
- 1快速搞定docker部署Filebeat、Elasticsearch、Logstash与Kibana_docker-compose构建filebeat + logstash +elasticsearch
- 2Android 的界面切换方法_android11 如何切换桌面模式 不要上划进入二级菜单
- 3Ubuntu系统查看显卡型号NVIDIA Corporation [10DE:1E82] -display UNCLAIMED
- 4C#学习教程10——文件操作_using (filestream fs = file.create(path))
- 5事务隔离(脏读、幻读与不可重复读)_isolation_repeatable_read
- 6新手安装node.js并build vue_node 怎么build
- 7【目标检测】Grounding DINO:开集目标检测器(CVPR2023)_groundingdino
- 8如果开了多个模拟器,那么如何知道每个模拟器对应的端口号_模拟器多开会有几个端口?
- 9架构设计内容分享(一百三十六):Spring AI 项目简介_spring-ai
- 10linux修改rc.local权限,CentOS7中rc.local中的指令不能生效问题。
MapReduce编程:单词计数--《大数据基础教程》_mapreduce单词计数
赞
踩
MapReduce编程:单词计数
1、实验描述
- 使用mapreduce编程,完成单词计数
- 实验时长:90分钟
- 主要步骤:
- 启动Hadoop集群
- 编写代码
- 打包程序,并提交至HDFS运行
- 查看实验结果文件
2、实验环境
- 虚拟机数量:3
- 系统版本:Centos 7.5
- Hadoop版本:Apache Hadoop 2.7.3
- Eclipse版本:Neon.3 4.6.3
3、相关技能
- JavaSE基础
- MapReduce编程
4、相关知识点
- 配置开发环境
- 编写Mapper类
- 编写Reducer类
- 编写main函数
- 程序打jar包
- 将jar包运行在hadoop集群上
5、实现效果
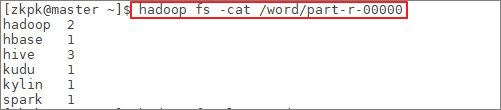
- 效果图:展示结果为成功对文件中的单词进行了单词计数
6、实验步骤
6.1进入虚拟机并启动Hadoop集群
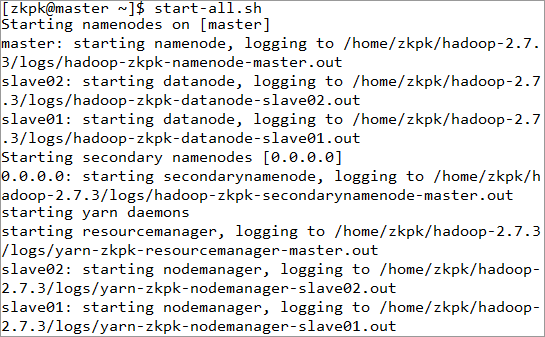
6.1.1在master启动Hadoop集群
[zkpk@master ~]$ start-all.sh
- 1
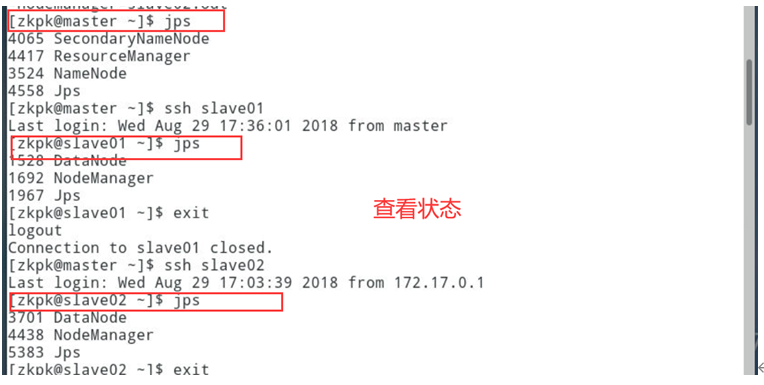
