
- 1HarmonyOS SDK快问快答
- 2帮我用python做智能ai的对话机器人
- 3HarmonyOS router页面跳转_harmony router
- 4基于博弈树的五子棋 AI 算法及其 C++ 实现_c++五子棋 ai算法
- 5基于深度学习的MNIST手写数字数据集识别(准确率99%,附代码)_mnist数据集99正确率
- 6脑成像中的双胞胎设计——阿尔茨海默病生物标志物综述
- 7启明智显分享|基于ESP32-S3方案的4寸86盒开发板快速开发及烧录_esp32方案板
- 8专家倡议推迟顶会截稿日期!半数以上国内学者无法参会AAAI!_aaai 截稿延期
- 9Large Language Model主题的若干论文简述
- 10pytorch中的torch.hub.load():以vggish为例
Datawhale-深入浅出pytorch简介安装和基础知识_pytorch 的preview
赞
踩
目录
1.1 PyTorch简介
1.1.1 PyTorch的介绍
PyTorch是由Facebook人工智能研究小组开发的一种基于Lua编写的Torch库的Python实现的深度学习库,目前被广泛应用于学术界和工业界,而随着Caffe2项目并入Pytorch, Pytorch开始影响到TensorFlow在深度学习应用框架领域的地位。总的来说,PyTorch是当前难得的简洁优雅且高效快速的框架。因此本课程我们选择了PyTorch来进行开源学习。
1.1.2 PyTorch的发展
“All in Pytorch”,对于PyTorch的发展我们只能用一句话来概况了,PyTorch自从提出就获得巨大的关注以及用户数量的剧增
总的来说,我们必须承认到现在为止PyTorch还是有不如别的框架的地方,但是框架只是给我们提供了轮子,让我们造汽车更加方便,最重要的还是我们个人的科学素养的提升。
1.1.3 PyTorch的优势
- 更加简洁,相比于其他的框架,PyTorch的框架更加简洁,易于理解。PyTorch的设计追求最少的封装,避免重复造轮子。
- 上手快,掌握numpy和基本的深度学习知识就可以上手。
- PyTorch有着良好的文档和社区支持,作者亲自维护的论坛供用户交流和求教问题。Facebook 人工智能研究院对PyTorch提供了强力支持,作为当今排名前三的深度学习研究机构,FAIR的支持足以确保PyTorch获得持续的开发更新。
- 项目开源,在Github上有越来越多的开源代码是使用PyTorch进行开发。
- 可以更好的调试代码,PyTorch可以让我们逐行执行我们的脚本。这就像调试NumPy一样 – 我们可以轻松访问代码中的所有对象,并且可以使用打印语句(或其他标准的Python调试)来查看方法失败的位置。
- 越来越完善的扩展库,活力旺盛,正处在当打之年。
1.2 PyTorch的安装
PyTorch的安装,一般常见的是Anaconda/miniconda+Pytorch+ (Pycharm) 的工具,我们的安装分为以下几步
- Anaconda的安装
- 检查有无NVIDIA GPU
- PyTorch的安装
- Pycharm的安装 ( Windows系统上更为常用)
1.2.1 Anaconda的安装
在DL和ML中,要用到大量成熟的package。一个个安装 package 很麻烦,而且容易出现奇奇怪怪的问题。而 Anaconda很好的解决了我们的问题,它集成了常用于科学分析(机器学习, 深度学习)的大量package。省略了我们安装一些package的过程。
Step 1:安装Anaconda/miniconda
登陆Anaconda | Individual Edition,选择相应系统DownLoad,此处以Windows为例:
