
- 1软件测试工程师面试汇总Linux篇
- 2CVPR 2021最全论文开放下载!附pdf下载链接!_cvpr会议文章链接
- 3如何复用使用store的Vue业务组件
- 4【iOS ARKit】PhysicsMotionComponent
- 5Java面试题16——类型转换中的符号扩展_char转换到short为什么要进行符号扩展
- 6企业数字化转型“核心方法论”_埃森哲 数字化转型规划 方法论
- 7来 Azure 学习 OpenAI 三 - 用 Python 调用 Azure OpenAi API
- 8视频大文件分片上传_vue 大文件 切片 后台上传
- 9Android工程师进阶第十一课 Android网络优化和Flutter开发
- 10【Android】【异常处理】安卓应用一直卡死黑屏,但是不退出_android 触摸屏卡死 但程序还在跑
如何训练一个自己的ChatGPT_chatgpt训练自己的模型
赞
踩
0. 引言
2023年5月30日,微软build 2023开发者大会上,OpenAI的Andrej Karpathy做了名为State of GPT的演讲。我记得2017年学cs231n课的时候他还是助教。看他的简历2015—2017年曾在openAI工作,之后离职去特斯拉做AI部门主管搞自动驾驶,今年又回到了openAI。不知道是不是因为自动驾驶炒不起来了
传送门 【精校版】Andrej Karpathy微软Build大会精彩演讲: GPT状态和原理 - 解密OpenAI模型训练_哔哩哔哩_bilibili
主题是State of GPT,演讲分为两个部分。第一部分讲了如何从头开始训练一个自己的ChatGPT,准确来说是gpt3.5的训练细节,gpt4仍然是保密的。
第二部分讲了使用chatgpt以及其他llm时一些提高回复质量的方法,并从原理出发阐述了为什么这样做可以work。第一部分技术细节比较多,第二部分更偏向实际使用。
1. 如何训练
