
- 1GET请求使用@RequestBody的正确姿势_get requestbody
- 2List Feature ID_feature-list-id
- 3使用 FasterTransformer 和 Triton 推理服务器加速大型 Transformer 模型的推理
- 4Elasticsearch:向量搜索 (kNN) 实施指南 - API 版_elastic knn and fliter
- 5详解舵机的基本原理以及控制方法_舵机工作原理与控制方法
- 6详细讲解Android Studio中使用Git——结合GitLab_androidstudio gitlab
- 7Java选择题(二十八)_java中非runtimeexception体系包括错误的类型转换、数组越界
- 8[转]在Controller中获取request和response对象的五种方式,分析各自的线程安全性_controller获取request
- 9leetcode-1379-找出克隆二叉树中的相同节点-medium_java 找出克隆二叉树中的相同节点
- 10一文读懂「Prompt Engineering」提示词工程
NLP笔记(9)——小白实现GPT中文对话系统_nlp gpt
赞
踩
之前的文章在我们介绍了如何搭建seq2seq模型、卷积神经网络、Tranformer等一系列,今天给大家带来基于Pytorch实现的小型GPT中文对话系统。文末获取代码及生成训练好的权重文件。

一.GPT模型介绍
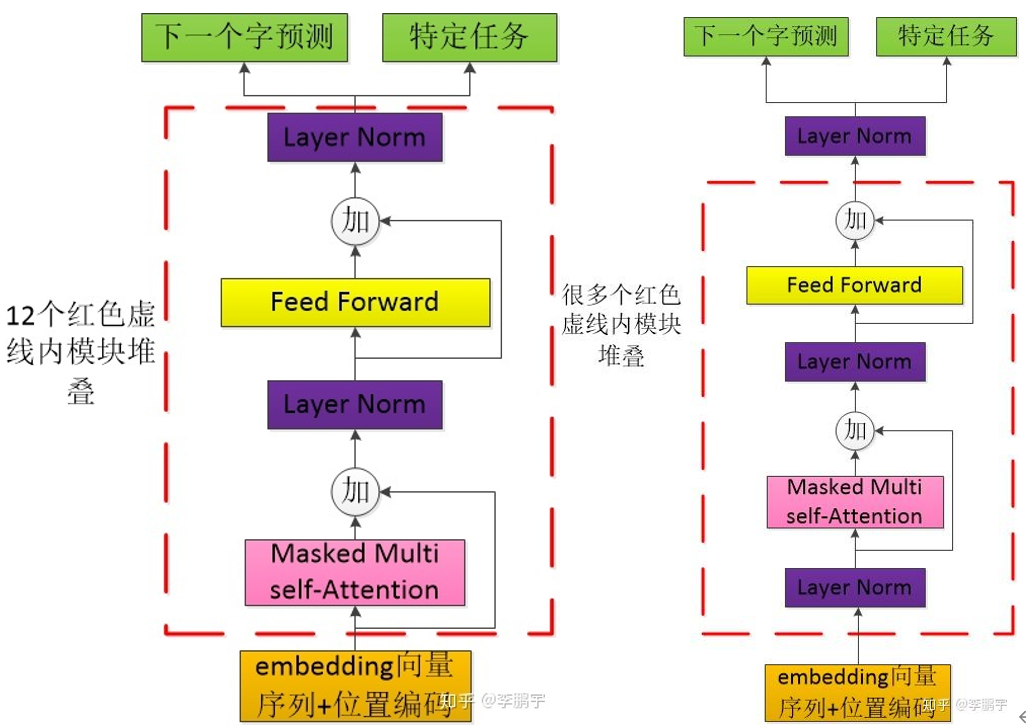
GPT也是一种预训练模型,与BERT不同的是,它采用的是Transformer的Decoder结构。它的训练过程与BERT类似,首先在大量未标记的数据上进行预训练,然后在少量标记数据上进行微调以训练下游模型。在微调过程中,只需要构建与任务相关的输入,而不需要太多地改变模型的架构。本次用的是GPT-2模型。相比GPT-1,GPT-2的layer norm位于“子层”(多头注意力和全连接层)之前;GPT-2在最后一个Transformer的输出那里,增加了一个layer norm。下图左为GPT-1,右为GPT-2。
使用的模型是基于Transformer的Decoder解码器。与编码器不同的是,解码器在计算注意力机制时会添加一个掩码mask。这个掩码使得模型在计算某个词的自注意力时无法看到该词后面的内容,只能依靠前面的词来提取信息。而编码器没有掩码,它可以看到整个序列的所有信息,在计算某个词的自注意力时,可以考虑整个序列。BERT使用的是Encoder,因此它可以用于完形填空任务,通过提取前后词的信息来预测中间的词。而GPT只能预测后面的词。由于预测未来比预测中间要困难得多,这导致了GPT的效果不如BERT。模型的计算公式如下:
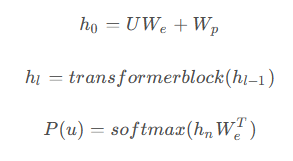
二.GPT实现中文对话系统
1.数据集及源码
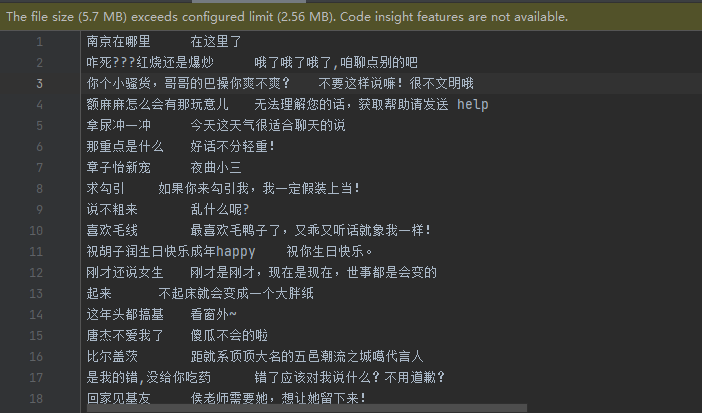
青云数据集,开放域,12万条对话:https://github.com/skyerhxx/Chatbot
2.完整步骤
(1)生成字典信息
- """
- get_vocab.py 生成字典信息
- """
- import json
- def get_dict(datas):
- word_count ={}
- for data in datas:
- data = data.strip().replace('\t','')
- for word in data:
- word_count.setdefault(word,0)
- word_count[word]+=1
- word2id = {"<pad>":0,"<unk>":1,"<sep>":2}
- temp = {word: i + len(word2id) for i, word in enumerate(word_count.keys())}
- word2id.update(temp)
- id2word=list(word2id.keys())
- return word2id,id2word
- if __name__ == '__main__':
- with open('data/qingyun.txt', 'r', encoding='utf-8') as f:
- datas = f.readlines()
- word2id, id2word = get_dict(datas)
- dict_datas = {"word2id":word2id,"id2word":id2word}
- json.dump(dict_datas, open('data/dict_qingyun.json', 'w', encoding='utf-8'))

(2)搭建模型
- """
- 该文件是GPT模型的实现,如果看不懂建议先去了解一下Transformer代码
- """
- import json
- import torch
- import torch.utils.data as Data
- from torch import nn, optim
- import numpy as np
- import time
- from tqdm import tqdm
-
- device = torch.device("cuda")
- dict_datas = json.load(open('data/dict_qingyun.json', 'r'))
- word2id, id2word = dict_datas['word2id'], dict_datas['id2word']
- vocab_size = len(word2id)
- max_pos = 1800
- d_model = 768 # Embedding Size
- d_ff = 2048 # FeedForward dimension
- d_k = d_v = 64 # dimension of K(=Q), V