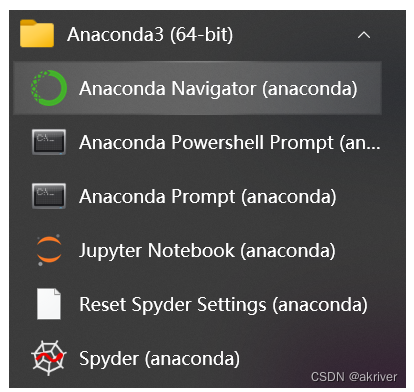
Step 2:检验是否安装成功
在开始页找到Anaconda Prompt,一般在Anaconda3的文件夹下,( Linux在终端下就行了)
Step 3:创建虚拟环境
Linux在终端(Ctrl+Alt+T)进行,Windows在Anaconda Prompt进行
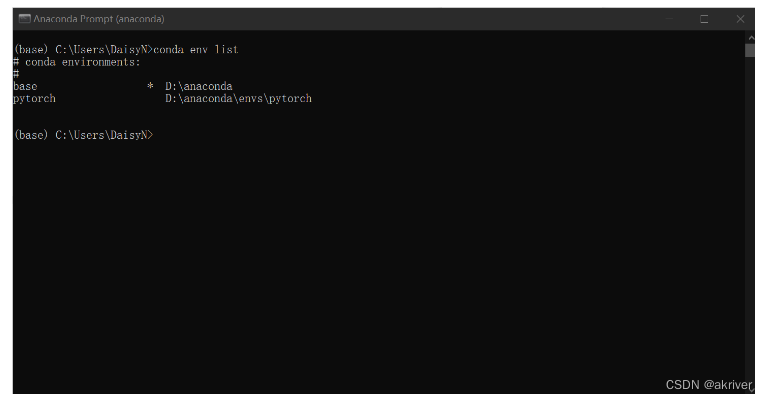
查看现存虚拟环境
查看已经安装好的虚拟环境,可以看到我们这里已经有两个环境存在了
conda env list
创建虚拟环境
在深度学习和机器学习中,我们经常会创建不同版本的虚拟环境来满足我们的一些需求。下面我们介绍创建虚拟环境的命令。
conda create -n env_name python==version
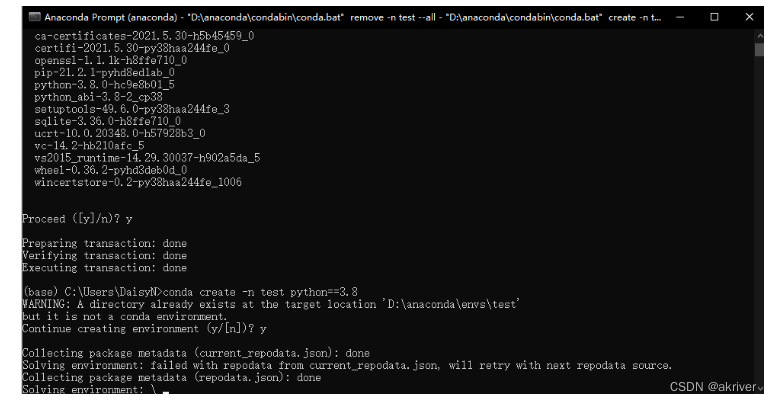
注:
- 这里忽略我们的warning,因为我们测试的时候已经安了又卸载一遍了,正常时是不会有warning的。
- 在选择Python版本时,不要选择太高,建议选择3.6-3.8,版本过高会导致相关库不适配。
删除虚拟环境命令
conda remove -n env_name --all
激活环境命令
conda activate env_name
退出当前环境
conda deactivate
Step 4:换源
在安装package时,我们经常会使用pip install package_name和conda install package_name 的命令,但是一些package下载速度会很慢,因此我们需要进行换源,换成国内源,加快我们的下载速度。以下便是两种对应方式的换源
pip换源
Linux:
Linux下的换源,我们首先需要在用户目录下新建文件夹.pip,并且在文件夹内新建文件pip.conf,具体命令如下
cd~
mkdir .pip/
vi pip.conf
随后,我们需要在pip.conf添加下方的内容:
[global]index-url =Simple Index
[install]use-mirrors =truemirrors=http://pypi.douban.com/simple/
trusted-host =pypi.douban.com
Windows:
1、文件管理器文件路径地址栏敲:%APPDATA% 回车,快速进入 C:\Users\电脑用户\AppData\Roaming 文件夹中 2、新建 pip 文件夹并在文件夹中新建 pip.ini 配置文件 3、我们需要在pip.ini 配置文件内容,我们可以选择使用记事本打开,输入以下内容,并按下ctrl+s保存,在这里我们使用的是豆瓣源为例子。
[global]index-url =Simple Index
[install]use-mirrors =truemirrors=http://pypi.douban.com/simple/
trusted-host =pypi.douban.com
conda换源(清华源)官方换源帮助
Windows系统:
TUNA 提供了 Anaconda 仓库与第三方源的镜像,各系统都可以通过修改用户目录下的 .condarc 文件。Windows 用户无法直接创建名为 .condarc 的文件,可先执行conda config --set show_channel_urls yes生成该文件之后再修改。
完成这一步后,我们需要修改C:\Users\User_name\.condarc这个文件,打开后将文件里原始内容删除,将下面的内容复制进去并保存。
