
- 1【送书福利-第三十八期】《 SaaS产品实践方法论:从0到N构建SaaS产品》
- 26-闭包和装饰器_带参数的装饰器。定义一个没有参数的函数foo,用于输出语句;定义一个装饰器函
- 3迅为RK3568开发板Debian系统安装ToDesk_debian rk3568版本
- 4php 生成水印输出图片,PHP的生成图片或文字水印的类
- 5SpringBoot3.x整合Nacos和Redis
- 6365天挑战LeetCode1000题——Day 109 贝壳周赛
- 7kubernetes 二进制部署
- 8Mysql-基本练习(07-修改表-添加主键、唯一、外键约束、添加/删除默认约束、删除约束)_alter table tb1 drop foreign key tb1____ibfk ____1
- 9神经网络学习笔记——神经网络基础(一)
- 10SpringBoot如何正确连接SqlServer_spring sqlserver
YoloV7训练最强操作教程._yolov7教程
赞
踩
YoloV7训练最强操作攻略
本文主要带领大家使用yolov7对口罩目标检测数据集进行实践,主要就是希望通过本教程可以让各位使用yolov7对自己的数据集进行训练,测试,预测。代码数据集训练模型链接在最后!
YOLOV7配置文件合并,随意更换主干,TSOCDE(2023最新解耦头)项目链接
2022-11-20更新:
在b站上传了一个yolov7的视频教学,配合本博文使用.链接
B站中的数据集链接,这个是一个1.1w张识别人是否带口罩的目标检测数据集,里面有voc格式和yolo格式.这个是yolov7训练好的代码和模型文件,里面有训练好的yolov7-tiny,yolov7,yolov7w6的权重,可以直接使用检测。
在yolov7中添加pyqt5作为可视化界面的教程、视频讲解、源码。链接
2022-12-28更新:
在B站和github上更新了yolov5和yolov7的热力图可视化,不需要对源码作任何修改,即插即用,有兴趣可以去看看。
2023-1-9更新:
B站和博客上上传了DAMO-YOLO的教程.
2023-1-28更新:
B站教学链接和博客 YOLOV7改进-添加EIOU,SIOU,AlphaIOU,FocalEIOU.
2023-1-31更新:
B站教学链接 YOLOV7改进-添加注意力机制 附带几十种注意力机制代码.
2023-2-11更新:
B站教学链接 YOLOV7改进-Wise IoU 参考.
2023-2-18更新:
B站教学链接 YOLOV7改进-添加可变形卷积DCNV2.
2023.2.26 更新
B站教学链接 可视化并统计预测结果的TP,FP,FN
2023.2.26 更新
B站教学链接 YOLOV7改进-添加SAConv.
重磅!!!!! YOLO模型改进集合指南-CSDN
2023-1
1月份会更新一个yolov7+byteTrack(2021年目标跟踪SOTA)源码,有兴趣的请点赞并关注,敬请期待!
另外这里打个广告,就是我自己整合并开源的一个基于pytorch-image-classifier代码,这个是示例博客,功能和可视化都非常全,有兴趣的可以看看,谢谢!
正文开始:
1. 下载源码和数据集
对于源码各位看官可以直接下载本链接的代码,本链接代码包含了一些便捷工具,比如voc格式转yolo,分割数据集等等,本链接的代码会随着官网的更新而更新,所以不用害怕代码版本旧的问题啦!
