
- 1PowerMILL中大型汽车模具3+2编程加工视频教程-保险杠车灯门_pm3+2编程
- 2PyTorch学习(6)—快速搭建法_import torchfrom torch.autograd import variableimp
- 3构建Wiki中文语料词向量模型(python3)_词向量模型 python
- 4GPT-4强到离谱,OpenAI首席科学家:开源并不明智,我们错了!
- 5python文字语音互转_python文字转语音
- 6机器学习算法总结_算法 通过标签 得到 特征值 最大几率
- 7python命名实体识别工具包 结巴_分词、词性标注、命名实体识别、句法分析?三行Python代码调用斯坦福自然语言处理工具~...
- 8Generative Pre-trained Transformer
- 9Python学习笔记:函数_"max()返回可迭代对象中的元素中的最大值或者所有参数的最大值,则max(\"123\")返回的"
- 10python训练自己中文语料库_中文语料库构建过程详细教程
【3D目标分类】PCT:Point Cloud Transformer
赞
踩
前言
1. 为什么要做这个研究?
将很火的Transformer迁移到点云学习中,发现也能取得很不错的效果。
2. 实验方法是什么样的?
网络分为三个部分:输入嵌入、注意力层和分类分割。
输入嵌入层:将点云从欧氏空间xyz映射到128维的空间,这里作者提出了点嵌入和邻域嵌入两种方法,后者还考虑了局部邻域信息。
注意力层:作者采用了自注意力(self-attention)机制和偏置注意力(offset-attention)机制。
分类分割操作:作者对经过注意力层的特征直接进行池化,再分别进行分类和分割的下一步操作。
3. 得到了什么结果?
在分类、分割任务中均取得了很好的效果。
摘要
不规则的定义域和无序性给设计用于点云处理的深度神经网络带来了挑战。作者提出了一种新的用于点云学习的框架,Point Cloud Transformer(PCT)。PCT是基于Transformer的,具有处理一系列点的置换不变性,非常适合点云学习。为了更好地捕获点云内的局部环境,作者加强了输入嵌入,支持最远点采样和最近邻搜索。该算法在形状分类、零件分割、语义分割和一般的估计任务中均取得了较好的性能。
1.介绍
点云是无序且无结构的,这使得设计神经网络直接从点云中提取语义很有挑战性。PointNet使用多层感知机(MLPs)、maxpooling和刚性变换来确保排列和旋转下的不变性,从而对点云进行特征学习。SEGCloud、PointCNN、PointConv等方法都考虑定义卷积算子来聚合点云的局部特征。这些方法要么对输入点序列进行重新排序,要么对点云进行体素化,以获得一个标准的卷积域。
Transformer是一种encoder-decoder结构,包含了3个模块:输入词嵌入、位置(顺序)编码和self-attention。其中,self-attention是其核心组件,基于全局上下文的输入特征,生成的精细的attention特征。
首先,self-attention将输入词嵌入和位置编码之和作为输入,通过训练的线性层为每个单词计算3个向量: q u e r y 、 k e y query、key query、key和 v a l u e value value。然后可以通过匹配(点积)查询和 k e y key key向量来获取任意两个word之间的attention权重。最后,attention feature定义为所有value向量和attention权重的加权和。显然,每个word的输出attention feature与所有的输入特征相关,因此能够学习全局上下文。Transformer的所有操作均可并行执行与顺序无关,理论上讲,可以替代CNN计算中的卷积运算,并且有更好的通用性。
PCT的核心思想是通过使用transformer的固有顺序不变性来避免定义点云数据的顺序,以及通过attention机制来进行特征学习。如图1所示,attention权值的分布与部分语义高度相关,并没有随着空间距离严重衰减。
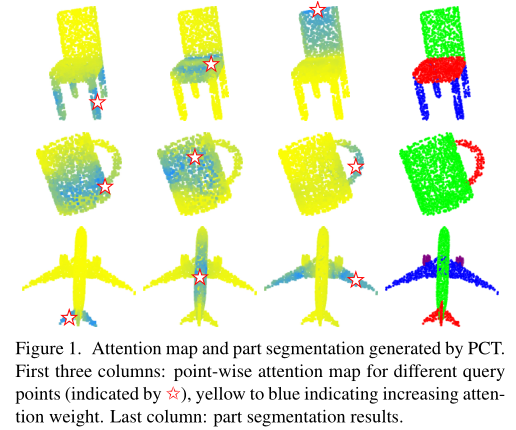
因为点云数据和自然语言数据截然不同,PCT对其进行了一系列调整。
- 基于坐标的输入嵌入模块。Transformer使用了位置编码模块来表示自然语言中的单词顺序。这样可以区分不同位置的相同单词,反映单词间的位置关系。然而,点云没有固定的顺序。因此在PCT框架中,作者将原始的位置编码和输入嵌入合并到一个基于坐标的输入嵌入模块。它可以生成可区分的特征,因为每个点都有表示其空间位置的唯一的坐标。
