
- 1uniapp App端使用高德地图_uniapp接入高德地图
- 2OSPF在广播类型的网络拓扑中DR和BDR的选举_h3c ospf dr和bdr选举
- 3Goby 漏洞发布|kafka-ui messages 远程代码执行漏洞(CVE-2023-52251)
- 4价值1000元的数字人制作教程来了_制作数字人
- 5编译原理总结_编译原理 基础问题
- 6利用python编写祝福_我用Scratch和Python编程祝福送给您Merry Christmas!
- 7【LLM】Langchain使用[三](基于文档的问答)_langchain csvloader
- 8IRC工具选择_好用的irc软件
- 9LLM: Prompt的使用
- 10关闭es-lint_typescript-eslint如何关闭
神经网络学习笔记——神经网络基础(一)
赞
踩
神经网络学习笔记——神经网络基础(一)
一、神经网络介绍
人工神经网络( Artificial Neural Network, 简写为ANN)也简称为神经网络(NN),是一种模仿生物神经网络结构和功能的 计算模型。
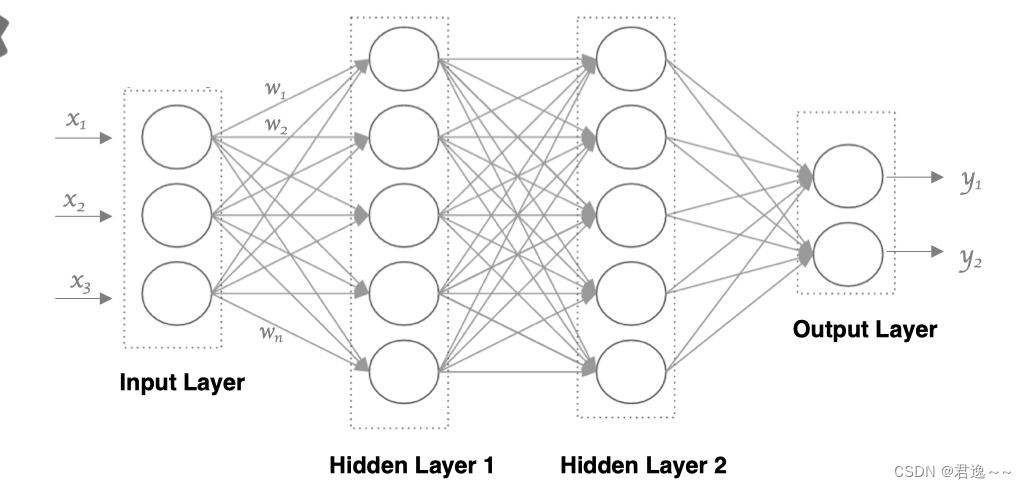
- 输入层: 即输入 x 的那一层
- 输出层: 即输出 y 的那一层
- 隐藏层: 输入层和输出层之间都是隐藏层
- 每个连接都有一个权值
二、激活函数
激活函数用于对每层的输出数据进行变换, 进而为整个网络结构结构注入了非线性因素。 如果不使用激活函数,整个网络虽然也复杂,但是其本质依旧是线性模型

5. 没有引入非线性因素的网络等价于使用一个线性模型来拟合
6. 通过给网络输出增加激活函数, 实现引入非线性因素, 使得网络模型可以逼近任意函数, 提升网络对复杂问题的拟合能力.
常见的激活函数
1. sigmoid 激活函数:sigmoid 函数将任意的输入映射到 (0, 1) ,减少最大最小值的影响
sigmoid 网络在 5 层之内就会产生梯度消失现象。而且,该激活函数并不是以 0 为中心的,所以在实践中这种激活函数使用的很少。sigmoid函数一般只用于二分类的输出层。
2. tanh 激活函数: Tanh 函数将输入映射到 (-1, 1) 之间
它是以 0 为中心的,使得其收敛速度要比 Sigmoid 快,减少迭代次数。然而,从图中可以看出,Tanh 两侧的导数也为 0,同样会造成梯度消失。若使用时可在隐藏层使用tanh函数,在输出层使用sigmoid函数。
3. ReLU 激活函数:ReLU 激活函数将小于 0 的值映射为 0,而大于 0 的值则保持不变,它更加重视正信号,而忽略负信号,这种激活函数运算更为简单,能够提高模型的训练效率。
4. SoftMax激活函数:softmax用于多分类过程中,它是二分类函数sigmoid在多分类上的推广,目的是将多分类的结果以概率的形式展现出来。
Softmax 直白来说就是将网络输出的 logits 通过 softmax 函数,就映射成为(0,1)的值,而这些值的累和为1(满足概率的性质),那么我们将它理解成概率,选取概率最大(也就是值对应最大的)节点,作为我们的预测目标类别。

