- 12020-01-09:InsightFace项目实战(四)调用模型检测_insightface模型输出
- 22、golang开发工具VScode安装配置_vscode golang
- 3Eclipse的设置Preferences,与项目Project的设置Properties,以及它们之间的关系_eclipse的配置preferences
- 4小麦苗的常用代码--常用命令(仅限自己使用)--上_zhs_notify_tools_x=74px
- 5鸿蒙HarmonyOS实战-ArkUI动画(布局更新动画)_鸿蒙系统动画
- 6安装Python 3.6 在Ubuntu 16.04 LTS 版本
- 7神经网络模型和动态计算图、梯度计算与自动微分_自动微分 神经网络
- 8Deep Captioning with Multimodal Recurrent Neural Networks ( m-RNN )
- 9Guitar Pro吉他软件2024使用教程汇总
- 10node 14.19.0 版本成功解决:安装 node-sass 和 sass-loader 的过程及各 node 版本对应的 node-sass 版本号_node14版本对应的nodesass版本
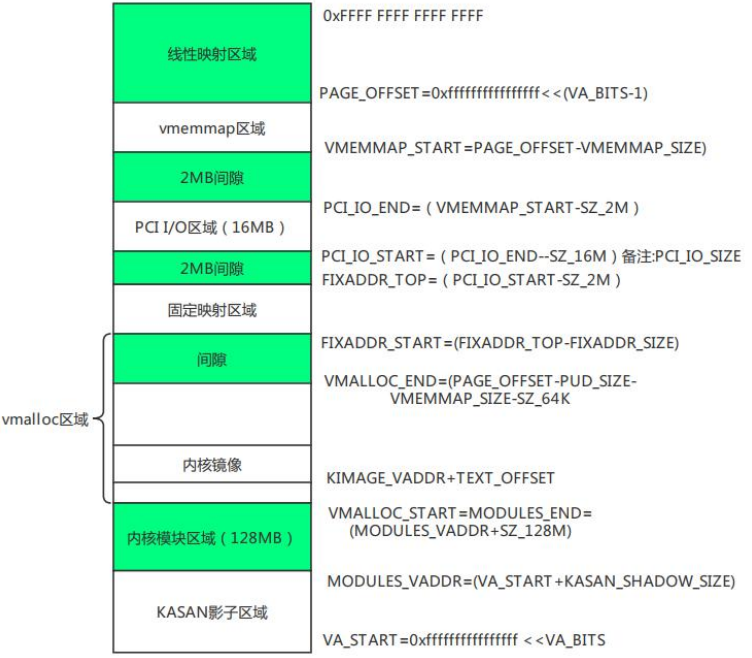
内存管理架构及虚拟地址空间布局_arm64位虚拟地址空间布局config_arm64_va_bits=39
赞
踩
主要参考了《深入linux内核》和《Linux内核深度解析》,简单浅析了一下相关内容
内存管理架构及虚拟地址空间布局
内存管理架构
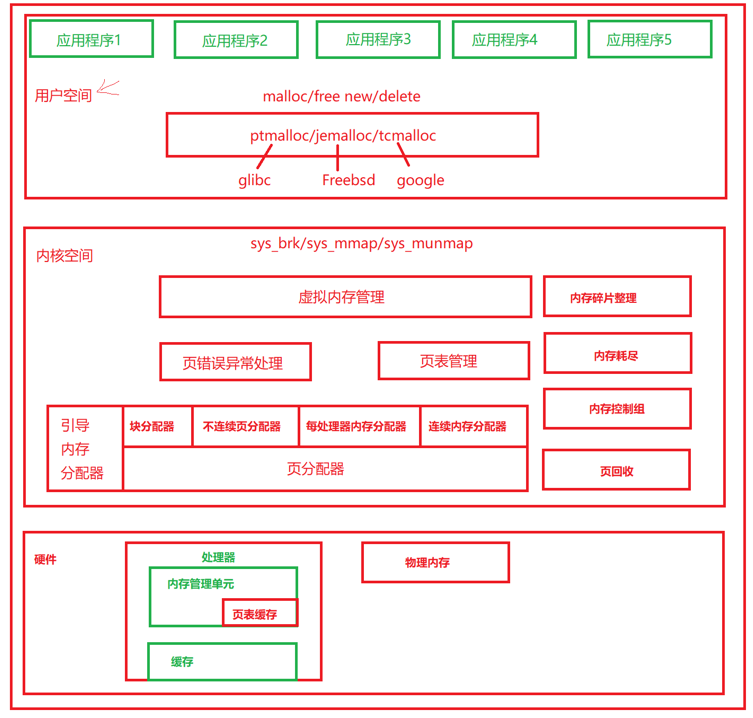
用户空间:
应用程序使用malloc()申请内存资源/free()释放内存资源。
malloc()和free()是glibc库的内存分配器ptmalloc提供的接口,ptmalloc使用系统调用brk或mmap向内核以页为单位申请内存,然后划分成小内存块
分配给应用程序。
用户空间的内存分配器,除了glibc库的ptmalloc,还有谷歌公司的tcmalloc和FreeBSD的jemalloc。
内核空间:
内核总是驻留在内存中,是操作系统的一部分。内核空间为内核保留,不允许应用程序读写该区域的内容或直接调用内核代码定义的函数。
- 虚拟内存管理负责从进程的虚拟地址空间分配虚拟页,sys_brk来扩大或收缩堆,sys_mmap用来在内存映射区域分配虚拟页,
sys_munmap用来释放虚拟页。 - 页分配器负责分配物理页,使用分配器是伙伴分配器。
内核使用延迟分配物理内存的策略,进程第一次访问虚拟页的时候,触发页错误异常,页错误异常处理程序从页分配器申请物理页,在进程的页表中把虚拟页映射到物理页。
-
内核空间提供了把页划分成小内存块分配的块分配器,提供分配内存的接口kmalloc()和释放内存的接口kfree(),支持3种块分配器:SLAB分配器、
SLUB分配器和SLOB分配器。 -
**内核空间扩展功能,不连续页分配器提供分配内存的接口vmalloc和释放内存接口vfree。**在内存碎片化的时候,申请连续物理页的成功
率比较低,可以申请不连续的物理页,映射到连续的虚拟页,即虚拟地址连续而物理地址不连续。 -
每处理器内存分配器用来为每处理器变量分配内存。
-