channels:
- defaults
show_channel_urls: truedefault_channels:
- Index of /anaconda/pkgs/main/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
- Index of /anaconda/pkgs/r/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
- Index of /anaconda/pkgs/msys2/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
custom_channels:
conda-forge: Index of /anaconda/cloud/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
msys2: Index of /anaconda/cloud/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
bioconda: Index of /anaconda/cloud/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
menpo: Index of /anaconda/cloud/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
pytorch: Index of /anaconda/cloud/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
simpleitk: Index of /anaconda/cloud/ | 清华大学开源软件镜像站 | Tsinghua Open Source Mirror
这一步完成后,我们需要打开Anaconda Prompt 运行 conda clean -i 清除索引缓存,保证用的是镜像站提供的索引。
Linux系统:
在Linux系统下,我们还是需要修改.condarc来进行换源
cd~
vi .condarc
在vim下,我们需要输入i进入编辑模式,将上方内容粘贴进去,按ESC退出编辑模式,输入:wq保存并退出
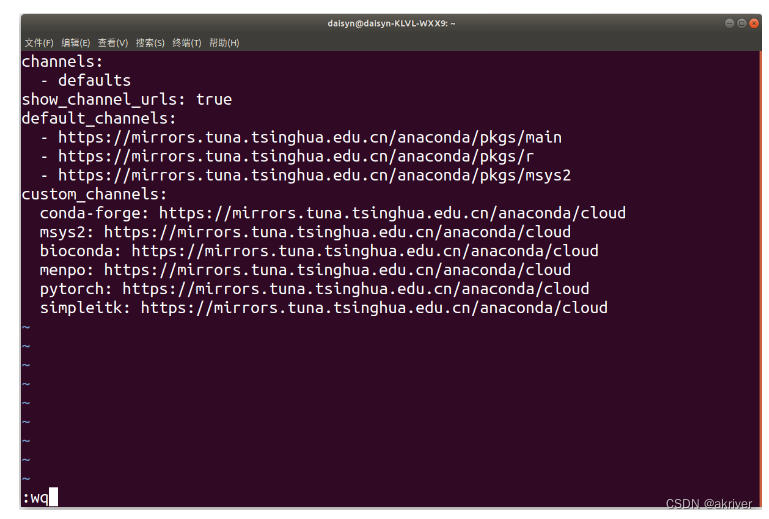
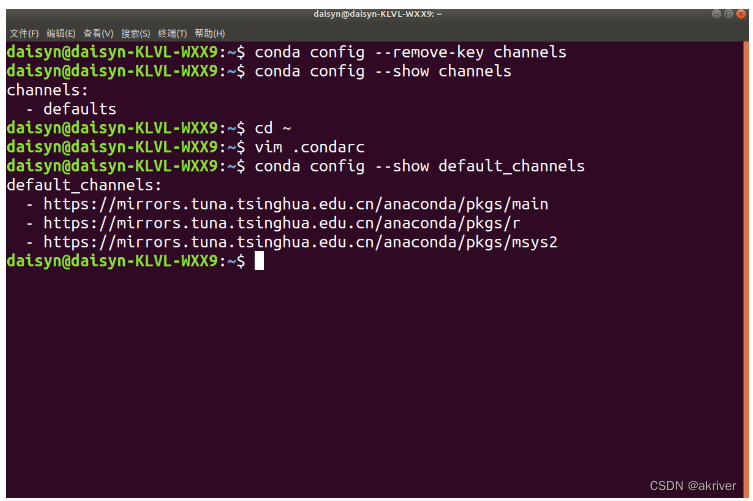
我们可以通过conda config --show default_channels检查下是否换源成功,如果出现下图内容,即代表我们换源成功。
同时,我们仍然需要conda clean -i 清除索引缓存,保证用的是镜像站提供的索引。
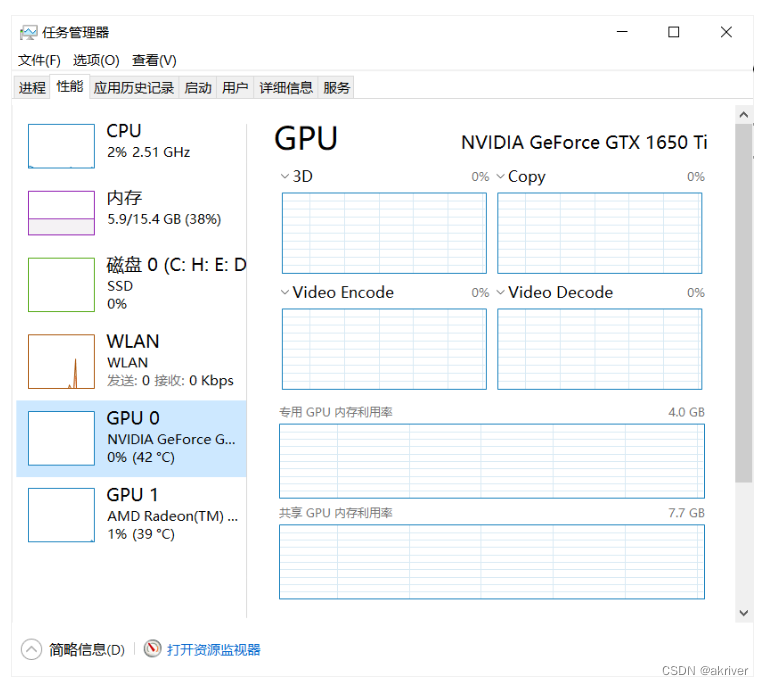
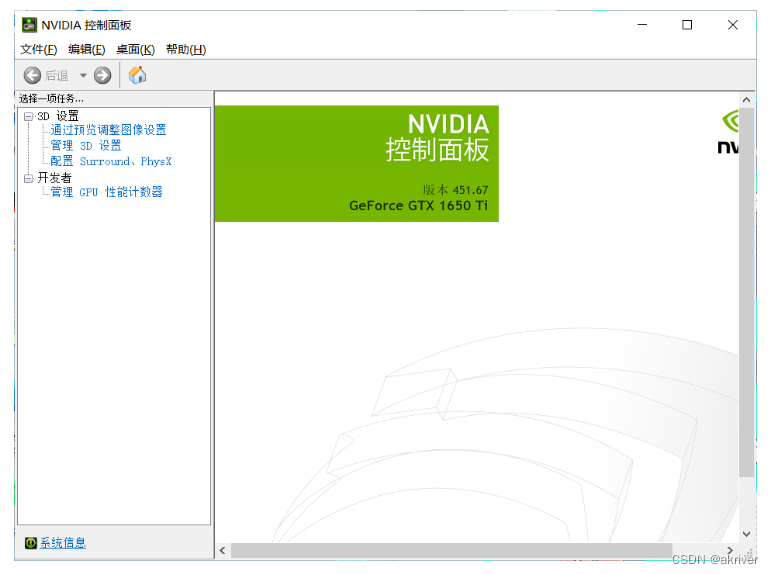
1.2.2 查看显卡
该部分如果仅仅只有CPU或者集显的小伙伴们可以跳过该部分
windows:
我们可以通过在cmd/terminal中输入nvidia-smi(Linux和Win命令一样)、使用NVIDIA控制面板和使用任务管理器查看自己是否有NVIDIA的独立显卡及其型号
linux:
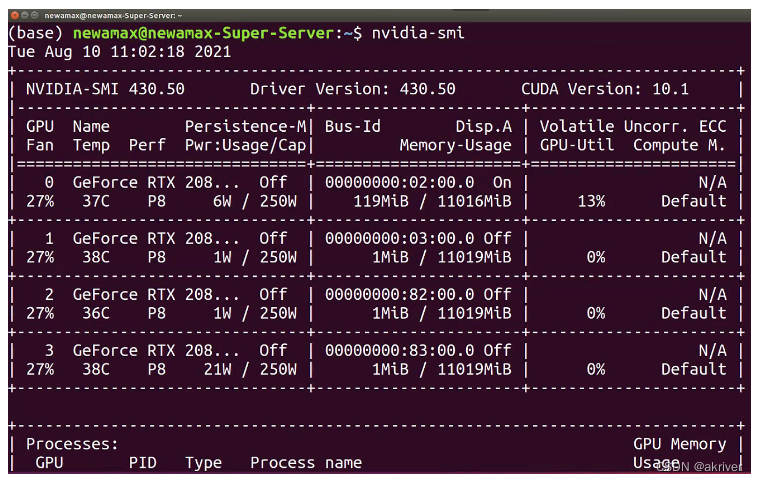
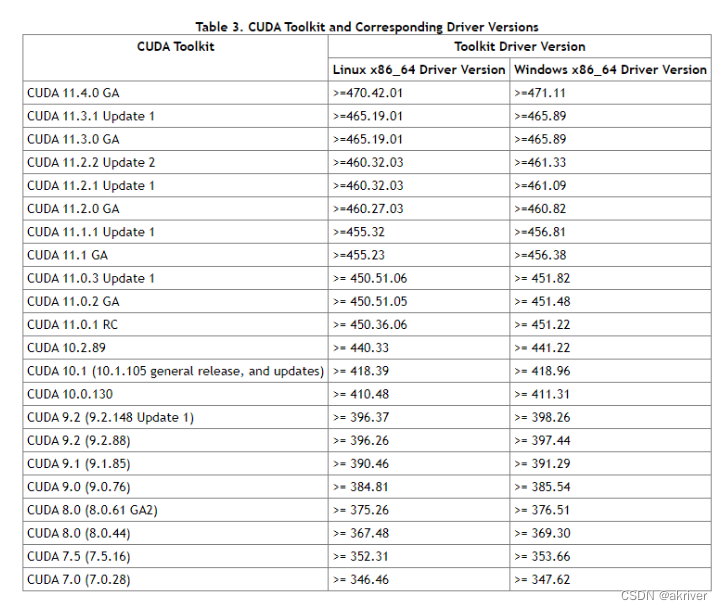
我们需要看下版本号,看自己可以兼容的CUDA版本,等会安装PyTorch时是可以向下兼容的。具体适配表如下图所示。
