
- 1推荐使用AI开源平台:搭建GA领域案件分类的自动化处理
- 2CSDN付费专栏写作协议_csdn关闭付费专栏后文章还在吗
- 3实例7:将图片文件制作成Dataset数据集_sklearn将图片转成数据集
- 4【阅读论文】TimesNet短期预测的基本流程梳理_m4数据集
- 5Java:SpringBoot的使用_java 程序 使用springboot 库
- 6探索政府工作报告中计算机行业的发展方向
- 7【亲测有效】Claude3为什么不能注册?解决Claude3账号注册遇到被封号和无法发送手机验证码问题!_claude 注册 虚拟号 不行
- 8目标跟踪简介
- 92023华为OD面试手撕真题【行星碰撞】_华为面试行星碰撞
- 10【黑马程序员】SpringCloud——微服务_黑马程序员springcloud资料
Azure OpenAI 官方指南02|ChatGPT 的架构设计与应用实例_azure chatgpt
赞
踩

ChatGPT 作为即将在微软全球 Azure 公有云平台正式发布的服务,已经迅速成为了众多用户关心的服务之一。而由 OpenAI 发布的 ChatGPT 产品,仅仅上线两个月,就成为互联网历史上最快突破一亿月活的应用。本期从技术角度深度解析 ChatGPT 的架构设计与应用实例。
ChatGPT的起源 ╱ 01
InsturctGPT的架构设计 ╱ 02
ChatGPT的技术应用场景及示例 ╱ 03
ChatGPT 的起源
ChatGPT 是由 OpenAI 公司在 2022年11月推出的一款智能聊天机器人程序,属于文本类AI应用。这里,Chat 即「聊天」,GPT 的全称为“Generative Pre-trained Transformer”。由于采用 Transformer 架构,且 ChatGPT 在 GPT-3 大模型基础上专门针对 Chat 聊天能力做了性能上的调优,所以 ChatGPT 在自然语言的许多交互场景中表现出了卓越的性能。
Transformer 模型在2017年问世,能够同时并行进行数据计算和模型训练,训练时长更短,并且训练得出的模型可用语法解释,也就是模型具有可解释性。经过训练后,这个最初的 Transformer 模型在包括翻译准确度、英语成分句法分析等各项评分上都达到了业内第一,成为当时最先进的大型语言模型(Large Language Model, LLM)。
2018年,在 Transformer 模型诞生还不到一年的时候,OpenAI 公司发表了论文“Improving Language Understanding by Generative Pre-training”(用创造型预训练提高模型的语言理解力),并推出了具有1.17亿个参数的GPT-1(Generative Pre-training Transformers)模型。
这是一个用大量数据训练的、基于 Transformer 结构的模型。OpenAI 的工程师使用了经典的大型书籍文本数据集(BookCorpus)进行模型预训练。该数据集包含超过7000本从未出版的书籍,涵盖了冒险、奇幻、言情等类别。在预训练之后,工程师们又针对四种不同的语言场景、使用不同的特定数据集对模型进行进一步的训练(又称为微调,Fine-Tuning)。最终训练所得的模型在问答、文本相似性评估、语义蕴含判定,以及文本分类这四种语言场景,都取得了比基础 Transformer 模型更优的结果,成为了新的业内第一。
2019年,OpenAI 公布了一个具有15亿个参数的模型:GPT-2。该模型架构与 GPT-1 原理相同,主要区别在于 GPT-2 的规模更大(10倍)。同时,OpenAI 也发表了介绍该模型的论文“Language Models are Unsupervised Multitask Learners”。
2020年,OpenAI 发表论文“Language Models are Few-Shot Learner”,并推出了最新的 GPT-3 模型——它有1750亿个参数。GPT-3 模型架构与 GPT-2 类似,但是规模大了整整两个数量级。GPT-3 的训练集也比前两款 GPT 模型要大得多:经过基础过滤的全网页爬虫数据集(4290亿个词符)、维基百科文章(30亿词符)、两个不同的书籍数据集(670亿词符)。
2022年3月,OpenAI再次发表论文“Training Language Models to Follow Instructions with Human Feedback”,并推出了基于 GPT-3 模型并进一步微调的 InstructGPT 模型。InstructGPT 的模型训练中加入了人类的评价和反馈数据,而不仅仅是事先准备好的数据集,从而训练出更真实、更无害,且更好地遵循用户意图的语言模型。
2022年11月,ChatGP 横空出世,它是基于 GPT-3.5 架构开发的对话AI模型,是 InstructGPT 的兄弟模型。但两者在训练模型的数据量上,以及数据收集、数据如何设置用于训练方面有所不同。
InsturctGPT 的架构设计
目前 Azure OpenAI 还没有官方公开资源详细说明 ChatGPT 的技术原理,因此我们将以 ChatGPT 的兄弟模型 InstructGPT 为对象,深度解析其算法架构设计。