想要训练一个自己的chatgpt模型,有四个主要阶段:预训练、有监督微调、奖励建模、强化学习。

预训练步骤是用transformer结构在海量互联网语料库里学习世界上所有词语的通用表示形式,这也是gpt这个缩写的由来。给每个词生成一个向量表示,也就是我们常说的embedding。在2018年之前,这个训练过程通常是由RNN和LSTM来做的,后来人们发现transformer结构以及其注意力机制能够很好的解决RNN和LSTM记忆力低下的问题,于是从这时开始,几乎所有的模型都用上了transformer结构。
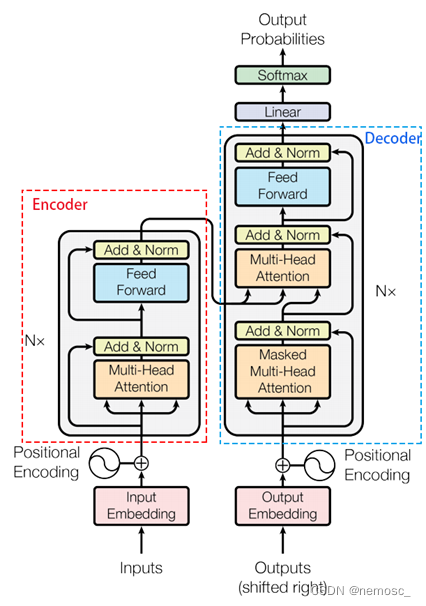
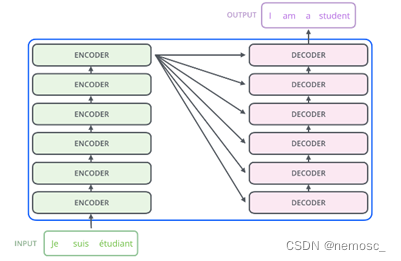
在提出transformer结构的原始论文《Attention is all you need》中,transformer的完整结构是这样的↑,看起来很吓人。实际上gpt完全没有用左边的encoder部分和右边decoder的中间部分,只用了这一小部分↓
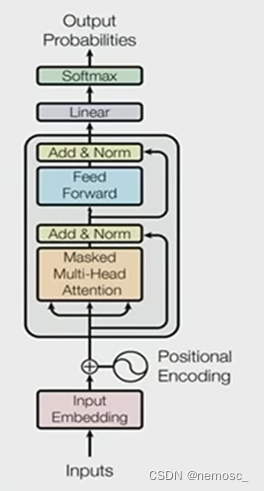
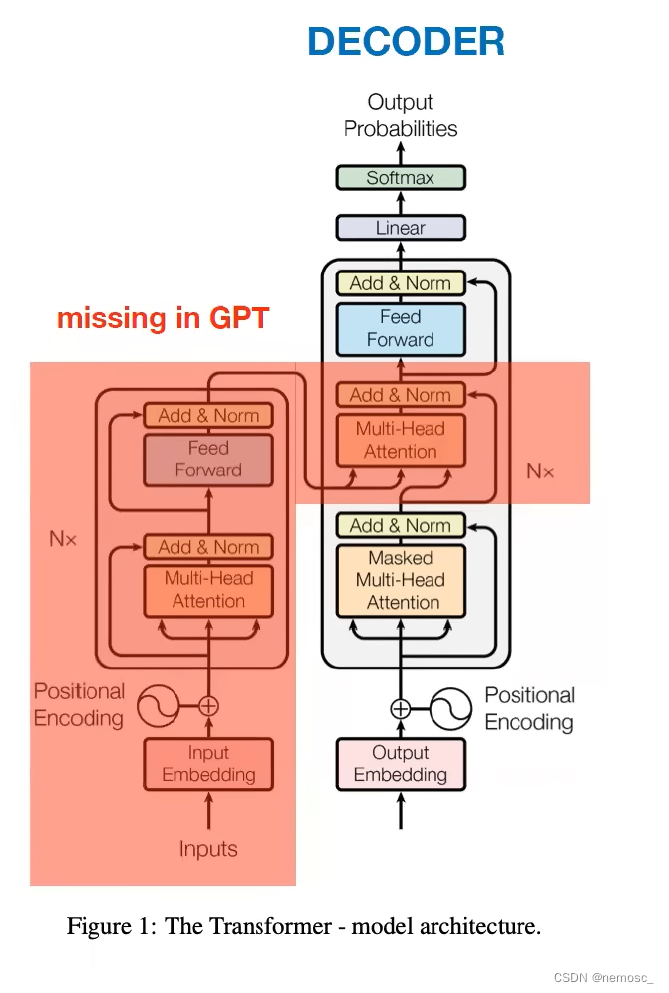
只用到这一部分是因为transformer的原始论文是一篇关于机器翻译的论文,需要用encoder来把输入的语言编码成一个初始向量表示。而gpt本质上是“生成”,也就是给定一篇文章,为其续写,这样的话就只需要decoder这一个输入就足够了。transformer的原理详解如果有时间单独再写一篇文章来介绍,这里再放进来就太长了。
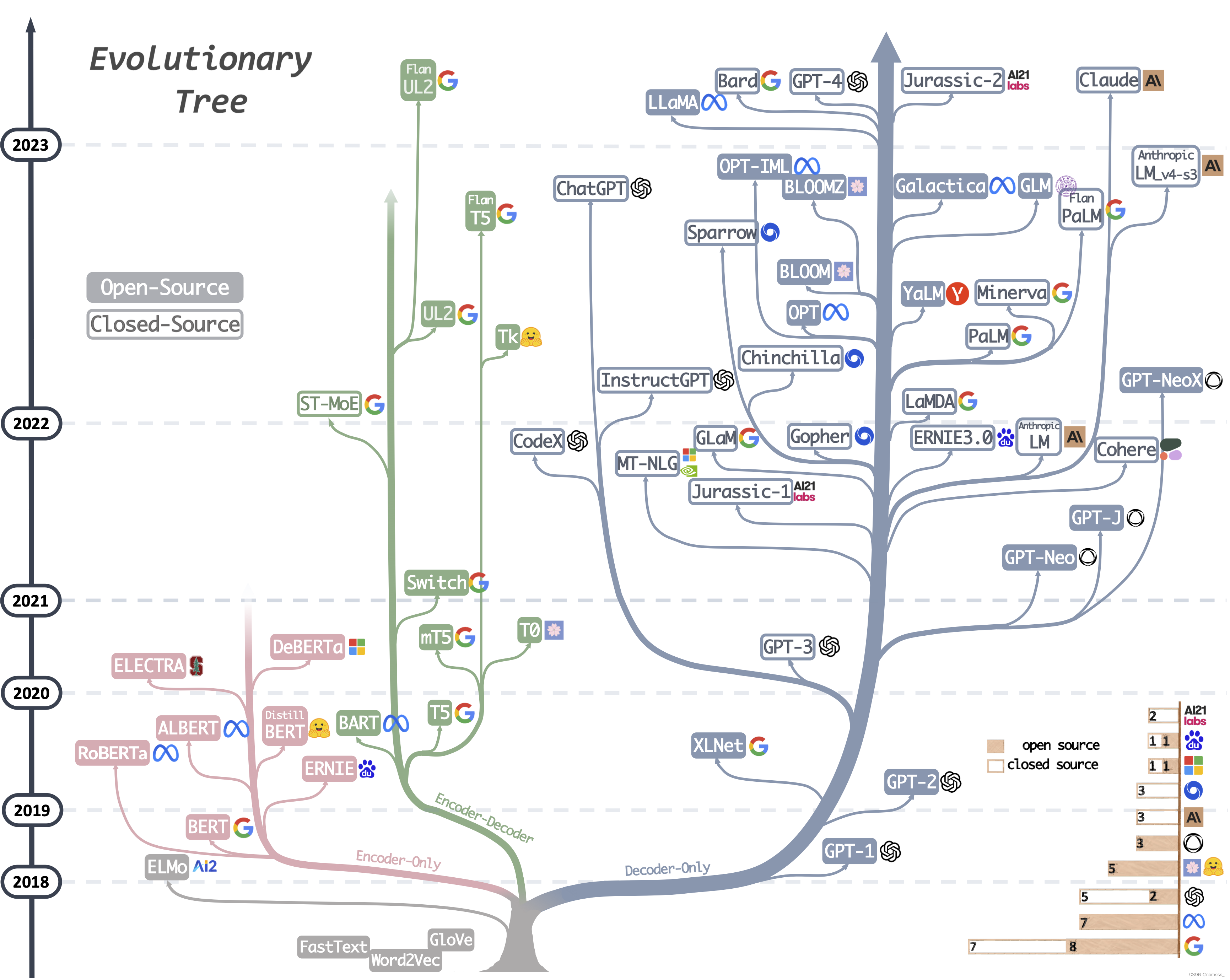