这里我准备了一个口罩目标检测数据集,如果各位目前没有数据集的可以下载一下这个数据集作为本博客的实践数据集案例。
2.配置环境
环境配置可以参考本博主的另外一篇文章基于pytorch的花朵分类,安装过程出现有什么问题,可以私信博主或者留言,博主看到会尽力帮助大家解决问题。
3. 处理数据集
总所周知,yolo系列的大部分源码都是需要使用yolo格式的标注文件,那么网上大部分数据集都是voc格式,那么这里就需要做一个格式的转换,我们下面分两种情况:
VOC数据集格式
如果你的数据集格式是VOC格式的话,一般就会有图片和xml后缀的文件,这个xml后缀的文件就是你的数据集的标签文件,在代码中,我们的dataset文件夹就是数据集的存储的位置,其中图片存放在dataset/VOCdevkit/JPEGImages文件夹中,标签文件需要存放在dataset/VOCdevkit/Annotations文件夹中,dataset/VOCdevkit/txt文件夹是存储转换后的yolo格式标签文件.。(这个文件创不创建都可以,转换的时候会自动检测,不存在的话会自动创建)


当然自己也可以修改imgpath(存放图像的路径),xmlpath(存在voc标注格式的路径),txtpath(存放转换的yolo格式的路径),不过博主建议一般就不要修改,因为有些看主的动手能力相对差一点,修改后有报错可能不会处理,建议还是按照博主路径和示例来是最稳妥的。
对应的数据放置好后,我们需要运行xml2txt.py,其中这个文件有一个postfix参数,其为你图像的后缀格式,默认为jpg,如果你的图像是bmp或者png可以修改这个参数,当然其不支持混合的后缀格式,其会导致输出文件找不到的错误信息,这个请大家注意!这个文件会把Annotations文件夹中的xml文件读取到内存,然后进行转换成yolo格式并保存到dataset/VOCdevkit/txt文件夹中,其中运行截图如下图所示:
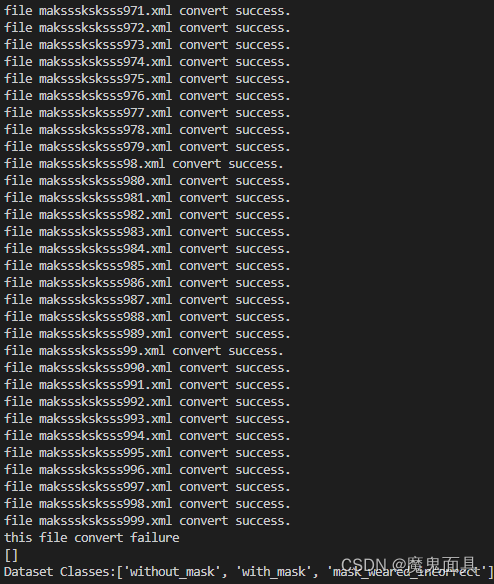
每个文件的转换都会单独有一行的输出,如果某个文件转换有问题或者你的标注文件里面有其他格式的文件存在都会提示对应的信息,比如如果某个文件转换失败的话,会提示报错信息,但是不会终止程序,只是这个文件就不转换了,最后会有一个this file convert failure下方有一个列表,如果这个列表为空,就是证明全部转换成功,如果不为空,列表里面的文件路径就是转换出错的标注文件,这种你可以看一下报错信息,如果奇奇怪怪的基本就不用理了,但是需要注意的一点是如果全部都转换出错了,那很有可能就是你存放的位置不对等等,这些需要根据报错信息检查。第二个列表是你这个数据集中的类别信息,这个类别信息是有用的,我们需要手动复制到data/data.yaml文件的names里面,如下图所示:

其中蓝色框是固定的路径(如果你按照本教程操作),黄色框是根据你数据集的类别进行修改,比如当前数据集是三个类别,我们就设置为3,红色款就是我们这个xml2txt.py输出的信息,那么类别的名字是可以改的,假设我们第三个类别代表的意思是不正确佩戴口罩,那么我们修改为mask_incorrect都是可以的,不过建议不要包含中文。
YOLO数据集格式
如果你自己的数据集是YOLO格式的话,那么你就直接把全部图片放到dataset/VOCdevkit/VOC2007/JPEGImages文件夹中,标签文件txt放到dataset/VOCdevkit/VOC2007/txt中,然后需要自行修改一下data/data.yaml中的类别数和类别名字,对于YOLO格式的数据集,一般会单独有一个classes.txt来记录类别信息。
