
- 1uni-app开发日志[2022022701]:解决因异步原因导致子组件调用父组件中uni-form表单验证事件时发生的错误及uniform、promise、async、await的同步异步使用注意点_unhandled error during execution of onload
- 2GitHub App终于来了,iPhone用户可尝鲜,「同性交友」更加便捷
- 3鸿蒙开发|开启鸿蒙开发之旅-发工具下载安装、项目创建和预览
- 4Android Studio使用的那些事(三)AS不同版本安装注意点(最新版AS 3.2.1)_as各个版本
- 5ssh报错:no matching host key type found. Their offer: ssh-rsa
- 6Android Studio 知识汇总
- 7微信小程序开发笔记 基础篇①——微信小程序navigationBarTitleText导航栏标题设置
- 8win11 vmware没有vmnet0(桥接后无法上网)解决办法_虚拟网络编辑器中没有vmnet0
- 9TCP Out-Of-Window报文限速_tcp_invalid_ratelimit
- 10RuntimeError: CUDA error: out of memoryCUDA_runtimeerror: cuda error: out of memory cuda kerne
R语言SVM、决策树与因子分析对城市空气质量分类与影响因素可视化研究
赞
踩
全文链接:https://tecdat.cn/?p=35303
数据处理和分析在数据科学领域中扮演着至关重要的角色。确保数据的准确性和完整性是数据处理的首要任务。在本研究中,我们以空气质量数据为例,帮助客户进行了数据处理和分析(点击文末“阅读原文”获取完整代码数据)。
相关视频
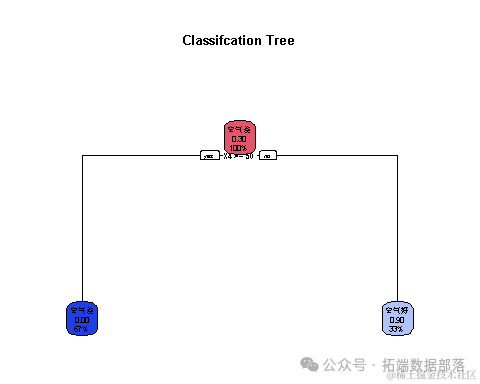
根据空气质量的指标(x1~x7),我们将30个城市分成两类,并使用Y1来评估分类的效果。为了便于分类,在本研究中,我们将使用决策树方法和支持向量机(SVM)方法来进行分类分析。这两种方法在机器学习领域被广泛应用,能够有效地处理分类问题,并提高模型的准确性和泛化能力。
读取数据
首先,我们使用R语言中的read.csv函数来导入名为"air.csv"的数据集,并通过skip参数跳过第一行进行读取。
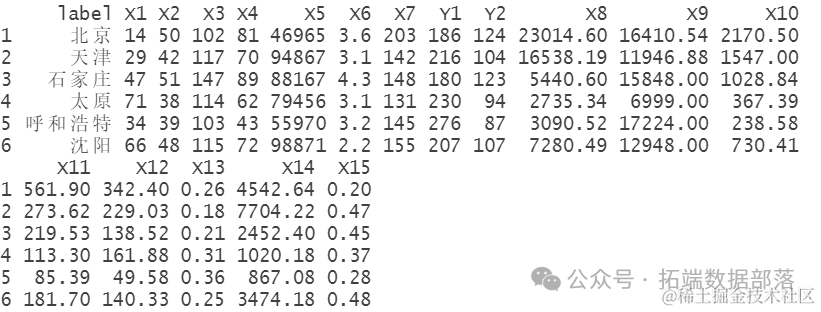
空气质量数据:

随后,使用head函数来查看数据的前几行,以初步了解数据的结构和内容。
- data=read.csv("air.csv",skip = 1)
- head(data)
第一部分:
数据处理 :我们将Y1的指标转化为0和1,分别表示该城市的空气质量好和差。这种分类方法有助于后续的分析和建模。
data$Y1<-ifelse(data$Y1>365*0.8,'空气好','空气差')构建因变量
data$Y1<-as.factor(data$Y1) ## 将因变量格式转为因子型构建训练集、测试集
在编程的过程中,我们需要确保每个步骤都得到充分的考虑和完善。从数据预处理、特征工程、数据可视化到建模、验证和优化,每个环节都至关重要,不能有任何遗漏。此外,构建训练集和测试集也是非常关键的一步。我们采用了分层抽样的方法,将数据集分为70%的训练集和30%的测试集。通过这种划分方式,我们可以在训练集上建立模型,并在测试集上验证模型的准确性和泛化能力,从而评估模型的有效性和可靠性。
- train<-data[trainindex, ] ## 去除price变量的训练集
- test<-data[-trainindex, ] ## 去除price变量的测试集
训练svm模型
一、使用线性核函数去拟合SVM模型
在训练SVM模型的过程中,我们首先使用线性核函数进行拟合。
1)模型拟合
- ,data=train,kernel='linear',
- cost=10,scale=F)
- #kernel='linear' ## 选择线性核函数
- #scale=F ## 对数据不进行标准化处理,支持向量机的的损失函数为凸函数,是否标准化不影响最优解,但标准化之后可以使求解速度变快
- #cost=10 ## 参数代表犯错的成本,越大模型对误差的惩罚越大,生成的分类边界越复杂
在上述代码中,我们使用svm函数拟合了一个SVM模型,其中指定了使用线性核函数(kernel='linear')进行分类。参数cost=10表示对误差的惩罚程度,这个值越大,模型对误差的惩罚越大,生成的分类边界也会更复杂。同时,我们选择不对数据进行标准化处理(scale=FALSE),因为SVM的损失函数是凸函数,标准化数据不会影响最优解,但可以加快求解速度。
summary ( svmfit1 ) 在上述代码中,我们使用summary函数对拟合的SVM模型进行了摘要。该摘要包含了模型的关键参数和性能指标,如下所示:
在上述代码中,我们使用summary函数对拟合的SVM模型进行了摘要。该摘要包含了模型的关键参数和性能指标,如下所示:
SVM-Type: C-classification
SVM-Kernel: linear
cost: 10
gamma: 0.02173913
Support Vectors数量: 8
从摘要中可以看出,我们拟合的SVM模型是一个C-classification类型的模型,使用了线性核函数,cost参数为10。此外,模型中有8个支持向量,这些支持向量在决定分类边界时起到关键作用。最后,模型中共有2个类别,分别为"空气差"和"空气好"。
2)对svmfit1模型进行改进,选择最优的cost值
在对已拟合的svmfit1模型进行改进时,我们选择了最优的cost值。以下是具体步骤和结果的解释:
- ranges =list(cost=c(0.001 ,
- 0.01, 0.1, 1,5,10,100) ))
- summary (tune.out )
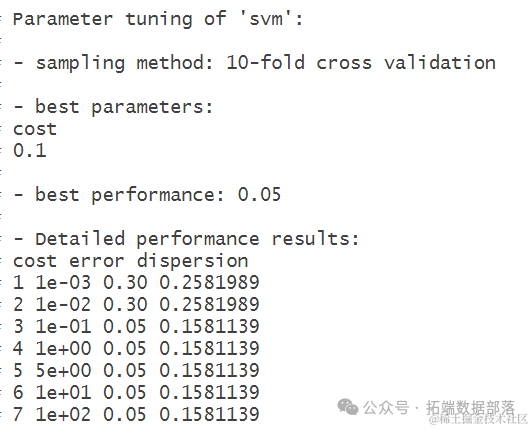
在上述代码中,我们使用tune函数对svm模型进行参数调优,通过10折交叉验证的方式选择最优的cost值。summary函数用于查看调优结果摘要,包括最佳参数和性能指标。
从上述结果中可以看出,经过参数调优后,最佳的cost值为0.1,对应的误差率为0.05。在调优过程中,我们对不同的cost值进行了评估,并选择了性能最优的参数值。
summary ( best.mode1 )
在最优模型摘要中,我们可以看到调优后的最佳模型参数为C-classification类型的线性SVM模型,使用线性核函数,cost参数为0.1。模型中共有11个支持向量,共包含2个类别:"空气差"和"空气好"。这些结果表明通过参数调优,我们成功选择了最优的cost值,优化了SVM模型的性能。
3)模型评估
在对模型进行评估的过程中,我们首先对SVM模型进行评估,然后训练决策树模型。
ypred<-predict(
在上述代码中,我们使用predict函数对训练好的SVM模型进行预测,得到了预测结果。这些结果可以与真实值进行对比,从而评估模型的性能。以上结果展示了SVM模型的预测情况,包括真实值和预测值的对比,可以进一步分析模型的准确性和性能。
训练决策树模型
接下来,我们训练决策树模型,以下是具体步骤和结果的解释:
- .-label-Y1,
- method="class", dat

