
- 1js 判断字符串为字母或汉字_js 怎么判断一段文本只要大部分为英文单词就可以认为这句话为英文
- 2Mac地址会重复吗?Mac地址也会耗尽吗?
- 3Linux守护进程_守护进程ps -ajx
- 4融优课堂数据科学导论习题答案_融优学堂数据科学导论答案
- 5ASP.NET 网络在线考试系统的设计与实现(论文+源码)_Nueve_基于.net的在线考试系统课设研究内容
- 6本地部署Stable Diffusion Webui AI 记录_stable diffusion本地部署
- 7【生信Linux基础】Linux文本处理三剑客(awk、grep、sed)_2. linux文本处理三剑客: awk、grep、sed1)grepgrep. txtmmmyy找
- 8Spring Boot application.properties或application.yml相关配置_在application.yml中配置security不拦截的url ignored
- 9有向无环图讲解及模板(C++代码)
- 10蓝桥杯十六进制与十进制的相互转换
如何运行代码mikel-brostrom/yolov8_tracking实现目标识别和跟踪?
赞
踩
https://github.com/mikel-brostrom/yolov8_tracking
项目名:Real-time multi-object tracking and segmentation using Yolov8
(1)它的识别和分割是YOLO8完成的。它的多目标追踪是由后面四种算法实现的(botsort,bytetrack,ocsort,strongsort)
(2)它这个是实时的Real-time,识别、跟踪、分割的速度很快
这个代码是是23年2月11号发布的
如果你想了解YOLOv8的模型细节和里面每个流程,可以阅读这篇博客https://blog.csdn.net/Albert233333/article/details/130044349
如果这篇博客对你有帮助,希望你 点赞、收藏、关注、评论,您的认可将是我创作下去最大的动力!
环境配置
- torch要求1.7,我满足
- 要求安装ultralytics==8.0.20(但是这个是错的,你必须安装最新版本的ultralytics,否则会报错)
- # 我这一边用的环境的名字是(py380tc170)
-
- # 下面这些包需要安装,否则无法运行
- pip install psutil
- pip install thop
特别提示,非常重要,一定要安装ultralytics最新版本(2023-02-23这个时间点,是'8.0.40'这个版本),否则会遇到下面这样的报错
"/yolov8_tracking/yolov8/ultralytics/nn/a utobackend.py", line 19, in <module>from ultralytics.yolo.utils.downloads import attempt_download_asset, is_url