6.1.2在master上运行jps,确认NameNode, SecondaryNameNode, ResourceManager进程启动
6.1.3在slave01上运行jps,确认DataNode, NodeManager进程启动
6.1.4在slave02上运行jps,确认DataNode, NodeManager进程启动
6.2启动Eclipse客户端
[zkpk@master ~]$ cd eclipse/[zkpk@master eclipse]$ ./eclipse
- 1
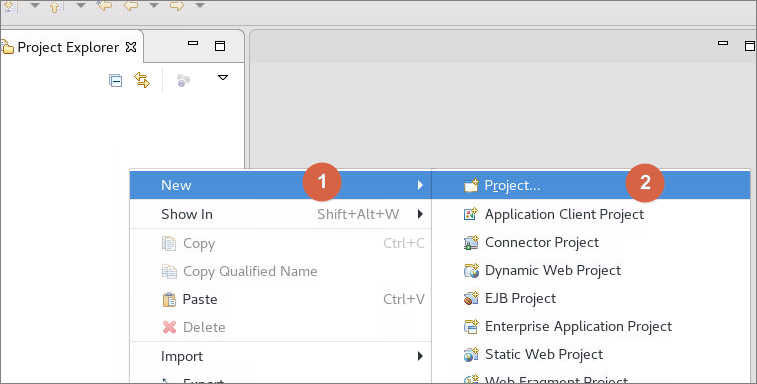
6.3在Eclipse客户端主界面中左侧空白处右击,依次选择New->Project,选择Java Project点击Next
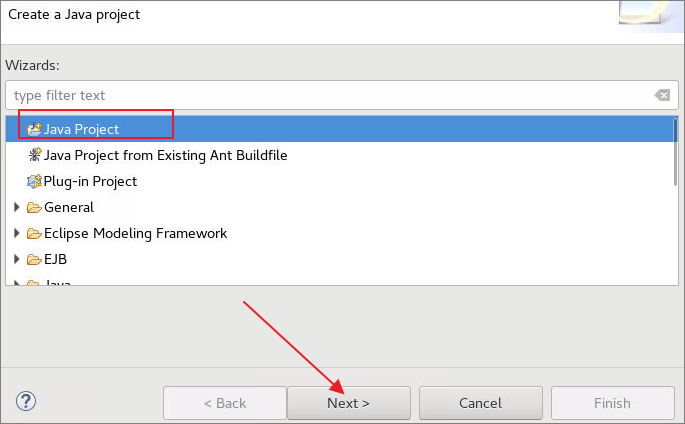
6.3.1在弹出的对话框中定义工程名为hadoop,然后点击Finish完成创建,弹出询问是否将Java Project设置为常用工程项目时,点击Yes即可
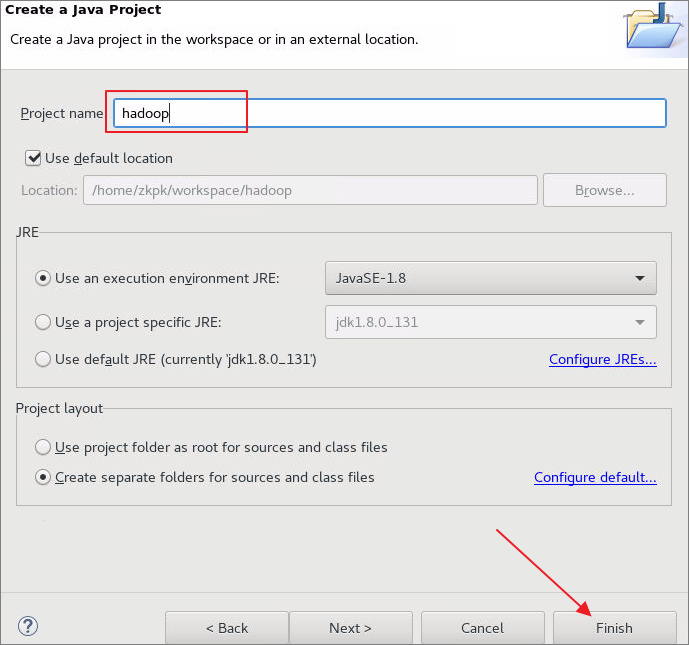
6.3.2在工程名上单击鼠标右键点击依次选择Build Path ->Configure Build Path
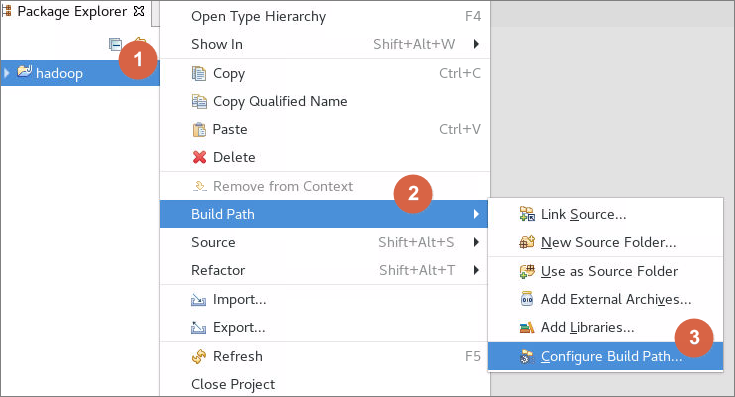