1.2.3 安装PyTorch
Step 1:登录PyTorch官网
Step 2:Install
这个界面我们可以选择本地开始(Start Locally),云开发(Cloud Partners),以前的Pytorch版本(Previous PyTorch Versions),移动端开发(Mobile),在此处我们需要进行本地安装。
Step 3:选择命令
我们需要结合自己情况选择命令并复制下来,然后使用conda下载或者pip下载(建议conda安装)
打开Terminal,输入conda activate env_name,激活环境并切换到环境下面,我们就可以进行PyTorch的安装了。

注:
- Stable代表的是稳定版本,Preview代表的是先行版本
- 可以结合电脑是否有显卡,选择CPU版本还是CUDA版本,建议还是需要NVIDIA GPU
- 官方建议我们使用Anaconda来进行管理
- 关于安装的系统要求
- Windows:
- Windows 7及更高版本;建议使用Windows 10或者更高的版本
- Windows Server 2008 r2 及更高版本
- Linux:以常见的CentOS和Ubuntu为例
- CentOS, 最低版本7.3-1611
- Ubuntu, 最低版本 13.04,这里会导致cuda安装的最大版本不同
- macOS:
- macOS 10.10及其以上
- Windows:
- 有些电脑所支持的cuda版本<10.2,此时我们需要进行手动降级,即就是cudatoolkit = 你所适合的版本,但是这里需要注意下一定要保持Pytorch和cudatoolkit的版本适配。查看Previous PyTorch Versions | PyTorch
Step 4:在线下载
如果我们使用的Anaconda Prompt进行下载的话,我们需要先通过conda activate env_name,激活我们的虚拟环境中去,再输入命令。
注: 我们需要要把下载指令后面的 -c pytorch 去掉以保证使用清华源下载,否则还是默认从官网下载。
Step 5:离线下载
Windows:
在安装的过程中,我们可能会出现一些奇奇怪怪的问题,导致在线下载不成功,我们也可以使用离线下载的方法进行。
下载地址:https://mirrors.tuna.tsinghua.edu.cn/anaconda/cloud/pytorch/
通过上面下载地址,我们需要下载好对应版本的pytorch和 torchvision 包,然后打开Anaconda Prompt/Terminal中,进入我们安装的路径下。
cdpackage_location
conda activate env_name
接下来输入以下命令安装两个包
conda install --offline pytorch压缩包的全称(后缀都不能忘记)
conda install --offline torchvision压缩包的全称(后缀都不能忘记)
Step 6:检验是否安装成功
进入所在的虚拟环境,紧接着输入python,在输入下面的代码。
importtorchtorch.cuda.is_available()
False
这条命令意思是检验是否可以调用cuda,如果我们安装的是CPU版本的话会返回False,能够调用GPU的会返回True。一般这个命令不报错的话就证明安装成功。
- Windows系统

- Linux系统

PyTorch的安装绝对是一个容易上火的过程,而且网络上的教程很可能对应早期的版本,或是会出现一些奇奇怪怪的问题,但是别担心,多装几次多遇到点奇奇怪怪的问题就好了,加油!
