
- 1一文看懂四种基本的神经网络架构_tcp 神经网络
- 2ai电销机器人系统搭建开发-通话模块_ai外呼机器人系统搭建
- 3【InternLM 实战营第二期笔记】书生·浦语大模型全链路开源体系及InternLM2技术报告笔记_internlm2训练数据量词表大小
- 4(六)阿里云ECS云服务器快照概念以及使用_云服务器ecs-快照
- 5Java 优先队列 PriorityQueue_java优先队列默认是大顶堆吗
- 6实验性AI算法揭示了招聘过程中的性别偏见_性别偏见招聘算法
- 7在职编程人员如何提升自我价值?_编程员工总结价值
- 8FPGA读取SHT31温湿度传感器(附驱动代码及tb)_fpga温湿度压强传感器
- 9文本分类-Word2vec+LSTM_word2vec lstm
- 10ChatGPT上线“论文神器”插件!无需关键字即可搜索2亿文章,链接绝对保真
自然语言处理Prompt内容解读与案例_prompt自然语言处理
赞
踩
自然语言处理Prompt内容解读与案例
注:大家觉得博客好的话,别忘了点赞收藏呀,本人每周都会更新关于人工智能和大数据相关的内容,内容多为原创,Python Java Scala SQL 代码,CV NLP 推荐系统等,Spark Flink Kafka Hbase Hive Flume等等~写的都是纯干货,各种顶会的论文解读,一起进步。
论文:https://arxiv.org/pdf/2111.01998.pdf
代码:https://github.com/thunlp/OpenPrompt
#博学谷IT学习技术支持#
前言
Prompt已经成为现代自然语言处理中的一种新范式,它是自然语言处理方面较新,交火的一个理念,在过去的几个月中,很多专家学者都在Prompt进行学术研究,这或许是自然语言处理以后发展的一个新方向,今天和大家一起分享一个Prompt的思想和案例。
一、火爆程度
首先来看几幅图


无须多言,大家可以看看这个趋势和短短几个月内github的star数,可以得知,而且正在成指数性的上升。
二、Prompt的核心思想
Prompt的核心思想是更好更充分的使用预训练模型,一般在自然语言处理中,有3种类型的预训练模型可以进行选择,他们分别是:
- 第一种是以Bert为典型的,使用Mask机制进行训练,类似于完形填空。
- 第二种是以GPT-3为典型,自回归模型,预测下一个token。
- 第三种是以T5为典型,Seq2Seq,序列到序列模型,比如机器翻译。
今天以第一种Bert为案例,和大家分享。更多案例,以后继续,我会持续关注Prompt最新的论文和落地项目。已经在CV领域也已经有使用。
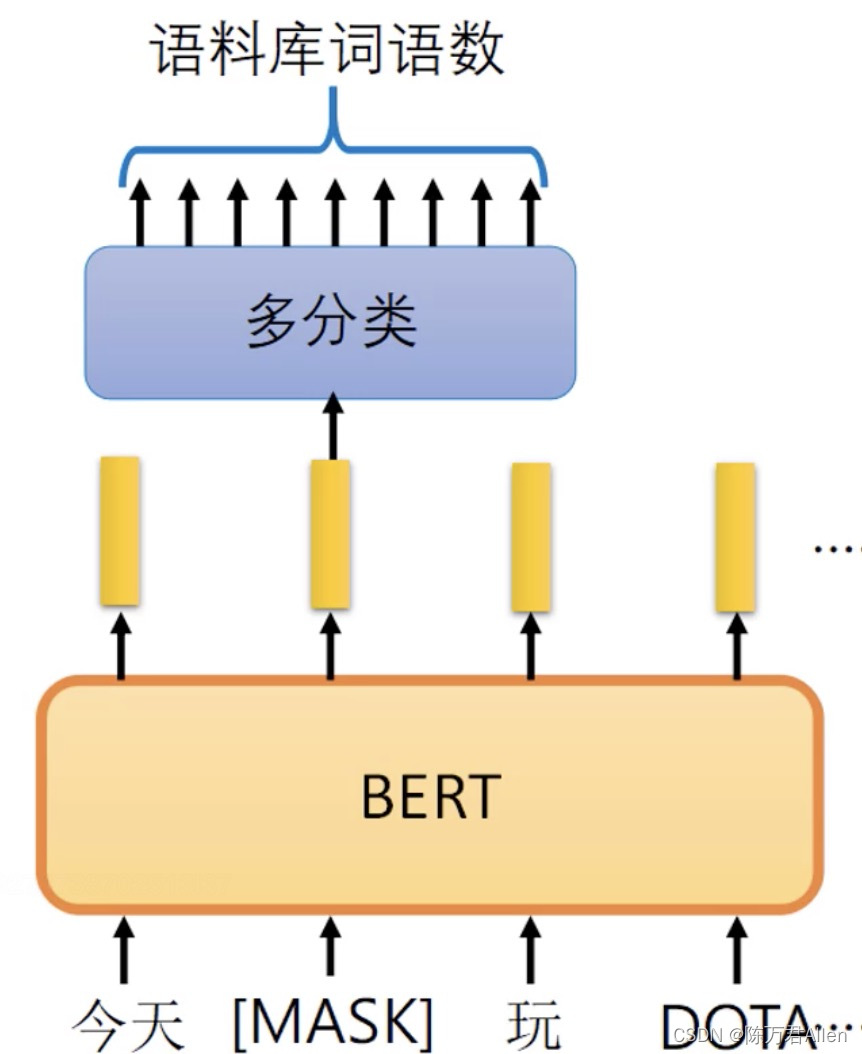
Bert,想必大家都很熟悉了,在训练的时候,使用了经典的Mask机制,进行训练,也是最被常使用的预训练模型之一。但是如果我的下游任务,不是完形填空类型的任务,比如说是分类任务的时候,使用Bert作为预训练模型,会不会有问题?效果打折?因为下游任务和Bert原来的训练方法不一样啊?如果把我的下游任务也改成完形填空,和Bert训练时候的方法完全一样,是否能提升下游任务的准确性?