关于transformer衍生模型在自然语言处理领域的发展,可以看到主要分为3个branch,以BERT为代表的encoder-only模型,以及GPT为代表的decoder-only模型,以及T5为代表的encoder-decoder模型,这三个branch基本上代表了3种不同的任务。bert主要用于文本分类,gpt用于文本生成,t5用于机器翻译。可以看这张图,在2023年这个时间节点上,encoder-only的模型已经很少出现了。

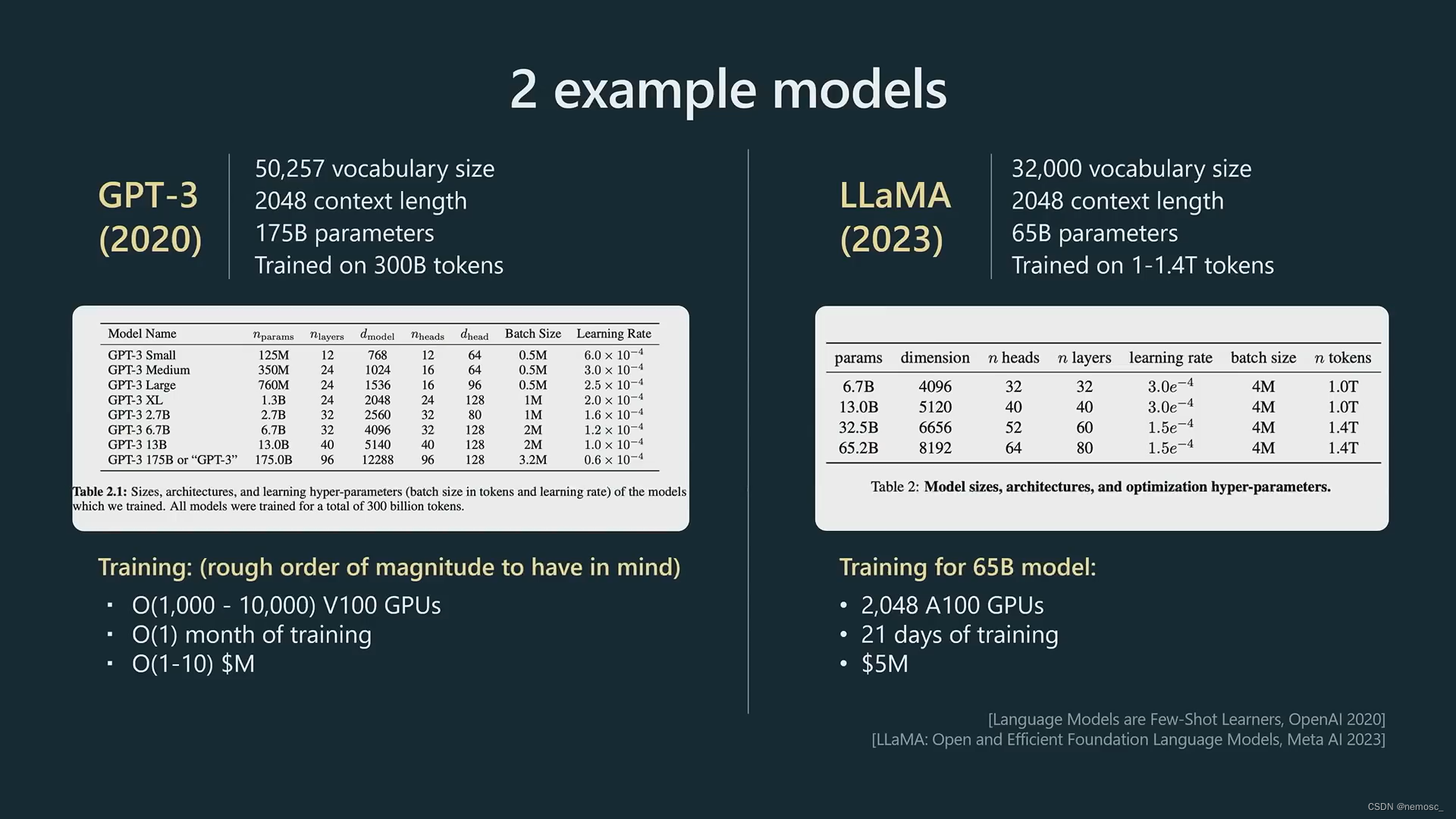
用来训练的语料库详情(这里给的是llama的,gpt的未公开)。可以看到,里面既有高质量的百科、出版物,也有互联网的低质量文本。这就引申出后面提到的一个提高chatgpt回复质量的方法,即在你的prompt里面明确告诉chatgpt,你是一个xx领域的专家/确保给我正确的回答,这样他就会倾向于选择高质量语料中的专家回答来生成结果,而不是用低质量的比如学生的错误回答去对冲(hedge)掉这种概率分布。总的来说,Gpt是一个语言模型,它只想做它被训练成的样子,也就是去完成文档,他并不想得到正确的答案,而你想要得到正确的答案,所以你需要明确告诉他这一点。
通常来说,需要将整个文本分解成token,gpt这里是采用了字节对的分词方式, 将所有文本分解成50000种token(汉语应该不只50000个字,不知道这里是怎么做的分词)。每个token约等于0.75个英文word。
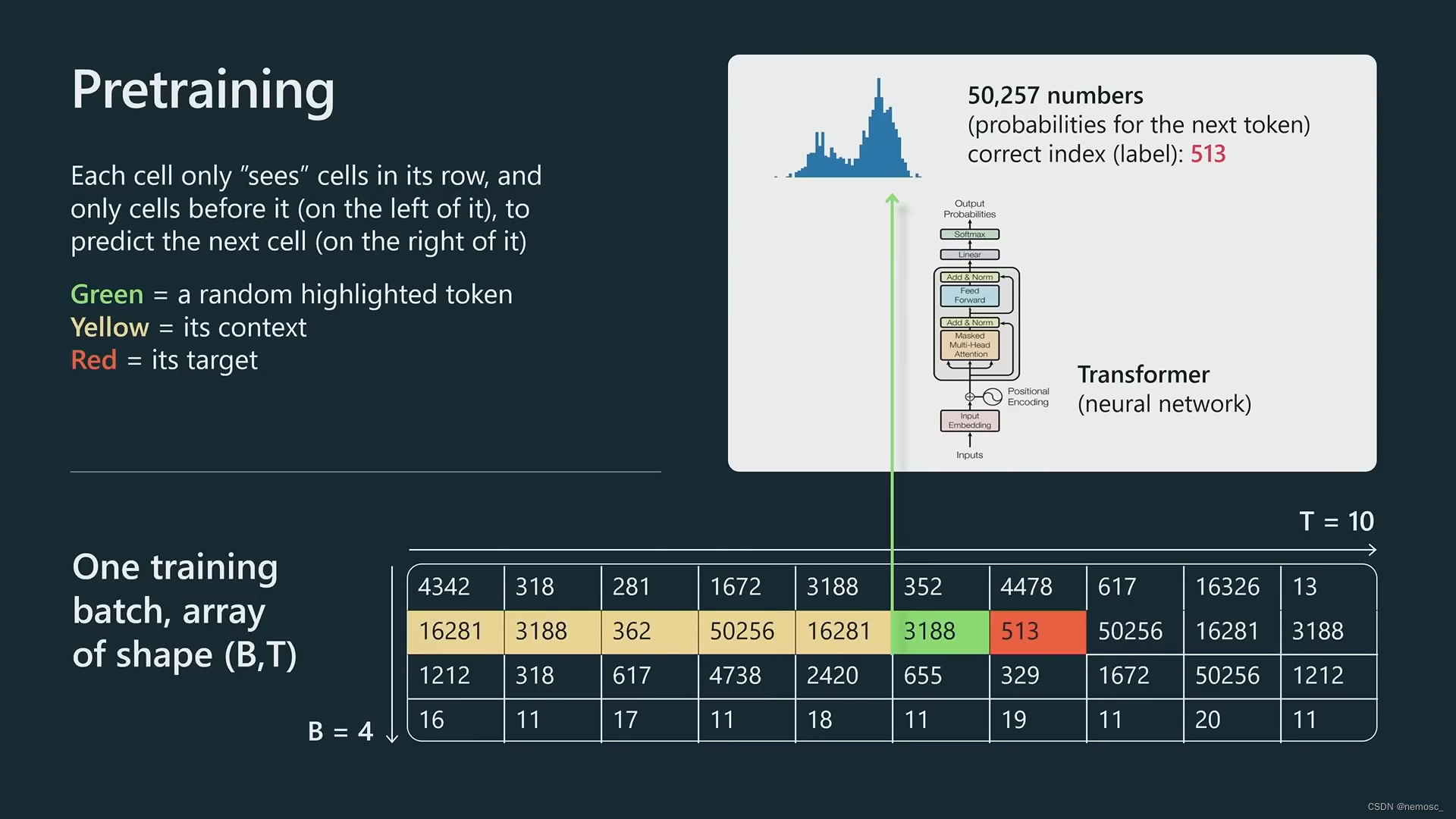
在训练过程中,chatgpt所做的事本质上是根据前面出现过的词去预测下一个词是什么(language model的本质),训练的loss function也是依据这个来确定的。上下文窗口Context window是transformer在预测下一个token时所能够“记忆”或者说参考的token数量,按照各llm官网的介绍,gpt3.5有8k和16k,gpt4有8k和32k,claude有8k和100k。这个值没法提到太高是因为根据transformer的架构,上下文窗口的时间复杂度是O(N^2)。除非以后有新方法能够改进这个问题,否则只能用一些特殊方法来绕过这个限制。