在较低维度的潜在空间上应用扩散过程,而不是使用实际像素空间,这样可以大幅减少内存和计算成本;
2. 文本-图像关联:在反向扩散过程中对U-Net的结构做了修改,使其可以添加文本向量Text Embedding,使得在每一轮的去噪过程中,让输出的图像与输入的文字产生关联;

2.2、Stable Diffusion的生成过程
Stable Diffusion在实际应用中的过程:原图——经过编码器E变成低维编码图——DM的前向过程逐步添加噪声,变成噪声图——T轮U-Net网络完成DM的反向过程——经过解码器D变成新图。
- Stable Diffusion会事先训练好一个编码器E、解码器D,来学习原始图像与低维数据之间的压缩、还原过程;
- 首先通过训练好的编码器E ,将原始图像压缩成低维数据,再经过多轮高斯噪声转化为低维噪声Latent data;
- 然后用低维噪声Latent data、时刻向量t、文本向量Text Embedding、在U-Net网络进行T轮去噪,完成反向扩散过程;
- 最后将得到的低维去噪图通过训练好的解码器D,还原出原始图像,完成整个扩散生成过程。
2.3、补充:CLIP模型详解
CLIP(Contrastive Language-Image Pre-Training) 模型是 OpenAI 在 2021 年初发布的用于匹配图像和文本的预训练神经网络模型,是近年来在多模态研究领域的经典之作。OpenAI 收集了 4 亿对图像 - 文本对(一张图像和它对应的文本描述),分别将图像和文本进行编码,使用 metric learning进行训练。希望通过对比学习,模型能够学习到图像 - 文本对的匹配关系。
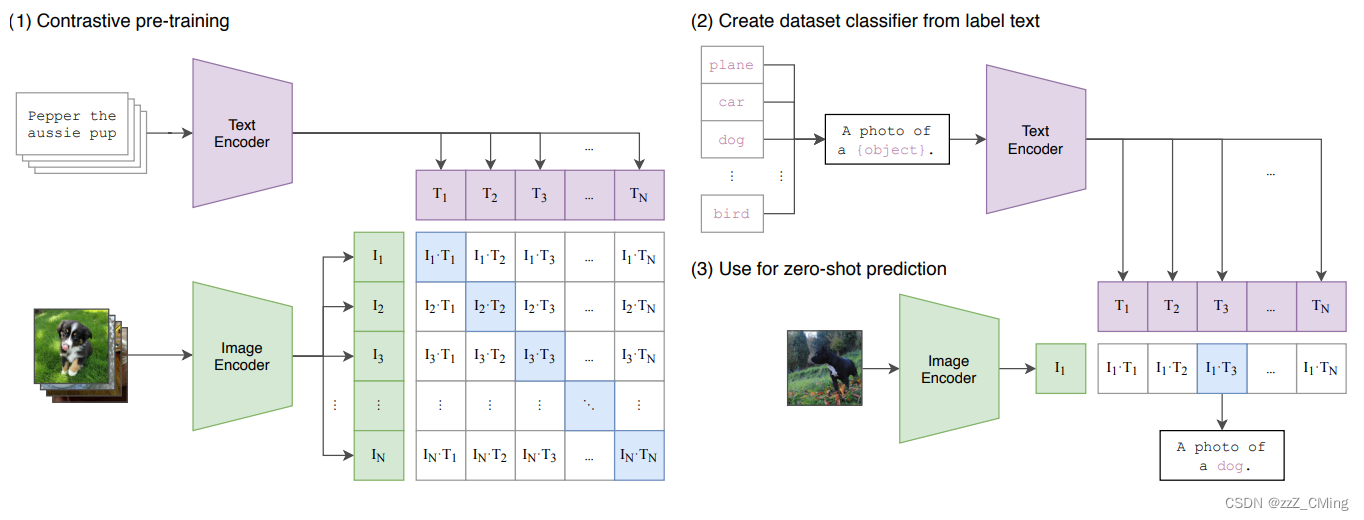
CLIP模型共有3个阶段:1阶段用作训练,2、3阶段用作推理。
- Contrastive pre-training:预训练阶段,使用图片 - 文本对进行对比学习训练;
- Create dataset classifier from label text:提取预测类别文本特征;
- Use for zero-shot predictiion:进行 zero-shot 推理预测;
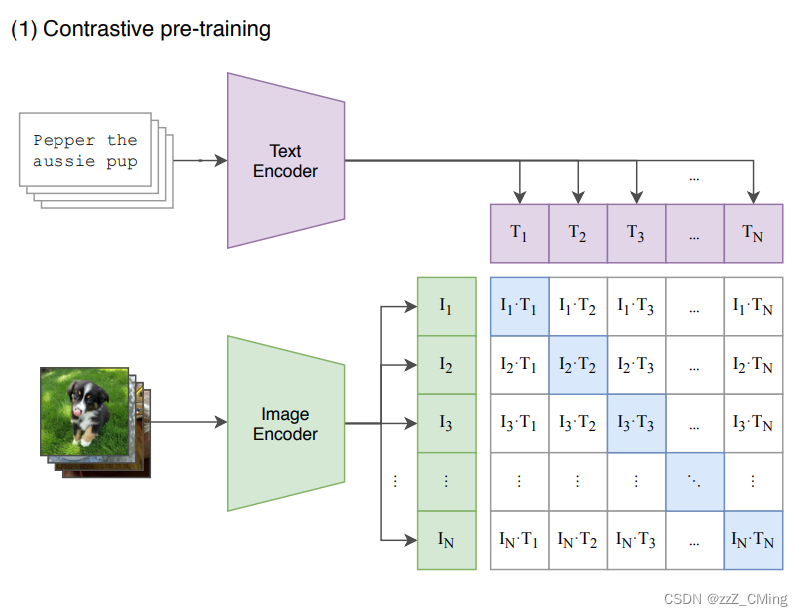
2.3.1、训练阶段
通过计算目标图像和对应文本描述的余弦相似度从而获取预测值。CLIP第一阶段主要包含以下两个子模型;
- Image Encoder:用来提取图像的特征,可以采用常用CNN模型或者vision transformer模型;(视觉模型)
- Text Encoder:用来提取文本的特征,可以采用NLP中常用的text transformer模型;(文本模型)
