
- 1网上书城项目的书籍分类列表展示及新书上架和热销书籍效果展示功能(项目进度四)_网上书店前端页面模板
- 2LTR (Learning to Rank): 排序算法 poitwise, pairwise, listwise常见方案总结_ltr算法
- 3easyUI点击编辑操作实现行编辑,点击取消编辑取消编辑,点击添加实现添加行操作
- 4学习Prompt之从一无所知到微微一笑_如何学习prompt
- 5ssm+maven+swagger的使用详解_maven ssm swagger
- 6常见的网络安全设备及功能汇总
- 7【动态规划】【C++】最低票价问题_c++多短途的最小成本问题的动态规划算法实现
- 8【机器学习】TinyML的介绍以及在运动健康领域的应用
- 9二手车价格预测 | 构建AI模型并部署Web应用 ⛵_scikitlearn二手车价格预测模型
- 10AI 生成二次元女孩,免费云端部署(仅需5分钟)_civitai
深度学习入门2_深度学习入门2pdf
赞
踩
神经网络中的卷积计算
对于一张输入图片, 将其转化为矩阵, 矩阵的元素为对应的像素值。 假设有一个
5
×
5
5 \times 5
5×5 的图像,使用一个
3
×
3
3 \times 3
3×3 的卷积核进行卷积,可得到一个
3
×
3
3 \times 3
3×3 的特征图。卷积核也称为滤波器(Filter)。
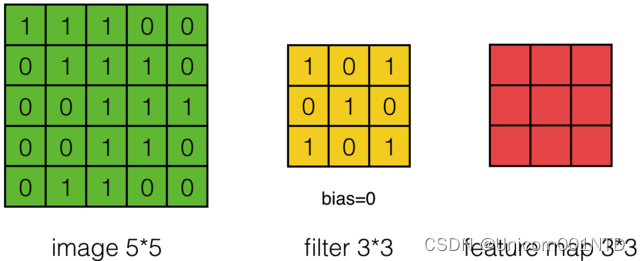
具体的操作过程如下图所示:
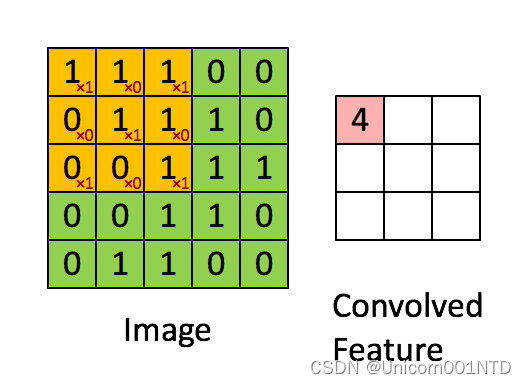
黄色的区域表示卷积核在输入矩阵中滑动, 每滑动到一个位置,将对应数字相乘并求和,,得到一个特征图矩阵的元素。注意卷积核每次滑动一个单位,滑动的幅度可以根据需要进行调整。如果滑动步幅大于 1, 则卷积核有可能无法恰好滑到边缘, 针对这种情况, 可在矩阵最外层补零,如下图所示:
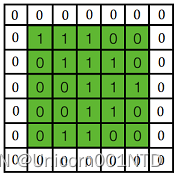
补零层称为 Zero Padding,是一个可以设置的超参数,但要根据卷积核的大小、 步幅和输入矩阵的大小进行调整,以使得卷积核恰好滑动到边缘。
一般情况下,输入的图片矩阵以及后面的卷积核,特征图矩阵都是方阵,这里设输入矩阵大小为
w
w
w,卷积核大小为
k
k
k,步幅为
s
s
s,补零层数为
p
p
p,则卷积后产生的特征图大小计算公式为:
w
′
=
w
+
2
p
−
k
s
+
1
w' = \frac{w+2p-k}{s} + 1
w′=sw+2p−k+1
上图是对一个特征图采用一个卷积核卷积的过程,为了提取更多的特征,可以采用多个卷积核分别进行卷积,这样便可以得到多个特征图。有时,对于一张三通道彩色图片,或者如第三层特征图所示,输入的是一组矩阵,这时卷积核也不再是一层的,而要变成相应的深度。
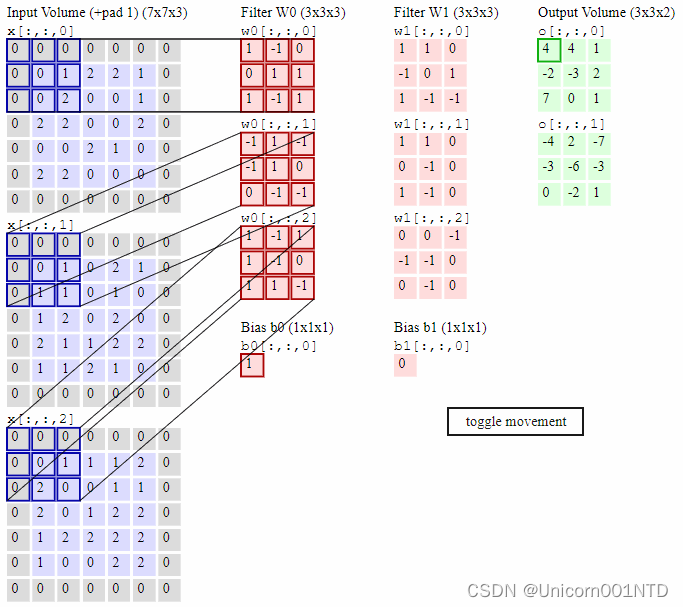
卷积神经网络
什么是卷积神经网络(CNN)
CNN是一种带有卷积结构的前馈神经网络,卷积结构可以减少深层网络占用的内存量,其中三个关键操作——局部感受野、权值共享、池化层,有效的减少了网络的参数个数,缓解了模型的过拟合问题。
卷积层和池化层一般会取若干个,采用卷积层和池化层交替设置,即一个卷积层连接一个池化层,池化层后再连接一个卷积层,依此类推。由于卷积层中输出特征图的每个神经元与其输入进行局部连接,并通过对应的连接权值与局部输入进行加权求和再加上偏置值,得到该神经元输入值,该过程等同于卷积过程,CNN也由此而得名1。
CNN主要应用于图像识别(计算机视觉,CV),应用有:图像分类和检索、目标定位检测、目标分割、人脸识别、骨骼识别和追踪,具体可见MNIST手写数据识别、猫狗大战、ImageNet LSVRC等,还可应用于自然语言处理和语音识别。
主要结构
CNN主要包括以下结构:
- 输入层(Input layer):输入数据;
- 卷积层(Convolution layer,CONV):使用卷积核进行特征提取和特征映射;
- 激活层:非线性映射(ReLU);
- 池化层(Pooling layer,POOL):进行下采样降维;
- 光栅化(Rasterization):展开像素,与全连接层全连接,某些情况下这一层可以省去;