- 优化的偏移attention模块。作者提出的偏移attention模块方法是对原有的self-attention的有效升级。它的工作原理是用self-attention模块的输入与attention特征之间的偏移量来替代attention特征。首先,绝对坐标通过刚性变换转换成相对坐标通常更加鲁棒。其次,拉普拉斯矩阵(度矩阵和邻接矩阵的偏移量)在图卷积学习中是非常有效的。从这个角度可以将点云看作一个图形,将“float"邻接矩阵作为attention graph。同样,作者将每行的总和缩放为1。因此度矩阵可以被看作恒等矩阵。因此,偏移attention优化过程可以近似理解为拉普拉斯过程(3.3)。此外,作者对第四节中介绍的偏移attention和self-attention做了大量对比实验来证明其有效性。
- 邻近嵌入模块。显然,句子中的每个单词都包含基本的语义信息。但是这些点的独立输入坐标与语义内容之间的关系很弱。attention机制可以有效地捕获全局特征,但可能会忽略局部几何信息,而这也是点云学习中必不可少的。为了解决这一问题,作者在点嵌入的基础上采用了邻近嵌入策略(point embedding)。它还通过考虑包含语义信息的局部点组而不是单个点之间的attention来辅助attention模块。
贡献:
- 提出了基于transformer的点云学习PCT框架。
- 提出了带有隐式拉普拉斯算子和归一化修正的偏移attention,与self-attention相比,更适合点云学习。
- 大量实验表明,具有局部上下文增强效果的PCT在形状分类、零件分割和法线估计任务方面达到了SOTA效果。
2.相关工作
2.1 Transformer in NLP
Bahdanau等人最早提出带有attention机制的神经机器翻译方法,该方法的attention权重通过RNN的隐藏层计算。LIn 等人提出 self-attention,用来可视化和解释句子嵌入。在这之后出现了用于机器翻译的transformer,它完全是基于self-attention的,无任何重复和卷积运算符。之后又出现了 BERT(双向 transformer),这是 NLP 领域中最强大的模型之一。最近,诸如 XLNet,Transformer-XL 和 BioBERT 之类的语言学习网络进一步扩展了 Transformer 框架。
但是,在自然语言处理中输入是有序的,单个的单词有基本的语义,点云中的点是无序的并且单个点无语义信息。
2.2 Transformer for vision
PCT借鉴了ViT中的局部补丁结构和单词的基本语义信息,提出了一个临近嵌入模块,该模块可以聚合来自点的局部邻域的特征,从而捕获局部信息并获得语义信息。
2.3 Point-based deep learning
一些方法也采用attention和transformer。PointASNL利用一种自注意机制来更新局部点组的特征,用以处理点云中的噪声。PointGMM用于形状插值的多层感知器(MLP)分割和attention分割。PCT基于transformer,而不是self-attention作为辅助模块,是一个更通用的框架,可以用于各种点云任务。
3.Transformer for Point Cloud Representation
在本节中将介绍如何将PCT学习到的点云表示应用于点云处理的各种任务,包括点云分类、部分分割和正态估计。然后,将详细介绍PCT的设计,首先介绍了一个naive版本的PCT,它将原来的transformer应用到点云上。接着,再使用特殊的attention机制来解释完整的PCT,以及提供增强的本地信息的邻居聚合。
3.1. Point Cloud Processing with PCT
Encoder. PCT的整体架构如图2所示。PCT旨在将输入点转换到一个新的高维特征空间,该空间可以表征点之间的语义相似性,为各种点云处理任务提供基础。PCT的编码器首先将输入坐标嵌入到一个新的特征空间中。然后将嵌入的特征输入4个堆叠的attention模块,学习每个点的语义性的丰富且有区别的表示,然后用一个线性层生成输出特征。总体而言,PCT的编码器与原始Transformer的设计理念几乎相同,只是位置嵌入被丢弃了,因为点的坐标已经包含了这一信息。
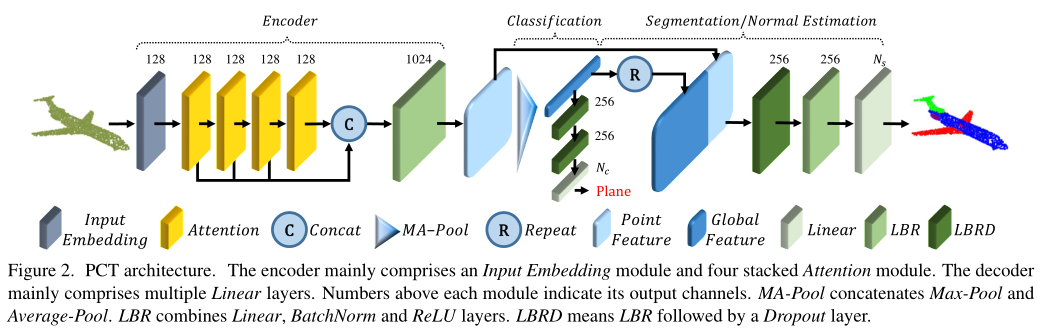
输入点云( N × d N×d N×d,N个点,每个点有d维特征描述)。首先通过Input Embedding模块学习 d e d_e de维嵌入特征 F e ∈ R N × d e F_e \in R^{N×d_e} Fe∈RN×de,然后通过每个attention层进行级联,再进行线性变换来形成 d 0 d_0 d0维特征 F 0 ∈ R N × d 0 F_0 \in R^{N×d_0} F0∈RN×