这里举例一个包含N个文本-图像对的训练batch,对提取的文本特征和图像特征进行训练的过程:
- 输入图片 —> 图像编码器 —> 图片特征向量;输入文字 —> 文字编码器 —> 文字特征向量;并进行线性投射,得到相同维度;
- 将N个文本特征和N个图像特征两两组合,形成一个具有N2个元素的矩阵;
- CLIP模型会预测计算出这N2个文本-图像对的相似度(文本特征和图像特征的余弦相似性即为相似度);
- 对角线上的N个元素因为图像-标签对应正确被作为训练的正样本,剩下的N2-N个元素作为负样本;
- CLIP的训练目标就是最大化N个正样本的相似度,同时最小化N2-N个负样本的相似度;
2.3.2、推理过程
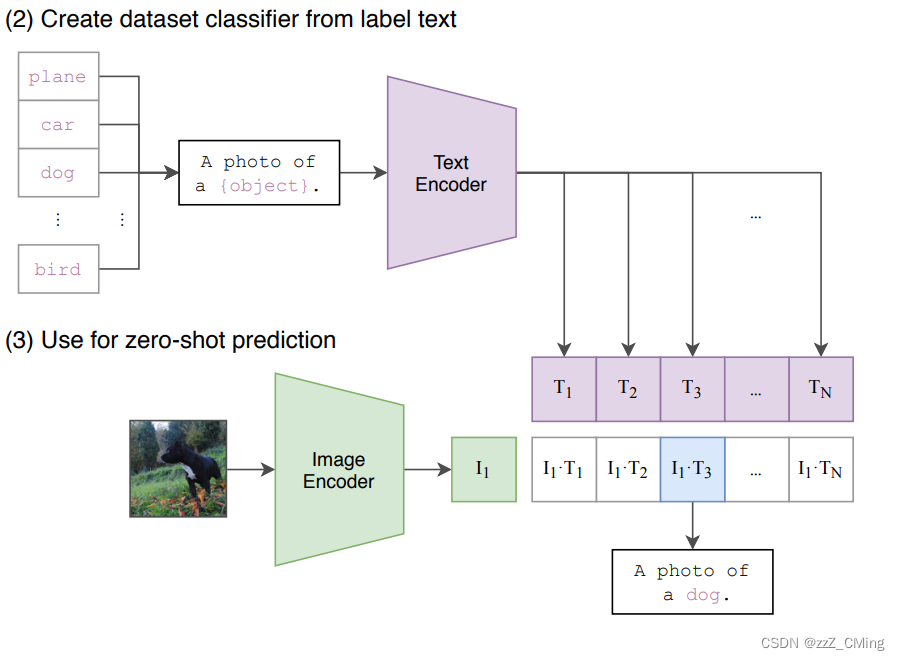
CLIP的预测推理过程主要有以下两步:
- 提取预测类别的文本特征:由于CLIP 预训练文本端的输出输入都是句子,因此需要将任务的分类标签按照提示模板 (prompt template)构造成描述文本(由单词构造成句子):
A photo of {object}.,然后再送入Text Encoder得到对应的文本特征。如果预测类别的数目为N,那么将得到N个文本特征。 - 进行 zero-shot 推理预测:将要预测的图像送入Image Encoder得到图像特征,然后与上述的N个文本特征计算余弦相似度(和训练过程一致),然后选择相似度最大的文本对应的类别作为图像分类预测结果。进一步地,可以将这些相似度看成输入,送入softmax后可以得到每个类别的预测概率。
2.3.3、补充:zero-shot 零样本学习
zero-shot :零样本学习,域外泛化问题。利用训练集数据训练模型,使得模型能够对测试集的对象进行分类,但是训练集类别和测试集类别之间没有交集,期间需要借助类别的描述,来建立训练集和测试集之间的联系,从而使得模型有效。
在计算机视觉中,即便想迁移VGG、MobileNet这种预训练模型,也需要新数据经过预训练、微调等手段,才能学习新数据集所持有的数据特征,而CLIP可以直接实现zero-shot的图像分类,即:不需要训练任何新数据,就能在某个具体下游任务上实现分类,这也是CLIP亮点和强大之处。
我的猜测:CLIP的zero-shot能力是依赖于它预训练的4亿对图像-文本对,样本空间非常大,下游任务的类别也不过是CLIP样本空间的子集,并不是真正的零样本学习,和解决域外泛化问题。和人脸比对的原理相似,依靠大量样本来学习分类对象的特征空间,区别在于人脸比对是image-to-image,CLIP是image-to-text。
2.3.4、代码: CLIP实现zero-shot分类
2.3.4.1、图像数据、文本数据
向模型提供8个示例图像及其文本描述,并比较相应特征之间的相似性