在上述代码中,我们使用rpart函数训练了一个决策树模型,其中method="class"表示进行分类分析。模型使用了数据集中除了label和Y1以外的其他变量作为预测因子。通过plotcp函数可视化交叉验证结果,进一步评估模型的性能。以下是可视化结果:
plotcp(fit) # visualize cross-validation results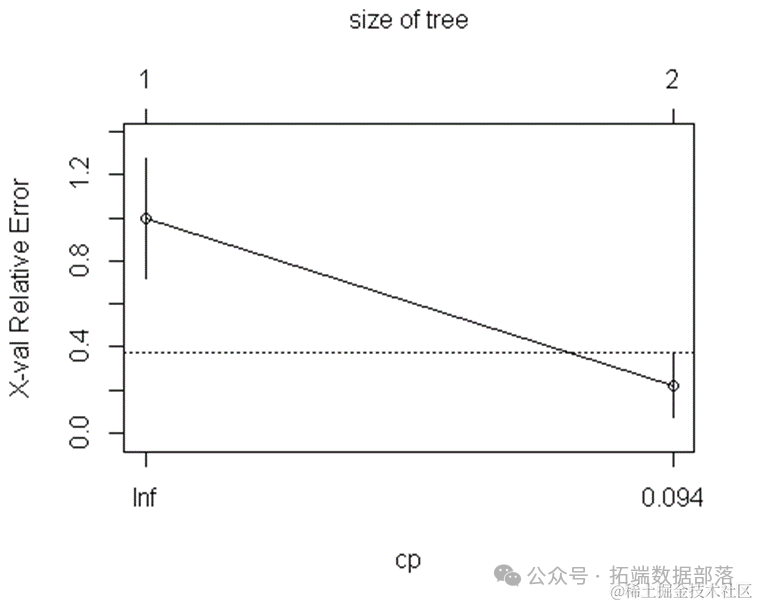
summary(fit) #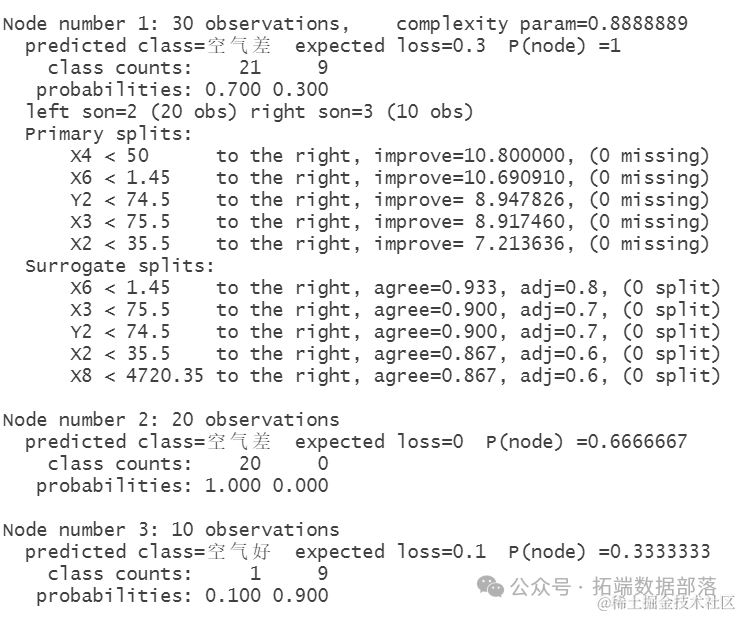 最后,利用summary函数对训练的决策树模型进行摘要,包括模型的性能指标、变量重要性以及节点信息。通过摘要结果,我们可以深入了解模型的构建过程和性能表现,为进一步的模型评估和优化提供参考。
最后,利用summary函数对训练的决策树模型进行摘要,包括模型的性能指标、变量重要性以及节点信息。通过摘要结果,我们可以深入了解模型的构建过程和性能表现,为进一步的模型评估和优化提供参考。
点击标题查阅往期内容