连续内存分配器(Contiguous Memory Allocator,CMA)用来给驱动程序预留一段连续的内存,当驱动程序不用的时候,可以给进程使用;当驱动
程序需要使用的时候,把进程占用的内存通过回收或迁移的方式让出来,给驱动程序使用。
内存控制组用来控制进程占用的内存资源。当内存碎片化的时候,找不到连续的物理页,内存碎片整理通过迁移方式得到连续的物理
页。
在内存不足的时候,页回收负责回收物理页,对于没有后备存储设备支持的匿名页,把数据换出到交换区,然后释放物理页;对于有后备存储设备支持
的文件页,把数据写回存储设备,然后释放物理页。如果页回收失败,使用最后一招:内存耗尽杀手(OOM killer,Out-of-Memory killer),选择
进程杀掉。
硬件
处理器包含一个内存管理单元(Memory Management Uint,MMU)的部件,负责把虚拟地址转换为物理地址。
MMU包含一个页表缓存(Translation Lookaside Buffer,TLB),保存最近使用过的页表映射,避免每次把虚拟地址转换为物理地址都需要查询内存中的页表。
为了解决处理器的执行速度和内存的访问速度不匹配的问题,在处理器和内存之间增加了缓存。缓存通常分为一级缓存和二级缓存,为了支持并行地取
指令和取数据,一级缓存分为数据缓存和指令缓存。
相关系统调用
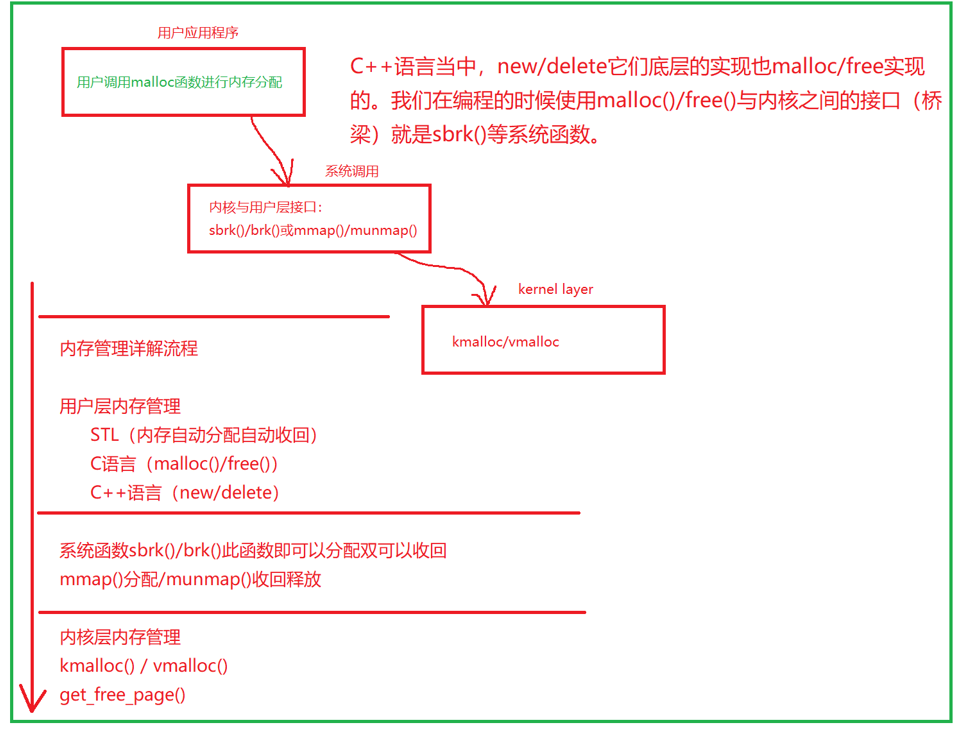
#include <stdio.h> #include <stdlib.h> #include <unistd.h> #define MAX 1024 int main(int argc, char *argv[]) { int *p = sbrk(0); int *old = p; p = sbrk(MAX * MAX); if (p == (void*)(-1)) { perror("sbrk error.\n"); exit(EXIT_FAILURE); } printf("old:%p\np=%p\n", p, old); int *new = sbrk(0); printf("new:%p\n", new); printf("\npid=%d\n", getpid()); sbrk(-MAX * MAX); while (1){} return 0; }

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
old:0x55ad459a1000
p=0x55ad459a1000
new:0x55ad45ac2000
参数 > 0 向后移动当前位置,相当分配内存空间
参数 < 0 向前移动当前位置,相当释放内存空间
参数 == 0 当前位置不动
>0 <0 ==0 返回总是移动前的位置
sbrk()函数,是C库在brk()基础上实现的一个库函数
pid=30384
下面第四行(heap)即为new的地址所示
cat /proc/30384/maps
虚拟地址空间布局架构
所有进程共享内核虚拟地址空间,每个进程有独立的用户虚拟地址空间,同一个线程组的用户线程共享用户虚拟地址空间,内核线程没有用户虚拟地址空间。
用户虚拟地址空间划分
进程的用户虚拟空间的起始地址是0,长度是TASK_SIZE,由每种处理器架构定义自己的宏TASK_SIZE。
ARM64架构定义的宏TASK_SIZE如下:
VA BITS是编译内核的时候选择的虚拟地址位数