6.3.3在弹出窗口中,进入Libraries模块,再点击Add External Jars导入实验相关jar包
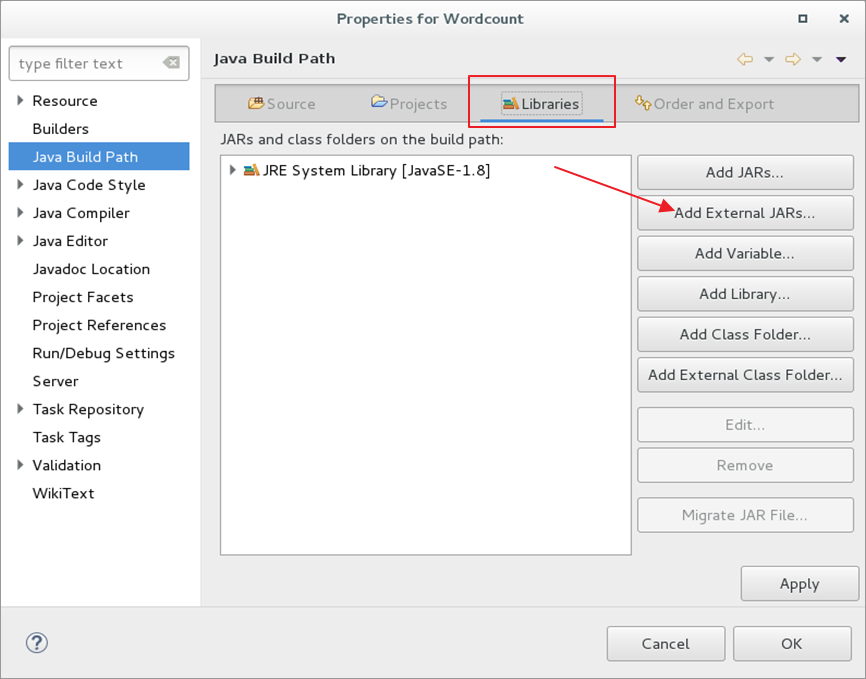
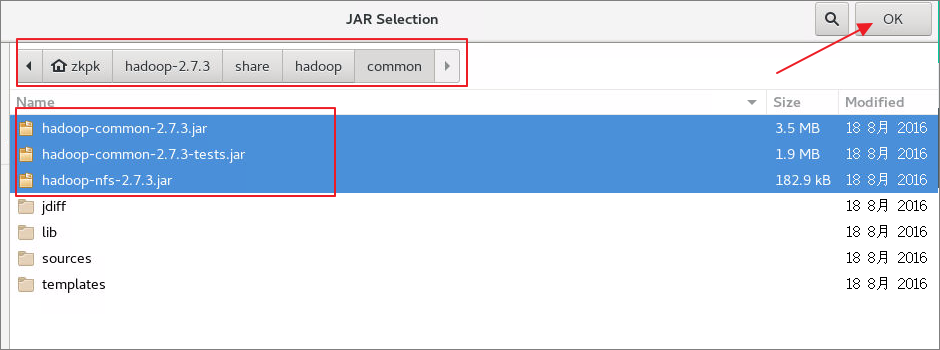
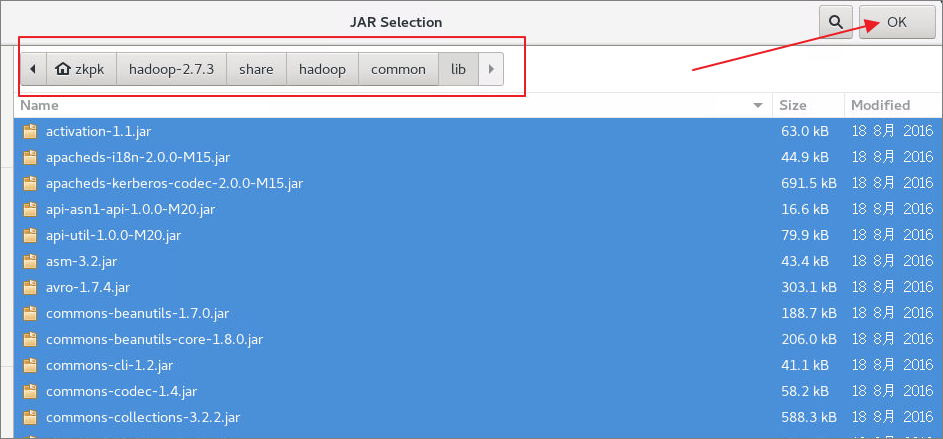
6.3.4将hadoop主目录中的share/hadoop/common中的jar包导入,然后再次点击Add External JARs将share/hadoop/common/lib文件夹中的所有jar包导入
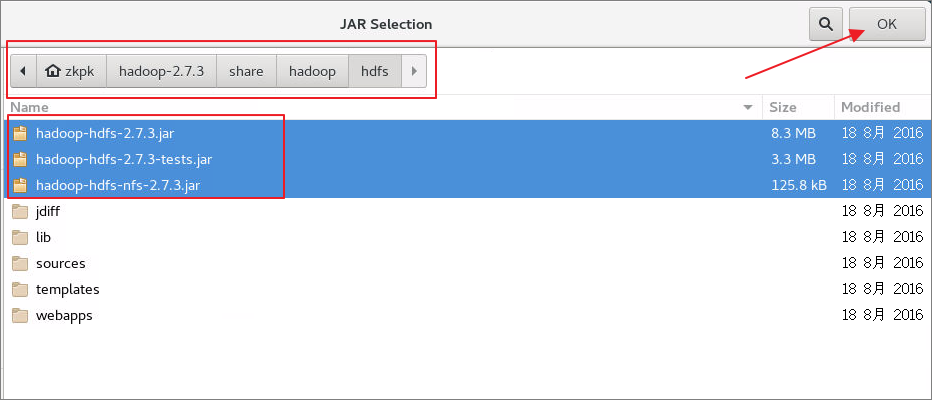
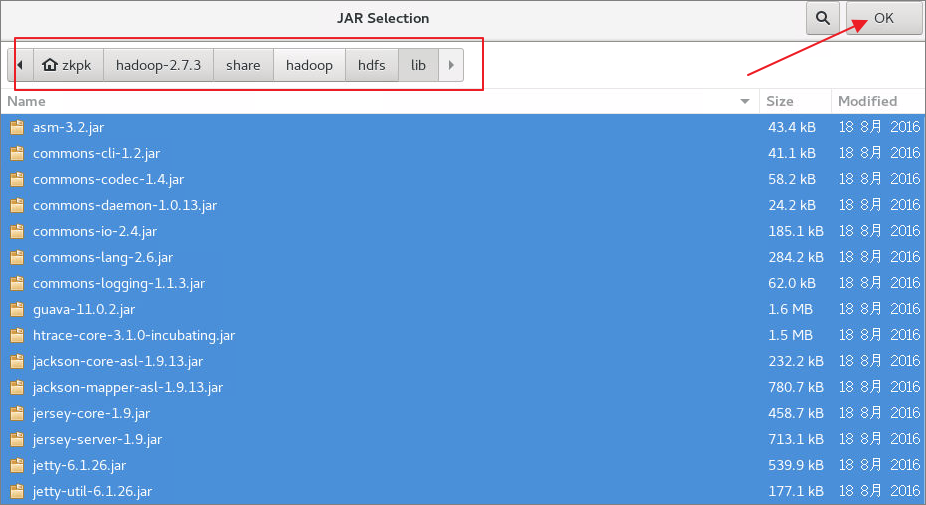
6.3.5将hadoop主目录中的share/hadoop/hdfs中的jar包导入,然后再次点击Add External JARs将share/hadoop/hdfs/lib文件夹中的所有jar包导入
6.3.6将hadoop主目录中的share/hadoop/mapreduce中的jar包导入,然后再次点击Add External JARs将share/hadoop/mapreduce/lib文件夹中的所有jar包导入