数据分享|R语言分析上海空气质量指数数据:kmean聚类、层次聚类、时间序列分析:arima模型、指数平滑法

左右滑动查看更多
01

02

03

04

第二部分:
根据第一部分的结果分成的两类城市来, 对第一类城市(空气好的城市):先根据城市发展指标(x8~x15)做因子分析,再将分出的因子和AQI值(y2)做对应分析,来分析它们的相关关系;
data1=data[data$Y1=="空气好",]对第一类城市(空气好的城市)进行因子分析和相关关系分析的步骤如下:
因子分析
画出协方差阵和相关系数矩阵
cov(data1[,-c(1,9:10)] )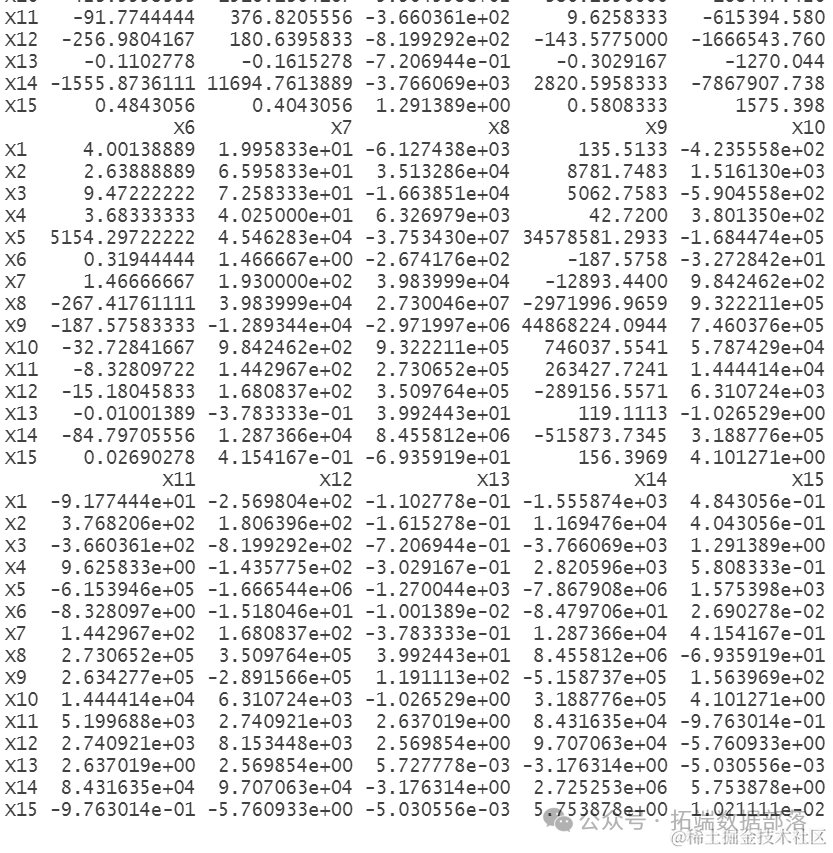
协方差阵展示了不同变量之间的协方差关系,可以帮助我们了解变量之间的线性关系。
cor(data1[,-c(1,9:10)] )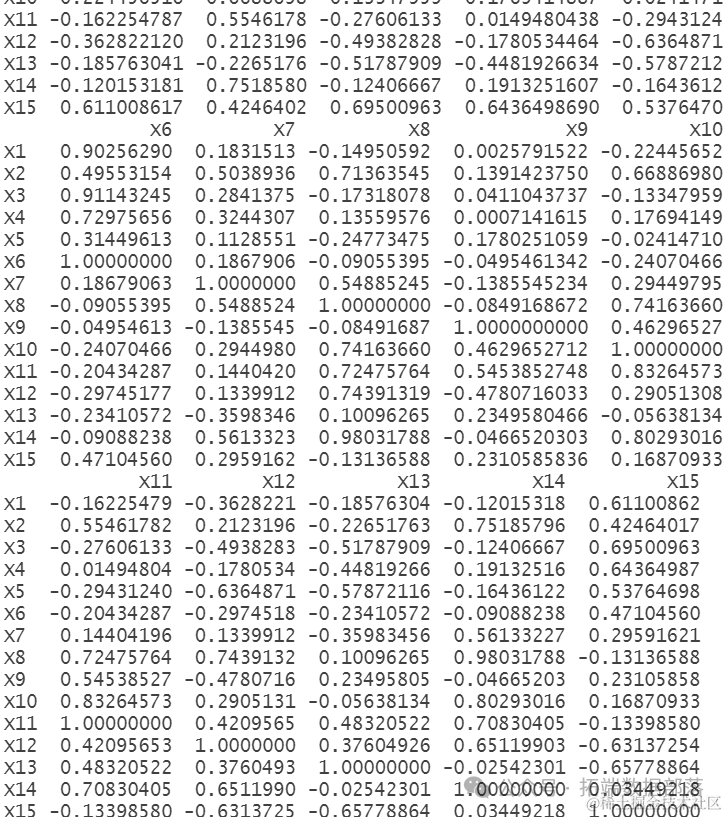
相关系数矩阵显示了各个变量之间的相关性程度,可以帮助我们理解变量之间的相关关系。
采用斜交旋转提取因子
- a1[ ,-c(1,9,10,11)]), nfactors=8, rotate=
- cor(data1$Y2 ,fm$scores)