三、反向传播算法(BP算法)
利用反向传播算法对神经网络进行训练。该方法与梯度下降算法相结合,对网络中所有权重计算损失函数的梯度,并利用梯度值来更新权值以最小化损失函数。
前向传播指的是数据输入的神经网络中,逐层向前传输,一直到运算到输出层为止。
在网络的训练过程中经过前向传播后得到的最终结果跟训练样本的真实值总是存在一定误差,这个误差便是损失函数。想要减小这个误差,就用损失函数 ERROR,从后往前,依次求各个参数的偏导,这就是反向传播(Back Propagation)
-
梯度下降
梯度下降法简单来说就是一种寻找使损失函数最小化的方法,从数学上的角度来看,梯度的方向是函数增长速度最快的方向,那么梯度的反方向就是函数减少最快的方向。
w2 = w1 - n*下降方向
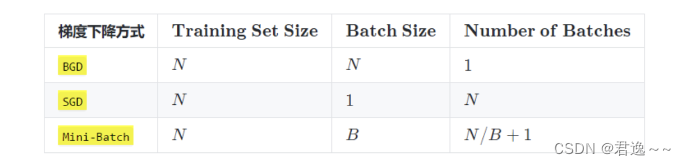
三个基本概念- Epoch: 使用全部数据对模型进行一次完整训练
- Batch: 使用训练集中的小部分样本对模型权重进行一次反向传播的参数更新
- Iteration: 使用一个 Batch 数据对模型进行一次参数更新的过程
-
链式法则
反向传播算法是利用链式法则进行梯度求解及权重更新的。对于复杂的复合函数,我们将其拆分为一系列的加减乘除或指数,对数,三角函数等初等函数,通过链式法则完成复合函数的求导。 -
反向传播
BP (Back Propagation)算法也叫做误差反向传播算法,它用于求解模型的参数梯度,从而使用梯度下降法来更新网络参数。它的基本工作流程如下:- 通过正向传播得到误差,所谓正向传播指的是数据从输入到输出层,经过层层计算得到预测值,并利用损失函数得到预测值和真实值之前的误差。
- 通过反向传播把误差传递给模型的参数,从而对网络参数进行适当的调整,缩小预测值和真实值之间的误差。
- 反向传播算法是利用链式法则进行梯度求解,然后进行参数更新。对于复杂的复合函数,我们将其拆分为一系列的加减乘除或指数,对数,三角函数等初等函数,通过链式法则完成复合函数的求导。
import torch import torch.nn as nn import torch.optim as optim class Net(nn.Module): def __init__(self): super(Net, self).__init__() self.linear1 = nn.Linear(2, 2) self.linear2 = nn.Linear(2, 2) # 网络参数初始化 self.linear1.weight.data = torch.tensor([[0.15, 0.20], [0.25, 0.30]]) self.linear2.weight.data = torch.tensor([[0.40, 0.45], [0.50, 0.55]]) self.linear1.bias.data = torch.tensor([0.35, 0.35]) self.linear2.bias.data = torch.tensor([0.60, 0.60]) def forward(self, x): x = self.linear1(x) x = torch.sigmoid(x) x = self.linear2(x) x = torch.sigmoid(x) return x if __name__ == '__main__': inputs = torch.tensor([[0.05, 0.10]]) target = torch.tensor([[0.01, 0.99]]) # 获得网络输出值 net = Net() output = net(inputs) # print(output) # tensor([[0.7514, 0.7729]], grad_fn=<SigmoidBackward>) # 计算误差 loss = torch.sum((output - target) ** 2) / 2 # print(loss) # tensor(0.2984, grad_fn=<DivBackward0>) # 优化方法 optimizer = optim.SGD(net.parameters(), lr=0.5) # 梯度清零 optimizer.zero_grad() # 反向传播 loss.backward() # 打印 w5、w7、w1 的梯度值 print(net.linear1.weight.grad.data) # tensor([[0.0004, 0.0009], # [0.0005, 0.0010]]) print(net.linear2.weight.grad.data) # tensor([[ 0.0822, 0.0827], # [-0.0226, -0.0227]]) # 打印网络参数 optimizer.step() print(net.state_dict()) # OrderedDict([('linear1.weight', tensor([[0.1498, 0.1996], [0.2498, 0.2995]])), # ('linear1.bias', tensor([0.3456, 0.3450])), # ('linear2.weight', tensor([[0.3589, 0.4087], [0.5113, 0.5614]])), # ('linear2.bias', tensor([0.5308, 0.6190]))])

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67