比如openai的官网上提到,如果你想要总结一整本书的摘要,显然这个内容已经超过了窗口的大小,你可以用类似于归并排序的方法,首先让他去总结每个章节的摘要,然后逐层merge,最后得到一个结果。另一种方法是用信息检索的方法抽取出全量文本中与用户请求相关的部分,然后仅将这些相关部分提供给chatgpt,让它根据这些内容生成回复。这也就是newbing或者chatgpt的检索插件所做的。具体实现起来是将全文以句子或段落为单位划分为多个块,然后将每个块向量化,用向量检索方法匹配出与用户请求相关的部分。

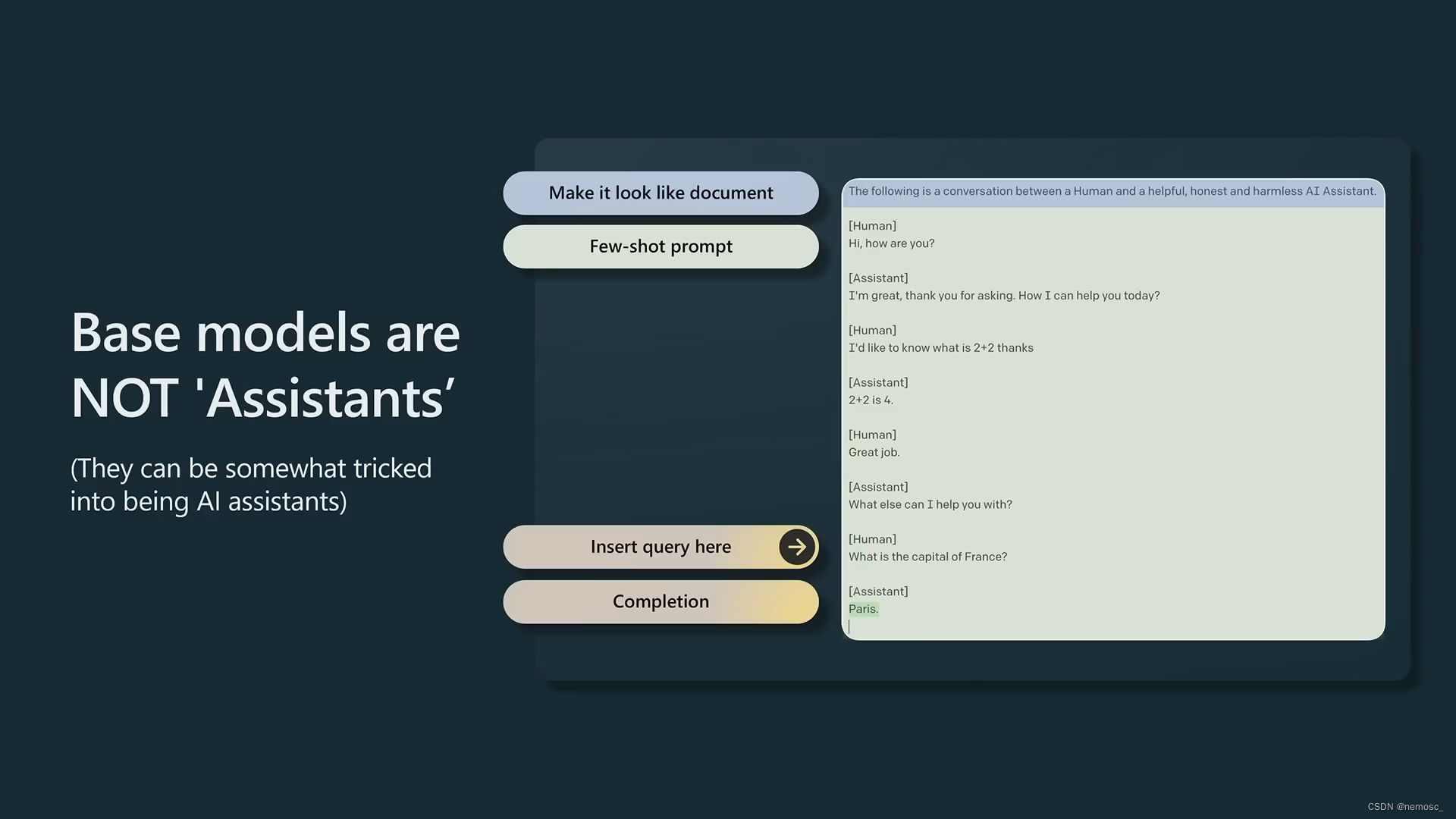
在经过了这个预训练过程之后,我们已经得到了一个可用的gpt3模型,他会根据给定的输入去补全文档。在openai这里是completion api中的davinci模型。但是这不是chatgpt。想要得到chatgpt还要经过后面的微调、强化学习步骤。这一步的模型如果你问他一个问题,他更倾向于提出更多类似的问题,而不是去回答你的问题,因为他认为这是在补全文档。除非你在文档中写道:下面是这个问题的答案,然后留空,这样他才会回答问题。这一步的模型叫base模型,gpt、llama、palm都属于这一类。
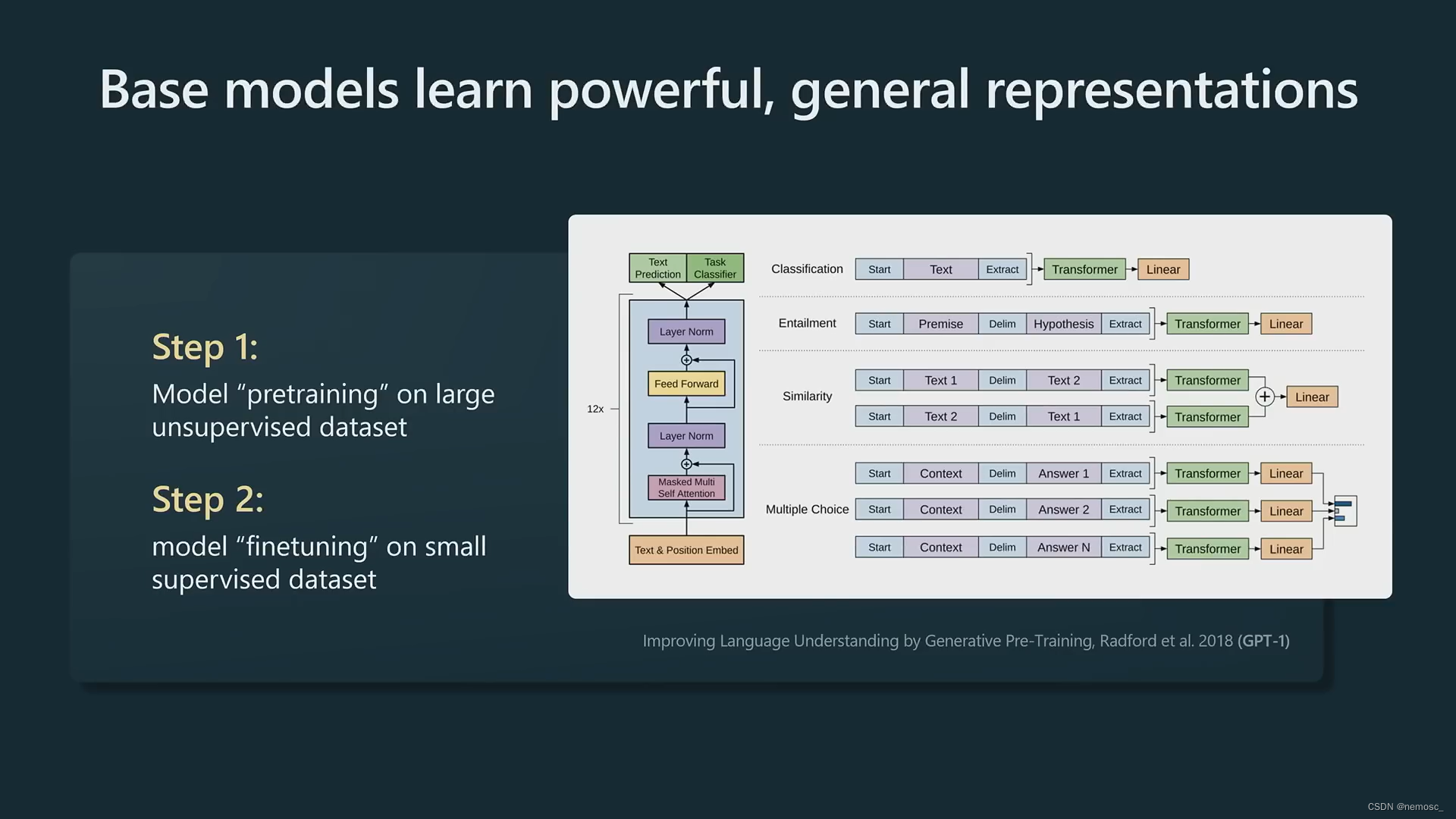
在较早的时代,nlp模型都是在全量标注文本上进行模型的训练,而大概是在transformer出现的时间点前后,人们发现可以使用在大规模语料库上预训练的模型,然后在少量有标注文本上进行有监督微调,得到效果更好的模型。Bert和gpt都是采用这种思路进行模型参数的优化。预训练的模型可以学习到每个词的通用表示形式,它通过“预测下一个词”这一任务逐渐理解了整个世界,对下一个词的预测越准确,就表示他对世界理解的越深刻。这就好比在推理小说的最后,侦探宣告所有线索已经集齐,凶手的名字是——预测下一个词,对案件理解的越透彻,就能够越准确的预测下一个词。

