
- 1【Linux】权限管理(文件的访问者、类型和访问权限,chmod、chown、chgrp、umask,粘滞位)
- 2AI算法面试题总结三(计算机视觉)_ai视觉识别 算法模型选择
- 32023 年四川省职业院校师生技能大赛(中职组)网络建设与运维赛项(样题)——网络建设与调试、服务搭建与运维_四川 中职 网络建设与运维 赛题
- 4Java之加互斥锁_为对象加互斥锁
- 5二维小波变换_【外文文献速读】实时二维水波模拟
- 6Android权限系统(三):运行时权限检查和申请,PermissionController_android根据包名检查和设置权限
- 7正规表达式2
- 8iphone html5 模板,聊聊IPHONE6分辨率与适配
- 9大模型“暴力计算”时代,华为昇腾如何突围算力之困? | WAIC2023
- 10上职高学计算机可以考师范大学吗,职业高中也可以考大学,你知道吗?
基于Redis的分布式限流详解_redis限流
赞
踩
前言
Redis除了能用作缓存外,还有很多其他用途,比如分布式锁,分布式限流,分布式唯一主键等,本文将和大家分享下基于Redis分布式限流的各种实现方案。
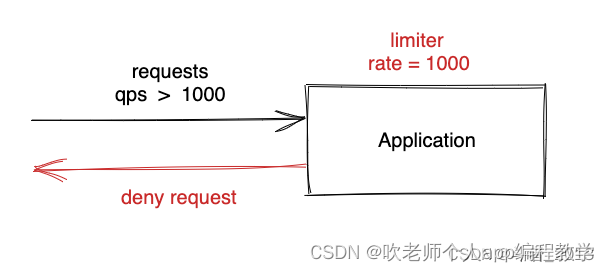
1 为什么需要限流
用最简单的话来说:外部请求是不可控的,而我们系统的负载是有限的,如果没有限流机制,一旦外部请求超过系统承载的压力,就会出现系统宕机等严重问题。加入限流正是为了保证系统负载在可以承受的范围内。
比如春节的秒杀环节。我们在上线前预估了能应对的秒杀 qps 是 1kw/s,但是实际可能达到了1亿/s,这种情况下这多出来的9kw请求很可能压垮我们的数据库,进而影响到接下来所有的用户正常访问。
补充:
微服务保证稳定性的几个利器:缓存、熔断、降级、限流。
缓存的目的是为了降低系统的访问延迟,提高系统能力,给用户更好的体验
熔断的目的是为了在发现某个服务故障熔断对下游依赖的请求,减少不必要的损耗
降级的目的是为了在系统在某个环节故障(比如某个下游故障)不影响整体核心链路,比如返回作者列表,关注服务故障了获取不了关注真实的关注情况,这种情况可以考虑降级关注按钮,全部显示为未关注
限流的目的是为了保证系统处理的请求量在可以承受的范围内,防止突发流量压垮系统,保证系统稳定性。
2 单机限流和分布式限流
2.1、单机限流的瓶颈
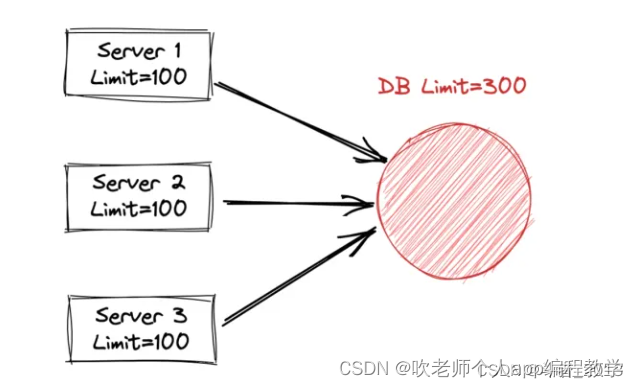
单机限流有个主要的缺陷就是不够精确,我们可能有1000个实例,但是下游存储只有一套,即多对一的关系,如果单纯的以单机限流作为衡量指标,很可能把下游打挂。如果以下游(数据库)的总请求量均衡到每台机器上,由于每个机器请求数据库量级可能不同,导致部分机器被限流严重,而部分机器压根没什么请求,造成误伤。
即不好根据下游数据库服务的负载压力,来评估上游应用服务器每台的负载压力是多少。
采用根据总负载来均摊负载的方式显然并不精确,并且不能充分发挥上游服务器的处理性能,极大的限制了系统的负载能力。
比如数据库负载为limit=300,由于采用上游采用负载均摊的方式每台应用服务器限制为limit=100,如果来个固定IP或固定用户的请求一直落在服务器Server1上,那么系统的实际并发就变成了100,显然这样处理并不科学,也降低了单台应用服务器的处理能力。
————————————————
单机限流也有好处:可以根据服务器配置的不同进行不同权重的限流配置。
比如:4核CPU,16G内存的服务器上限流为1000;2核 8G内存的服务器上限流为500.