这就是Prompt的核心理论,**把下游任务去凑成和预训练模型完全一样的模式!**只有这样才能最大化的发挥预训练模型的优势!
三、案例和代码
1.数据集
假如我现在有一个多分类任务,判断文章属于哪个类型,数据用的公开数据集agnews

数据一共有3列,第一列是标签,表示这篇文章属于哪一类,一共是4类,第二列是文章的title,第三列是文章的内容。希望通过文章的title和内容,去预测文章属于哪一类,属于多分类认为。
2.读取数据集
首先对样本进行采样操作,原数据集12000个数据,太大了,没啥难度,这里对每一类数据进行采样,分别采16个,一共只有64个数据数据进行训练,加大难度。
代码如下(示例):
from openprompt.data_utils.text_classification_dataset import AgnewsProcessor
from openprompt.data_utils.data_sampler import FewShotSampler #每种类别采样16个样本
dataset = {} #4个类别的语料库,新闻标题与内容
dataset['train'] = AgnewsProcessor().get_train_examples("../agnews")
sampler = FewShotSampler(num_examples_per_label=16, num_examples_per_label_dev=16, also_sample_dev=True)
dataset['train'], dataset['validation'] = sampler(dataset['train'])
dataset['test'] = AgnewsProcessor().get_test_examples("../agnews")
print('采样后原始数据集大小:',len(dataset['train']))
print('数据样例',dataset['train'][0])
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
2.将下游任务凑成Bert模版
from openprompt.plms import load_plm from openprompt.prompts import ManualTemplate from openprompt import PromptDataLoader from openprompt.prompts import SoftVerbalizer from openprompt import PromptForClassification import torch plm, tokenizer, model_config, WrapperClass = load_plm("bert", "bert-base-cased")#读取预训练模型 #这一行是关键代码,写模版 mytemplate = ManualTemplate(tokenizer=tokenizer, text='{"placeholder":"text_a"} {"placeholder":"text_b"} In this sentence, the topic is {"mask"}.') wrapped_example = mytemplate.wrap_one_example(dataset['train'][0]) print('wrapped_example:',wrapped_example) train_dataloader = PromptDataLoader(dataset=dataset["train"], template=mytemplate, tokenizer=tokenizer, tokenizer_wrapper_class=WrapperClass, max_seq_length=256, decoder_max_length=3, batch_size=4,shuffle=True, teacher_forcing=False, predict_eos_token=False, truncate_method="head") #可以实现将模型输出的词表概率映射为分类标签的概率。本质上是设定k个可训练的虚拟token,然后计算模型输出和这几个token的相似度: myverbalizer = SoftVerbalizer(tokenizer, plm, num_classes=4)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
3.模型的训练
from transformers import AdamW, get_linear_schedule_with_warmup use_cuda = False prompt_model = PromptForClassification(plm=plm,template=mytemplate, verbalizer=myverbalizer, freeze_plm=False) if use_cuda: prompt_model= prompt_model.cuda() loss_func = torch.nn.CrossEntropyLoss() no_decay = ['bias', 'LayerNorm.weight'] # it's always good practice to set no decay to biase and LayerNorm parameters optimizer_grouped_parameters1 = [ {'params': [p for n, p in prompt_model.plm.named_parameters() if not any(nd in n for nd in no_decay)], 'weight_decay': 0.01}, {'params': [p for n, p in prompt_model.plm.named_parameters() if any(nd in n for nd in no_decay)], 'weight_decay': 0.0} ] # Using different optimizer for prompt parameters and model parameters optimizer_grouped_parameters2 = [ {'params': prompt_model.verbalizer.group_parameters_1, "lr":3e-5}, {'params': prompt_model.verbalizer.group_parameters_2, "lr":3e-4}, ] optimizer1 = AdamW(optimizer_grouped_parameters1, lr=3e-5) optimizer2 = AdamW(optimizer_grouped_parameters2) for epoch in range(5): tot_loss = 0 for step, inputs in enumerate(train_dataloader): if use_cuda: inputs = inputs.cuda() logits = prompt_model(inputs) labels = inputs['label'] loss = loss_func(logits, labels) loss.backward() tot_loss += loss.item() optimizer1.step() optimizer1.zero_grad() optimizer2.step() optimizer2.zero_grad() print(tot_loss/(step+1)) ##模型的训练过程较为普通,大家可以根据自己的实际情况训练模型
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
总结
Prompt是时下交火的一种充分利用预训练模型的方式,也可以改变label标签,加入先验知识。提升模型整体效果。希望将来能看到更多的落地项目。