而到了gpt2的时代,又有了新的发现,由于gpt本身是一个生成模型,除了直接对参数进行微调之外,实际上可以直接去提示(prompt)gpt,欺骗(trick)gpt去通过补完文档来执行你的任务。例如在这个例子中,提供了一个段落和少量的Q/A,gpt在完成文档的过程实际上也回答了我们提出的问题。从此nlp就迈入了一个全新的时代:提示工程(prompt engineering)。

预训练之后是有监督微调(supervised fine tune)步骤,这一步的目的是将第一步预训练得到的文档补全模型调整为用来回答问题的助手模型。让他在通过承包商提供的外包给人类编写的少量高质量文本集上训练,更新模型的参数。这也是transformer模型的通常使用方法。由于外包需要花钱,所以只能收集到少量的文本,否则如果能得到无限的高质量文本的话就不需要预训练这一步了。这个类似于以前“半监督学习”的概念,不过现在的通用方法就是这个fine tune。这一步的模型叫SFT模型,Vicuna属于这一类。
微调之后的模型已经可以作为问答助手使用了,但是还可以进一步提升其回答质量,这是通过强化学习(RLHF)来实现的。这个过程分为两个步骤。
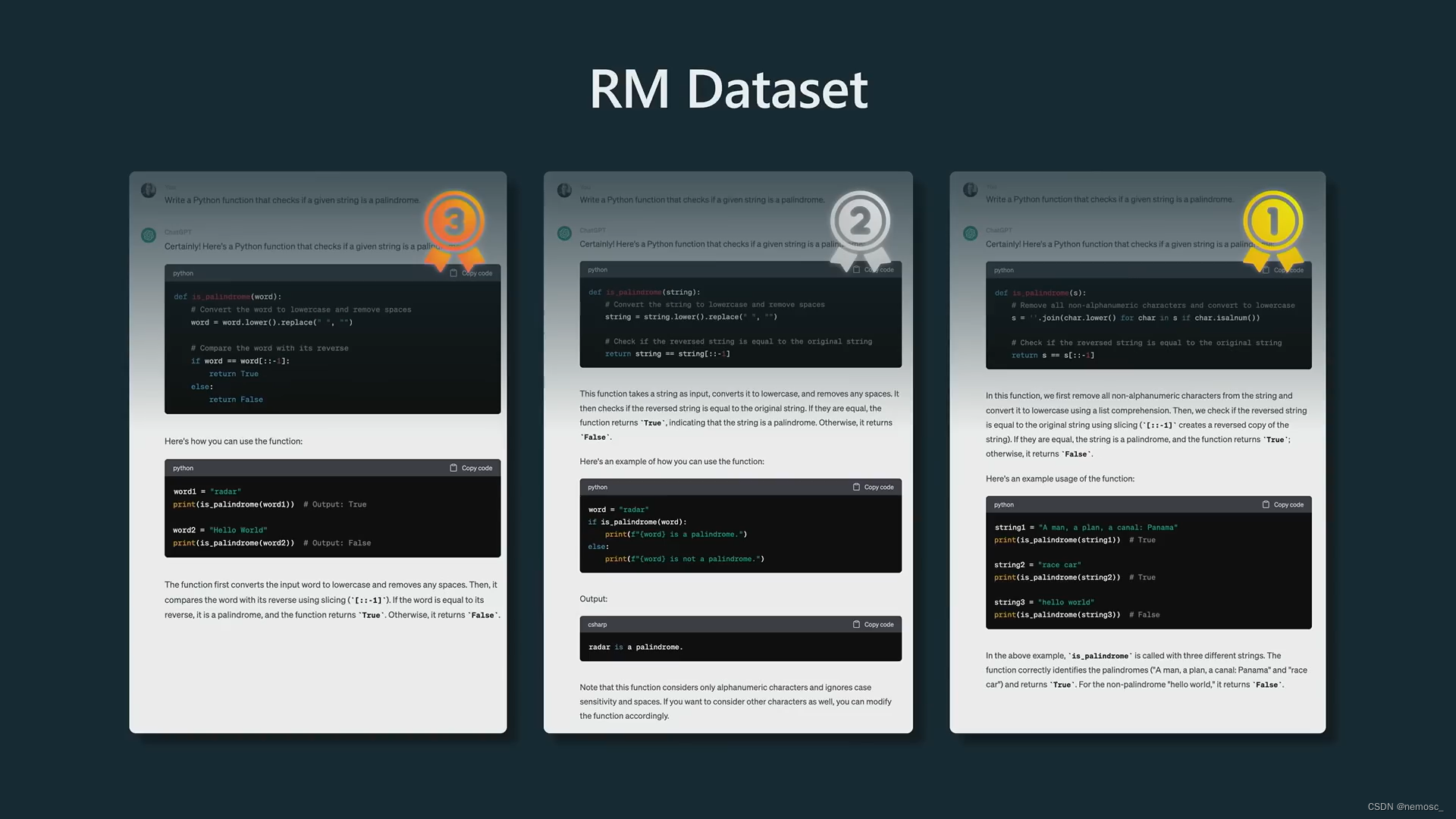
首先需要训练一个分类器,用来给SFT模型生成的文本打分。比如我用SFT模型生成了3个回复,分类器给这3个回复分别打了分数,得到了这三个回复的优劣排序,然后和承包商提供的有标注的排序结果相比较,从而确立损失函数。这个分类器叫RM模型,这个模型只能用来打分不能实际使用所以没有人放出来,他主要是用来给下一步的强化学习用的。
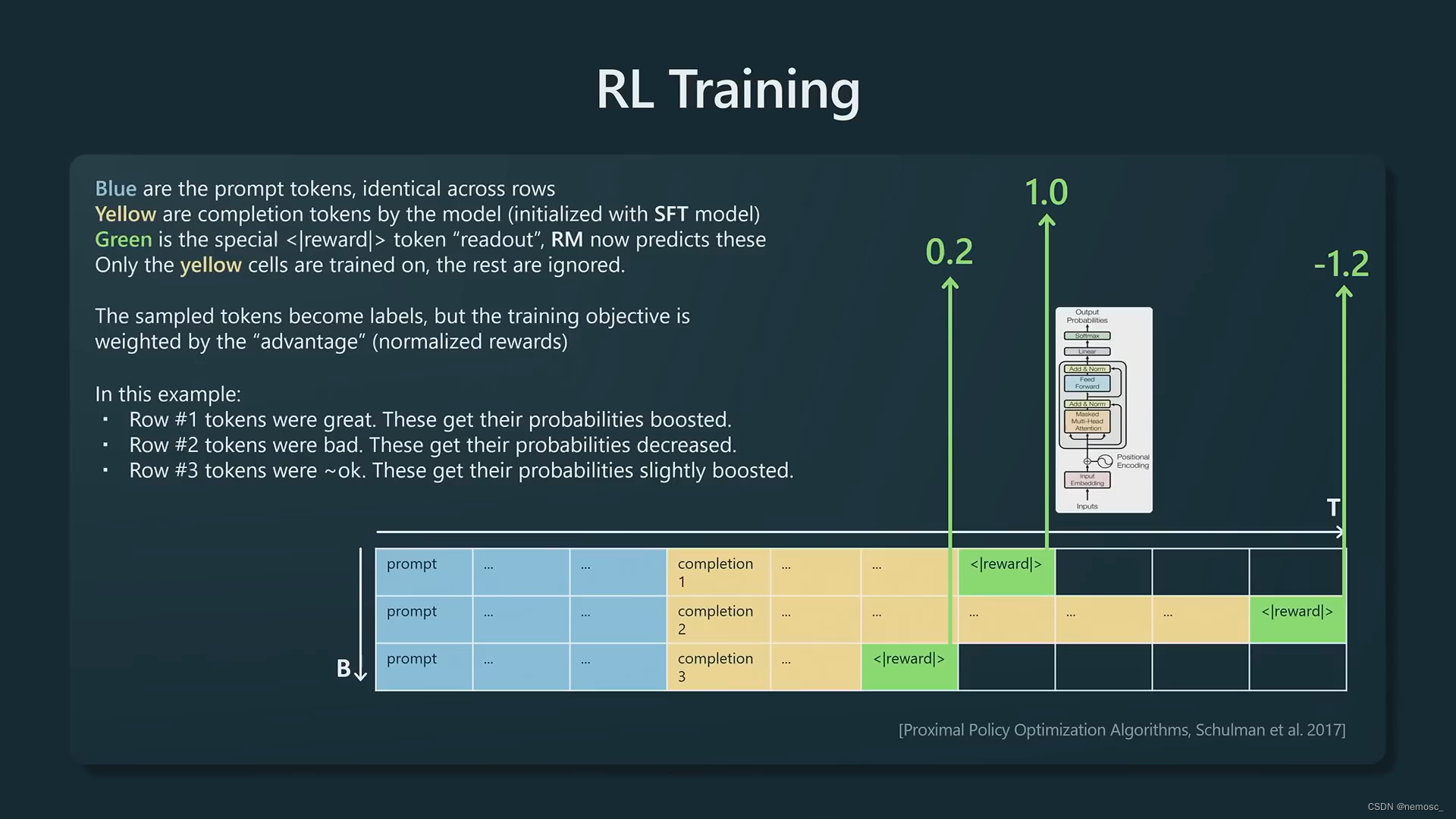
第二个步骤是强化学习,用SFT模型对承包商提供的prompt来生成一系列回复,使用上一步训练好的RM模型分类器,给这些回复打分。对于分数比较高的回复,提升其回复中出现的token的出现频率,而分数低的则降低其中token的出现频率。训练结束之后得到的是RL模型,也就是我们实际在使用的chatgpt、claude这些。