- 32位用户空间程序:TASK_SIZE的值是TASK_SIZE_32,即0x100000000,4GB。
- 64位用户空间程序:TASK_SIZE的值是TASK_SIZE_64,即2 ^ (VA_BITS) 字节。
进程的用户虚拟地址空间包含区域:
- 代码段、数据段、未初始化数据段;
- 动态库的代码段、数据段和未初始化数据段;
- 存放动态生成的数据的堆;
- 存放局部变量和实现函数调用的栈;
- 把文件区间映射到虚拟地址空间的内存映射区域;
- 存放在栈底部的环境变量和参数字符串。
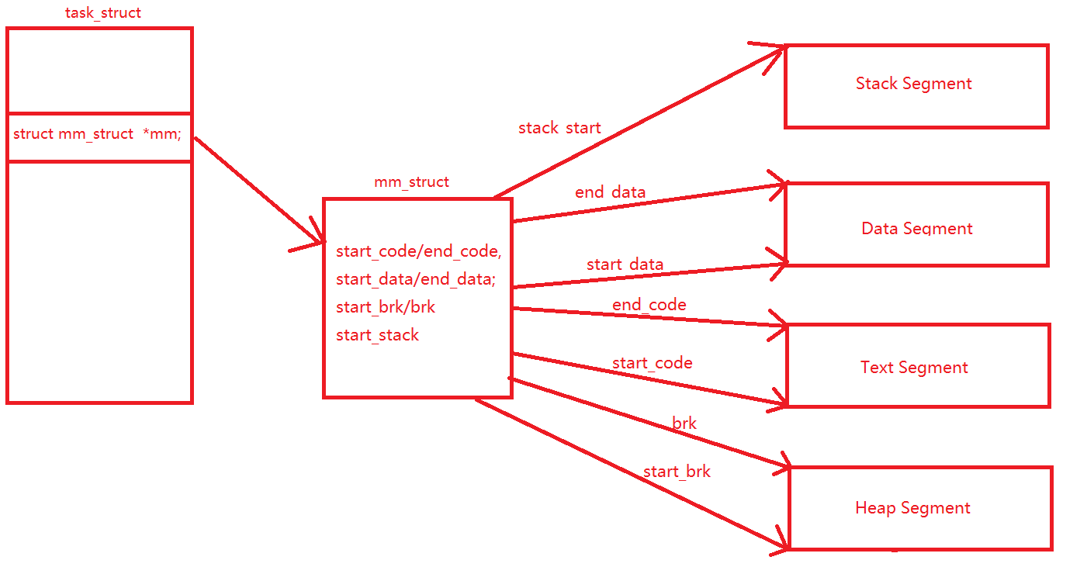
mm_struct
内核使用内存描述符mm_struct描述进程的用户虚拟地址空间
一个进程的虚拟地址空间主要由两个数据结构进行描述。一个是最高层次的mm_struct,较高层次的vm_area_struct。最高层次mm_struct结构描述一个进程整个虚拟地址空间。较高层次结构描述虚拟地址空间的一个区间(称为虚拟区)。
每个进程只有一个mm_struct结构,在每个进程的task_struct结构中,有一个专门用来指向该进程的结构。mm struct结构是对整个用户空间的描述。
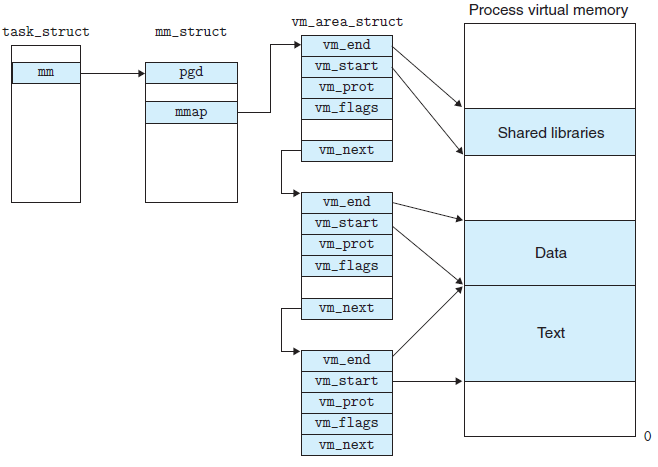
linux-4.4.4\include\linux\mm_types.h
struct mm_struct { struct vm_area_struct *mmap; // 虚拟内存区域链表 struct rb_root mm_rb; // 虚拟内存区域红黑树 u32 vmacache_seqnum; /* per-thread vmacache */ #ifdef CONFIG_MMU // 在内存映射区域找到一个没有映射的区域 unsigned long (*get_unmapped_area) (struct file *filp, unsigned long addr, unsigned long len, unsigned long pgoff, unsigned long flags); #endif unsigned long mmap_base; // 内存映射区域的起始地址 unsigned long mmap_legacy_base; /* base of mmap area in bottom-up allocations */ unsigned long task_size; // 用户虚拟地址空间的长度 unsigned long highest_vm_end; /* highest vma end address */ pgd_t * pgd; // 指向页全局目录,即第一级页表 // 共享一个用户虚拟地址空间的进程的数量,也就是线程组包含的进程的数量 atomic_t mm_users; /* How many users with user space? */ // 内存描述符的引用计数 atomic_t mm_count; /* How many references to "struct mm_struct" (users count as 1) */ atomic_long_t nr_ptes; /* PTE page table pages */ #if CONFIG_PGTABLE_LEVELS > 2 atomic_long_t nr_pmds; /* PMD page table pages */ #endif int map_count; /* number of VMAs */ spinlock_t page_table_lock; /* Protects page tables and some counters */ struct rw_semaphore mmap_sem; struct list_head mmlist; /* List of maybe swapped mm's. These are globally strung * together off init_mm.mmlist, and are protected * by mmlist_lock */ unsigned long hiwater_rss; // 进程所拥有的最大页框数 unsigned long hiwater_vm; // 进程线性区中最大页数 unsigned long total_vm; // 进程地址空间大小(页数) unsigned long locked_vm; // 锁住而不能换出页的个数 unsigned long pinned_vm; /* Refcount permanently increased */ unsigned long shared_vm; /* Shared pages (files) */ unsigned long exec_vm; /* VM_EXEC & ~VM_WRITE */ unsigned long stack_vm; /* VM_GROWSUP/DOWN */ unsigned long def_flags; // 代码段 的起始地址和结束地址,数据段的起始地址和结束地址 unsigned long start_code, end_code, start_data, end_data; // 堆的起始地址和结束地址,栈的起始地址 unsigned long start_brk, brk, start_stack; // 参数字符串的起始地址和结束地址,环境变量的起始地址和结束地址 unsigned long arg_start, arg_end, env_start, env_end; unsigned long saved_auxv[AT_VECTOR_SIZE]; /* for /proc/PID/auxv */ /* * Special counters, in some configurations protected by the * page_table_lock, in other configurations by being atomic. */ struct mm_rss_stat rss_stat; struct linux_binfmt *binfmt; cpumask_var_t cpu_vm_mask_var; /* Architecture-specific MM context */ mm_context_t context; // 处理器架构特定的内存管理上下文 ... };
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75