- n_layers = 6 # number of Encoder of Decoder Layer
- n_heads = 8 # number of heads in Multi-Head Attention
- CLIP = 1
-
-
- def make_data(datas):
- train_datas = []
- for data in datas:
- data = data.strip()
- train_data = [i if i != '\t' else "<sep>" for i in data] + ['<sep>']
- train_datas.append(train_data)
-
- return train_datas
-
-
- class MyDataSet(Data.Dataset):
- def __init__(self, datas):
- self.datas = datas
-
- def __getitem__(self, item):
- data = self.datas[item]
- decoder_input = data[:-1]
- decoder_output = data[1:]
-
- decoder_input_len = len(decoder_input)
- decoder_output_len = len(decoder_output)
-
- return {"decoder_input": decoder_input, "decoder_input_len": decoder_input_len,
- "decoder_output": decoder_output, "decoder_output_len": decoder_output_len}
-
- def __len__(self):
- return len(self.datas)
-
- def padding_batch(self, batch):
- decoder_input_lens = [d["decoder_input_len"] for d in batch]
- decoder_output_lens = [d["decoder_output_len"] for d in batch]
-
- decoder_input_maxlen = max(decoder_input_lens)
- decoder_output_maxlen = max(decoder_output_lens)
-
- for d in batch:
- d["decoder_input"].extend([word2id["<pad>"]] * (decoder_input_maxlen - d["decoder_input_len"]))
- d["decoder_output"].extend([word2id["<pad>"]] * (decoder_output_maxlen - d["decoder_output_len"]))
- decoder_inputs = torch.tensor([d["decoder_input"] for d in batch], dtype=torch.long)
- decoder_outputs = torch.tensor([d["decoder_output"] for d in batch], dtype=torch.long)
-
- return decoder_inputs, decoder_outputs
-
-
- def get_attn_pad_mask(seq_q, seq_k):
- '''
- seq_q: [batch_size, seq_len]
- seq_k: [batch_size, seq_len]
- seq_len could be src_len or it could be tgt_len
- seq_len in seq_q and seq_len in seq_k maybe not equal
- '''
- batch_size, len_q = seq_q.size()
- batch_size, len_k = seq_k.size()
- # eq(zero) is PAD token
- pad_attn_mask = seq_k.data.eq(0).unsqueeze(1) # [batch_size, 1, len_k], True is masked
- return pad_attn_mask.expand(batch_size, len_q, len_k) # [batch_size, len_q, len_k]
-
-
- def get_attn_subsequence_mask(seq):
- '''
- seq: [batch_size, tgt_len]
- '''
- attn_shape = [seq.size(0), seq.size(1), seq.size(1)]
- subsequence_mask = np.triu(np.ones(attn_shape), k=1) # Upper triangular matrix
- subsequence_mask = torch.from_numpy(subsequence_mask).byte()
- subsequence_mask = subsequence_mask.to(device)
- return subsequence_mask # [batch_size, tgt_len, tgt_len]
-
-
- class ScaledDotProductAttention(nn.Module):
- def __init__(self):
- super(ScaledDotProductAttention, self).__init__()
-
- def forward(self, Q, K, V, attn_mask):
- '''
- Q: [batch_size, n_heads, len_q, d_k]
- K: [batch_size, n_heads, len_k, d_k]