2.2 分布式限流
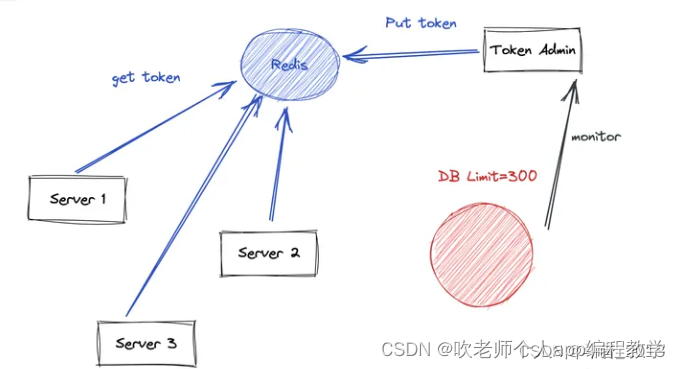
为了解决单机限流的瓶颈,需要引入分布式限流,即我们不应为每个单机设置限流阈值,而是根据下游的负载情况设置一个全局的阈值。目前主流的做法主要是通过 redis 或者 zookeeper 来实现。zookeeper 使用、运维都比较复杂,所以大部分是使用 redis + lua 脚本来实现。
分布式限流器和单机限流的实现类似,只是计数存储换成了一些分布式存储而不是在单机内存中。
我们可以使用 redis + lua 脚本实现令牌桶的算法,因为 lua 的执行可以做到事务,要么全部成功要么全部失败。所以可以很简单地实现分布式的令牌桶逻辑,并且可以实现精确的限流。但是这种实现的缺陷是如果请求 qps很高,所有的请求都要和redis交互,redis 不一定能承载得住。
小结
单机限流更适合对单机精确限流,比如针对单个mysql数据库的请求限流,某低配的应用服务器只能处理100并发的限流。
分布式限流更适合分布式场景的总体流控,比如知道请求链路中下游的负载能力出现瓶颈,那么上游就需要根据下游瓶颈进行整体流量控制,如数据库的负载是limit=500,这时就可以采用分布式限流器来控制落在应用服务器上整体的请求数。
3、4种主流的限流算法
3.1、固定时间窗口
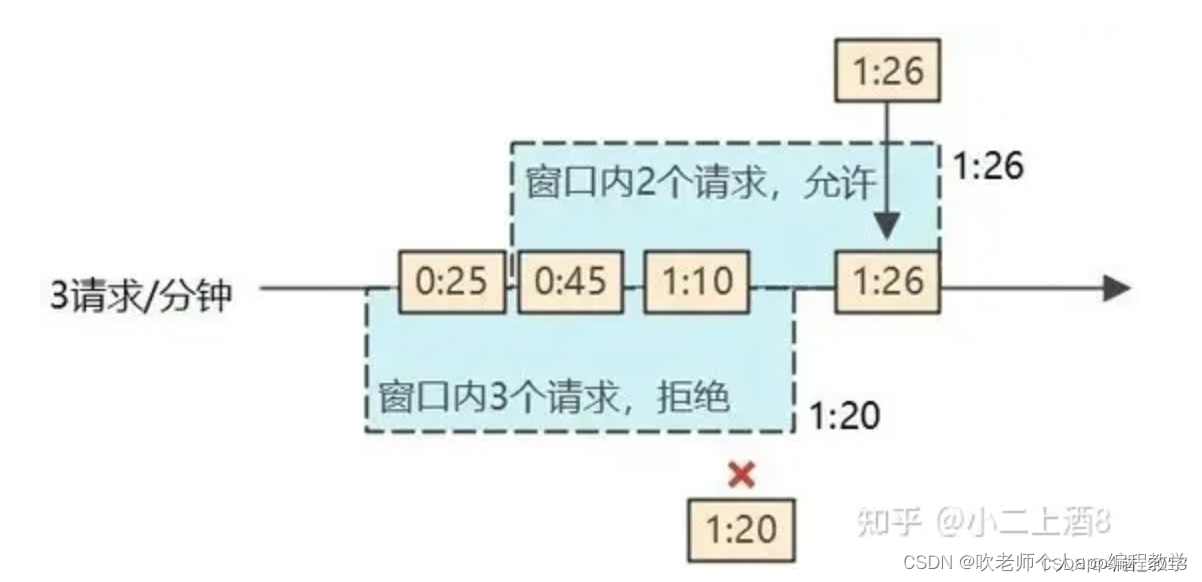
固定窗口算法又叫计数器算法,是一种简单方便的限流算法。主要通过一个支持原子操作的计数器来累计 1 秒内的请求次数,当 1 秒内计数达到限流阈值时触发拒绝策略。每过 1 秒,计数器重置为 0 开始重新计数。

优点:时间窗口固定,实现简单,性能较高
缺点:无法应对两个时间窗口临界时间内的突发流量,如上图所示,我们虽然通过限流器限制了单个时间窗口内只能有2个请求(即QPS=2),但是在两个1秒时间窗口中间1秒的时间窗口内却发生了4次请求。
3.2、滑动时间窗口
我们已经知道固定窗口算法的实现方式以及它所存在的问题,而滑动窗口算法是对固定窗口算法的改进。既然固定窗口算法在遇到时间窗口的临界突变时会有问题,那么我们在遇到下一个时间窗口前也调整时间窗口不就可以了吗?
下面是滑动窗口的示意图:
上图的示例中,每 500ms 滑动一次窗口,可以发现窗口滑动的间隔越短,时间窗口的临界突变问题发生的概率也就越小,不过只要有时间窗口的存在,还是有可能发生时间窗口的临界突变问题。

那么有没有什么办法更精确的统计时间窗口内的请求数呢?
答案是有的,就是记录下所有的请求时间点,新请求到来时以请求时间作为时间窗口的结尾时间统计时间窗口范围内的请求数量是否超过指定阈值,由此来确定是否达到限流,这种方式没有了时间窗口突变的问题,限流比较准确,但是因为要记录下每次请求的时间点,所以占用的内存较多。
该方法又叫做滑动日志算法。不过其算法的本质还是滑动时间窗口那套,区别在于滑动时间窗口是固定时间间隔滑动时间窗口,而滑动日志算法由于保存了每个请求的时间戳,可以根据最新请求的时间戳计算出当前时间窗口内的请求数。
————————————————
优点:优化了固定时间窗口的临界问题,限流更加精准
缺点:实现较为复杂,会占用较多内存,每个请求都需要重新统计最新时间窗口内的请求数,性能较低。
3、漏桶
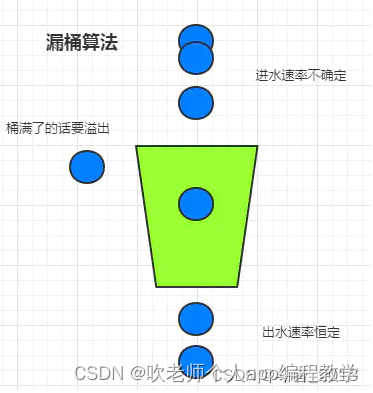
漏桶算法中将限流器比作一个漏斗,每一个请求到来就会向桶中添加一定的水量,桶底有一个孔,以恒定速度不断的漏出水;当一个请求过来需要向加水时,如果漏桶剩余容积不足以容纳添加的水量,就会触发拒绝策略。
假设限流要求是每分钟允许30个请求,可以将漏桶的容积看作30,每次请求加水量为1,漏桶中水的流出速度为30/时间周期1分钟。
当出现最大30个并发时,漏桶会被瞬间注满水,后续请求都会被拒绝。只有随着水量以固定速度流出后,漏斗中有剩余空间容纳新的水量,系统才能接受的新的请求。
注意:
1)、漏桶算法模型中并没有队列的概念,每个请求到来时向漏斗中加水并不是加入队列等待被消费,所以漏斗并不能像消息队列那样削峰填谷、缓解突发的请求压力,限流器只负责判断当前请求是被允许还是需要拒绝。只要容器中能继续加水,请求就被允许,否则拒绝请求。
2)、漏桶中水的流出速度并不等于请求的并发量,往漏桶中加水的速度才是当前系统的实际并发量。水的流出可以等同于令牌桶算法中向桶中投放令牌,水流出的速度越快,漏桶中就越快腾出空余空间用来存放新的请求到来需要添加的水量。所以不要简单认为水的流出速度恒定,就能控制当前系统的并发量保持均衡,两者并不是一个概念。
3)、桶的容积决定了限流器允许的最大并发。当漏桶中没有水时,允许出现最大的并发流量。
很多地方对漏桶的说法都是可以缓冲请求,对此我有不同的看法,所有的限流器不管是采用何种方法实现,都仅仅只是做请求是否被允许的判定器,请求要么被允许通过,要么被直接拒绝,其本身并不提供缓冲请求的功能。漏桶模型中的桶的容量并不会像消息队列那样缓冲请求,不会存放真实的请求信息,等待被处理消费。
————————————————
优点:能够起到一定的平滑突发流量的作用。水的恒定流出速度,可以等价于固定速度的投放令牌,不会出现一下子投放大量令牌,立刻被抢空,导致突发流量的问题。
缺点:
1)、资源利用率低:漏桶并不能高效地利用可用的资源。因为它只在固定的时间间隔放行请求,所以在很多情况下,流量非常低,即使不存在资源争用,也无法有效地消耗资源。
2)、饥饿问题:当短时间内有大量突发请求,即使服务器没有任何负载,由于漏桶中的水还没有流出,请求会大量被拒绝。
3)、实现复杂,性能较低,会占用较多内存
————————————————
以上观点有两种说法,如果漏斗无缓存作用,就失去了限流的意义,和令牌桶限流没啥区别了
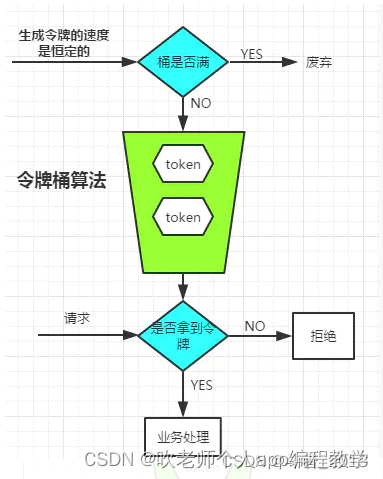
4、令牌桶
漏桶是看处理效率和生产效率来控制流速,但是这个流速是静态的,很可能无法充分利用机器的性能。比如,服务器能处理的速率是100qps,但是我们配置的恒定流速只有50qps,这个时候服务器资源还非常地冗余。
令牌桶算法能比较灵活的调整以最大化利用资源:系统每接受到一个请求时,都要求有一个令牌,如果拿到令牌就处理,否则就拒绝,处理完以后把令牌丢弃。
桶中能存放的最大令牌数决定了令牌桶算法的最大并发,当桶中放满令牌时,允许达到最大并发。
令牌桶限流算法的核心就在于如何控制令牌的发放策略。这样可以做的很动态,例如利用系统的负载、业务高峰情况等,高峰时且负载允许加快令牌发放。
从本质上来说,令牌桶中以恒定速度生成令牌和漏桶算法中以恒定速度控制水的流出速度是等同的,都可以实现相同的限流效果。
漏桶 vs 令牌桶
网上的大多数说法:
令牌桶相比漏桶会更加灵活,可以根据业务诉求配置灵活的发放策略。比如可以任意时间放入令牌,或者依据机器负载放入多个令牌,但是漏桶的整形效果会更好,对下游服务会更加友好,因为不容易出现突刺。
个人理解:
两者本质上只是模型不同,但都能实现相同的限流效果。令牌桶能调整令牌的发放策略,漏桶也可以改进水流出的速率。只是我们一般的默认理解是令牌桶是定时投放一定数量的令牌,而漏桶中的水是恒定速度流出,这样的前提下,漏桶相较之下更能起到平滑突发流量的作用,不会像令牌桶那样出现令牌投放后立刻被抢空的情况,而令牌桶则是能更好的适应突发流量。
优点:可以适应流量突发,N 个请求到来只需要从桶中获取 N 个令牌就可以继续处理。当然在漏桶算法中只要桶中剩余空间够大,也能够应付突发的流量。
缺点:实现复杂,性能较低,会占用较多内存
5、基于Redis的Lua分布式限流实战
基于Redis实现分布式限流一般都会采用Lua实现,以保证操作的原子性。
初始化配置:

public class RedisConfig { @Bean(name = "redisTemplate") @ConditionalOnClass(RedisOperations.class) public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) { RedisTemplate<String, Object> template = new RedisTemplate<>(); template.setConnectionFactory(factory); Jackson2JsonRedisSerializer<Object> jackson2JsonRedisSerializer = new Jackson2JsonRedisSerializer<> (Object.class); ObjectMapper mapper = new ObjectMapper(); mapper.setVisibility(PropertyAccessor.ALL, JsonAutoDetect.Visibility.ANY); mapper.activateDefaultTyping(mapper.getPolymorphicTypeValidator(), ObjectMapper.DefaultTyping.NON_FINAL); jackson2JsonRedisSerializer.setObjectMapper(mapper); StringRedisSerializer stringRedisSerializer = new StringRedisSerializer(); // 指定 key 的序列化格式 template.setKeySerializer(stringRedisSerializer); // 指定 hash 的 key 的序列化格式 template.setHashKeySerializer(stringRedisSerializer); // 指定 value 的序列化格式 template.setValueSerializer(jackson2JsonRedisSerializer); // 指定 hash 的 value 的序列化格式 template.setHashValueSerializer(jackson2JsonRedisSerializer); template.afterPropertiesSet(); return template; } }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
lua 脚本初始化