6.3.7将hadoop主目录中的share/hadoop/yarn中的jar包导入,然后再次点击Add External JARs将share/hadoop/yarn/lib文件夹中的所有jar包导入
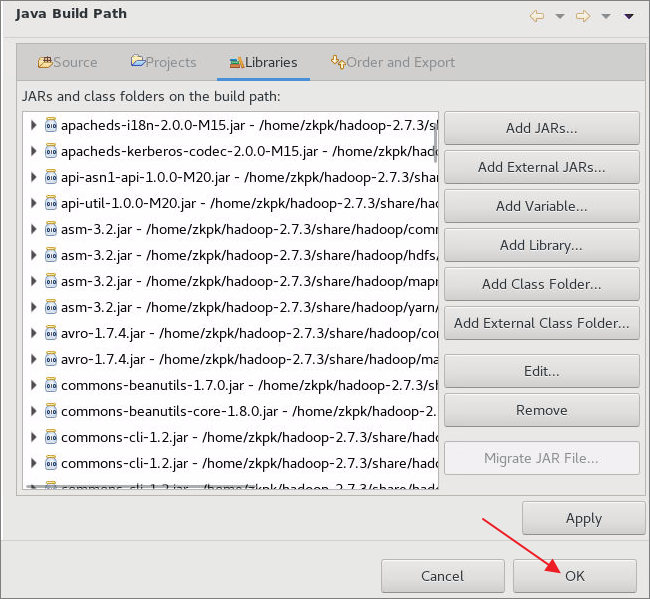
6.3.8所有jar包导入完成,在Build Path点击OK按钮完成环境配置
6.4创建Wordcount的Mapper类
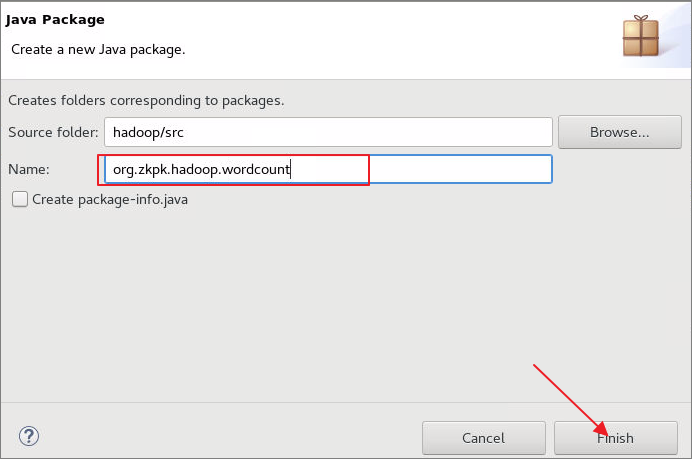
6.4.1首先在工程目录中的src文件夹上右击,依次选择New->Package,创建名字是org.zkpk.hadoop.wordcount的package
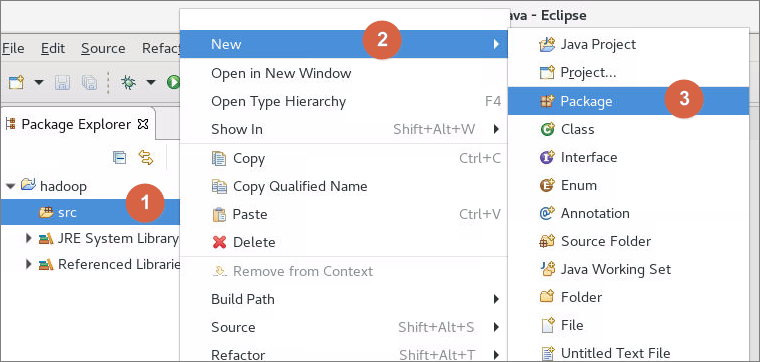
6.4.2右键点击Package包名,依次选择New->Class,在此package中创建mr编程中的mapper类
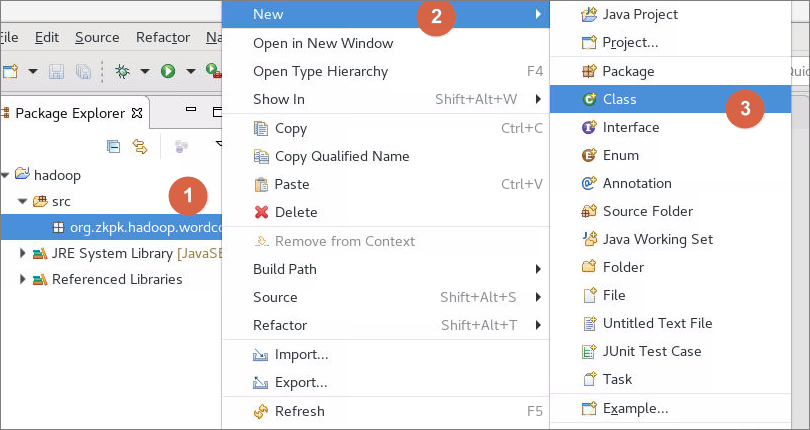
6.4.2.1弹出对话框,定义类名为WordMap
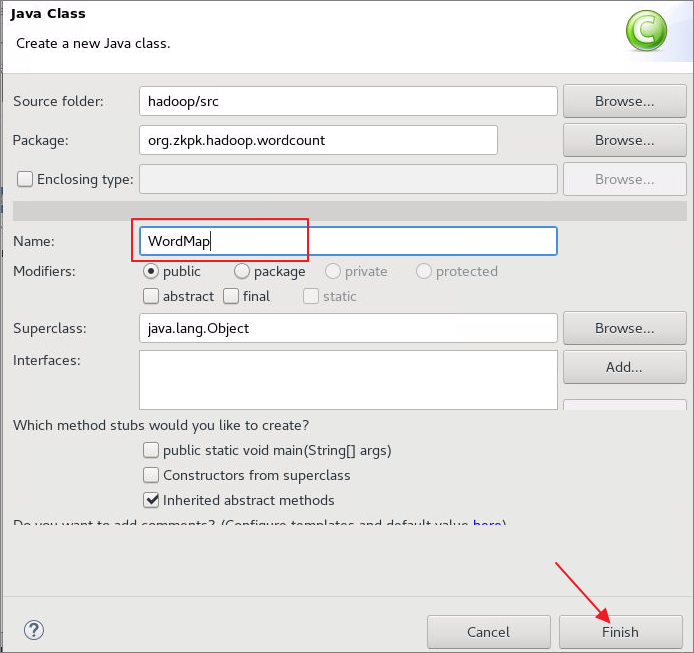
6.4.2.2WordMap类继承Mapper类,Mapper类的输入键值对中键是Object类型,值是Text类型;输出键值对中键是Text类型,值是IntWritable类型

6.4.3覆写Mapper类中的map方法

6.4.3.1map方法第一个参数key表示当前所读的这一行数据行首的文本偏移量
6.4.3.2第二个参数value表示当前所读的这一行文本
6.4.3.3在map方法中编写代码读取数据的每一行,将value转换成string类型,再按照字段之间的分隔符进行切分,得到一个字符串数组

6.4.3.4使用for循环对单词数组进行遍历,将每次遍历得到的单词包装成Text类型,1包装成Intwritable类型,分别作为输出的key和value

6.5创建Wordcount中的Reduce类
6.5.1右键点击包名,依次选择New->Class,在名为org.zkpk.hadoop.wordcount的package中创建reducer类
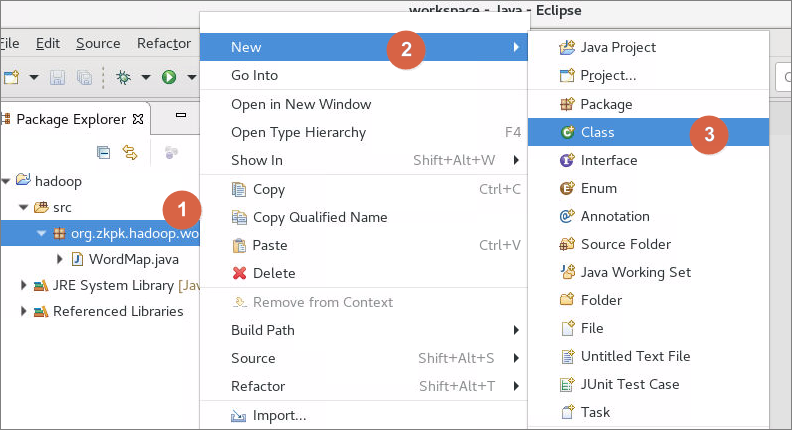
6.5.1.1弹出对话框,定义类名为WordReduce,点击Finish完成创建
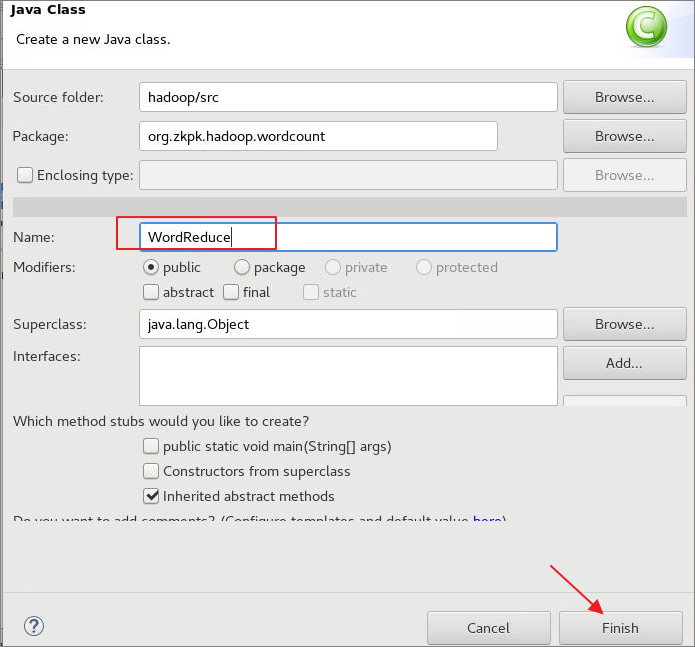
6.5.1.2WordReduce类继承Reducer类,Reducer类的输入键值对中键是Text类型,值是IntWritable类型(与Mapper输出的键值对类型分别一致);输出键值对中键是Text类型,值是IntWritable类型

6.5.2覆写Reducer类中的reduce方法

6.5.2.1reduce会将相同key的键值对汇聚到一个reduce task中
6.5.2.2第一个参数key表示单词,类型对应Mapper的输出key类型
6.5.2.3第二个参数Values表示当前key对应的所有value集合,集合元素类型对应于Mapper的输出value类型
6.5.2.4对values进行遍历,将每次遍历的数值进行累加到一个变量,例如:sum

6.5.2.5结束遍历,将参数key作为输出的键值对中的键,将sum包装成IntWritable类型作为输出键值对中的值,使用context的write方法写出

6.6创建Wordcount中包含main方法的类
6.6.1右键点击包名依次选择New->Class,在名为org.zkpk.hadoop.wordcount的package中创建包含MapReduce的main方法的类

6.6.1.1定义类名为WordMain
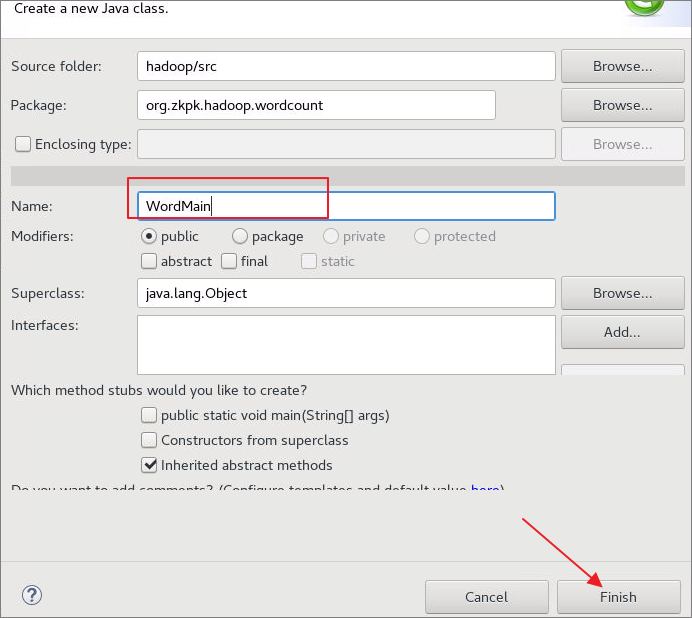
6.6.1.2在类WordMain中创建main方法,在main方法中使用if语句判断传入的参数格式是否正确,如果不正确则退出程序(这里我们的代码需要接受两个参数作为输入和输出路径)

6.6.1.3生成Configuration类型对象

6.6.1.3利用Configuration对象生成job对象

6.6.1.4调用job的setJarByClass方法设置job运行主类

6.6.1.5通过setInputFormatClass方法设置job输入格式,setOutputFormatClass方法设置job输出格式

6.6.1.6通过setInputPaths、setOutputPath方法设置job的输入、输出路径

6.6.1.7通过setMapperClass、setReducerClass方法设置Map/Reduce阶段的类

6.6.1.8通过setOutputKeyClass、setOutputValueClass方法设置最终输出key/value的类型

6.6.1.9通过waitForCompletion方法提交job

6.7程序打jar包
6.7.1右击工程名,点击export,在弹出窗口中,选择java的 JAR file点击Next,如图:
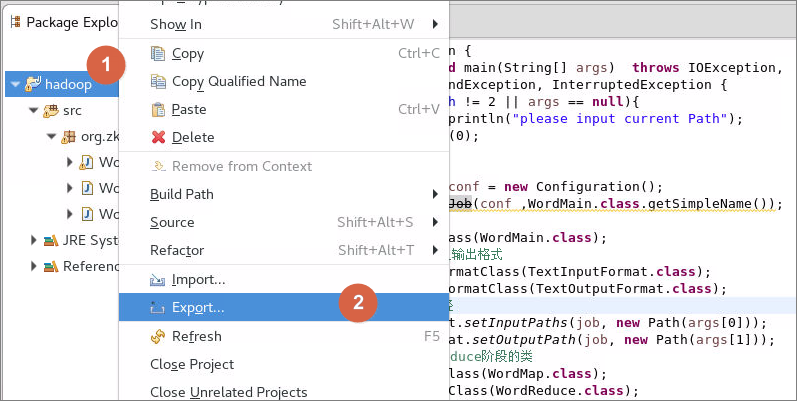
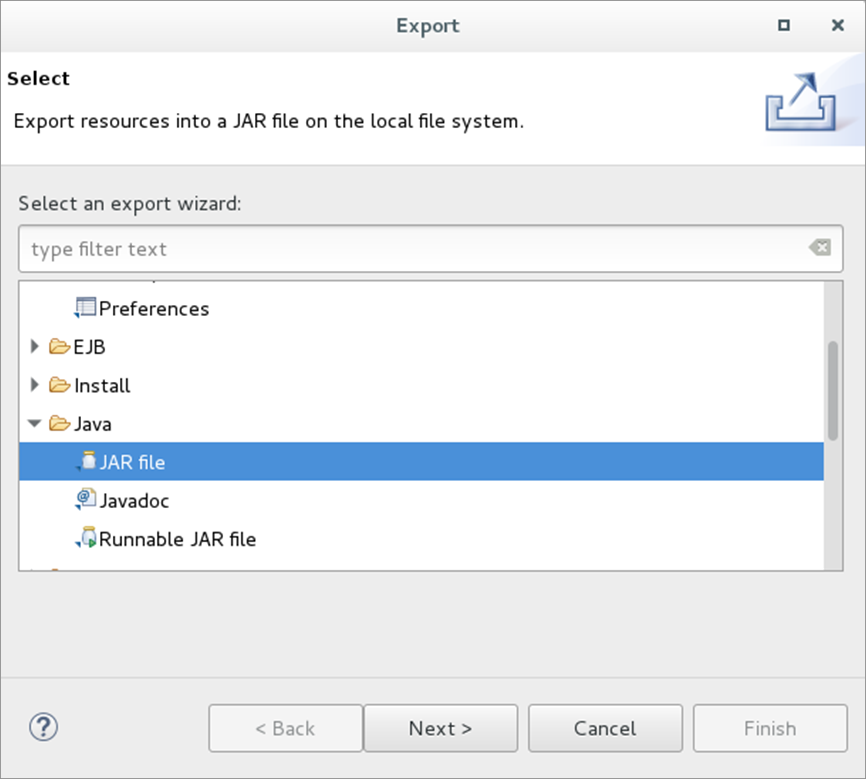
6.7.2指定导出的jar包的位置及名字然后点击Finish,如图:
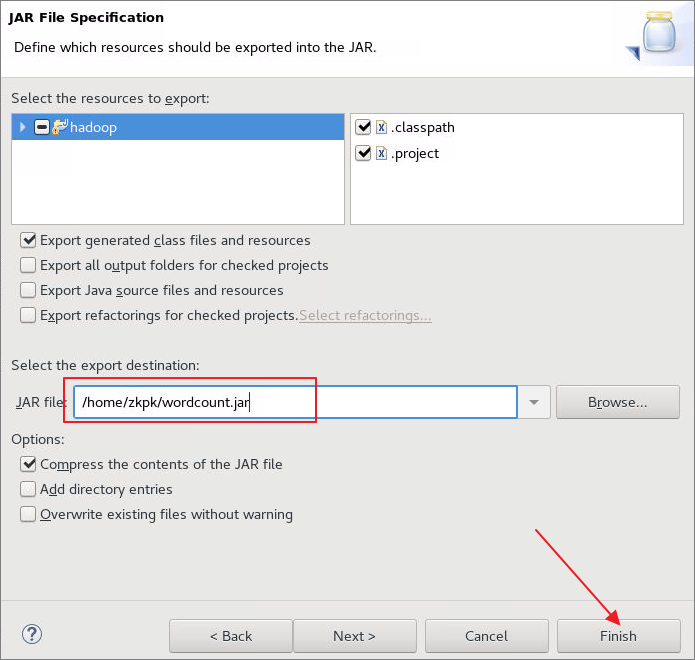
6.7.3导出完成后,关闭eclipse然后返回指定目录查看,如图所示

6.8运行jar包
6.8.1上传输入数据
6.8.1.1从Hadoop的公共目录下拷贝数据文件test.txt到/home/zkpk
[zkpk@master ~]$ cp ~/experiment/test.txt ~/
- 1
6.8.1.2将上一步拷贝的数据文件test.txt上传到HDFS的根目录
[zkpk@master ~]$ hadoop fs -put /home/zkpk/test.txt /
- 1
6.8.2查看是否上传成功
[zkpk@master ~]$ hadoop fs -ls /
- 1

6.8.3运行jar包,指定包名及主类名,然后指定输入路径参数和输出路径参数(该参数都是在HDFS上,且输出路径即word文件夹不能够已存在)
[zkpk@master ~]$ hadoop jar /home/zkpk/wordcount.jar org.zkpk.hadoop.wordcount.WordMain /test.txt /word
- 1
6.8.4查看输出目录
[zkpk@master ~]$ hadoop fs -ls /word/
- 1

6.8.5查看输出结果
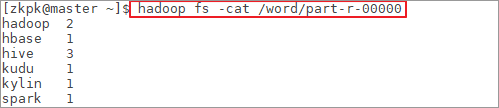
[zkpk@master ~]$ hadoop fs -cat /word/part-r-00000
- 1
7、参考答案
- 代码清单org.zkpk.hadoop.wordcount.WordMain

- 代码清单org.zkpk.hadoop.wordcount.WordMap
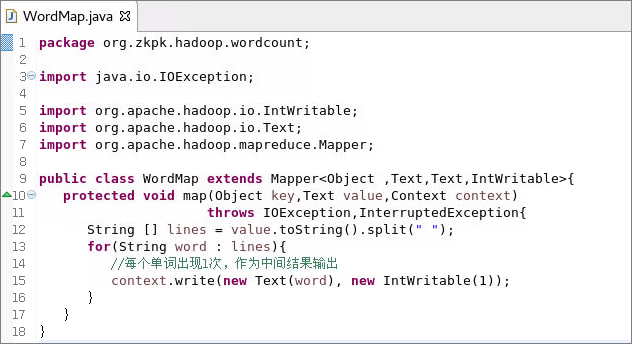
图 53
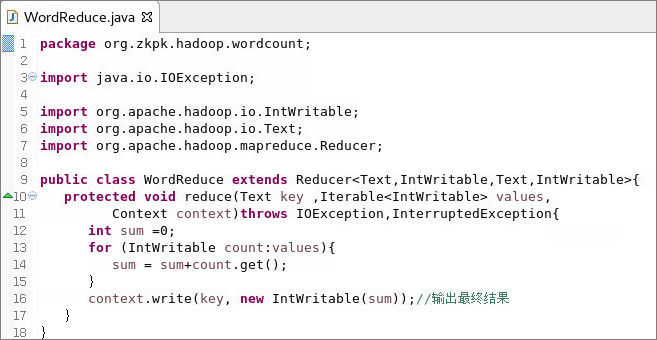
- 代码清单org.zkpk.hadoop.wordcount.WordReduce
8、总结
完成本实验可掌握用mapreduce计算框架对数据做基本分布式处理。