- V: [batch_size, n_heads, len_v(=len_k), d_v]
- attn_mask: [batch_size, n_heads, seq_len, seq_len]
- '''
- scores = torch.matmul(Q, K.transpose(-1, -2)) / np.sqrt(
- d_k) # scores : [batch_size, n_heads, len_q, len_k]
- scores.masked_fill_(attn_mask, -1e9) # Fills elements of self tensor with value where mask is True.
-
- attn = nn.Softmax(dim=-1)(scores)
- context = torch.matmul(attn, V) # [batch_size, n_heads, len_q, d_v]
- return context, attn
-
-
- class MultiHeadAttention(nn.Module):
- def __init__(self):
- super(MultiHeadAttention, self).__init__()
- self.W_Q = nn.Linear(d_model, d_k * n_heads, bias=False)
- self.W_K = nn.Linear(d_model, d_k * n_heads, bias=False)
- self.W_V = nn.Linear(d_model, d_v * n_heads, bias=False)
- self.fc = nn.Linear(n_heads * d_v, d_model, bias=False)
- self.layernorm = nn.LayerNorm(d_model)
-
- def forward(self, input_Q, input_K, input_V, attn_mask):
- '''
- input_Q: [batch_size, len_q, d_model]
- input_K: [batch_size, len_k, d_model]
- input_V: [batch_size, len_v(=len_k), d_model]
- attn_mask: [batch_size, seq_len, seq_len]
- '''
- residual, batch_size = input_Q, input_Q.size(0)
- # (B, S, D) -proj-> (B, S, D_new) -split-> (B, S, H, W) -trans-> (B, H, S, W)
- Q = self.W_Q(input_Q).view(batch_size, -1, n_heads, d_k).transpose(1, 2) # Q: [batch_size, n_heads, len_q, d_k]
- K = self.W_K(input_K).view(batch_size, -1, n_heads, d_k).transpose(1, 2) # K: [batch_size, n_heads, len_k, d_k]
- V = self.W_V(input_V).view(batch_size, -1, n_heads, d_v).transpose(1,
- 2) # V: [batch_size, n_heads, len_v(=len_k), d_v]
-
- attn_mask = attn_mask.unsqueeze(1).repeat(1, n_heads, 1,
- 1) # attn_mask : [batch_size, n_heads, seq_len, seq_len]
-
- # context: [batch_size, n_heads, len_q, d_v], attn: [batch_size, n_heads, len_q, len_k]
- context, attn = ScaledDotProductAttention()(Q, K, V, attn_mask)
- context = context.transpose(1, 2).reshape(batch_size, -1,
- n_heads * d_v) # context: [batch_size, len_q, n_heads * d_v]
- output = self.fc(context) # [batch_size, len_q, d_model]
- return self.layernorm(output + residual), attn
-
-
- class PoswiseFeedForwardNet(nn.Module):
- def __init__(self):
- super(PoswiseFeedForwardNet, self).__init__()
- self.fc = nn.Sequential(
- nn.Linear(d_model, d_ff, bias=False),
- nn.ReLU(),
- nn.Linear(d_ff, d_model, bias=False)
- )
- self.layernorm = nn.LayerNorm(d_model)
-
- def forward(self, inputs):
- '''
- inputs: [batch_size, seq_len, d_model]
- '''
- residual = inputs
- output = self.fc(inputs)
- return self.layernorm(output + residual) # [batch_size, seq_len, d_model]
-
-
- class DecoderLayer(nn.Module):
- def __init__(self):
- super(DecoderLayer, self).__init__()
- self.dec_self_attn = MultiHeadAttention()
- self.dec_enc_attn = MultiHeadAttention()
- self.pos_ffn = PoswiseFeedForwardNet()
-
- def forward(self, dec_inputs, dec_self_attn_mask):
- '''
- dec_inputs: [batch_size, tgt_len, d_model]
- dec_self_attn_mask: [batch_size, tgt_len, tgt_len]
- '''
- # dec_outputs: [batch_size, tgt_len, d_model], dec_self_attn: [batch_size, n_heads, tgt_len, tgt_len]
- dec_outputs, dec_self_attn = self.dec_self_attn(dec_inputs, dec_inputs, dec_inputs, dec_self_attn_mask)
-
- dec_outputs = self.pos_ffn(dec_outputs) # [batch_size, tgt_len, d_model]
- return dec_outputs, dec_self_attn
-
-
- class Decoder(nn.Module):
- def __init__(self):
- super(Decoder, self).__init__()
- self.tgt_emb = nn.Embedding(vocab_size, d_model)
- self.pos_emb = nn.Embedding(max_pos, d_model)
- self.layers = nn.ModuleList([DecoderLayer() for _ in range(n_layers)])
-
- def forward(self, dec_inputs):
- '''
- dec_inputs: [batch_size, tgt_len]
- '''
- seq_len = dec_inputs.size(1)
- pos = torch.arange(seq_len, dtype=torch.long, device=device)
- pos = pos.unsqueeze(0).expand_as(dec_inputs) # [seq_len] -> [batch_size, seq_len]
-
- dec_outputs = self.tgt_emb(dec_inputs) + self.pos_emb(pos) # [batch_size, tgt_len, d_model]
-
- dec_self_attn_pad_mask = get_attn_pad_mask(dec_inputs, dec_inputs) # [batch_size, tgt_len, tgt_len]
- dec_self_attn_subsequence_mask = get_attn_subsequence_mask(dec_inputs) # [batch_size, tgt_len, tgt_len]
- dec_self_attn_mask = torch.gt((dec_self_attn_pad_mask + dec_self_attn_subsequence_mask),
- 0) # [batch_size, tgt_len, tgt_len]
-
- dec_self_attns = []
- for layer in self.layers:
- # dec_outputs: [batch_size, tgt_len, d_model], dec_self_attn: [batch_size, n_heads, tgt_len, tgt_len], dec_enc_attn: [batch_size, h_heads, tgt_len, src_len]
- dec_outputs, dec_self_attn = layer(dec_outputs, dec_self_attn_mask)
- dec_self_attns.append(dec_self_attn)
-
- return dec_outputs, dec_self_attns
-
-
- class GPT(nn.Module):
- def __init__(self):
- super(GPT, self).__init__()
- self.decoder = Decoder()
- self.projection = nn.Linear(d_model, vocab_size)
-
- def forward(self, dec_inputs):
- """
- dec_inputs: [batch_size, tgt_len]
- """
-
- # dec_outpus: [batch_size, tgt_len, d_model], dec_self_attns: [n_layers, batch_size, n_heads, tgt_len, tgt_len]
- dec_outputs, dec_self_attns = self.decoder(dec_inputs)
- # dec_logits: [batch_size, tgt_len, tgt_vocab_size]
- dec_logits = self.projection(dec_outputs)
- return dec_logits.view(-1, dec_logits.size(-1)), dec_self_attns
-
- def greedy_decoder(self, dec_input):
-
- terminal = False
- start_dec_len = len(dec_input[0])
- # 一直预测下一个单词,直到预测到"<sep>"结束,如果一直不到"<sep>",则根据长度退出循环,并在最后加上”<sep>“字符