@Component public class RedisLuaBean { @Bean public DefaultRedisScript<Long> limitScript() { //执行 Redis Lua 脚本的一种方式 DefaultRedisScript<Long> redisScript = new DefaultRedisScript<>(); //将lua脚本加载ClassPathResource中 ClassPathResource resource = new ClassPathResource("lua/limitCount.lua"); //将脚本加载容器中方便后续执行 ResourceScriptSource resourceScriptSource = new ResourceScriptSource(resource); redisScript.setScriptSource(resourceScriptSource); redisScript.setResultType(Long.class); return redisScript; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
4.1、固定时间窗口
--KEYS[1]: 限流 key --ARGV[1]: 阈值 --ARGV[2]: 时间窗口,计数器的过期时间 local rateLimitKey = KEYS[1]; local rate = tonumber(ARGV[1]); local rateInterval = tonumber(ARGV[2]); local allowed = 1; -- 每次调用,计数器rateLimitKey的值都会加1 local currValue = redis.call('incr', rateLimitKey); if (currValue == 1) then -- 初次调用时,通过给计数器rateLimitKey设置过期时间rateInterval达到固定时间窗口的目的 redis.call('expire', rateLimitKey, rateInterval); allowed = 1; else -- 当计数器的值(固定时间窗口内) 大于频度rate时,返回0,不允许访问 if (currValue > rate) then allowed = 0; end end return allowed
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
>aop 拦截处 import club.chuige.appmanagement.common.enums.ApiResultCodeEnum; import club.chuige.appmanagement.common.model.common.ApiResultBuilder; import club.chuige.appmanagement.common.util.IPUtil; import club.chuige.appmanagement.service.service.streamLimit.bucket.StreamLimitBucketService; import club.chuige.appmanagement.service.service.streamLimit.count.service.StreamLimitCountService; import club.chuige.appmanagement.service.service.streamLimit.slide.service.StreamLimitSlideService; import club.chuige.appmanagement.service.service.streamLimit.token.TokenService; import lombok.extern.slf4j.Slf4j; import org.aspectj.lang.ProceedingJoinPoint; import org.aspectj.lang.annotation.Around; import org.aspectj.lang.annotation.Aspect; import org.aspectj.lang.annotation.Pointcut; import org.aspectj.lang.reflect.MethodSignature; import org.springframework.core.annotation.Order; import org.springframework.stereotype.Component; import javax.annotation.Resource; import java.lang.reflect.Method; @Aspect @Component @Order(1) @Slf4j public class StreamLimiting { @Resource private StreamLimitCountService streamLimitCountService; @Resource private StreamLimitSlideService streamLimitSlideService; @Resource private TokenService tokenService; @Resource private StreamLimitBucketService streamLimitBucketService; /** * @Pointcut注解用于定义切入点 * @annotation(注解)为切入点表达式,后续由此注解描述的方法为切入 点方法 */ @Pointcut("execution(* club.chuige.appmanagement.web.controller.