# images in skimage to use and their textual descriptions
descriptions = {
"page": "a page of text about segmentation",
"chelsea": "a facial photo of a tabby cat",
"astronaut": "a portrait of an astronaut with the American flag",
"rocket": "a rocket standing on a launchpad",
"motorcycle_right": "a red motorcycle standing in a garage",
"camera": "a person looking at a camera on a tripod",
"horse": "a black-and-white silhouette of a horse",
"coffee": "a cup of coffee on a saucer"
}
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11

2.3.4.2、计算余弦相似度
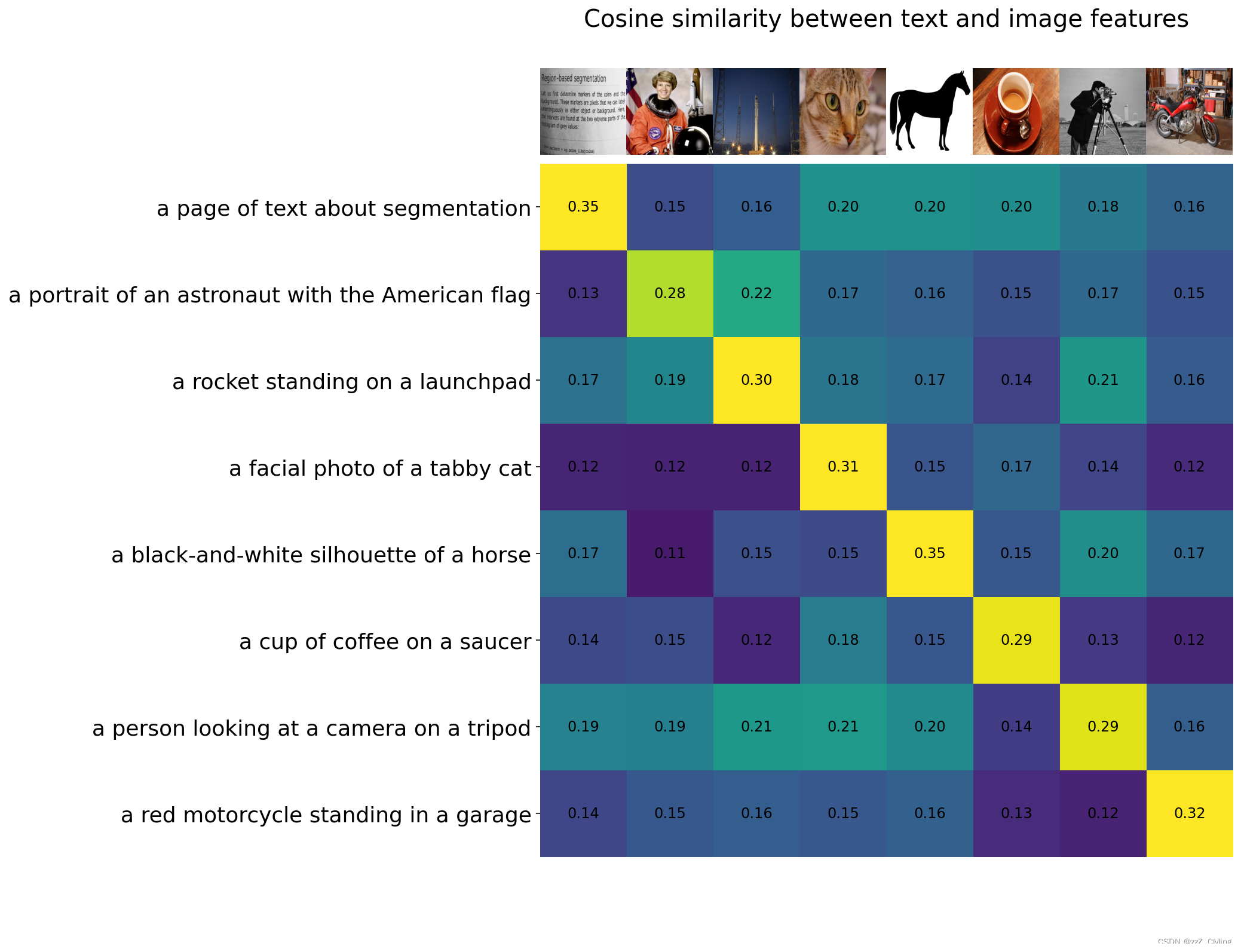
2.3.4.3、Zero-Shot图像分类
from torchvision.datasets import CIFAR100 cifar100 = CIFAR100(os.path.expanduser("~/.cache"), transform=preprocess, download=True) text_descriptions = [f"This is a photo of a {label}" for label in cifar100.classes] text_tokens = clip.tokenize(text_descriptions).cuda() with torch.no_grad(): text_features = model.encode_text(text_tokens).float() text_features /= text_features.norm(dim=-1, keepdim=True) text_probs = (100.0 * image_features @ text_features.T).softmax(dim=-1) top_probs, top_labels = text_probs.cpu().topk(5, dim=-1) plt.figure(figsize=(16, 