struct vm_area_struct { /* The first cache line has the info for VMA tree walking. */ // 这两个成员分别用来保存该虚拟内存空间的首地址和末地址后第一个字节的地址。 unsigned long vm_start; /* Our start address within vm_mm. */ unsigned long vm_end; /* The first byte after our end address within vm_mm. */ /* linked list of VM areas per task, sorted by address */ struct vm_area_struct *vm_next, *vm_prev; // 分别为VMA链表的前后成员连接操作 // 创建一棵红黑树,将VMA作为一个节点加入到红黑树中,加速搜索 struct rb_node vm_rb; /* * Largest free memory gap in bytes to the left of this VMA. * Either between this VMA and vma->vm_prev, or between one of the * VMAs below us in the VMA rbtree and its ->vm_prev. This helps * get_unmapped_area find a free area of the right size. */ unsigned long rb_subtree_gap; /* Second cache line starts here. */ struct mm_struct *vm_mm; // 指向内存描述符,即虚拟内存区域所属的用户地址空间 pgprot_t vm_page_prot; // 保护位 /* 标志位 */ unsigned long vm_flags; /* Flags, see mm.h. */ /* * For areas with an address space and backing store, * linkage into the address_space->i_mmap interval tree. */ struct { struct rb_node rb; unsigned long rb_subtree_last; } shared; /* * A file's MAP_PRIVATE vma can be in both i_mmap tree and anon_vma * list, after a COW of one of the file pages. A MAP_SHARED vma * can only be in the i_mmap tree. An anonymous MAP_PRIVATE, stack * or brk vma (with NULL file) can only be in an anon_vma list. */ struct list_head anon_vma_chain; /* Serialized by mmap_sem & * page_table_lock */ struct anon_vma *anon_vma; /* Serialized by page_table_lock */ /* Function