ImportError: cannot import name 'attempt_download_asset' from 'ultralytics.yolo.utils.downloads' (/home/anaconda3/envs/py380tc170/lib/python3.8/site-packages/ultralytics/yolo/utils/ downloads.py)
以及这样的报错
/yolov8_tracking/yolov8/ultralytics/ yolo/data/build.py", line 12, in <module> from ultralytics.yolo.data.dataloaders.stream_loaders import ( LOADERS, LoadImages, LoadPilAndNumpy, LoadScreenshots,
ImportError: cannot import name 'LOADERS' from 'ultralytics.yolo.data.dataloaders.stream_loaders' (/home/anaconda3/envs/py380tc170/lib/python3.8/site-packages/ultralytics/yolo/data/dataloaders/ stream_loaders.py)
因此
pip install ultralytics==8.0.40在tracking.py line359注释掉这个函数的执行
因为如果你不注释这一行。一旦你运行这个trackiung.py的代码,就会自动按照requirement.txt里面写好的这些东西逐一排查是否符合要求,不符合要求的会重新安装。比如这个ultralytics现在的版本是8.0.40,但是requirements.txt里面必须是8.0.20所以给你重装回了8.0.20,再次引发报错。
check_requirements(requirements=ROOT / 'requirements.txt', exclude=('tensorboard', 'thop'))运行代码
作者这个默认的是用分割的YOLOv8模型,这个模型在在我这里报错。因此我换成了仅仅做识别的YOLOv8模型
这个地方,找模型文件
https://github.com/ultralytics/assets/releases
https://github.com/ultralytics/assets/releases/download/v0.0.0/yolov8n.pt
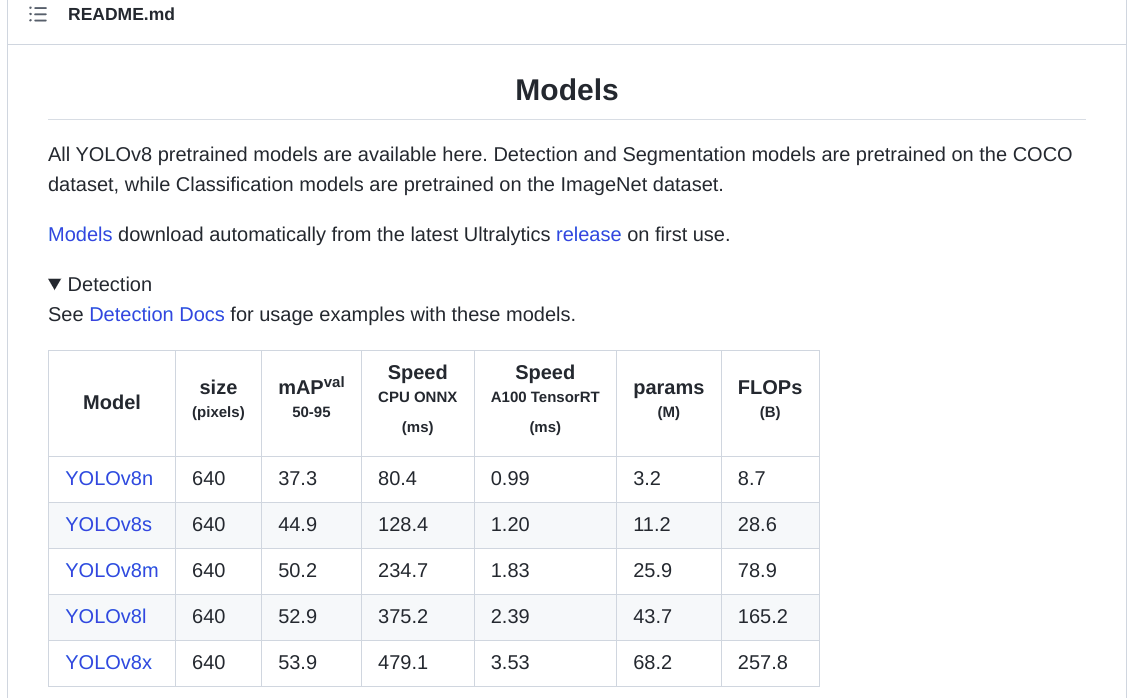
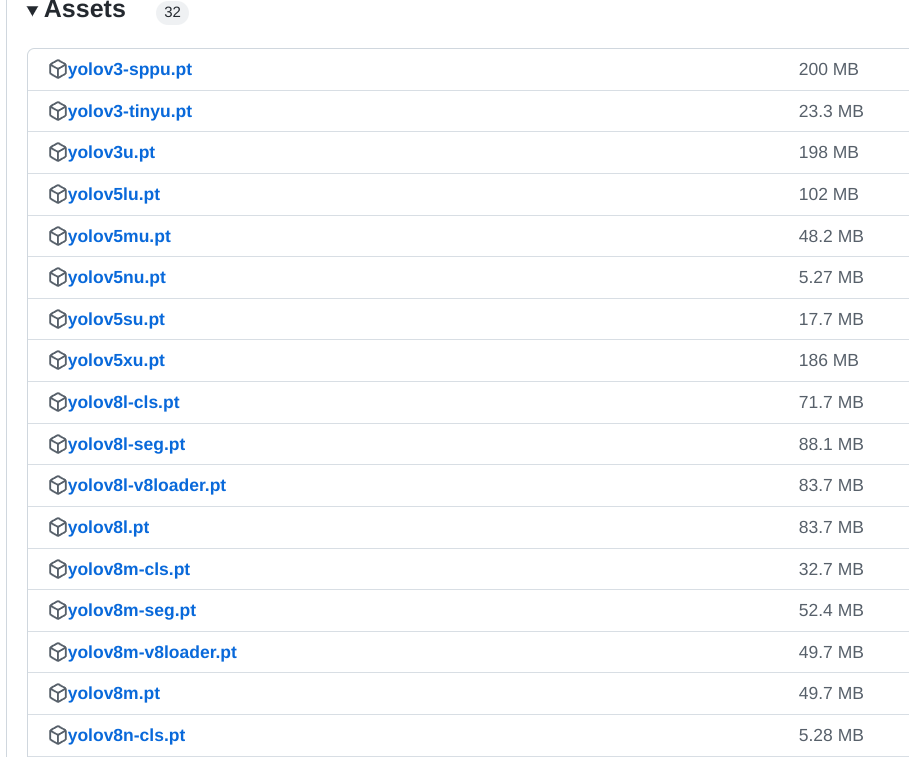
然后在tracking.py line316这个位置修改,将识别过程调用的模型,从“yolov8s-seg.pt”,更改为'yolov8n.pt