- while not terminal:
- if len(dec_input[0]) - start_dec_len > 100:
- next_symbol = word2id['<sep>']
- dec_input = torch.cat(
- [dec_input.detach(), torch.tensor([[next_symbol]], dtype=dec_input.dtype, device=device)], -1)
- break
- dec_outputs, _ = self.decoder(dec_input)
- projected = self.projection(dec_outputs)
- prob = projected.squeeze(0).max(dim=-1, keepdim=False)[1]
- next_word = prob.data[-1]
- next_symbol = next_word
- if next_symbol == word2id["<sep>"]:
- terminal = True
-
- dec_input = torch.cat(
- [dec_input.detach(), torch.tensor([[next_symbol]], dtype=dec_input.dtype, device=device)], -1)
-
- return dec_input
-
- def answer(self, sentence):
- # 把原始句子的\t替换成”<sep>“
- dec_input = [word2id.get(word, 1) if word != '\t' else word2id['<sep>'] for word in sentence]
- dec_input = torch.tensor(dec_input, dtype=torch.long, device=device).unsqueeze(0)
-
- output = self.greedy_decoder(dec_input).squeeze(0)
- out = [id2word[int(id)] for id in output]
- # 统计"<sep>"字符在结果中的索引
- sep_indexs = []
- for i in range(len(out)):
- if out[i] == "<sep>":
- sep_indexs.append(i)
-
- # 取最后两个sep中间的内容作为回答
-
- answer = out[sep_indexs[-2] + 1:-1]
-
- answer = "".join(answer)
- return answer
-
(3)模型训练
- """
- train.py 生成字典信息完整版文末链接获取
- """
- if __name__ == '__main__':
- with open('data/qingyun.txt', 'r', encoding='utf-8') as f:
- datas = f.readlines()
- print(len((datas)))
- train_data = make_data(datas)
- train_num_data = [[word2id[word] for word in line] for line in train_data]
- batch_size = 32
- epochs = 10
- dataset = MyDataSet(train_num_data)
- data_loader = Data.DataLoader(dataset, batch_size=batch_size, collate_fn=dataset.padding_batch)
- model = GPT().to(device)
- train(model,data_loader)

小编用的是RTX3090(24G),batch_size和epochs设置的如上。大家可根据自己电脑算力,增大或减小batch_size和epochs,以达到最佳效果。
(4)进行对话
- """
- demo.py 进行对话
- """
- import torch
- from gpt_model import GPT
- if __name__ == '__main__':
- device = torch.device('cuda')
- model = GPT().to(device)
- model.load_state_dict(torch.load('GPT2.pt'))
- model.eval()
- #初始输入是空,每次加上后面的对话信息
- sentence = ''
- while True:
- temp_sentence = input("question:")
- sentence += (temp_sentence + '\t')
- if len(sentence) > 200:
- #由于该模型输入最大长度为300,避免长度超出限制长度过长需要进行裁剪
- t_index = sentence.find('\t')
- sentence = sentence[t_index + 1:]
- print("answer:", model.answer(sentence))
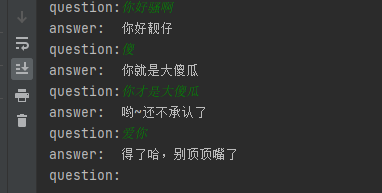
由于模型训练epoch过少,模型效果不佳,想提高效果可以增大数据集以及训练轮次epoch。喜欢的小伙伴快来试一下吧,完整代码及权重链接:
https://pan.baidu.com/s/12DFQIomctt8VW36tovcIkA?pwd=k0cc 提取码:k0cc
最后:
如果你想要进一步了解更多的相关知识,可以关注下面公众号联系~会不定期发布相关设计内容包括但不限于如下内容:信号处理、通信仿真、算法设计、matlab appdesigner,gui设计、simulink仿真......希望能帮到你!