pointers to deal with this struct. */ const struct vm_operations_struct *vm_ops; /* Information about our backing store: */ unsigned long vm_pgoff; /* Offset (within vm_file) in PAGE_SIZE units, *not* PAGE_CACHE_SIZE */ struct file * vm_file; /* File we map to (can be NULL). */ void * vm_private_data; /* was vm_pte (shared mem) */ #ifndef CONFIG_MMU struct vm_region *vm_region; /* NOMMU mapping region */ #endif #ifdef CONFIG_NUMA struct mempolicy *vm_policy; /* NUMA policy for the VMA */ #endif struct vm_userfaultfd_ctx vm_userfaultfd_ctx; };
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
用户虚拟地址空间布局
内存映射区域的起始地址是内存描述符的成员 mmap_base。如下图所示,用户虚拟地址空间有两种布局,区别是内存映射区域的起始位置和增长
方向不同。
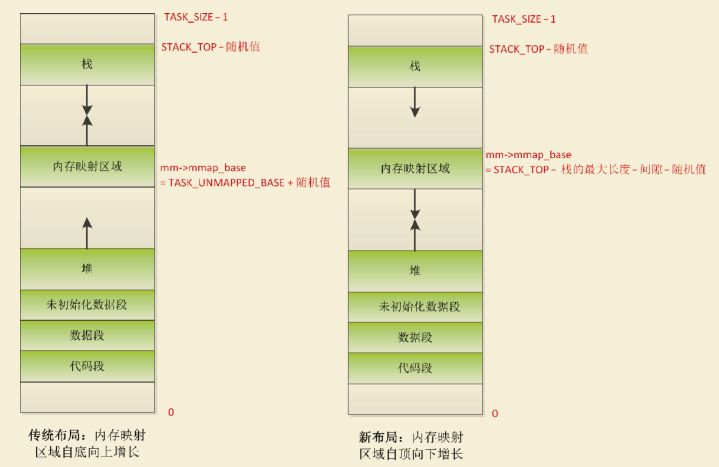
1)传统布局:内存映射区域自底向上增长,起始地址是TASK_UNMAPPED_BASE,每种处理器架构都要定义这个宏,ARM64架构
定义为 TASK_SIZE/4。默认启用内存映射区域随机化,需要把起始地址加上一个随机值。传统布局的缺点是堆的最大长度受到限制,在32位系统中影响
比较大,但是在64位系统中这不是问题。
2)新布局(虚拟地址空间不够用):内存映射区域自顶向下增长,起始地址是(STACK_TOP −栈的最大长度 − 间隙)。默认启用内存映射区域随机化,需要把起始地址减去一个随机值。
- 其想法在于使用固定值限制栈的最大长度。由于栈是有界的,因此安置内存映射的区域可以在栈末端的下方立即开始。与经典方法相反,该区域现在是自顶向下扩展。由于堆仍然位于虚拟地址空间中较低的区域并向上增长,因此mmap区域和堆可以相对扩展,直至耗尽虚拟地址空间中剩余的区域。
为确保栈与mmap区域不发生冲突,两者之间设置了一个安全隙。
当进程调用execve以装载ELF文件的时候,函数load_elf_binary将会创建进程的用户虚拟地址空间。函数load_elf_binary创建用户虚拟地址空间的过程如下图所示。
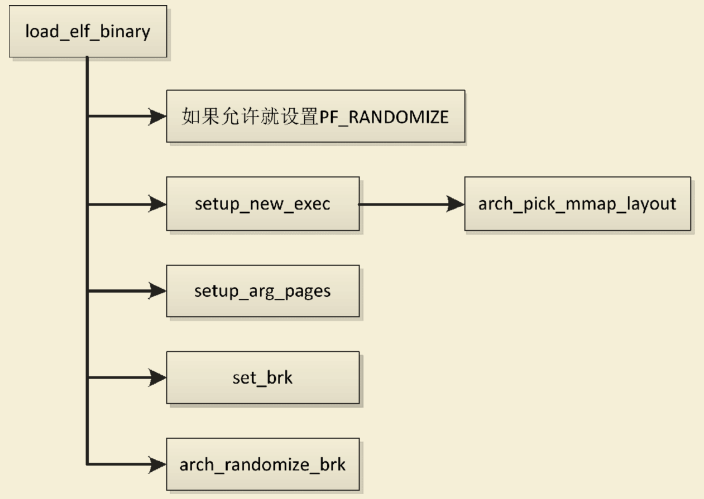
如果没有给进程描述符的成员personality设置标志位ADDR_NO_RANDOMIZE(该标志位表示禁止虚拟地址空间随机化),并且全局变量randomize_va_space是非零值,那么给进程设置标志PF_RANDOMIZE,允许虚拟地址空间随机化。
ARM64内核地址空间布局
KASAN:动态内存错误检查工具
ARM64处理器架构内核地址空间布局如下图所示: