
- 1何时应用 RAG 与微调
- 2FFmpeg常用命令汇总_ffmpeg命令大全
- 3大数据技术学习笔记(十一)—— Flume_大数据学习笔记
- 4【项目实战】npm 删除node_modules的多种方式_npm删除nodemodules
- 5惊叹 | 膜拜一下清华大学特等奖学金的学霸大佬们的简历! -- 我们没有理由不努力!...
- 6HTML-day02-列表标签,表格标签,form表单_列表ul和表格tr的区别
- 7Fastboot 命令报错分析篇_(bootloader) current-slott: not found
- 8周末没有怎么出门,终于解决了word不能另存为UTF8格式txt的问题_文本文档另存utf8没有用
- 9STM32CubeMX + freeRTOS线程操作(二)_oskernelsystick
- 10pytorch模型参数迁移(三种方法)_pytorch模型迁移有哪几种方法?
概率论复习总结——基本概念_估计p(a | +),p(b | +),p(c | +),p(a | - ),p(b | - )和p
赞
踩
本博客主要用于记录概率论复习中的基础概念。
1. 概率的性质
- 加法公式:
①对于任意事件A,B,有 P ( A + B ) = P ( A ) + P ( B ) − P ( A B ) P(A+B)=P(A)+P(B)-P(AB) P(A+B)=P(A)+P(B)−P(AB);
② P ( A + B + C ) = P ( A ) + P ( B ) + P ( C ) − P ( A B ) − P ( A C ) − P ( B C ) + P ( A B C ) P(A+B+C)=P(A)+P(B)+P(C)-P(AB)-P(AC)-P(BC)+P(ABC) P(A+B+C)=P(A)+P(B)+P(C)−P(AB)−P(AC)−P(BC)+P(ABC)
理解: P(A)+P(B)导致P(AB)被多计算一次,因此需要减去一个P(AB)。P(A)+P(B)+P©导致P(ABC)被多计算两次,但P(AB), P(AC), P(BC)将P(ABC)减去三次,因此需要补上一个P(ABC)。
-
减法公式:
①对于任意事件A,B,有 P ( A − B ) = P ( A ) − P ( A B ) P(A-B)=P(A)-P(AB) P(A−B)=P(A)−P(AB); -
分配律:先并后交等于先交后并。
① P { ( A ∪ B ) ∩ C } = P { A C ∪ B C } P\{(A \cup B )\cap C \} = P\{AC \cup BC \} P{(A∪B)∩C}=P{AC∪BC}
② P { ( A ∩ B ) ∪ C } = P { ( A ∪ C ) ∩ ( B ∪ C ) } P\{(A \cap B )\cup C \} = P\{(A \cup C) \cap (B \cup C) \} P{(A∩B)∪C}=P{(A∪C)∩(B∪C)}
2. 条件概率
- 条件概率:事件A发生的条件下,事件B发生的概率为 P ( B ∣ A ) = P ( A B ) P ( A ) P(B|A)=\frac{P(AB)}{P(A)} P(B∣A)=P(A)P(AB);
- 乘法公式:若 P ( A ) > 0 P(A)>0 P(A)>0,则 P ( A B ) = P ( B ∣ A ) P ( A ) P(AB)=P(B|A)P(A) P(AB)=P(B∣A)P(A);
- 性质
① P ( B ˉ ∣ A ) = 1 − P ( B ∣ A ) P(\bar{B}|A)=1-P(B|A) P(Bˉ∣A)=1−P(B∣A)
② P ( B ∪ C ∣ A ) = P ( B ∣ A ) + P ( C ∣ A ) − P ( B C ∣ A ) P(B \cup C|A) = P(B|A)+P(C|A)-P(BC|A) P(B∪C∣A)=P(B∣A)+P(C∣A)−P(BC∣A);
3. 古典概型
- 若随机试验的样本空间
Ω
\Omega
Ω只有有限个样本点,且每个基本事件发生的可能性相等,则事件A发生的概率为A中所含样本点数k除以样本空间