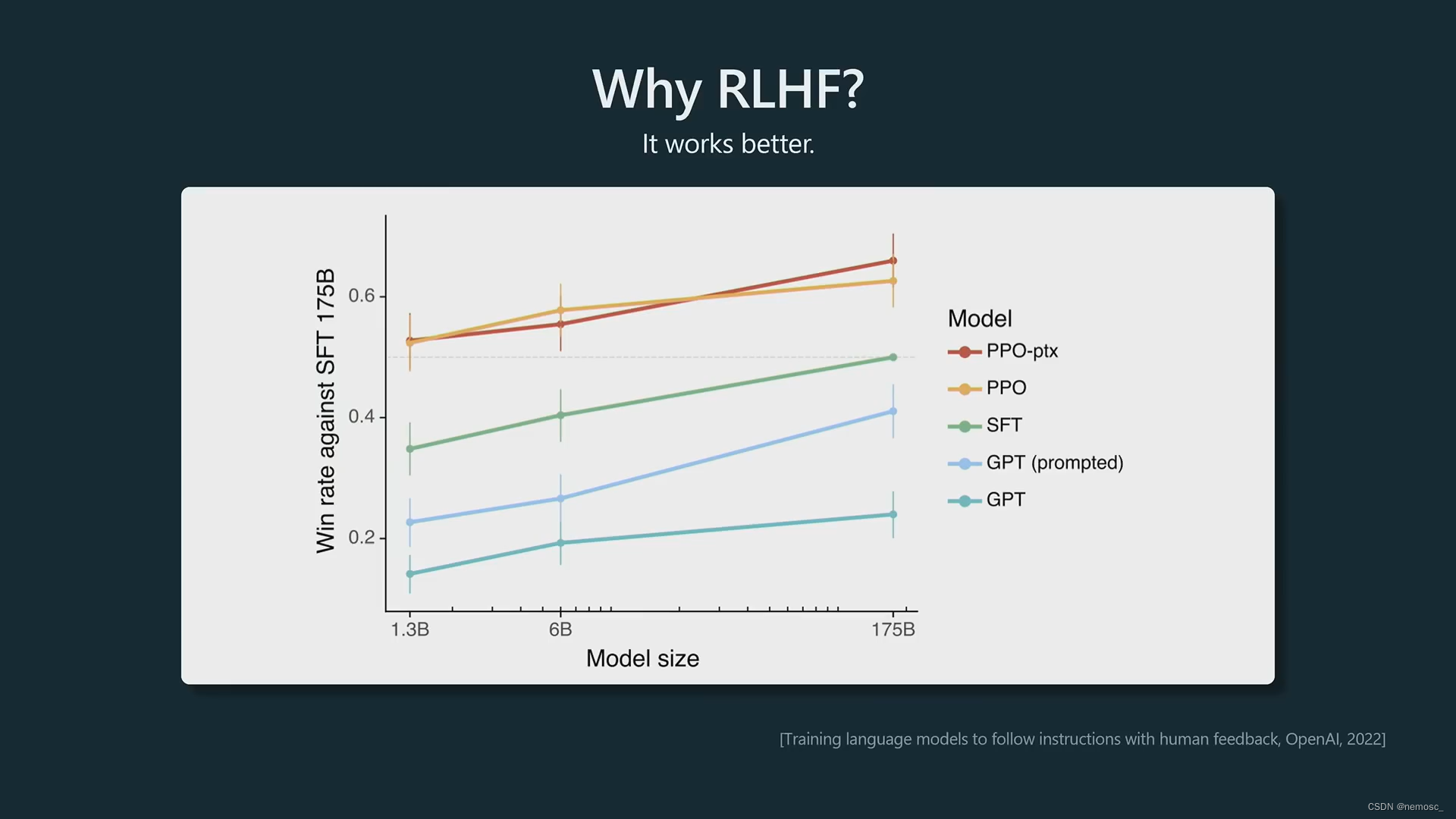

openAI在一篇论文中提到他们的研究结果,如果交给人类打分,则排序为RL模型的结果优于SFT模型优于base模型。Andrej在这里给出一个可能的解释是“比较”相对于“生成”来说是一个更简单的任务,因为承包商在SFT阶段提供的训练文本不一定是最优的答案,而在RM模型提供的排序则更容易保证是最优的答案,因此利用这些最优答案可以创建一个更好的模型。

RL模型的训练过程丢失了一些熵,这意味着他们会提供更加峰值(peaky)的结果,也就是结果更加确定,而base模型的熵更高,会提供大量不同的输出。那么什么openai为什么要把base模型单独放出来呢,他在什么情况下更适合呢,Andrej举了一个例子,比如你给他一些实际存在的宝可梦名字,要求他去生成一些新的宝可梦名字。这个模型会倾向于生成有创意的、不同的名字。

总之,第一个步骤基本是无监督的,而后三个步骤都是需要人工标注的数据。如果你有特殊需求可以选择在base模型的基础上微调出自己的SFT模型,openai的api也提供了允许用户在gpt3的基础上微调的接口。而后面的RLHF过程则更难以控制,只推荐专家进行这个操作。
2. 如何提高回复质量


人类生成文本与chatgpt生成文本有本质的区别。人类在写作时要进行很多的推理过程。比如我要去各种网站查资料,计算,反思内容是否准确,反思这句话的表达方式是否有问题等等。但是chatgpt不会,他写作的过程就像是磕了炫迈一样停不下来,他虽然也有很多层神经网络,能记住海量信息,但是不像人类一样需要经过推理,也没法回头去反思或修改已经生成的内容。所以我们希望他解决一个非常复杂的问题,就要明确的告诉他去遵循这个推理过程,让它可以利用这个推理过程中生成的词来进行充分的思考。
