
- 1java 前端加密后端解密_前端登陆加密和后端解密
- 2NLP的学习笔记(1)_基于统计方法的哲学基础的理性主义方法
- 3OpenStack介绍(及资源)
- 4python使用requests模块下载文件并获取进度提示
- 5C++从入门到精通——auto的使用
- 6激活函数小结:ReLU、ELU、Swish、GELU等_swigelu
- 7[机器学习] 第二章 模型评估与选择 1.ROC、AUC、Precision、Recall、F1_score_怎样在真阳率限制的情况下选择模型
- 8Linux——线程概念与线程的创建
- 9【证明】期望风险最小化等价于后验概率最大化_期望风险最小化 后验概率最大化
- 10osg 倾斜数据纹理_高科技构筑逼真效果——无人机倾斜摄影技术在实景三维建模的应用及展望...
判断随机抽取代码_中文知识图谱-领域词抽取
赞
踩
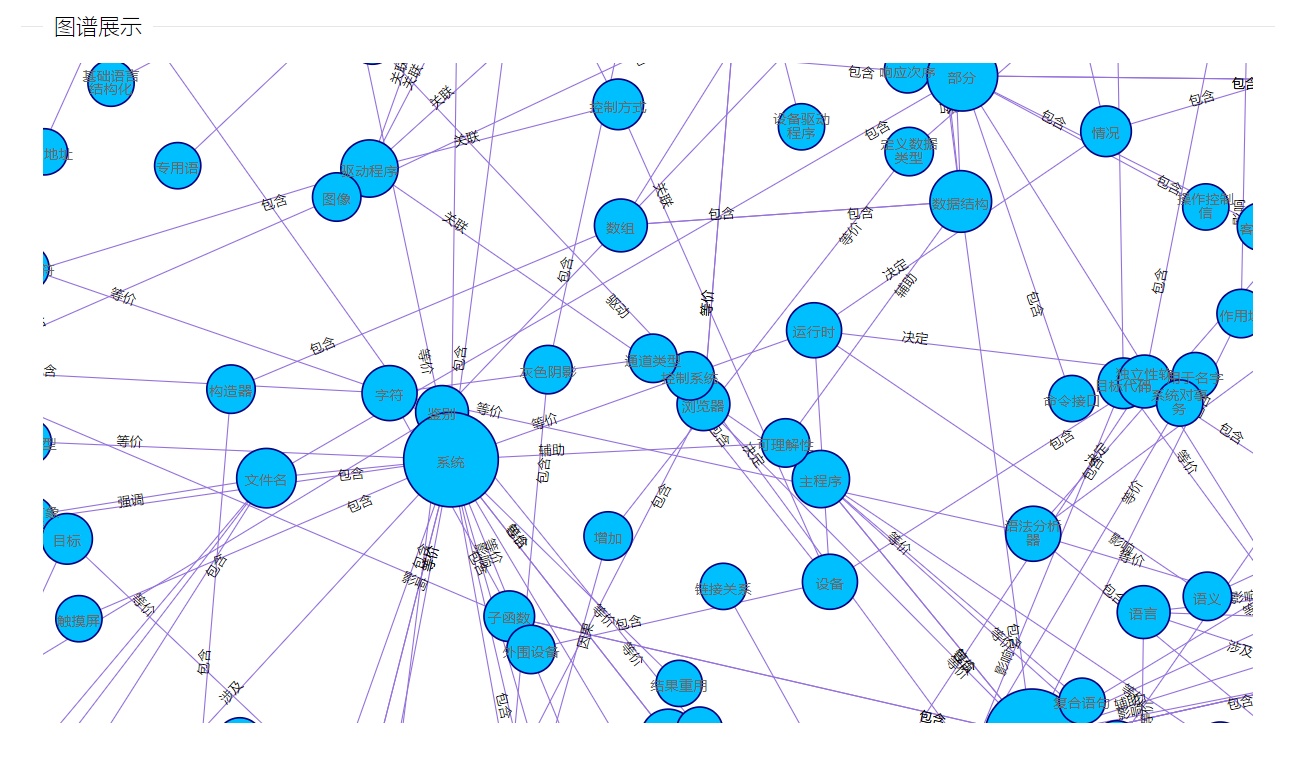
本文章为博主本人的项目总结,欢迎各位大佬沟通交流。
领域词分类代码:
LiuYaKu/Word_classificationgithub.com
数据构建代码:
LiuYaKu/baidu_make_datagithub.com
任务定义
从无结构文本(中文)中抽取领域词(某个领域内的专有词汇),无监督型数据。
方案设计
新词发现+词分类+词性规则+远程监督
新词发现
所谓的新词发现,就是发现词典里面没有的词,采用的方法就是互信息与左右信息熵抽取新词,简单说来就是计算几个词组合成一个词的概率。
互信息
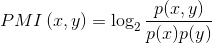
点间互信息就是计算两个词的粘合程度。
左右信息熵
左熵
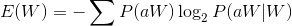
左右信息熵即候选词左右两边词的变化情况,变化越多,熵值越大,候选词成词的分数越大。
新词发现结果

“_”两边是组合的两个词。注意:这里不仅可以是2-gram,也可以是n-gram,即判断两个或者n个词的组词概率,但是n越大,所耗费的时间也越大(顺便说一句:高瞻远瞩公司真的是领域词,吃惊.jpg)。逗号右边是评分。
词分类
模型任务
新词有了,现在的任务是从这些新词中找出领域词即可。从上面的结果可以发现抽取出来的领域词,分为三类:领域词(高瞻远瞩公司)、非领域词(马利奥)、非正常词(先力时)。
为了简单起见,模型任务是二分类,即只有两个分类:领域词和非领域词(包含非领域词和非正常词)。
数据构建
现在模型任务确定了,那么下一步就是构造数据,全部依靠人工肯定不行,我们的方案采用远程监督+规则+少量人工的方式构造数据。
正样本构建:即领域词
两个途径:
1、从百度文库爬取领域大牛总结的领域词,只要是不太冷门的领域,都会有领域大牛总结领域词。
2、利用百度百科的词条,将新词发现的结果,逐个在百度百科里查询,如果在百度百科里面,那么就当做是候选领域词,然后再人工筛选。(在百度百科查询的部分可以使用脚本实现)。
负样本构建:即非领域词和非正常词
通用方法:每个领域都有构词法,我们使用的是词性对规则,比如a_a,形容词_形容词肯定不是领域词,使用jieba词典标注的词性。


非领域词:即是正常词但不是领域词的词,比较好找,使用jieba词典里面的词,随机抽取出一些(里面会含有一些领域词,抽取的时候需要制定规则,比如不包含某些字的词),还可以找一些其他领域内的词。
非正常词:使用规则,构造一些非正常词,用字随机组词。
最终正样本:1万5000多个
最终负样本:120万左右
模型选择
模型的选择,我尝试了四种模型:1.cnn+char2vec 2.lstm+char2vec 3.lstm+cnn+char2vec 4.bert
效果依次变好,但是需要的硬件水平也依次提高。
数据噪声问题
由于构建数据集部分存在问题,比如词性对规则部分需要领域专家如果是非领域人员整理的话,那么就会给数据集引入噪音。
解决方法:使用循环训练,测试负样本,将其中的领域内的词去掉。
具体流程就是每次训练一个模型,训练完之后测试负样本,将负样本中分数较高的词,直接从训练样本中除去。
领域词分类代码:
LiuYaKu/Word_classificationgithub.com
数据构建代码:
LiuYaKu/baidu_make_datagithub.com