*.*(..))") public void doLog() { } /** * @param jp 连接点对象,此对象封装了要执行的目标方法信息. * 可以通过连接点对象调用目标方法. * @return 目标方法的执行结果 * @throws Throwable * @Around注解描述的方法,可以在切入点执行之前和之后进行业务拓展, */ @Around("doLog()") public Object doAround(ProceedingJoinPoint jp) throws Throwable { try { // 计算 // boolean isLimit = streamLimitCountService.isLimit(jp); // 滑动窗口 boolean isLimit = streamLimitSlideService.isLimit(jp); // 令牌 // boolean isLimit = tokenService.isLimit(jp); // 漏桶算法,主要是调用外部接口,因为存在任务挤压,不太适合外部调用自身,这里异步提交任务,对外接口进行请求限制 // streamLimitBucketService.submitTask(jp); if (isLimit) { return ApiResultBuilder.errorResult(ApiResultCodeEnum.STREAM_LIMIT.getDesc()); } return jp.proceed(); } catch (Exception e) { log.error("限流redis 服务异常", e); return ApiResultBuilder.errorResult(ApiResultCodeEnum.UNKONWN_ERROR.getDesc()); } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
@Service public class StreamLimitCountService { @Resource private RedisTemplate<String, Object> redisTemplate; @Autowired RedisScript<Long> redisScript; RateLimiter rateLimiter = new RateLimiter(); public boolean isLimit(ProceedingJoinPoint jp) { int time = rateLimiter.getTime(); int count = rateLimiter.getCount(); String combineKey = StreamLimitUtil.getCombineKey(true, jp) + "_count"; Object[] o = {count, time}; Long allowd = redisTemplate.execute(redisScript, Collections.singletonList(combineKey), o); if (allowd == 0) { return true; } return false; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
4.2、滑动时间窗口
--KEYS[1]: 限流器的 key --ARGV[1]: 当前时间窗口的开始时间 --ARGV[2]: 请求的时间戳(也作为score) --ARGV[3]: 阈值 -- 1. 移除时间窗口之前的数据 redis.call('zremrangeByScore', KEYS[1], 0, ARGV[1]) -- 2. 统计当前元素数量 local res = redis.call('zcard', KEYS[1]) -- 3. 是否超过阈值 if (res == nil) or (res < tonumber(ARGV[3])) then -- 4、保存每个请求的时间搓 redis.call('zadd', KEYS[1], ARGV[2], ARGV[2]) return 1 else return 0 end
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