16)) for i, image in enumerate(original_images): plt.subplot(4, 4, 2 * i + 1) plt.imshow(image) plt.axis("off") plt.subplot(4, 4, 2 * i + 2) y = np.arange(top_probs.shape[-1]) plt.grid() plt.barh(y, top_probs[i]) plt.gca().invert_yaxis() plt.gca().set_axisbelow(True) plt.yticks(y, [cifar100.classes[index] for index in top_labels[i].numpy()]) plt.xlabel("probability") plt.subplots_adjust(wspace=0.5) plt.show()

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32

2.4、补充:Stable Diffusion训练的四个主流AI模型
-
Dreambooth:会使用正则化。通常只用少量图片做输入微调,就可以做一些其他扩散模型不能或者不擅长的事情——具备个性化结果的能力,既包括文本到图像模型生成的结果,也包括用户输入的任何图片;
-
text-inversion:通过控制文本到图像的管道,标记特定的单词,在文本提示中使用,以实现对生成图像的细粒度控制;
-
LoRA:大型语言模型的低阶自适应,简化过程降低硬件需求,详情请学习LoRA模型原理;
-
Hypernetwork:这是连接到Stable Diffusion模型上的一个小型神经网络,是噪声预测器U-Net的交叉互视(cross-attention)模块;
四个主流模型的区别:
- Dreambooth最直接但非常复杂占内存大,用的人很多评价好;
- text-inversion很聪明,不用重新创作一个新模型,所有人都可以下载并运用到自己的模型,模型小,存储空间占用小;
- LoRA可以在不做完整模型拷贝的情况下,让模型理解这个概念,速度快;
- Hypernetwork:没有官方论文;
三、补充:四大生成模型对比
GAN生成对抗模型、VAE变微分自动编码器、流模型、DM扩散模型
3.1、GAN生成对抗模型
- GAN模型要同时训练两个网络,难度较大,多模态分布学习困难;
- 不容易收敛,不好观察损失;
- 图像特征多样性较差,容易出现模型坍缩,只关注如何骗过判别器;
3.2、VAE变微分自动编码器
Deepfaker、DeepFaceLab的处理方式,生成中间状态
3.3、流模型
待完善
3.4、DM扩散模型
xx