Ω
\Omega
Ω所有样本点数n:
P
(
A
)
=
k
n
P(A)=\frac{k}{n}
P(A)=nk;
①样本空间 Ω \Omega Ω只有有限个样本点。
②每个基本事件发生的可能性相等。
理解: 古典概型是通过事件样本数除以总的测试样本数以近似事件发生的概率。
4. 全概率与贝叶斯公式
- 全概率公式:
P
(
A
)
=
∑
i
=
1
n
P
(
A
B
i
)
=
∑
i
=
1
n
P
(
A
∣
B
i
)
P
(
B
i
)
P(A)=\sum_{i=1}^nP(AB_i)=\sum_{i=1}^n P(A|B_i)P(B_i)
P(A)=∑i=1nP(ABi)=∑i=1nP(A∣Bi)P(Bi)
当事件A可以分为几种情况时,A发生的概率就是这些情况对应概率之和 - 贝叶斯公式:
P
(
B
i
∣
A
)
=
P
(
B
i
A
)
P
(
A
)
=
P
(
A
∣
B
i
)
P
(
B
i
)
∑
i
=
1
n
P
(
A
∣
B
i
)
P
(
B
i
)
P(B_i|A)=\frac{P(B_iA)}{P(A)}=\frac{P(A|B_i)P(B_i)}{\sum_{i=1}^n P(A|B_i)P(B_i)}
P(Bi∣A)=P(A)P(BiA)=∑i=1nP(A∣Bi)P(Bi)P(A∣Bi)P(Bi)
假设事件A可以分成几种情况,当结果A发生了,需要判断是那种情况时,要用贝叶斯公式。
理解: 贝叶斯公式一般用于已知事件B_i的概率和在事件B_i发生条件下A发生的条件概率时,因为不同B_i对应发生事件A的概率不同,利用贝叶斯公式求事件B_i发生的概率。根据公式可以知道,分母就是全概率公式对于所有的事件B都相同,导致结果不同的是分子即B_i发生的概率乘以A对应的条件概率。
5. 事件的独立性
事件A, B相互独立,则:
- P ( A B ) = P ( A ) P ( B ) P(AB) = P(A)P(B) P(AB)=P(A)P(B)
- 条件概率: P ( B ∣ A ) = P ( B ∣ A ˉ ) = P ( B ) P(B|A) = P(B|\bar{A})=P(B) P(B∣A)=P(B∣Aˉ)=P(B)
- 联合分布律: P ( X = x i , Y = y j ) = P ( X = x i ) P ( Y = y j ) P(X=x_i,Y=y_j)=P(X=x_i)P(Y=y_j) P(X=xi,Y=yj)=P(X=xi)P(Y=yj)
- 联合、边缘概率密度: f ( x , y ) = f X ( x ) f Y ( y ) f(x,y)=f_X(x) f_Y(y) f(x,y)=fX(x)fY(y)
- 数学期望: E ( X Y ) = E ( X ) E ( Y ) ; E(XY)=E(X)E(Y); E(XY)=E(X)E(Y);
- 方差: D ( X ± Y ) = D ( X ) + D ( Y ) ; D(X \pm Y)=D(X)+D(Y); D(X±Y)=D(X)+D(Y);
- 协方差: C o v ( X , Y ) = 0 ; Cov(X,Y)=0; Cov(X,Y)=0;
6. 离散型随机变量分布律与分布函数
- 分布律: P ( X = x k ) = p k P(X=x_k)=p_k P(X=xk)=pk
- 分布函数:
F
(
x
)
=
P
(
X
≤
x
)
=
∑
x
k
≤
x
p
k
F(x)=P(X \leq x)=\sum_{x_k \leq x} p_k
F(x)=P(X≤x)=∑xk≤xpk
① 0 ≤ F ( x ) ≤ 1 0 \leq F(x) \leq 1 0≤F(x)≤1
②F(x)单调不减,右连续。 - 概率:
P
(
X
≤
a
)
=
F
(
a
)
P(X \leq a)=F(a)
P(X≤a)=F(a)
① P ( X = a ) = F ( a ) − F ( a − 1 ) P(X=a)=F(a)-F(a-1) P(X=a)=F(a)−F(a−1)
② P ( X > a ) = 1 − F ( a ) P(X>a)=1-F(a) P(X>a)=1−F(a)
③ P ( a < X ≤ b ) = F ( b ) − F ( a ) P(a < X \leq b)=F(b)-F(a) P(a<X≤b)=F(b)−F(a)
7. 连续型随机变量概率的计算
- 分布函数:
F
(
x
)
=
P
(
X
≤
x
)
=
∫
−
∞
x
f
(
t
)
d
t
F(x)=P(X \leq x)=\int_{-\infty}^x f(t)dt
F(x)=P(X≤x)=∫−∞xf(t)dt
① 0 ≤ F ( x ) ≤ 1 0 \leq F(x) \leq 1 0≤F(x)≤1
②F(x)单调不减,右连续。 - 概率密度:
f
(
x
)
,
−
∞
<
x
<
∞
f(x),-\infty <x<\infty
f(x),−∞<x<∞
① f ( x ) ≥ 0 f(x) \geq 0 f(x)≥0
②若f(x)连续,则 F ′ ( x ) = f ( x ) F'(x)=f(x) F′(x)=f(x) - 概率:
① P ( X = a ) = 0 P(X=a)=0 P(X=a)=0
② P ( X < a ) = P ( x ≤ a ) = 1 − F ( a ) P(X < a)=P(x \leq a)=1-F(a) P(X<a)=P(x≤a)=1−F(a)
注意: 连续型随机变量在某一点处的概率为0,这是与离散型随机变量概率极大的不同点。
8. 连续型随机变量函数的分布
已知连续型随机变量X的概率密度函数为 f X ( x ) f_X(x) fX(x),则 Y = g ( X ) Y=g(X) Y=g(X)的概率密度的求解步骤为:
- 分布函数法:
①求出Y的分布函数,并利用关系 Y = g ( X ) Y=g(X) Y=g(X),将Y的范围转化为X的范围,利用X的分布获得Y的分布:
F Y ( y ) = P ( Y ≤ y ) = P ( g ( X ) ≤ y ) = P ( X ∈ G y ) = ∫ G y f X ( x ) d x ; F_Y(y)=P(Y\leq y)=P(g(X) \leq y)=P(X \in G_y)=\int_{G_y} f_X(x)dx; FY(y)=P(Y≤y)=P(g(X)≤y)=P(X∈Gy)=∫GyfX(x)dx;
②求导得到 f Y ( y ) = F Y ′ ( y ) ; f_Y(y)=F'_Y(y); fY(y)=FY′(y);
已知连续型随机变量X, Y的联合概率密度函数为 f ( x , y ) f(x,y) f(x,y),则 Z = g ( x , y ) Z=g(x,y) Z=g(x,y)的概率密度函数为:
- 分布函数法:
①求 Z = g ( x , y ) Z=g(x,y) Z=g(x,y)的分布函数:
F ( z ) = P ( Z ≤ z ) = P ( g ( x , y ) ≤ z ) = P ( ( X , Y ) ∈ G z ) = ∫ ∫ G z f ( x , y ) d x d y ; F(z)=P(Z \leq z)=P(g(x,y) \leq z)=P((X,Y) \in G_z)={\int\int}_{G_z}f(x,y)dxdy; F(z)=P(Z≤z)=P(g(x,y)≤z)=P((X,Y)∈Gz)=∫∫Gzf(x,y)dxdy;
②求导得到 f ( z ) = F ′ ( z ) f(z)=F'(z) f(z)=F′(z)
9. 二维离散型随机变量的分布
- 联合分布律、边缘分布律
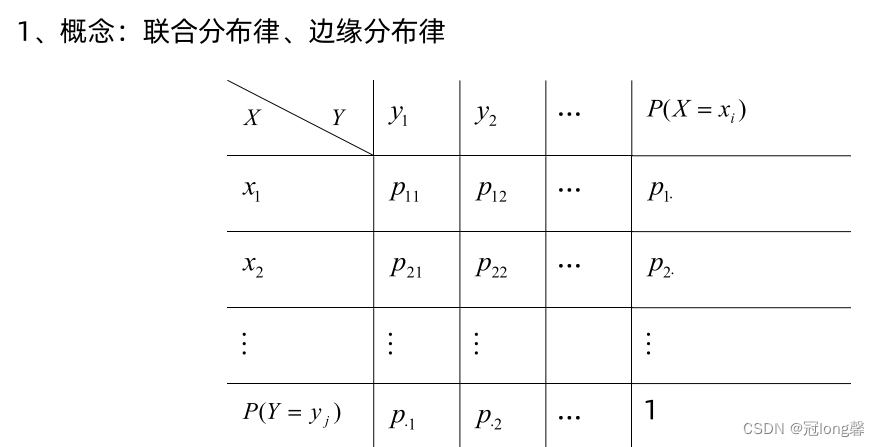
- 若X, Y相互独立,则 P ( X = x i , Y = y j ) = P ( X = x i ) × P ( Y = y j ) P(X=x_i,Y=y_j)=P(X=x_i)\times P(Y=y_j) P(X=xi,Y=yj)=P(X=xi)×P(Y=yj)
10. 二维连续型随机变量的分布
- 联合分布函数: F ( x , y ) = P { X ≤ x , Y ≤ y } = ∫ − ∞ x ∫ − ∞ y f ( u , v ) d u d v ; F(x,y)=P\{X \leq x, Y \leq y\}=\int_{-\infty}^x\int_{-\infty}^yf(u,v)dudv; F(x,y)=P{X≤x,Y≤y}=∫−∞x∫−∞yf(u,v)dudv;