@Slf4j @Service public class StreamLimitSlideService { @Autowired DefaultRedisScript<Long> redisScript; @Resource private RedisTemplate redisTemplate; String key = "redis_limiter"; // 窗口大小, 单位:秒 long windowTime = 5; // 每 窗口大小时间 最多 多少个请求 int limitCount = 3; public boolean isLimit(ProceedingJoinPoint jp) { //将脚本加载容器中方便后续执行 redisScript.setScriptSource(new ResourceScriptSource(new ClassPathResource("lua/slide.lua"))); Long currentTime = System.currentTimeMillis(); Long allowd = (Long) redisTemplate.execute(redisScript, Collections.singletonList(StreamLimitUtil.getCombineKey(false, jp) + "_slide"), currentTime - 1000 * windowTime, currentTime, limitCount); if (allowd == 0) { return true; } return false; } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
4.3、漏斗
--参数说明: --KEYS[1]: 限流器的 key --ARGV[1]: 容量,决定最大的并发量 --ARGV[2]: 漏水速率,决定平均的并发量 --ARGV[3]: 一次请求的加水量 --ARGV[4]: 时间戳 local limitInfo = redis.call('hmget', KEYS[1], 'capacity', 'passRate', 'water', 'lastTs') local capacity = limitInfo[1] local passRate = limitInfo[2] local water = limitInfo[3] local lastTs = limitInfo[4] --初始化漏斗 if capacity == nil then capacity = tonumber(ARGV[1]) passRate = tonumber(ARGV[2]) lastTs = tonumber(ARGV[3]) redis.call('hmset', KEYS[1], 'capacity', capacity, 'passRate', passRate, 'water', 1, 'lastTs', lastTs) return 1 else local nowTs = tonumber(ARGV[3]) --计算距离上一次请求到现在的漏水量 = 流水速度 * (nowTs - lastTs) local waterPass = tonumber(ARGV[2] * (nowTs - lastTs + 1)) water = math.max(tonumber(0), tonumber(water - waterPass + ARGV[2])) if tonumber(ARGV[4]) == 0 then water = water + 1 end ------计算当前剩余水量 = 上次水量 - 时间间隔中流失的水量 ------设置本次请求的时间 lastTs = nowTs ----如果剩余水量 小于等于流出,代表可以处理请求 if tonumber(water) - tonumber(waterPass) <= 0 then redis.call('hmset', KEYS[1], 'water', water, 'lastTs', lastTs) return 1; end if tonumber(capacity) >= tonumber(water) then -- 更新增加后的当前水量和时间戳 redis.call('hmset', KEYS[1], 'water', water, 'lastTs', lastTs) return 2 end ------ 请求失败 return 0 end
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
package club.chuige.appmanagement.service.service.streamLimit.bucket; import club.chuige.appmanagement.common.util.StreamLimitUtil; import lombok.extern.slf4j.Slf4j; import org.aspectj.lang.ProceedingJoinPoint; import org.springframework.beans.factory.annotation.Autowired; import org.springframework.core.io.ClassPathResource; import org.springframework.data.redis.core.RedisTemplate; import