在这一步中,我们采用斜交旋转提取因子的方法,将城市发展指标(x8~x15)进行因子分析,并提取8个因子。接着,我们将提取的因子与AQI值(Y2)进行对应分析,以探究它们之间的相关关系。
以上代码展示了AQI值(Y2)与提取的因子之间的相关系数,帮助我们分析城市发展指标与空气质量之间的关联关系。
对第二类城市(即空气质量较差的城市)的研究中,我们首先针对城市发展指标(x8~x15)进行了因子分析,以探究这些指标之间的潜在结构。随后,我们将因子分析得到的因子与空气质量指数(AQI值,即y2)进行了对应分析,以揭示它们之间的相关关系。
首先,我们从原始数据集中筛选出空气质量较差的城市数据
data1=data[data$Y1=="空气差",]因子分析
接着,我们对筛选出的城市发展指标(x8~x15)进行了因子分析。为了初步了解这些指标之间的关联性,我们计算了它们的协方差矩阵。协方差矩阵能够展示各指标之间的变异程度以及它们之间的线性相关程度。
- cov(data1[,-c(1,9:10)] )
-
-
-
- cor(data1[,-c(1,9:10)] )

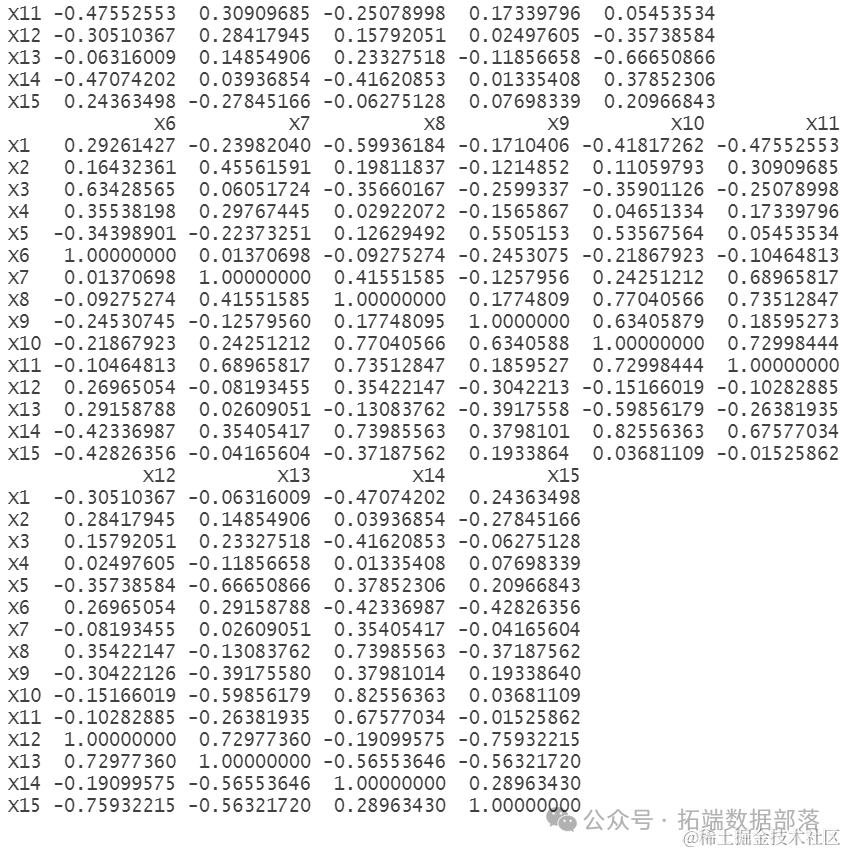
采用斜交旋转提取因子
对第二类城市(即空气质量较差的城市)进行深入研究时,我们首先采用因子分析方法来探究城市发展指标(x8~x15)之间的潜在结构。为了更清晰地解释因子并使其具有实际意义,我们使用了斜交旋转(特别是“varimax”旋转)来提取因子。这种方法有助于我们理解各个因子所代表的原始指标组合,以及这些因子在解释城市发展特征时的相对重要性。
在因子分析过程中,我们设定了提取8个因子的目标,这是因为我们希望找到能够代表原始指标中大部分信息的少数几个因子。通过斜交旋转,我们得到了旋转后的因子载荷矩阵,这有助于我们解释每个因子所代表的含义。
随后,为了探究这些因子与空气质量指数(AQI值,即y2)之间的相关关系,我们计算了因子得分与AQI值之间的相关系数。相关系数矩阵显示了每个因子与AQI值之间的线性相关程度。
- ctors=8, rotate="varimax
- cor(data1$Y2 ,fm$scores)