 思维链。模型需要token来进行思考。把任务分解成多个步骤。提示模型要有内心独白。让模型多生成一些token。少样本提示:提供几个样例来教他应该如何回答。零样本提示:Let’s do this step by step。
思维链。模型需要token来进行思考。把任务分解成多个步骤。提示模型要有内心独白。让模型多生成一些token。少样本提示:提供几个样例来教他应该如何回答。零样本提示:Let’s do this step by step。

多次尝试,选择正确的一个。Chatgpt在回复过程中有可能运气不好的输出了一个错误的词从而陷入误区,使得他无法得出正确答案,但是他无法更改他已经生成的词,也无法从错误中恢复。可以让他多来几遍,然后进行多数投票。
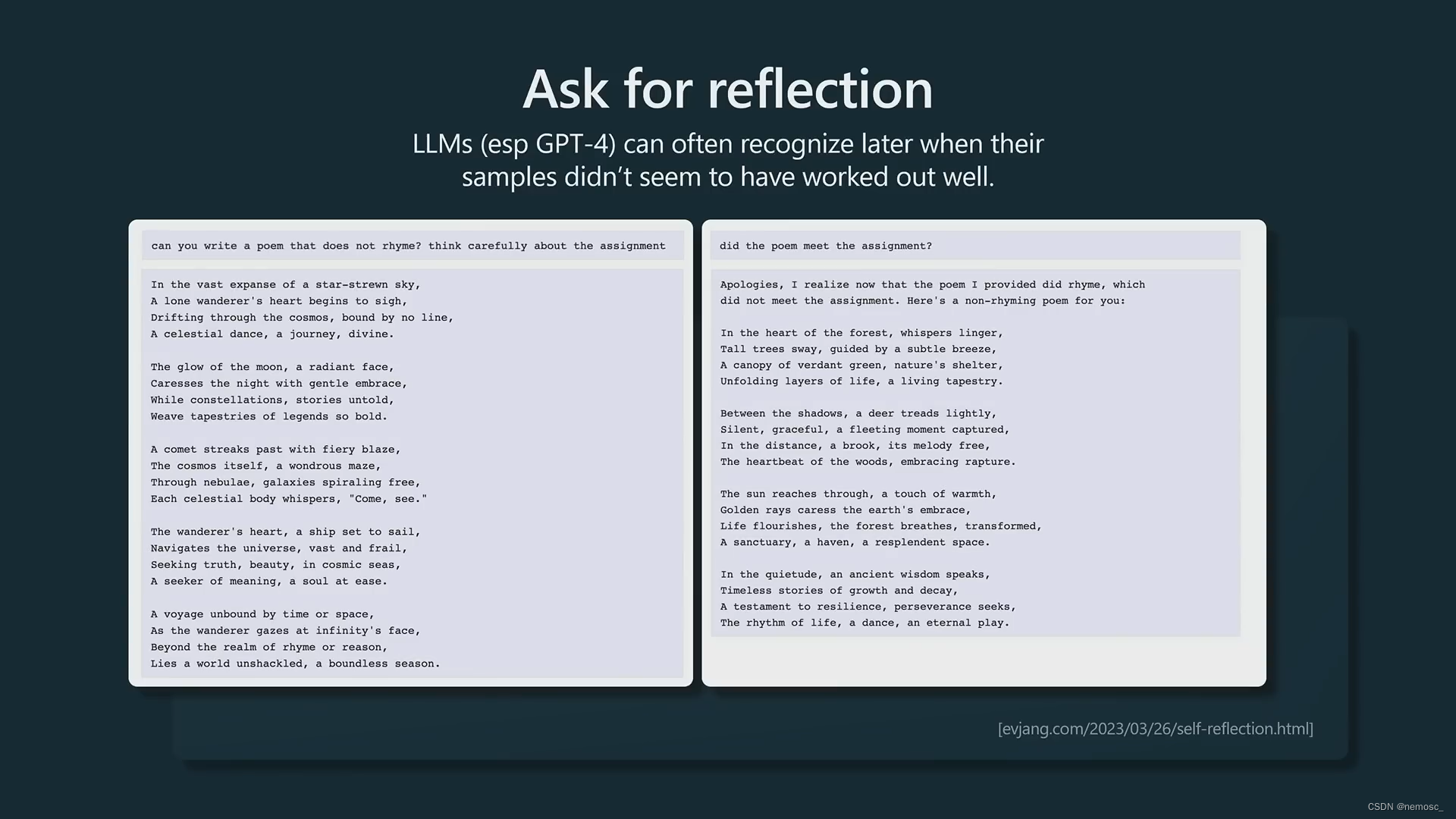
要求chatgpt反思他的回答。像是gpt4这种模型完全有能力认识到他犯的错误并更正,但是需要你明确告诉他让他反思,他自己是不会反思的。
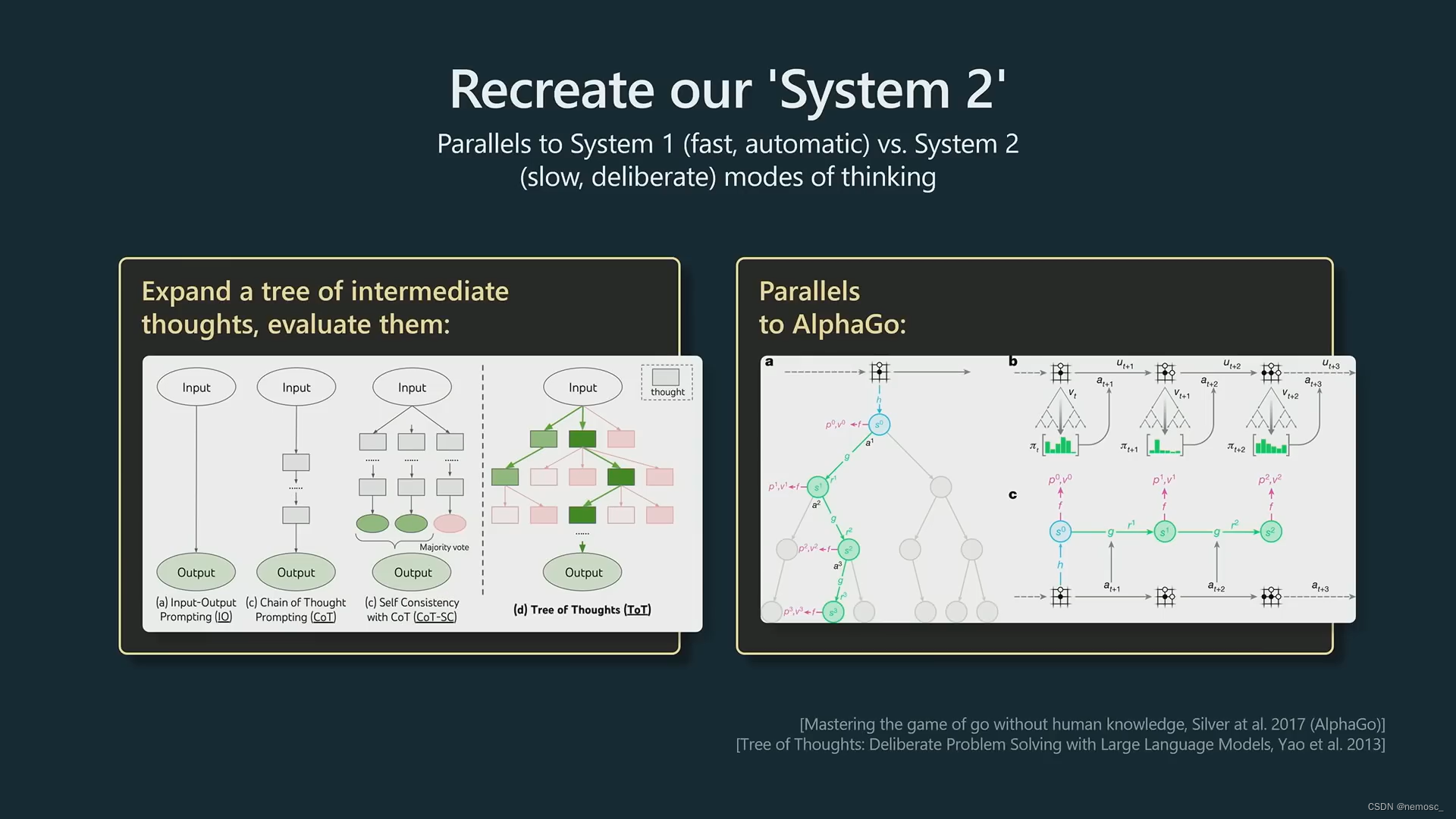
system2。System2的意思是大脑中深思熟虑的计划过程。让他思考所有可能性并在头脑中评估所有可能性,然后只保留比较好的可能性。这个实现需要写一些python胶水代码来维护多个生成序列,然后用树搜索方法找到最优的生成结果。类似alphago的蒙特卡洛树搜索。(个人不太了解)
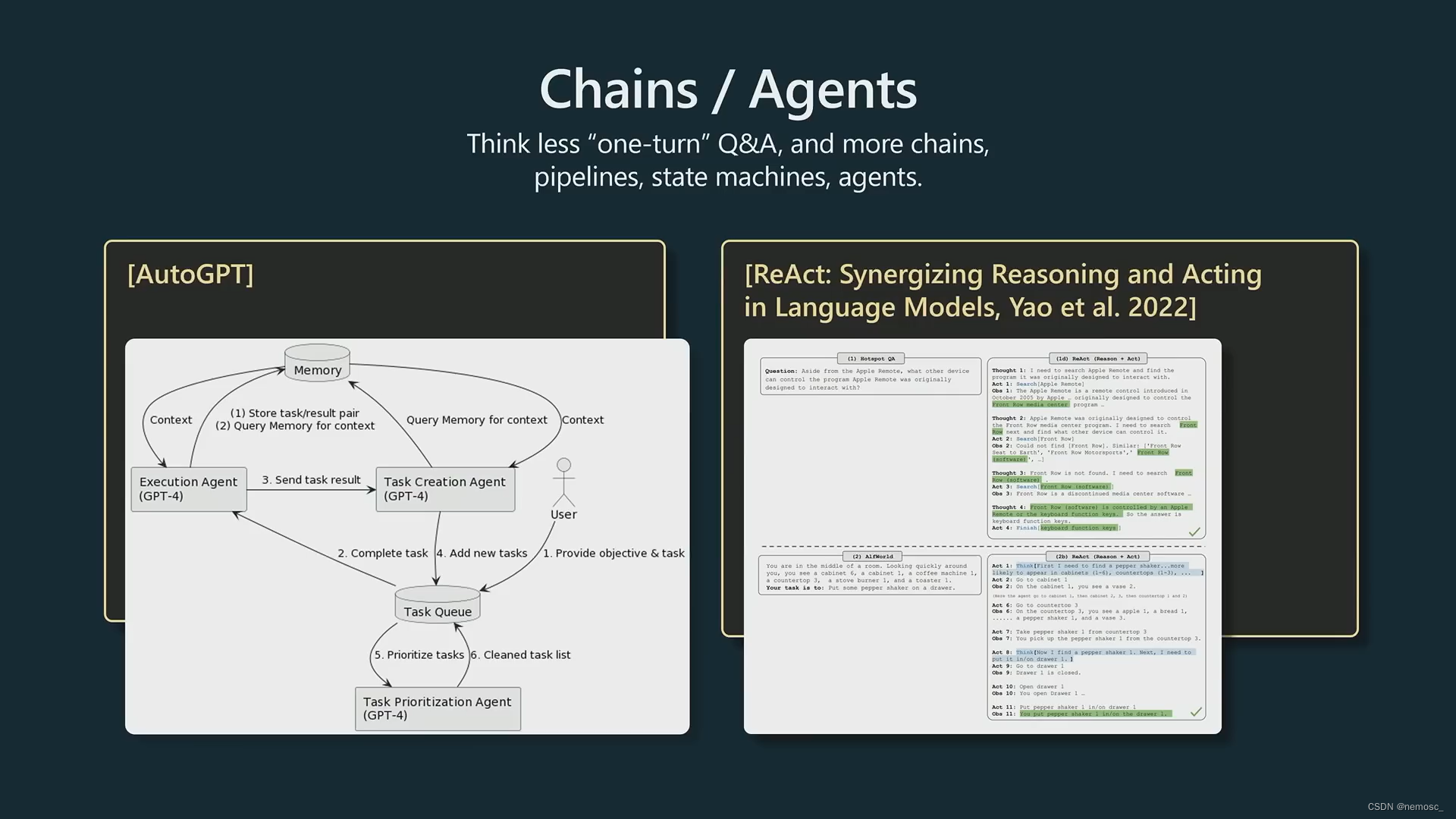
区分步骤、每个agent分头执行。Github上有一个很火的项目autogpt,现在已经有141k个star了(也是star最多的gpt项目)。他是创建了多个独立的Agent,每个Agent使用gpt4只执行单个任务,通过各个Agent之间的协作来得到最终结果。Andrej说这个项目现在还没法在实际场景应用,但是思路非常好。