parser.add_argument('--yolo-weights', nargs='+', type=Path, default=WEIGHTS / 'yolov8n.pt', help='model.pt path(s)')如果你不换成纯识别的模型,而是继续沿用 带分割的模型,会有下面这样的报错,说你矩阵维度不匹配
- Traceback (most recent call last):
- File "track.py", line 371, in <module>
- main(opt)
- File "track.py", line 366, in main
- run(**vars(opt))
- File "/home/albert/anaconda3/envs/py380tc170/lib/python3.8/site-packages/torch/autograd/grad_mode.py", line 26, in decorate_context
- return func(*args, **kwargs)
- File "track.py", line 216, in run
- masks.append(process_mask(proto[i], det[:, 6:], det[:, :4], im.shape[2:], upsample=True)) # HWC
- File "/media/F:/FILES_OF_ALBERT/IT_paid_class/graduation_thesis/model_innov/yolov8_tracking/yolov8/ultralytics/yolo/utils/ops.py", line 595, in process_mask
- masks = (masks_in @ protos.float().view(c, -1)).sigmoid().view(-1, mh, mw) # CHW
- RuntimeError: mat1 dim 1 must match mat2 dim 0
- terminate called without an active exception
tracking.py line 165,这句话,将最后一个参数去掉
- # p = non_max_suppression(preds[0], conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det, nm=32)
-
- # p = non_max_suppression(preds[0], conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det)
如果你不去掉,就会报这样的错
- File "track.py", line 165, in run
- p = non_max_suppression(preds[0], conf_thres, iou_thres, classes, agnostic_nms, max_det=max_det, nm=32)