- 联合概率密度: f ( x , y ) > 0 , ∫ − ∞ ∞ ∫ − ∞ ∞ f ( x , y ) d x d y = 1 f(x,y)>0,\int_{-\infty}^{\infty}\int_{-\infty}^{\infty}f(x,y)dxdy=1 f(x,y)>0,∫−∞∞∫−∞∞f(x,y)dxdy=1
- 边缘概率密度: f X ( x ) = ∫ − ∞ ∞ f ( x , y ) d y ; f Y ( y ) = ∫ − ∞ ∞ f ( x , y ) d x f_X(x)=\int_{-\infty}^{\infty}f(x,y)dy; \ \ \ f_Y(y)=\int_{-\infty}^{\infty}f(x,y)dx fX(x)=∫−∞∞f(x,y)dy; fY(y)=∫−∞∞f(x,y)dx
- 条件概率密度: f Y ∣ X ( y ∣ x ) = f ( x , y ) f X ( x ) ; f X ∣ Y ( x ∣ y ) = f ( x , y ) f Y ( y ) f_{Y|X}(y|x)=\frac{f(x,y)}{f_X(x)}; \ \ \ f_{X|Y}(x|y)=\frac{f(x,y)}{f_Y(y)} fY∣X(y∣x)=fX(x)f(x,y); fX∣Y(x∣y)=fY(y)f(x,y)
- 若X和Y相互独立, f ( x , y ) = f X ( x ) f Y ( y ) f(x,y)=f_X(x) f_Y(y) f(x,y)=fX(x)fY(y)
11. 常见分布
二项分布与泊松分布
-
二项分布: B ( n , p ) B(n,p) B(n,p),其中n表示n重伯努利试验中A发生的次数, X ∼ B ( n , p ) X \sim B(n,p) X∼B(n,p),其中p表示每次试验中A发生的概率。
①分布律: P { X = k } = C n k p k ( 1 − p ) n − k P\{X=k\}=C_n^kp^k(1-p)^{n-k} P{X=k}=Cnkpk(1−p)n−k;表示事件A发生k次的概率。 -
泊松分布: P ( λ ) P(\lambda) P(λ),若 X ∼ B ( n , p ) X \sim B(n,p) X∼B(n,p),当n较大,p较小时,X近似服从 P ( n p ) P(np) P(np)。
①分布律: P { X = k } = λ k e − λ k ! P\{X=k\}=\frac{\lambda^k e^{-\lambda}}{k!} P{X=k}=k!λke−λ
均匀分布
- 均匀分布:
U
(
a
,
b
)
U(a,b)
U(a,b)
①概率密度函数: f ( x ) = { 1 b − a , a < x < b 0 , e l s e f(x)=f(x)={b−a1,0,a<x<belse{1b−a,0,a<x<belse
正太分布
- 正太分布:
N
(
μ
,
σ
2
)
N(\mu,\sigma^2)
N(μ,σ2)
①概率密度函数: 1 2 π σ e − ( x − μ ) 2 2 σ 2 \frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{(x-\mu)^2}{2\sigma^2}} 2π σ1e−2σ2(x−μ)2
②当 μ = 0 , σ = 1 \mu=0,\sigma=1 μ=0,σ=1时,为标准正太分布 X ∼ N ( 0 , 1 ) ; X \sim N(0,1); X∼N(0,1);
12. 数学期望与方差和标准差
- 离散型随机变量的期望: E ( X ) = ∑ i = 1 ∞ x i p i E(X)=\sum_{i=1}^\infty x_ip_i E(X)=∑i=1∞xipi
- 连续型随机变量的期望: E ( X ) = ∫ − ∞ ∞ x f ( x ) d x E(X)=\int_{-\infty}^\infty xf(x)dx E(X)=∫−∞∞xf(x)dx