从相关系数矩阵中,我们可以看到MR5因子与AQI值之间存在较高的正相关关系(相关系数为0.8802801),这意味着该因子所代表的城市发展特征与空气质量较差有显著的正向关联。同时,MR6因子也与AQI值呈现出一定的正相关(相关系数为0.3007104),表明该因子同样与较差的空气质量有关。
其他因子与AQI值之间的相关系数虽然较低,但也可能存在某种关联。这些结果为我们提供了关于城市发展指标与空气质量之间关系的初步线索,有助于我们进一步理解和分析这些城市在发展过程中所面临的空气质量挑战。

本文中分析的数据分享到会员群,扫描下面二维码即可加群!

点击文末“阅读原文”
获取全文完整代码数据资料。
本文选自《R语言SVM、决策树与因子分析对城市空气质量分类与影响因素可视化研究》。


点击标题查阅往期内容
R语言分布滞后非线性模型(DLNM)空气污染研究温度对死亡率影响建模应用
Python中的ARIMA模型、SARIMA模型和SARIMAX模型对时间序列预测
Python用RNN神经网络:LSTM、GRU、回归和ARIMA对COVID19新冠疫情人数时间序列预测
数据分享|PYTHON用ARIMA ,ARIMAX预测商店商品销售需求时间序列数据
Python用RNN神经网络:LSTM、GRU、回归和ARIMA对COVID19新冠疫情人数时间序列预测
【视频】Python用LSTM长短期记忆神经网络对不稳定降雨量时间序列进行预测分析|数据分享
深度学习实现自编码器Autoencoder神经网络异常检测心电图ECG时间序列
Python中TensorFlow的长短期记忆神经网络(LSTM)、指数移动平均法预测股票市场和可视化
RNN循环神经网络 、LSTM长短期记忆网络实现时间序列长期利率预测
结合新冠疫情COVID-19股票价格预测:ARIMA,KNN和神经网络时间序列分析
深度学习:Keras使用神经网络进行简单文本分类分析新闻组数据
PYTHON用LSTM长短期记忆神经网络的参数优化方法预测时间序列洗发水销售数据
Python用Keras神经网络序列模型回归拟合预测、准确度检查和结果可视化
R语言深度学习卷积神经网络 (CNN)对 CIFAR 图像进行分类:训练与结果评估可视化
深度学习:Keras使用神经网络进行简单文本分类分析新闻组数据
Python用LSTM长短期记忆神经网络对不稳定降雨量时间序列进行预测分析
R语言深度学习Keras循环神经网络(RNN)模型预测多输出变量时间序列
R语言KERAS用RNN、双向RNNS递归神经网络、LSTM分析预测温度时间序列、 IMDB电影评分情感
Python用Keras神经网络序列模型回归拟合预测、准确度检查和结果可视化
Python用LSTM长短期记忆神经网络对不稳定降雨量时间序列进行预测分析
R语言中的神经网络预测时间序列:多层感知器(MLP)和极限学习机(ELM)数据分析报告
R语言深度学习:用keras神经网络回归模型预测时间序列数据
Matlab用深度学习长短期记忆(LSTM)神经网络对文本数据进行分类
R语言KERAS深度学习CNN卷积神经网络分类识别手写数字图像数据(MNIST)
Python中用PyTorch机器学习神经网络分类预测银行客户流失模型
SAS使用鸢尾花(iris)数据集训练人工神经网络(ANN)模型
【视频】R语言实现CNN(卷积神经网络)模型进行回归数据分析
R语言用神经网络改进Nelson-Siegel模型拟合收益率曲线分析
matlab使用长短期记忆(LSTM)神经网络对序列数据进行分类
使用PYTHON中KERAS的LSTM递归神经网络进行时间序列预测
python用于NLP的seq2seq模型实例:用Keras实现神经网络机器翻译
用于NLP的Python:使用Keras的多标签文本LSTM神经网络分类

![]()