- TypeError: non_max_suppression() got an unexpected keyword argument 'nm'
运行代码,识别的过程,显示出来,tracking.py的 line355这样修改
- # line355
- # 原来的
- # parser.add_argument('--show-vid', action='store_true', help='display tracking video results')
- # 更改以后
- parser.add_argument('--show-vid', default=True,action='store_true', help='display tracking video results')
把识别后的录像保存下来,tracking.py的 line367这样修改
这样修改以后,识别的录像保存在了这个位置“runs/track/exp8”,这个录像上有全部的识别框
- # line367
- # 修改前
- # parser.add_argument('--save-vid', action='store_true', help='save video tracking results')
- # 修改后
- parser.add_argument('--save-vid', default=True,action='store_true', help='save video tracking results')
电脑摄像头识别
python track.py --source 0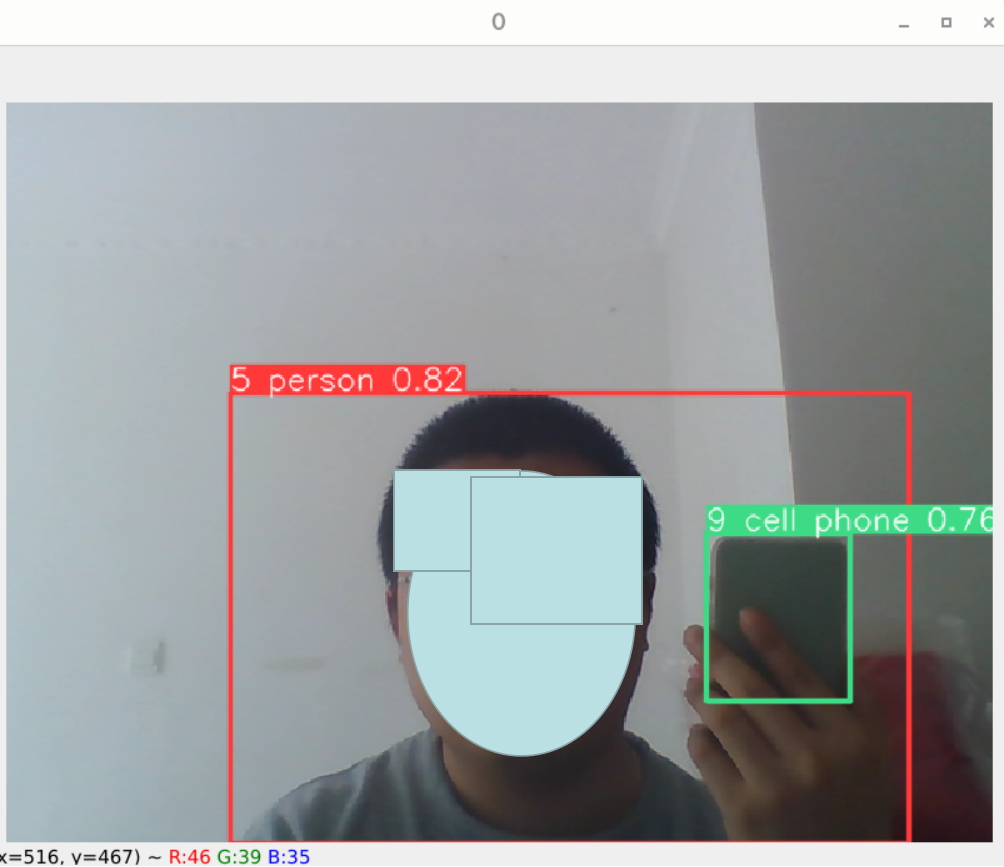
图片识别+计数
- python track.py --source ./val_data/bus.jpg
- # 结果:val_data/bus.jpg: 640x480 3 persons, 1 bus, 11.0ms
- # 数出了图中的人数,3个人,一辆车
-
-
- python track.py --source ./val_data/15_persons.PNG
- # 结果:PNG: 256x640 11 persons, 2 bicycles
- # 12个人数出11个,(这是一个参数最少的模型,情有可原),之前的yolo5只数出7个人,比YOLOv5进步很大了
视频识别
python track.py --source ./val_data/Traffic.mp4可以运行数出来的是每一帧图中汽车的数量,有三辆,有四辆,有两辆
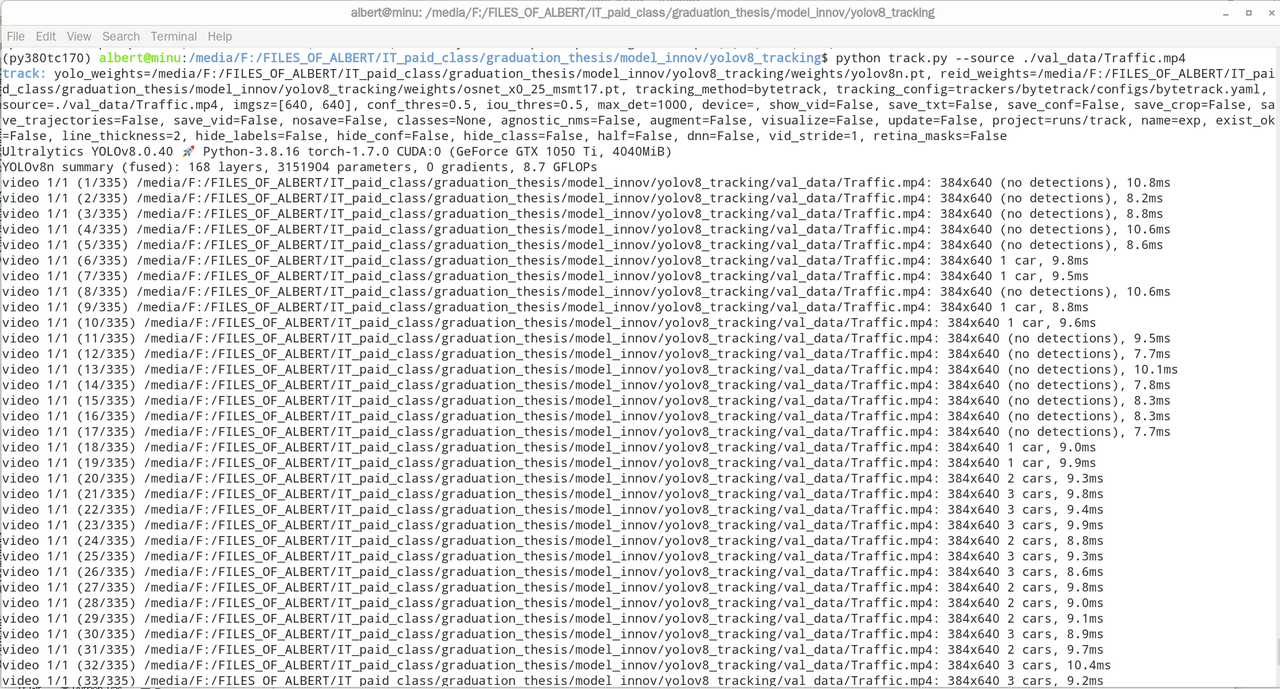
- 3 cars, 9.7ms
- 4 cars, 9.3ms
- (no detections), 7.8ms
- 1 car, 8.3ms
视频识别结果,在这里看./runs/track/exp