- 期望的性质
① E ( C ) = C ; E(C)=C; E(C)=C;
② E ( C X ) = C E ( X ) ; E(CX)=CE(X); E(CX)=CE(X);
③ E ( X + Y ) = E ( X ) + E ( Y ) ; E(X+Y)=E(X)+E(Y); E(X+Y)=E(X)+E(Y);
③若X, Y相互独立, E ( X Y ) = E ( X ) E ( Y ) ; E(XY)=E(X)E(Y); E(XY)=E(X)E(Y);
-
方差: D ( X ) = E [ X − E ( X ) ] 2 = E ( X 2 ) − E ( X ) 2 D(X)=E[X-E(X)]^2=E(X^2)-E(X)^2 D(X)=E[X−E(X)]2=E(X2)−E(X)2
理解:方差等于平方的期望减去期望的平方。 -
标准差: σ = D ( X ) \sigma=\sqrt{D(X)} σ=D(X)
-
方差的性质
① D ( C ) = 0 ; D(C)=0; D(C)=0;
② D ( X + C ) = D ( X ) ; D(X+C)=D(X); D(X+C)=D(X);
③ D ( C X ) = C 2 E ( X ) ; D(CX)=C^2E(X); D(CX)=C2E(X);
④ D ( X ± Y ) = D ( X ) + D ( Y ) ± 2 E { [ X − E [ X ] ] [ Y − E [ Y ] ] } = D ( X ) + D ( Y ) ± C o v ( X , Y ) ; D(X \pm Y)=D(X)+D(Y) \pm 2E\{[X-E[X]][Y-E[Y]] \}=D(X)+D(Y)\pm Cov(X,Y); D(X±Y)=D(X)+D(Y)±2E{[X−E[X]][Y−E[Y]]}=D(X)+D(Y)±Cov(X,Y);
⑤若X, Y相互独立, D ( X ± Y ) = D ( X ) + D ( Y ) ; D(X \pm Y)=D(X)+D(Y); D(X±Y)=D(X)+D(Y);
13. 常用分布的期望和方差
| 分布 | 分布律或概率密度 | 数学期望 | 方差 |
|---|---|---|---|
| 0-1分布 | P { x = k } = p k ( 1 − p ) 1 − k P\{x=k\}=p^k(1-p)^{1-k} P{x=k}=pk(1−p)1−k | p p p | p ( 1 − p ) p(1-p) p(1−p) |
| 二项分布 B ( n , p ) B(n,p) B(n,p) | P { x = k } = C n k p k ( 1 − p ) n − k P\{x=k\}=C_n^kp^k(1-p)^{n-k} P{x=k}=Cnkpk(1−p)n−k | n p np np | n p ( 1 − p ) np(1-p) np(1−p) |
| 泊松分布 P ( λ ) P(\lambda) P(λ) | P { x = k } = λ k e − λ k ! P\{x=k\}=\frac{\lambda^ke^{-\lambda}}{k!} P{x=k}=k!λke−λ | λ \lambda λ | λ \lambda λ |
| 均匀分布 U ( a , b ) U(a,b) U(a,b) | f ( x ) = 1 b − a ( a ≤ x ≤ b ) f(x)=\frac{1}{b-a}(a \leq x \leq b) f(x)=b−a1(a≤x≤b) | a + b 2 \frac{a+b}{2} 2a+b | ( b − a ) 2 12 \frac{(b-a)^2}{12} 12(b−a)2 |
| 正态分布 N ( μ , σ 2 ) N(\mu,\sigma^2) N(μ,σ2) | f ( x ) = 1 2 π σ e − ( x − μ ) 2 2 σ 2 f(x)=\frac{1}{\sqrt{2\pi}\sigma}e^{-\frac{(x-\mu)^2}{2\sigma^2}} f(x)=2π σ1e−2σ2(x−μ)2 | μ \mu μ | σ 2 \sigma^2 σ2 |