1.2.4 PyCharm安装(可选操作)
VSCode这些也是ok的,安装PyCharm非必须操作
Linux,Windows此处操作相同,我们建议Windows的同学安装Pycharm即可,因为在Linux上pycharm并不是主流的IDE。
Step 1:进入官网下载
如果是学生的话可以使用学生邮箱注册并下载Professional版本,Community版本也基本能满足我们的日常需求。
Step 2:配置环境
我们需要将虚拟环境设为我们的编译器,具体操作:File --> Settings --> Project:你的项目名称--> Python Interpreter
进去后,我们可以看见他使用的是默认的base环境,现在我们需要将这个环境设置成我们的test环境,点击齿轮,选择Add

点击Conda Environment ,选择Existing environment,将Interpreter设置为test环境下的python.exe
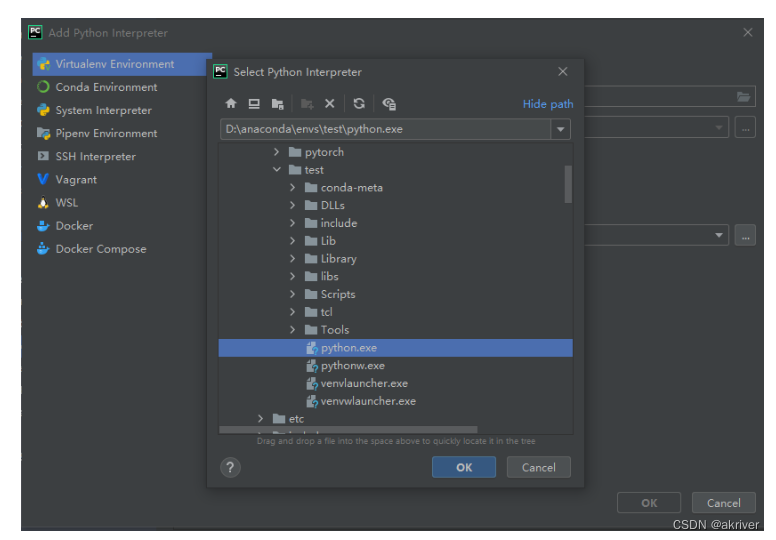
注:如果在pycharm的环境时,想进入我们的虚拟环境,要使用conda activate 名称
1.3 PyTorch相关资源
PyTorch之所以被越来越多的人使用,不仅在于其完备的教程,还受益于许多相关的资源,在这里,我们列举了相关的优质资源希望能帮助到各位同学。
- Awesome-pytorch-list:目前已获12K Star,包含了NLP,CV,常见库,论文实现以及Pytorch的其他项目。
- PyTorch官方文档:官方发布的文档,十分丰富。
- Pytorch-handbook:GitHub上已经收获14.8K,pytorch手中书。
- PyTorch官方社区:在这里你可以和开发pytorch的人们进行交流。
除此之外,还有很多学习pytorch的资源,b站,stackoverflow,知乎......未来大家还需要多多探索哦。
2.1 张量
本章我们开始介绍PyTorch基础知识,我们从张量说起,建立起对数据的描述,再介绍张量的运算,最后再讲PyTorch中所有神经网络的核心包 autograd ,也就是自动微分,了解完这些内容我们就可以较好地理解PyTorch代码了。
2.1.1 简介
几何代数中定义的张量是基于向量和矩阵的推广,比如我们可以将标量视为零阶张量,矢量可以视为一阶张量,矩阵就是二阶张量。
张量是现代机器学习的基础。它的核心是一个数据容器,多数情况下,它包含数字,有时候它也包含字符串,但这种情况比较少。因此可以把它想象成一个数字的水桶。

- Tensor可以是高维的
- 并非是PyTorch中才有的概念
- PyTorch运算的基本单元
- 基础数据定义和运算
- 在Pytorch中支持GPU运算,自动求导等操作
这里有一些存储在各种类型张量的公用数据集类型:
例子:一个图像可以用三个字段表示:
(width, height, channel) = 3D
但是,在机器学习工作中,我们经常要处理不止一张图片或一篇文档——我们要处理一个集合。我们可能有10,000张郁金香的图片,这意味着,我们将用到4D张量:
(sample_size, width, height, channel) = 4D
在PyTorch中, torch.Tensor 是存储和变换数据的主要工具。如果你之前用过NumPy,你会发现 Tensor 和NumPy的多维数组非常类似。然而,Tensor 提供GPU计算和自动求梯度等更多功能,这些使 Tensor 这一数据类型更加适合深度学习。
2.1.2 创建tensor
在接下来的内容中,我们将介绍几种创建tensor的方法。
我们可以通过torch.rand()的方法,构造一个随机初始化的矩阵:
import torch
x = torch.rand(4, 3)
print(x)
tensor([[0.7569, 0.4281, 0.4722],
[0.9513, 0.5168, 0.1659],
[0.4493, 0.2846, 0.4363],
[0.5043, 0.9637, 0.1469]])
我们可以通过torch.zeros()构造一个矩阵全为 0,并且通过dtype设置数据类型为 long。
import torch
x = torch.zeros(4, 3, dtype=torch.long)
print(x)
tensor([[0, 0, 0],
[0, 0, 0],
[0, 0, 0],
[0, 0, 0]])
我们可以通过torch.tensor()直接使用数据,构造一个张量:
import torch
x = torch.tensor([5.5, 3])
print(x)
tensor([5.5000, 3.0000])
基于已经存在的 tensor,创建一个 tensor :
x = x.new_ones(4, 3, dtype=torch.double) # 创建一个新的tensor,返回的tensor默认具有相同的 torch.dtype和torch.device
# 也可以像之前的写法 x = torch.ones(4, 3, dtype=torch.double)
print(x)
x = torch.randn_like(x, dtype=torch.float)
# 重置数据类型
print(x)
# 结果会有一样的size
# 获取它的维度信息
print(x.size())
print(x.shape)
tensor([[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.],
[1., 1., 1.]], dtype=torch.float64)
tensor([[ 2.7311, -0.0720, 0.2497],
[-2.3141, 0.0666, -0.5934],