- 全连接层(Affine layer / Fully Connected layer,FC):在尾部进行拟合,减少特征信息的损失;
- 输出层(Output layer):输出结果。
其中,卷积层、激活层和池化层可叠加重复使用,这是CNN的核心结构。
在经过数次卷积和池化之后,最后会先将多维的数据进行“扁平化”,也就是把图片的长、宽、通道的数据压缩成长度为长x宽x通道的一维数组,然后再与全连接层连接,这之后就跟普通的神经网络无异了。
经典的卷积神经网络
- LeNet-5
LeNet是最早推动深度学习领域发展的卷积神经网络之一。这项由Yann LeCun7完成的开创性工作自1988年以来多次成功迭代之后被命名为LeNet-5。
卷积层块里的基本单位是卷积层后接平均池化层。每个卷积层都使用5×5的窗口,并在输出上使用Sigmoid激活函数,用来识别图像里的空间模式,如线条和物体局部(第一个卷积层输出通道数为6,第二个卷积层输出通道数则增加到16);平均池化层则用来降低卷积层对位置的敏感性,对卷积层输出的结果进行采样,压缩图像尺寸大小。卷积层由两个这样的基本单位重复堆叠构成。
全连接层块含3个全连接层。其中的向量全部展开成一维向量,一维向量与权重向量进行点积运算,在加上一个偏置,通过激活函数后输出,得到新的神经元输出。它们的神经元个数分别是120、84和10,其中10为输出的类别个数,也是输出层。 - AlexNet
2012年,Alex Krizhevsky等6发布了 AlexNet,它是提升了深度和广度版本的LeNet,并在2012年以巨大优势赢得了ImageNet大规模视觉识别挑战赛(ILSVRC)。这是基于之前方法的重大突破,目前 CNN 的广泛应用都要归功于AlexNet。
AlexNet首次证明了学习到的特征可以超越⼿⼯设计的特征,它有以下四点特征:
8层变换,其中有5层卷积和2层全连接隐藏层,以及1个全连接输出层;
将sigmoid激活函数改成了更加简单的ReLU激活函数,降低了模型的计算复杂度,模型的训练速度也提升了几倍;
Max池化,避免平均池化的模糊化效果。同时采用重叠池化,提升特征的丰富性;
用Dropout来控制全连接层的模型复杂度:通过Dropout技术在训练过程中将中间层的一些神经元随机置为0,使模型更具有鲁棒性,也减少了全连接层的过拟合;
引入数据增强(Data Augmentation),如图像平移、镜像、翻转、裁剪、改变灰度和颜色变化,从而进一步扩大数据集来缓解过拟合。 - GoogLeNet
2014年 ILSVRC 获奖者是 Google 的 Szegedy 等8人的卷积网络。其主要贡献是开发了一个初始模块(Inception),该模块大大减少了网络中的参数数量。
LeNet、AlexNet和VGG都是先以由卷积层构成的模块充分抽取空间特征,再以由全连接层构成的模块来输出分类结果。与它们三种模型不同,GoogLeNet模型由如下的Inception基础块组成,Inception块相当于⼀个有4条线路的子网络,该结构将CNN中常用的卷积、池化操作堆叠在一起,一方面增加了网络的宽度,另一方面也增加了网络对尺度的适应性。它通过不同窗口形状的卷积层和最⼤池化层来并行抽取信息,并使用 1 × 1 1 \times 1 1×1卷积层减少通道数从而降低模型复杂度。它的参数比AlexNet少了12倍,而且GoogleNet的准确率更高。 - VGGNet
2014年ILSVRC亚军是名为VGGNet的网络,由Simonyan等人9开发。其主要贡献在于证明了网络深度(层数)是影响性能的关键因素。它使用了小卷积核,用卷积深度替代了卷积核大小。
VGG模型用具有小卷积核的多个卷积层替换一个具有较大卷积核的卷积层,如用大小均为 3 × 3 3 \times 3 3×3卷积核的3层卷积层代替一层具有 7 × 7 7 \times 7 7×7卷积核的卷积层,这种替换方式减少了参数的数量,而且也能够使决策函数更具有判别性。接上一个步幅为 2 2 2、窗口形状为 2 × 2 2 \times 2 2×2的最大池化层,使得卷积层保持输入的高和宽不变,而池化层则对其减半。- 2个 3 × 3 3\times3 3×3相当于1个 5 × 5 5 \times 5 5×5 ;
- 3个 3 × 3 3 \times 3 3×3相当于1个 7 × 7 7\times7 7×7;
- 1 × 1 1 \times 1 1×1的卷积层可视为非线性变换。