如上图所示,开发人员将提示分为三个阶段,并以不同的方式为每个阶段创建响应和训练:
第 1 阶段 训练监督策略模型
在这个阶段,工程师会在数据集中随机抽取问题,由专门的标注人员给出高质量答案,然后用这些人工标注好的数据来微调 GPT-3.5 模型。这些标注人员会在应聘前进行筛选测试,训练数据大约有1万3千个。相较于第二、三阶段,这里用到的数据量较少。
标注人员根据提示 (prompt) 编写质量可靠的输出响应 (demonstrations)。这里采用的是 Supervised Fine-Tuning(SFT)模型,即有监督的策略来进行微调。微调之后,SFT 模型在遵循指令/对话方面已经优于 GPT-3.5,但不一定符合人类偏好。
第 2 阶段 训练奖励模型
这一阶段主要是训练一个奖励模型Reward Modeling (RM)。这里的训练数据是怎么得到的呢?首先通过在数据集中随机抽取问题,使用第一阶段生成的模型,对每个问题生成多个不同的回答,然后再让标注人员对这些回答进行排序。对于标注人员来说,对输出进行排序比从头开始打标要容易得多,因此这一过程可以扩展数据量,大约产生3万3千个训练用的数据。
接下来,再使用这个排序结果来训练奖励模型。对于多个排序结果,两两组合,形成多个训练数据对。RM 模型接受输入后,给出评价回答质量的分数。对于一对训练数据,通过调节参数使得高质量回答的打分比低质量的打分要高。奖励模型学会了为评分高的响应计算更高的奖励,为评分低的回答计算更低的奖励。
第 3 阶段 采用 PPO 强化学习进行优化
PPO (Proximal Policy Optimization,近端策略优化)是一种用于在强化学习中训练 agent 的策略,这里被用来微调 SFT 模型。这一阶段利用第二阶段训练好的奖励模型,靠奖励打分来更新预训练模型参数。在数据集中随机抽取问题后,使用 PPO 模型生成回答,并用上一阶段训练好的 RM 模型计算奖励,给出质量分数,然后用这个奖励来继续更新 PPO 模型。奖励依次传递,由此产生策略梯度,通过强化学习的方式更新 PPO 模型参数。
不断重复第二和第三阶段,通过迭代,会训练出更高质量的 InstructGPT 模型。我们将来自于人类反馈的强化学习简称为 RLHF(reinforcement learning from human feedback):使用人类的偏好作为奖励信号来微调模型。这也是 ChatGPT 在实际对话过程中的输出更符合人类偏好的原因。
ChatGPT 的技术应用场景及示例
总的来说,ChatGPT 有如下几大类技术应用的领域——
⦿ 对话机器人:可以用于生成自然语言对话,实现人机交互。
⦿ 文本生成:可以用于生成摘要、文章、诗歌等文本。
⦿ 问答系统:可以用于回答用户提出的问题,提供相关信息。
⦿ 自动翻译:可以用于实现自动翻译,将文本从一种语言翻译为另一种语言。
⦿ 情感分析:可以用于分析文本的情感倾向,实现情感分析。
⦿ 语音合成:可以用于生成语音,将文本转换为语音。
场景示例 1 NLP 领域

⦿ 生成摘要

⦿ 情感分析(小样本或零样本)
few-shot or zero-shot

⦿ 开放领域问答

⦿ 由文字生成表格

⦿ 数据集生成(小样本或零样本)
few-shot or zero-shot
场景示例 2 代码领域

⦿ 代码生成

⦿ 解释代码
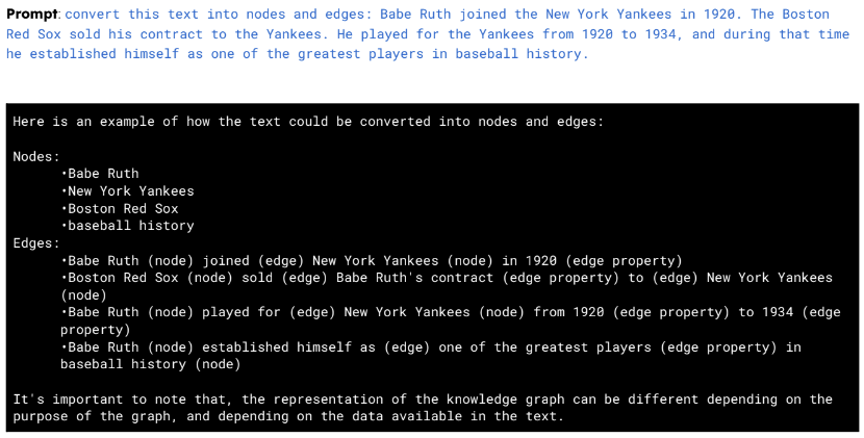
⦿ 知识库生成
Azure OpenAI 官方指南 Vol.02 ChatGPT 作者
Annie Hu 微软云 AI 高级技术专家