[ 1.5253, 1.0336, 1.3859],
[ 1.3806, -0.6965, -1.2255]])
torch.Size([4, 3])
torch.Size([4, 3])
返回的torch.Size其实是一个tuple,⽀持所有tuple的操作。
还有一些常见的构造Tensor的函数:
| 函数 | 功能 |
| Tensor(sizes) | 基础构造函数 |
| tensor(data) | 类似于np.array |
| ones(sizes) | 全1 |
| zeros(sizes) | 全0 |
| eye(sizes) | 对角为1,其余为0 |
| arange(s,e,step) | 从s到e,步长为step |
| linspace(s,e,steps) | 从s到e,均匀分成step份 |
| rand/randn(sizes) | rand是[0,1)均匀分布;randn是服从N(0,1)的正态分布 |
| normal(mean,std) | 正态分布(均值为mean,标准差是std) |
| randperm(m) | 随机排列 |
2.1.3 张量的操作
在接下来的内容中,我们将介绍几种常见的张量的操作方法:
-
加法操作:
import torch
# 方式1
y = torch.rand(4, 3)
print(x + y)
# 方式2
print(torch.add(x, y))
# 方式3 提供一个输出 tensor 作为参数
# 这里的 out 不需要和真实的运算结果保持维数一致,但是会有警告提示!
result = torch.empty(5, 3)
torch.add(x, y, out=result)
print(result)
# 方式4 in-place
y.add_(x)
print(y)
tensor([[ 2.8977, 0.6581, 0.5856],
[-1.3604, 0.1656, -0.0823],
[ 2.1387, 1.7959, 1.5275],
[ 2.2427, -0.3100, -0.4826]])
tensor([[ 2.8977, 0.6581, 0.5856],
[-1.3604, 0.1656, -0.0823],
[ 2.1387, 1.7959, 1.5275],
[ 2.2427, -0.3100, -0.4826]])
tensor([[ 2.8977, 0.6581, 0.5856],
[-1.3604, 0.1656, -0.0823],
[ 2.1387, 1.7959, 1.5275],
[ 2.2427, -0.3100, -0.4826]])
tensor([[ 2.8977, 0.6581, 0.5856],
[-1.3604, 0.1656, -0.0823],
[ 2.1387, 1.7959, 1.5275],
[ 2.2427, -0.3100, -0.4826]])
-
索引操作:(类似于numpy)
需要注意的是:索引出来的结果与原数据共享内存,修改一个,另一个会跟着修改。如果不想修改,可以考虑使用copy()等方法
# 取第二列
print(x[:, 1])
tensor([-0.0720, 0.0666, 1.0336, -0.6965])
y = x[0,:]
y += 1
print(y)
print(x[0, :]) # 源tensor也被改了了
tensor([3.7311, 0.9280, 1.2497])
tensor([3.7311, 0.9280, 1.2497])
改变大小:如果你想改变一个 tensor 的大小或者形状,你可以使用 torch.view:
x = torch.randn(4, 4)
y = x.view(16)
z = x.view(-1, 8) # -1是指这一维的维数由其他维度决定
print(x.size(), y.size(), z.size())
torch.Size([4, 4]) torch.Size([16]) torch.Size([2, 8])
注意 view() 返回的新tensor与源tensor共享内存(其实是同一个tensor),也即更改其中的一个,另 外一个也会跟着改变。(顾名思义,view仅仅是改变了对这个张量的观察⻆度)
x += 1
print(x)
print(y) # 也加了1
tensor([[ 1.3019, 0.3762, 1.2397, 1.3998],
[ 0.6891, 1.3651, 1.1891, -0.6744],
[ 0.3490, 1.8377, 1.6456, 0.8403],
[-0.8259, 2.5454, 1.2474, 0.7884]])
tensor([ 1.3019, 0.3762, 1.2397, 1.3998, 0.6891, 1.3651, 1.1891, -0.6744,
0.3490, 1.8377, 1.6456, 0.8403, -0.8259, 2.5454, 1.2474, 0.7884])
所以如果我们想返回一个真正新的副本(即不共享内存)该怎么办呢?Pytorch还提供了一 个 reshape() 可以改变形状,但是此函数并不能保证返回的是其拷贝,所以不推荐使用。推荐先用 clone 创造一个副本然后再使用 view 。
注意:使用 clone 还有一个好处是会被记录在计算图中,即梯度回传到副本时也会传到源 Tensor
如果你有一个元素 tensor ,使用 .item() 来获得这个 value:
import torch
x = torch.randn(1)
print(type(x))
print(type(x.item()))
<class 'torch.Tensor'>
<class 'float'>
2.1.4 广播机制