org.springframework.data.redis.core.script.DefaultRedisScript; import org.springframework.data.redis.core.script.RedisScript; import org.springframework.scripting.support.ResourceScriptSource; import org.springframework.stereotype.Component; import org.springframework.stereotype.Service; import javax.annotation.PostConstruct; import javax.annotation.Resource; import java.util.Collections; import java.util.LinkedList; import java.util.concurrent.BlockingQueue; import java.util.concurrent.Executors; import java.util.concurrent.LinkedBlockingDeque; @Slf4j @Component public class StreamLimitBucketService { @Resource private RedisTemplate<String, Object> redisTemplate; @Autowired DefaultRedisScript<Long> redisScript; private LinkedBlockingDeque<ProceedingJoinPoint> linkedQue = new LinkedBlockingDeque<>(); int maxCount = 5; public void submitTask(ProceedingJoinPoint jp) { if (linkedQue.size() > 2) { log.info("漏桶已满,限流"); return; } try { linkedQue.put(jp); } catch (InterruptedException e) { log.error("任务添加失败", e); } } @PostConstruct public void startStreamLimit() { Executors.newSingleThreadExecutor().submit(() -> { boolean repeat = false; ProceedingJoinPoint proceedingJoinPoint = null; while (true) { try { if (!repeat) { proceedingJoinPoint = linkedQue.take(); } // 线程池执行 String combineKey = "Redis_limit_test_"; redisScript.setScriptSource(new ResourceScriptSource(new ClassPathResource("lua/bucket.lua"))); Long currentTime = System.currentTimeMillis() / 1000; Object[] o = {2, 1, currentTime, repeat ? 1 : 0}; Long number = redisTemplate.execute(redisScript, Collections.singletonList(combineKey), o); log.info("number 值为:" + number); if (number == 1) { repeat = false; Executors.newFixedThreadPool(4).submit(() -> { log.info("异步执行,调用三方等"); }); } else { log.info("等待下一次执行"); repeat = true; Thread.sleep(200); } } catch (Exception e) { log.error("限流失败", e); } } }); } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
4.4、令牌桶
local function token_bucket(key, rate, burst, now) local current = tonumber(redis.call('get', key) or burst) local last_refreshed = tonumber(redis.call('get', key .. ':last_refreshed') or '0') local time_passed = math.max(now - last_refreshed, 0) local new_tokens = math.floor(time_passed * rate) if new_tokens > 0 then current = math.min(current + new_tokens, burst); redis.call('set', key, current) redis.call('set', key .. ':last_refreshed', now) end if current > 0 then redis.call('decr', key) return current-1; end return current end -- 调用令牌桶限流算法 return token_bucket(KEYS[1], tonumber(ARGV[1]), tonumber(ARGV[2]), tonumber(ARGV[3]))