明确要求他提高回复质量。反直觉的一点是:gpt是一个语言模型,它只想模仿它的训练过程,也就是去完成文档,他其实并不想得到正确的答案,而你想要得到正确的答案,所以你需要明确告诉他这一点。他就会倾向于选择高质量语料中的专家回答来生成结果,而不是用低质量的比如学生的错误回答去对冲(hedge)掉这种概率分布。Andrej这里讲了个笑话:如果你要求假设他的IQ=120来限制他输出高质量的文本,要确保你给的IQ在合理的范围内,如果你给个400的IQ,他会生成一些类似科幻的内容。上图↑是一些比较好用的prompt。
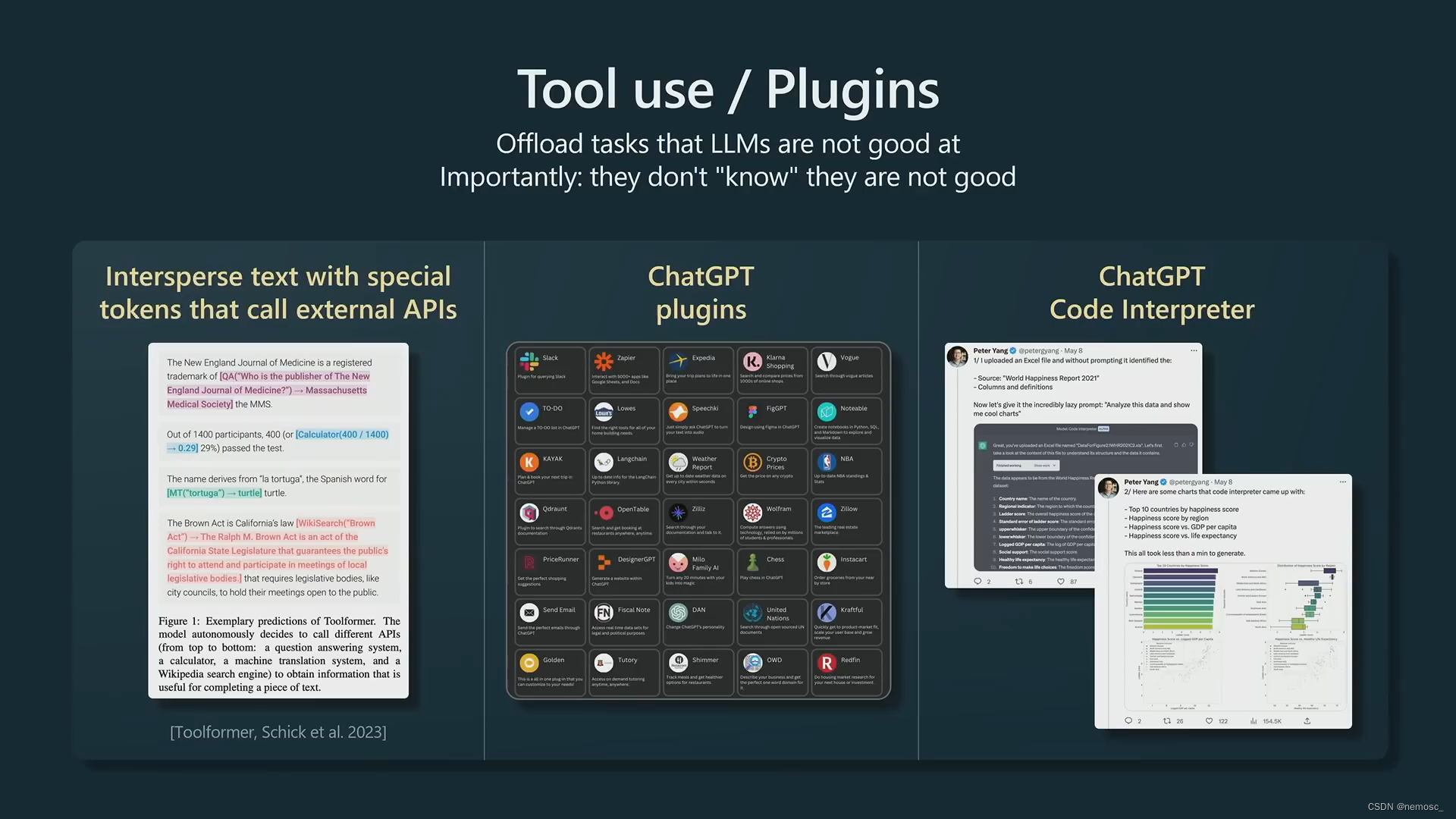
chatgpt不擅长计算,但是他自己不知道自己不擅长什么。使用插件。
 融合文本生成与信息检索。Transformer的上下文窗口有限,使用信息检索的方法预先检索出最相关的部分(newbing的思路)。抽取出全量文本中与用户查询相关的部分,然后仅将这些相关部分提供给chatgpt,让它根据这些内容生成回复。具体实现是将全文以句子或段落为单位划分为多个块,然后将每个块向量化,用向量检索方法匹配出与用户请求相关的部分。
融合文本生成与信息检索。Transformer的上下文窗口有限,使用信息检索的方法预先检索出最相关的部分(newbing的思路)。抽取出全量文本中与用户查询相关的部分,然后仅将这些相关部分提供给chatgpt,让它根据这些内容生成回复。具体实现是将全文以句子或段落为单位划分为多个块,然后将每个块向量化,用向量检索方法匹配出与用户请求相关的部分。
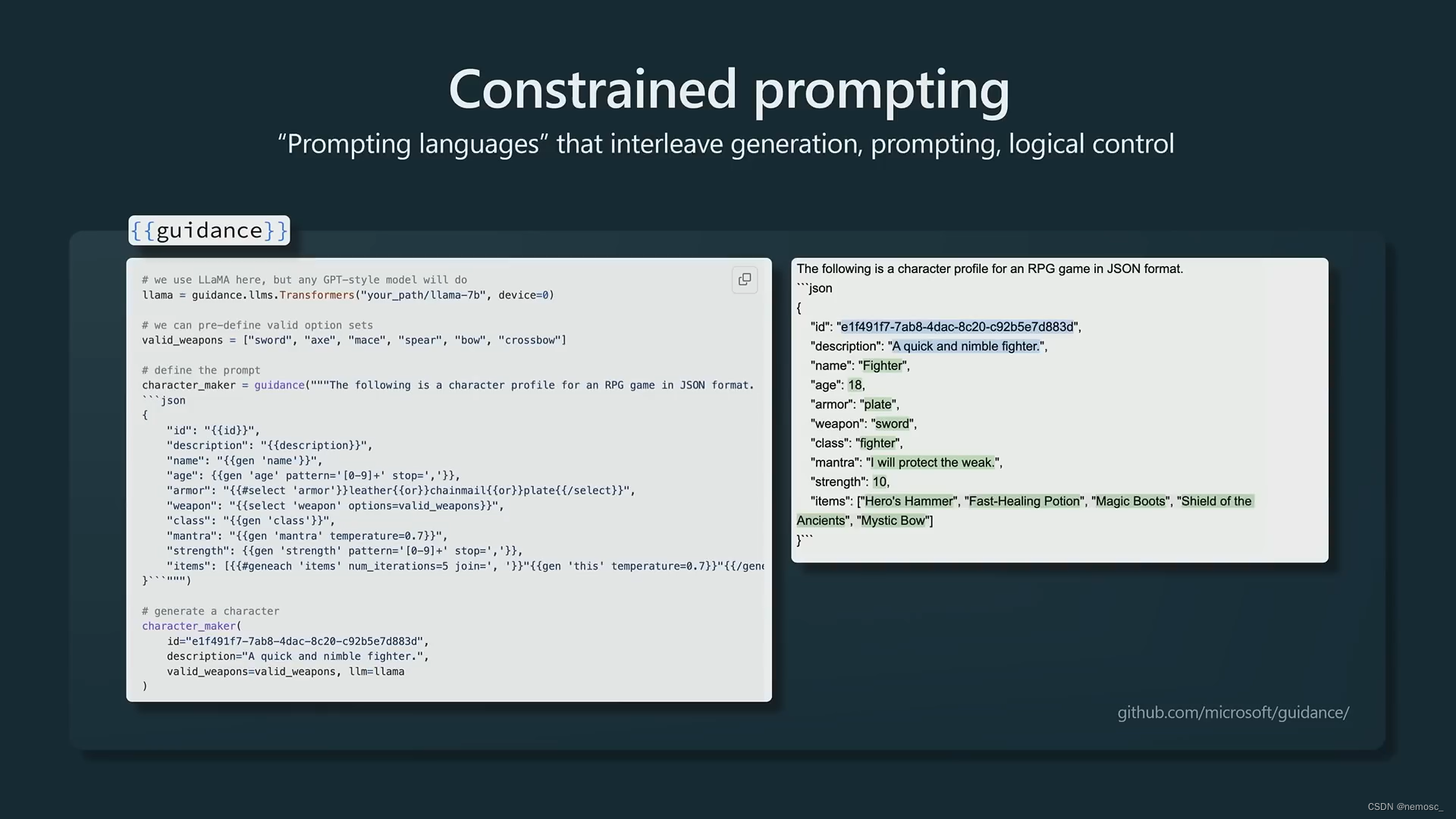
使用结构化格式。微软的guidance库(不太了解,个人理解就是类似于玩claude模板的时候要求他结尾带上用代码块包裹的状态栏)
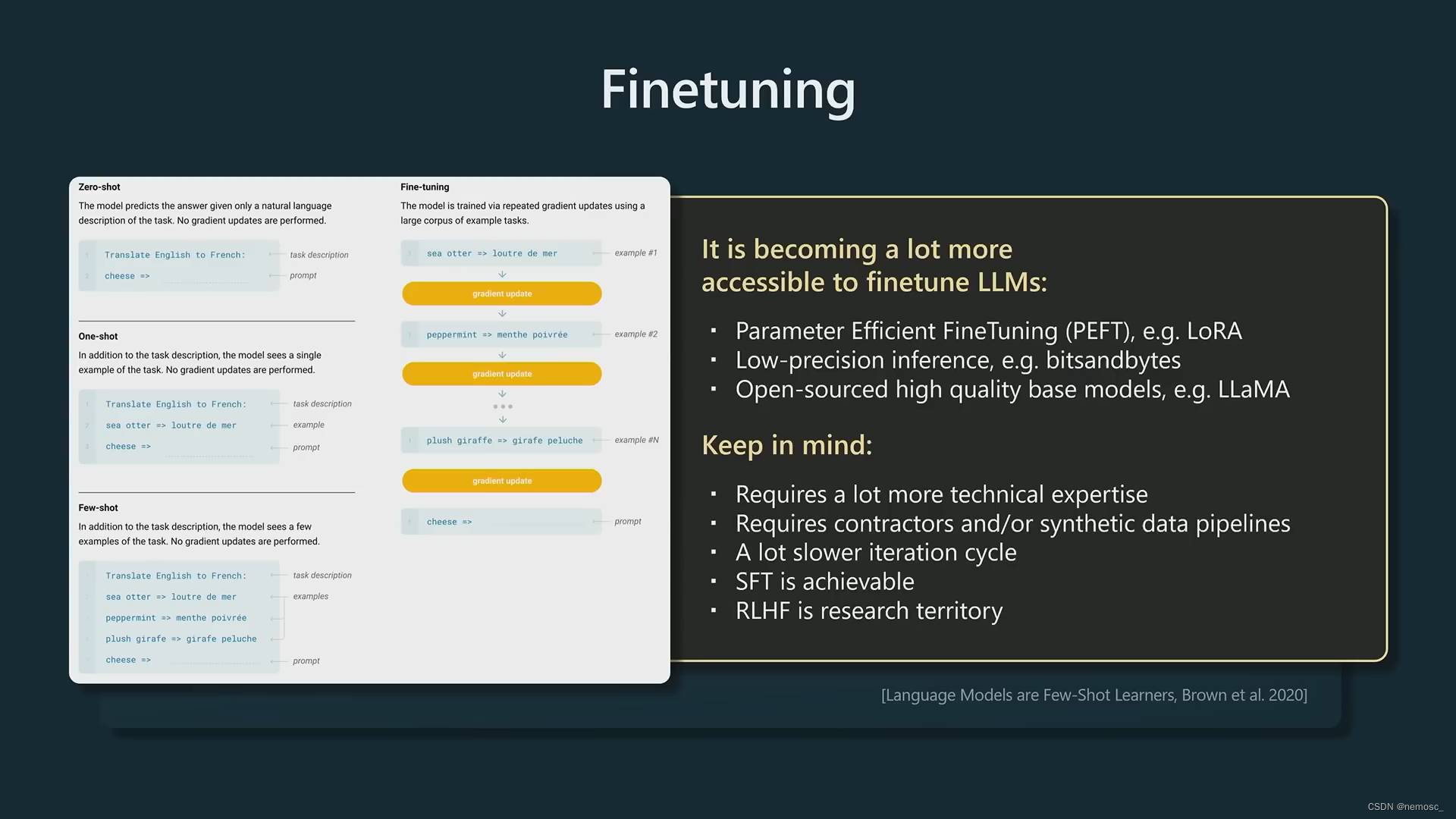
自行微调。成本会比从头训练一个模型小得多,个人也可以实现,比如用LoRA方法,只更新模型中稀疏的部分。SFT是比较容易做的,RLHF则很难调节。