当对两个形状不同的 Tensor 按元素运算时,可能会触发广播(broadcasting)机制:先适当复制元素使这两个 Tensor 形状相同后再按元素运算。
x = torch.arange(1, 3).view(1, 2)
print(x)
y = torch.arange(1, 4).view(3, 1)
print(y)
print(x + y)
tensor([[1, 2]])
tensor([[1],
[2],
[3]])
tensor([[2, 3],
[3, 4],
[4, 5]])
由于 x 和 y 分别是1行2列和3行1列的矩阵,如果要计算 x + y ,那么 x 中第一行的2个元素被广播 (复制)到了第二行和第三行,⽽ y 中第⼀列的3个元素被广播(复制)到了第二列。如此,就可以对2 个3行2列的矩阵按元素相加。
2.2 自动求导
PyTorch 中,所有神经网络的核心是 autograd 包。autograd包为张量上的所有操作提供了自动求导机制。它是一个在运行时定义 ( define-by-run )的框架,这意味着反向传播是根据代码如何运行来决定的,并且每次迭代可以是不同的。
torch.Tensor 是这个包的核心类。如果设置它的属性 .requires_grad 为 True,那么它将会追踪对于该张量的所有操作。当完成计算后可以通过调用 .backward(),来自动计算所有的梯度。这个张量的所有梯度将会自动累加到.grad属性。
注意:在 y.backward() 时,如果 y 是标量,则不需要为 backward() 传入任何参数;否则,需要传入一个与 y 同形的Tensor。
要阻止一个张量被跟踪历史,可以调用.detach()方法将其与计算历史分离,并阻止它未来的计算记录被跟踪。为了防止跟踪历史记录(和使用内存),可以将代码块包装在 with torch.no_grad(): 中。在评估模型时特别有用,因为模型可能具有 requires_grad = True 的可训练的参数,但是我们不需要在此过程中对他们进行梯度计算。
还有一个类对于autograd的实现非常重要:Function。Tensor 和 Function 互相连接生成了一个无环图 (acyclic graph),它编码了完整的计算历史。每个张量都有一个.grad_fn属性,该属性引用了创建 Tensor 自身的Function(除非这个张量是用户手动创建的,即这个张量的grad_fn是 None )。下面给出的例子中,张量由用户手动创建,因此grad_fn返回结果是None。
from __future__ import print_function
import torch
x = torch.randn(3,3,requires_grad=True)
print(x.grad_fn)
None
如果需要计算导数,可以在 Tensor 上调用 .backward()。如果 Tensor 是一个标量(即它包含一个元素的数据),则不需要为 backward() 指定任何参数,但是如果它有更多的元素,则需要指定一个gradient参数,该参数是形状匹配的张量。
创建一个张量并设置requires_grad=True用来追踪其计算历史
x = torch.ones(2, 2, requires_grad=True)
print(x)
tensor([[1., 1.],
[1., 1.]], requires_grad=True)
对这个张量做一次运算:
y = x**2
print(y)
tensor([[1., 1.],
[1., 1.]], grad_fn=<PowBackward0>)
y是计算的结果,所以它有grad_fn属性。
print(y.grad_fn)
<PowBackward0 object at 0x000001CB45988C70>
对 y 进行更多操作
z = y * y * 3
out = z.mean()
print(z, out)
tensor([[3., 3.],
[3., 3.]], grad_fn=<MulBackward0>) tensor(3., grad_fn=<MeanBackward0>)
.requires_grad_(...) 原地改变了现有张量的requires_grad标志。如果没有指定的话,默认输入的这个标志是 False。
a = torch.randn(2, 2) # 缺失情况下默认 requires_grad = False
a = ((a * 3) / (a - 1))
print(a.requires_grad)
a.requires_grad_(True)
print(a.requires_grad)
b = (a * a).sum()
print(b.grad_fn)
False
True
<SumBackward0 object at 0x000001CB4A19FB50>
梯度
现在开始进行反向传播,因为 out 是一个标量,因此out.backward()和 out.backward(torch.tensor(1.)) 等价。
out.backward()
输出导数 d(out)/dx
print(x.grad)
tensor([[3., 3.],
[3., 3.]])

注意:grad在反向传播过程中是累加的(accumulated),这意味着每一次运行反向传播,梯度都会累加之前的梯度,所以一般在反向传播之前需把梯度清零。
# 再来反向传播⼀次,注意grad是累加的
out2 = x.sum()
out2.backward()
print(x.grad)
out3 = x.sum()
x.grad.data.zero_()
out3.backward()
print(x.grad)
tensor([[4., 4.],
[4., 4.]])
tensor([[1., 1.],
[1., 1.]])