分割数据集
无论对于VOC格式数据集还是YOLO格式数据集,按照上述步骤处理好后运行split_data.py,这个文件也有一个postfix参数,默认为jpg,如果自己的数据集不是jpg后缀的话,请自行修改,当然不支持混合后缀格式,请大家注意!split_data.py中还有val_size,test_size参数,其为比例系数,默认为0.1,0.2,如有需要请自行修改。运行成功后,其会自动创建下图这些文件夹,然后把对应的图片和标签文件复制到对应的文件夹中。
当你完成这一步的时候,数据集就处理完成。
4. 训练
对于训练,我们分为两个来说,因为yolov7是有两个训练的文件,一个是train.py,一个是train_aux.py。其中如果你是下载本文章的代码,那么预训练权重是已经下载好到项目中的weights文件夹,那么下面开始训练的教程:
训练-train.py
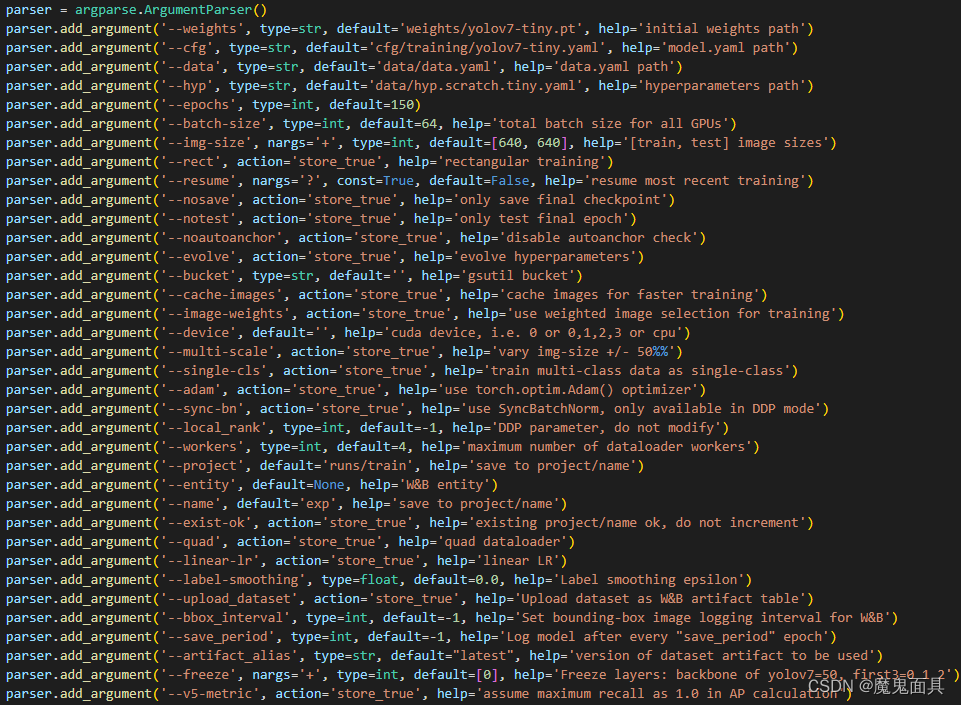
我们先解释一下重点的参数的意思:
- weights
预训练文件权重路径,这个可以在weights文件夹中找到。 - cfg
模型配置文件路径,这个可以在cfg/training文件夹中找到。 - data
数据配置文件的路径,默认就是data/data.yaml。 - hyp
超参数配置文件路径,这个可以在data文件夹中可以找到。 - epochs
学习次数。 - batch-size
一次迭代的数据量。 - img-size
训练的图像输入大小。 - resume
是否继续上一次未完成的训练。 - device
训练所使用的的设备。 - label-smoothing
标签平滑的值。 - name
日志模型保存的文件夹名字。 - project
日志模型保存的文件夹中的上一级文件夹的路径。 - workers
dataloader中的workers数量。 - single-cls
是否把所有类别当做一个类别去训练。就是不分类别的意思。 - multi-scale
多尺度训练。
对于大部分项目,我们只需要关注weights,cfg,epochs,batch-size,img-size这几个参数即可,其中weights与cfg需要相匹配,就是你选择yolov7-tiny的配置文件,你就要选择yolov7-tiny的权重,如下图所示:

那么我们就可以开始训练,其中我们这里就使用yolov7-tiny进行演示,如果需要训练其他模型,请自行更改–weights和–cfg参数的路径即可,有一个点注意的就是目前的这个train.py只支持训练yolov7-tiny,yolov7,yolov7x这三个模型:

其他的模型是要在另外一个训练脚本train_aux.py中训练,我们下边会进行演示,我们的参数设置如下:
然后运行train.py文件即可,接下来就是漫长的训练时间,当训练结束后,我们可以在控制台看到以下信息:
其中最后会输出训练时间,精度指标,保存的模型路径和大小。
训练-train_aux.py
首先这个脚本文件所训练的模型都是比较大的,一般没有服务器的话可能就训练不起来,这个操作上跟train.py一模一样,只是cfg和weights只支持下面的这些模型:
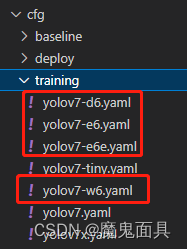
因为这个train_aux.py只支持训练带有p6检测层的模型,然后我们的训练参数设置如下:

主要就是修改了weights和cfg参数,因为带有p6检测层的模型都比较大,因此这里epochs只设置为50做个演示,然后我们就可以运行train_aux.py,等待训练完成即可。
–hyp参数