| 指数分布 E ( θ ) E(\theta) E(θ) | f ( x ) = θ e θ x ( x > 0 ) f(x)=\theta e^{\theta x}(x>0) f(x)=θeθx(x>0) | 1 θ \frac{1}{\theta} θ1 | 1 θ 2 \frac{1}{\theta^2} θ21 |
14. 协方差和相关系数
-
协方差: C o v ( X , Y ) = E ( X Y ) − E ( X ) E ( Y ) ; Cov(X,Y)=E(XY)-E(X)E(Y); Cov(X,Y)=E(XY)−E(X)E(Y);
-
相关系数: ρ X Y = C o v ( X , Y ) D ( X ) D Y \rho_{XY}=\frac{Cov(X,Y)}{\sqrt{D(X)D{Y}}} ρXY=D(X)DY Cov(X,Y)
理解:当X, Y相互独立时,它们的协方差和相关系数为0. -
协方差的性质:
① C o v ( X , C ) = 0 ; Cov(X,C)=0; Cov(X,C)=0;
② C o v ( a X , b Y ) = a b C o v ( X , Y ) ; Cov(aX,bY)=abCov(X,Y); Cov(aX,bY)=abCov(X,Y);
③ C o v ( X 1 + X 2 , Y ) = C o v ( X 1 , Y ) + C o v ( X 2 , Y ) ; Cov(X_1+X_2,Y)=Cov(X_1,Y)+Cov(X_2,Y); Cov(X1+X2,Y)=Cov(X1,Y)+Cov(X2,Y);
④ D ( X ± Y ) = D ( X ) + D ( Y ) ± 2 C o v ( X , Y ) ; D(X \pm Y)=D(X)+D(Y) \pm 2Cov(X,Y); D(X±Y)=D(X)+D(Y)±2Cov(X,Y);
⑤若X, Y相互独立,则 C o v ( X , Y ) = 0 ; Cov(X,Y)=0; Cov(X,Y)=0;
15. 大数定律
-
辛钦大数定理:对于独立同分布且具有均值 μ \mu μ的随机变量 X 1 , X 2 , ⋯ , X n X_1,X_2,\cdots,X_n X1,X2,⋯,Xn,当n充分大时,它们的算数平均 1 n ∑ i = 1 n X i \frac{1}{n}\sum_{i=1}^nX_i n1∑i=1nXi很可能接近于 μ \mu μ。
理解:对独立同分布的随机变量求和,当n充分大时,求和的均值与分布均值相似。 -
伯努利大数定理:设 f A f_A fA是n次独立重复实验中事件A发生的次数,p是事件A在每次试验中发生的概率,则对于任意正数 ϵ > 0 \epsilon>0 ϵ>0有: lim n → ∞ P ( ∣ f A n − p ∣ < ϵ ) = 1 \lim_{n \to \infty}P(|\frac{f_A}{n}-p|<\epsilon)=1 limn→∞P(∣nfA−p∣<ϵ)=1。
理解:对于n次独立重复实验,当n充分大时,事件发生的比例可以近似于事件发生的概率。
16. 中心极限定理
-
设随机变量 X 1 , X 2 , ⋯ X_1,X_2,\cdots X1,X2,⋯独立同分布, E ( X k ) = μ , D ( X k ) = σ 2 E(X_k)=\mu,D(X_k)=\sigma^2 E(Xk)=μ,D(Xk)=σ2,则当n充分大时,近似有 ∑ k = 1 n X k ∼ N ( n μ , n σ 2 ) , 即 ∑ k = 1 n X k − n μ n σ ∼ N ( 0 , 1 ) \sum_{k=1}^nX_k \sim N(n\mu,n\sigma^2),即\frac{\sum_{k=1}^nX_k-n\mu}{\sqrt{n}\sigma}\sim N(0,1) ∑k=1nXk∼N(nμ,nσ2),即n σ∑k=1nXk−nμ∼N(0,1)。
理解:独立同分布的随机变量求和,当n趋近于无穷大时,它们和的分布趋近于正太分布。 -