现在我们来看一个雅可比向量积的例子:
x = torch.randn(3, requires_grad=True)
print(x)
y = x * 2
i = 0
while y.data.norm() < 1000:
y = y * 2
i = i + 1
print(y)
print(i)
tensor([-0.9332, 1.9616, 0.1739], requires_grad=True)
tensor([-477.7843, 1004.3264, 89.0424], grad_fn=<MulBackward0>)
8
在这种情况下,y 不再是标量。torch.autograd 不能直接计算完整的雅可比矩阵,但是如果我们只想要雅可比向量积,只需将这个向量作为参数传给 backward:
v = torch.tensor([0.1, 1.0, 0.0001], dtype=torch.float)
y.backward(v)
print(x.grad)
tensor([5.1200e+01, 5.1200e+02, 5.1200e-02])
也可以通过将代码块包装在 with torch.no_grad(): 中,来阻止 autograd 跟踪设置了.requires_grad=True的张量的历史记录。
print(x.requires_grad)
print((x ** 2).requires_grad)
with torch.no_grad():
print((x ** 2).requires_grad)
True
True
False
如果我们想要修改 tensor 的数值,但是又不希望被 autograd 记录(即不会影响反向传播), 那么我们可以对 tensor.data 进行操作。
x = torch.ones(1,requires_grad=True)
print(x.data) # 还是一个tensor
print(x.data.requires_grad) # 但是已经是独立于计算图之外
y = 2 * x
x.data *= 100 # 只改变了值,不会记录在计算图,所以不会影响梯度传播
y.backward()
print(x) # 更改data的值也会影响tensor的值
print(x.grad)
tensor([1.])
False
tensor([100.], requires_grad=True)
tensor([2.])
2.3 并行计算简介
在利用PyTorch做深度学习的过程中,可能会遇到数据量较大无法在单块GPU上完成,或者需要提升计算速度的场景,这时就需要用到并行计算。本节让我们来简单地了解一下并行计算的基本概念和主要实现方式,具体的内容会在课程的第二部分详细介绍。
2.3.1 为什么要做并行计算
我们学习PyTorch的目的就是可以编写我们自己的框架,来完成特定的任务。可以说,在深度学习时代,GPU的出现让我们可以训练的更快,更好。所以,如何充分利用GPU的性能来提高我们模型学习的效果,这一技能是我们必须要学习的。这一节,我们主要讲的就是PyTorch的并行计算。PyTorch可以在编写完模型之后,让多个GPU来参与训练。
2.3.2 为什么需要CUDA
CUDA是我们使用GPU的提供商——NVIDIA提供的GPU并行计算框架。对于GPU本身的编程,使用的是CUDA语言来实现的。但是,在我们使用PyTorch编写深度学习代码时,使用的CUDA又是另一个意思。在PyTorch使用 CUDA表示要开始要求我们的模型或者数据开始使用GPU了。
在编写程序中,当我们使用了 .cuda 时,其功能是让我们的模型或者数据迁移到GPU当中,通过GPU开始计算。
注:
- 我们使用GPU时使用的是.cuda而不是使用.gpu。这是因为当前GPU的编程接口采用CUDA,但是市面上的GPU并不是都支持CUDA,只有部分NVIDIA的GPU才支持,AMD的GPU编程接口采用的是OpenGL,在现阶段PyTorch并不支持。
- 数据在GPU和CPU之间进行传递时会比较耗时,应当尽量避免。
- GPU运算很快,但是在使用简单的操作时,我们应该尽量使用CPU去完成。
- 当我们的服务器上有多个GPU,我们应该指明我们使用的GPU是哪一块,如果我们不设置的话,tensor.cuda()方法会默认将tensor保存到第一块GPU上,等价于tensor.cuda(0),这将会导致爆出out of memory的错误。我们可以通过以下两种方式继续设置。
#设置在文件最开始部分
import os
os.environ["CUDA_VISIBLE_DEVICE"] = "2" # 设置默认的显卡
CUDA_VISBLE_DEVICE=0,1 python train.py # 使用0,1两块GPU
2.3.3 常见的并行的方法:
网络结构分布到不同的设备中(Network partitioning)
在刚开始做模型并行的时候,这个方案使用的比较多。其中主要的思路是,将一个模型的各个部分拆分,然后将不同的部分放入到GPU来做不同任务的计算。其架构如下:

这里遇到的问题就是,不同模型组件在不同的GPU上时,GPU之间的传输就很重要,对于GPU之间的通信是一个考验。但是GPU的通信在这种密集任务中很难办到,所以这个方式慢慢淡出了视野。
同一层的任务分布到不同数据中(Layer-wise partitioning)
第二种方式就是,同一层的模型做一个拆分,让不同的GPU去训练同一层模型的部分任务。其架构如下:

这样可以保证在不同组件之间传输的问题,但是在我们需要大量的训练,同步任务加重的情况下,会出现和第一种方式一样的问题。
不同的数据分布到不同的设备中,执行相同的任务(Data parallelism)
第三种方式有点不一样,它的逻辑是,我不再拆分模型,我训练的时候模型都是一整个模型。但是我将输入的数据拆分。所谓的拆分数据就是,同一个模型在不同GPU中训练一部分数据,然后再分别计算一部分数据之后,只需要将输出的数据做一个汇总,然后再反传。其架构如下:

这种方式可以解决之前模式遇到的通讯问题。
PS:现在的主流方式是数据并行的方式(Data parallelism)
仅作笔记使用,支持开源学习,支持Datawhale:
第一章:PyTorch的简介和安装 — 深入浅出PyTorch![]() https://datawhalechina.github.io/thorough-pytorch/%E7%AC%AC%E4%B8%80%E7%AB%A0/index.html第二章:PyTorch基础知识 — 深入浅出PyTorch
https://datawhalechina.github.io/thorough-pytorch/%E7%AC%AC%E4%B8%80%E7%AB%A0/index.html第二章:PyTorch基础知识 — 深入浅出PyTorch![]() https://datawhalechina.github.io/thorough-pytorch/%E7%AC%AC%E4%BA%8C%E7%AB%A0/index.html
https://datawhalechina.github.io/thorough-pytorch/%E7%AC%AC%E4%BA%8C%E7%AB%A0/index.html