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
@Slf4j @Service public class TokenService { @Autowired DefaultRedisScript<Long> redisScript; @Resource private RedisTemplate redisTemplate; public boolean isLimit(ProceedingJoinPoint jp) { redisScript.setScriptSource(new ResourceScriptSource(new ClassPathResource("lua/token.lua"))); String key = StreamLimitUtil.getCombineKey(false, jp) + "_token"; int rate = 1; int count = 2; long now = System.currentTimeMillis() / 1000; Number execute = (Number) redisTemplate.execute(redisScript, Collections.singletonList(key), rate, count, now); if (execute.intValue() == 0) { return true; } else { log.info("当前访问时间段内剩余{}次访问次数", execute.toString()); return false; } } }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
6、怎么兼容单机限流
上面采用Redis的Lua脚本实现了经典的4种限流算法,并且都是分布式限流。那么基于Redis的限流器,可以兼容单机限流吗?
其中参考Redisson中的RRateLimiter实现,我们很容易发现,针对单机限流的实现只需要在每个限流器的Key中添加客户端标识信息即可,比如IP信息。
这样每种限流器实现就既可以支持分布式限流,也可以支持单机限流。
这里只提供思路,感兴趣的朋友可以自己实现。
7、其他限流方案
7.1、Guava的RateLimiter
Google开源工具包Guava提供了限流工具类RateLimiter,该类基于令牌桶算法实现流量限制,使用十分方便,而且十分高效。
其提供了2种令牌桶算法实现:平滑突发限流(SmoothBursty)和平滑预热限流(SmoothWarmingUp)实现,但是由于限流信息都保存在本地JVM中,因此RateLimiter只能用于单机限流。
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>23.0</version>
</dependency>
- 1
- 2
- 3
- 4
- 5
使用样例:
@Service public class GuavaRateLimiterService { /*每秒控制5个许可*/ RateLimiter rateLimiter = RateLimiter.create(5.0); /** * 获取令牌 * * @return */ public boolean tryAcquire() { return rateLimiter.tryAcquire(); } } @Autowired private GuavaRateLimiterService rateLimiterService; @ResponseBody @RequestMapping("/ratelimiter") public Result testRateLimiter(){ if(rateLimiterService.tryAcquire()){ return ResultUtil.success1(1001,"成功获取许可"); } return ResultUtil.success1(1002,"未获取到许可"); }
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
思考
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/不正经/article/detail/230009
Copyright © 2003-2013 www.wpsshop.cn 版权所有,并保留所有权利。