设随机变量 X ∼ B ( n , p ) X \sim B(n,p) X∼B(n,p),当n充分大时,近似有 X ∼ N ( n p , n p q ) , 即 X − n p n p q ∼ N ( 0 , 1 ) X \sim N(np,npq),即\frac{X-np}{\sqrt{npq}}\sim N(0,1) X∼N(np,npq),即npq X−np∼N(0,1)。
理解:对于二项分布,当n充分大时二项分布可以近似于泊松分布和正态分布(中心极限定理)。
17. 三大分布
-
χ 2 ( n ) \chi^2(n) χ2(n)分布:若 X 1 , X 2 , ⋯ , X n X_1,X_2,\cdots,X_n X1,X2,⋯,Xn相互独立,且 X i ∼ N ( 0 , 1 ) X_i \sim N(0,1) Xi∼N(0,1),则 X 1 2 + X 2 2 + ⋯ + X n 2 ∼ χ 2 ( n ) ; X_1^2+X_2^2+\cdots+X_n^2 \sim \chi^2(n); X12+X22+⋯+Xn2∼χ2(n);
理解: χ ( n ) 2 \chi(n)^2 χ(n)2分布就是服从于正态分布N(0,1)的相互独立的随机变量的平方和。 -
t ( n ) t(n) t(n)分布:设 X ∼ N ( 0 , 1 ) , Y ∼ χ 2 ( n ) X \sim N(0,1),Y\sim \chi^2(n) X∼N(0,1),Y∼χ2(n),X, Y相互独立,则 T = X Y / n ∼ t ( n ) T=\frac{X}{\sqrt{Y/n}}\sim t(n) T=Y/n X∼t(n)。
理解: t ( n ) t(n) t(n)分布就是正态分布除以 χ 2 ( n ) \chi^2(n) χ2(n)分布。 -
F F F分布:设 X ∼ χ 2 ( n 1 ) , Y ∼ χ 2 ( n 2 ) X \sim \chi^2(n_1),Y \sim \chi^2(n_2) X∼χ2(n1),Y∼χ2(n2),X, Y相互独立,则 F = X / n 1 Y / n 2 F=\frac{X/n_1}{Y/n_2} F=Y/n2X/n1。
理解: F F F分布就是两个 χ 2 \chi^2 χ2分布相除。
18. 点估计
- 求解步骤:
①写出总体一阶矩 E ( X ) = g ( θ ) E(X)=g(\theta) E(X)=g(θ),和样本一阶矩 X ˉ \bar{X} Xˉ。
②令总体矩=样本矩,反解出矩估计量 θ ^ = h ( X ˉ ) \hat{\theta}=h(\bar{X}) θ^=h(Xˉ)。
19. 极大似然估计
-
离散型总体的最大似然估计:
①计算似然函数 L ( θ ) = ∏ i = 1 n p ( x i , θ ) ; L(\theta)=\prod_{i=1}^n p(x_i,\theta); L(θ)=∏i=1np(xi,θ);
②对似然函数取对数 ln L ( θ ) = ∑ i = 1 n ln p ( x i , θ ) ; \ln L(\theta)=\sum_{i=1}^n \ln p(x_i,\theta); lnL(θ)=∑i=1nlnp(xi,θ);
③令 d d θ ln L ( θ ) = 0 \frac{d}{d\theta}\ln L(\theta)=0 dθdlnL(θ)=0,解出最大似然估计 θ ^ ; \hat{\theta}; θ^; -
连续型总体的最大似然估计:
①计算似然函数 L ( θ ) = ∏ i = 1 n f ( x i , θ ) ; L(\theta)=\prod_{i=1}^n f(x_i,\theta); L(θ)=∏i=1nf(xi,θ);
②对似然函数取对数 ln L ( θ ) = ∑ i = 1 n ln f ( x i , θ ) ; \ln L(\theta)=\sum_{i=1}^n \ln f(x_i,\theta); lnL(θ)=∑i=1nlnf(xi,θ);
③令 d d θ ln L ( θ ) = 0 \frac{d}{d\theta}\ln L(\theta)=0 dθdlnL(θ)=0,解出最大似然估计 θ ^ ; \hat{\theta}; θ^;