hyp参数是超参数的配置文件路径,对于新手来说,一般默认即可,就是不需要修改你基本都可以得到一个比较好的结果,对于想调参的看官,可以自行打开对应的文件进行修改,配置文件中每个参数官方都给出比较详细的解释。
4. 测试
第三步我们主要分别介绍了train.py和train_aux.py两个训练脚本的一些重要参数和如何使用,第四步我们主要介绍如何使用训练好的模型对我们的测试集进行计算指标。我们计算指标的脚本是test.py,下面对一些重点的参数进行讲解:
- weights
训练好的模型权重路径。 - data
数据配置文件路径。模型就是data/data.yaml(如果你按照本博客操作的话) - batch-size
测试一次迭代的数据量。 - img-size
测试的图像大小,一般跟训练的时候保持一致。 - conf-thres
目标的置信度阈值。 - iou-thres
nms中iou阈值。 - task
任务类型,支持测试(train,val,test)集合,默认是test,还支持计算fps,只需要设置为speed。 - augment
是否采用测试阶段数据增强(TTA)。 - verbose
代码中注释是写显示每个类别的ap,但是实际使用起来没有区别。 - save-txt
是否需要把识别的结果存为txt。 - save-hybrid
测试的时候感觉跟save-txt没什么区别,如有了解可以留言。 - save-conf
是否保存置信度,需要配合save-txt一起使用。 - save-json
是否需要把识别结果保存为coco-json格式。 - name
精度指标保存的文件夹名字。 - project
精度指标保存的文件夹中的上一级文件夹的路径。
我们训练成功后可以在runs/train中的文件集里面找到以下文件:
其中weights里面都是训练保存的权重,其他的都是一些指标文件,自己可以打开看看,这里就不细讲了,都是一些比较常见的指标。
我们参数设置如下,主要就是weights的路径,这里我们选用best.pt,就是在训练过程中验证集精度最好的模型。
运行结束后,你可以看到下图:

显示的是每个类别和总体的指标和一些推理耗时信息。你还可以在runs/test中的文件夹里面找到对应的指标图像:
5. 预测
第五步就是预测脚本detect.py的教程,其大部分参数跟test.py类似,我们先解释一下重点的参数:
- weights
训练好的模型权重路径。 - source
检测的数据路径。(支持图像,文件夹(里面是存放图片),视频) - img-size
测试的图像大小,一般跟训练的时候保持一致。 - conf-thres
目标的置信度阈值。 - iou-thres
nms中iou阈值。 - augment
是否采用测试阶段数据增强(TTA)。 - verbose
代码中注释是写显示每个类别的ap,但是实际使用起来没有区别。 - save-txt
是否需要把识别的结果存为txt。 - save-conf
是否保存置信度,需要配合save-txt一起使用。 - name
精度指标保存的文件夹名字。 - project
精度指标保存的文件夹中的上一级文件夹的路径。
我们的参数设置如下:
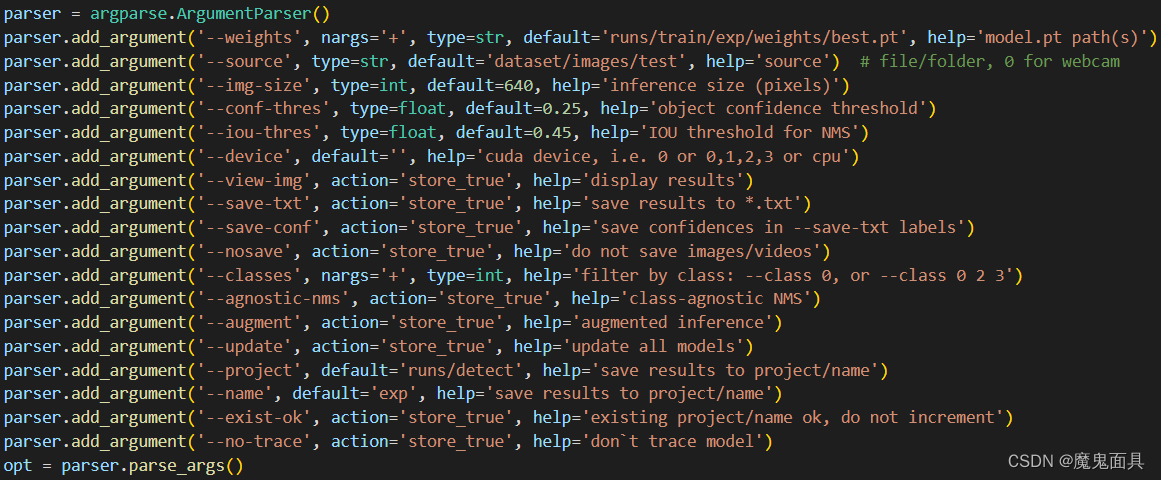
那么我们跟使用test.py一致,也是用best.pt进行检测,source我们设置为测试集的图片路径。运行完成后,你可以在runs/detect文件夹中找到对应保存的图像数据。
6.后续
后续还会更新实用性比较高的基于yolov7的口罩检测项目(带pyqt界面,训练数据集更加大,检测效果更加好),可以用作课程项目或者毕业设计等等,请各位多多关注。
代码数据集模型链接

