
- 1Android Handler.postDelayed 挖坑记_android studio mhandler.postdelayed
- 2springboot项目实战-API接口限流
- 3初识Metaio SDK (一)
- 4leafLet入门教程兼leafLet API中文文档参考_leaflet中文文档
- 5Python编程实验五:文件的读写操作
- 6【相关问题解答1】bert中文文本摘要代码:import时无法找到包时,几个潜在的原因和解决方法
- 7ESRGAN_esrgan的训练
- 8GEE机器学习——利用随机森林RF方法进行土地分类和精度评定_基于rf的土地利用分类
- 9flex布局(弹性盒子三)_flex 平分
- 10CVPR 2012 Papers_non-linear calibration refinement
只有27亿参数,性能却高25倍!微软发布Phi-2_phi-2模型的github地址
赞
踩
12月13日,微软在官方网站正式发布了,27亿参数的大语言模型—Phi-2。
Phi-2是基于微软的Phi-1.5开发而成,可自动生成文本/代码、总结文本、数学推理等功能。
虽然Phi-2的参数很小,性能却优于130亿参数的Llama-2和70亿参数的Mistral,以及谷歌最新发布的Gemini Nano 2。
值得一提的是,Phi-2没有进行过RLHF(人类反馈强化学习)和指令微调只是一个基础模型,但在多个任务评测中,其性能可以媲美或超过25倍参数的模型。
目前,微软已经开源了Phi-1.5和Phi-1,帮助开发者们深度研究和应用小参数模型。
Phi-1.5开源地址:https://huggingface.co/microsoft/phi-1_5
Phi-1开源地址:https://huggingface.co/microsoft/phi-1
Phi-1.5论文地址:https://arxiv.org/abs/2309.05463
目前,大模型界有一个很怪的现象,就是出的模型参数越来越大,几百亿参数只能算刚入门,上千亿的比比皆是,有的模型甚至已经达到上万亿。
参数高的模型并非不好,而是要看应用场景。对于像微软、OpenAI、百度、科大讯飞这样的基础模型服务商来说,参数越高覆盖能力就越广,例如,ChatGPT已经进化到多模态,除了生成文本,还能生成图片听懂声音等。
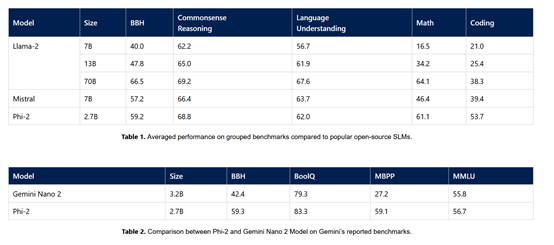
Phi-2评测数据
但参数高的模型同样也有很多缺点:过拟合,如果训练数据较差会出现能力不升反降的现象;算力成本巨大,用户每一次的提问都像是在“燃烧金钱”;预训练时间长,每一次模型的迭代需要耗费大量训练时间。
调优困难,高参数的模型拥有庞大且难控制的神经元,想进行部分功能调优和控制非常困难,最近变懒的GPT-4便是最好的案例。
所以,微软开发Phi系列模型的主要目的是研究,小参数模型如何在保证功能的前提下,也能与大参数的模型相媲美甚至超越,这对于企业和应用者来说是一个双赢的局面。
Phi-2简单介绍
Phi-2和Phi-1.5一样采用了24层的Transformer架构,每个头的维度为64,并使用了旋转嵌入等技术来提升模型性能。
Phi-2只是一个基础模型,没有进行过人类反馈强化学习和指令微调。但在文本生成、数学推理、代码编程方面丝毫不比大参数的模型差,甚至比他们更好。

训练数据和流程方面,Phi-2使用了1.4T超高质量的“教科书级”数据进行了预训练,并非是网络爬取的杂乱、黑箱数据。微软表示,这也是小参数模型比大参数模型性能高的关键原因之一。
Phi-2 在 96 个 A100 GPU上一共训练了14天。
Phi-2实验数据
微软在MMLU、BBH、PIQA、WinoGrande、ARC easy、Challenge、SIQA和GSM8k等主流测试平台对Phi-2进行了测试。
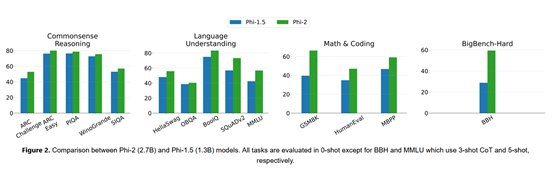
数据显示,在各种聚合基准上的测试超过了,Mistral -7B和Llama-2-13B。
值得一提的是,在多步推理测试任务中,例如,编码和数学,Phi-2的性能超过了700亿参数的Llama-2。
本文素材来源微软官网、Phi-1.5论文,如有侵权请联系删除

