
- 1python中文文本预处理,文本预处理
- 2CountVectorizer和TfidfVectorizer对比_tfidfvectorizer, countvectorizer
- 3关于Tomcat双击startup.bat 闪退的解决⽅法
- 4[2024]安卓手机system分区扩容教程_扩容system分区
- 5吴恩达提示工程实战演练 - 提示原则及其相关策略_与大语言模型对话,编写提示的策略技巧有哪些?
- 6C语言实现超简单贪吃蛇(代码是抄的),我做一下讲解_贪吃蛇代码
- 7东软睿驰携手BlackBerry QNX开发新一代自动驾驶域控制器_自动驾驶操作系统
- 8Python与科学计算课程设计报告———基于LSTM的气候变化预测_基于lstm的天气预测
- 9用训练好的模型测试训练集每张图片的loss_loss小于多少结束训练
- 10【Selenium】浏览器配置_selenium怎样伪装window.chrome参数
AAAI 2024 | 腾讯优图实验室27篇论文入选!异常检测、多模态、医学图像分割等方向...
赞
踩
点击下方卡片,关注“CVer”公众号
AI/CV重磅干货,第一时间送达
扫码加入CVer学术星球,可以获得最新顶会/顶刊上的论文idea和CV从入门到精通资料,以及最前沿项目和应用!发论文搞科研,强烈推荐!

转载自:腾讯优图实验室
AAAI 2024 (AAAI Conference on Artificial Intelligence) 人工智能国际会议于近日公布论文录用结果,本届会议共收到9862篇份论文投稿,最终录用2342篇论文,录用率23.75%。
AAAI 是美国人工智能协会主办的年会,同时也是是人工智能领域中历史最悠久、涵盖内容最广泛的的国际顶级学术会议之一。
今年,腾讯优图实验室共有27篇论文入选,内容涵盖表格结构识别、异常图像生成、医学图像分割等多个研究方向,展示了腾讯优图在人工智能领域的技术能力和学术成果。
以下为腾讯优图实验室入选论文概览:
01
抓取你所需:通过灵活组件重新思考复杂场景的表格结构识别
Grab What You Need: Rethinking Complex Table Structure Recognition with Flexible Components Deliberation
Hao Liu*, Xin Li*, Mingming Gong, Bing Liu, Yunfei Wu, Deqiang Jiang, Yinsong Liu, Xing Sun
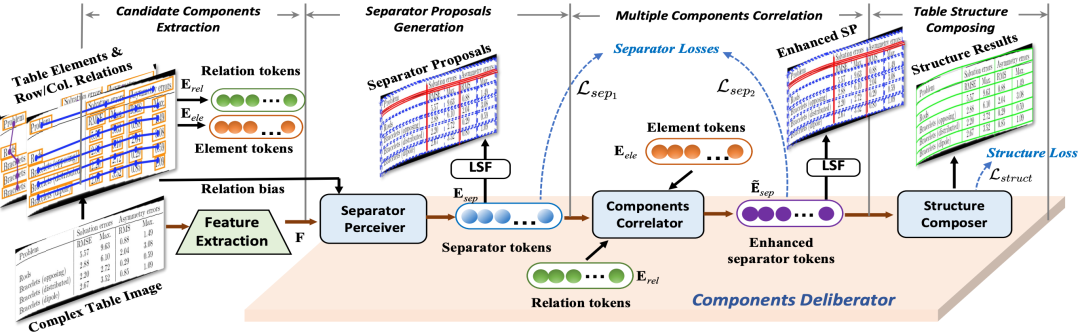
最近,表格结构识别任务,旨在将表格结构识别为机器可读格式,已经在社区中引起了越来越多的关注。尽管近来的研究取得了令人印象深刻的成功,但大多数基于单一表格组件的方法在受到不仅复杂的内部结构,还有外部捕获失真的干扰的不规则表格案例上表现不佳。在本文中,我们将其定义为复杂场景的表格结构识别问题,现有方法的性能退化归因于它们对组件的使用效率低下和冗余的后处理。为了缓解这个问题,我们将视角从表格组件提取转向有效利用多个组件。具体来说,我们提出了一种名为GrabTab的开创性方法,配备了新提出的组件审议器。得益于其渐进式审议机制,我们的GrabTab可以灵活地适应大多数复杂的表格,选择合理的组件,但不涉及复杂的后处理。在公开基准上的定量实验结果表明,我们的方法显著优于最先进的技术,尤其是在更具挑战性的场景下。
论文链接:
https://arxiv.org/abs/2303.09174
02
基于扩散的多类异常检测框架
DiAD: A Diffusion-based Framework for Multi-class Anomaly Detection
Haoyang He, Jiangning Zhang, Hongxu Chen, Xuhai Chen, Zhishan Li, Xu Chen, Yabiao Wang, Chengjie Wang, Lei Xie
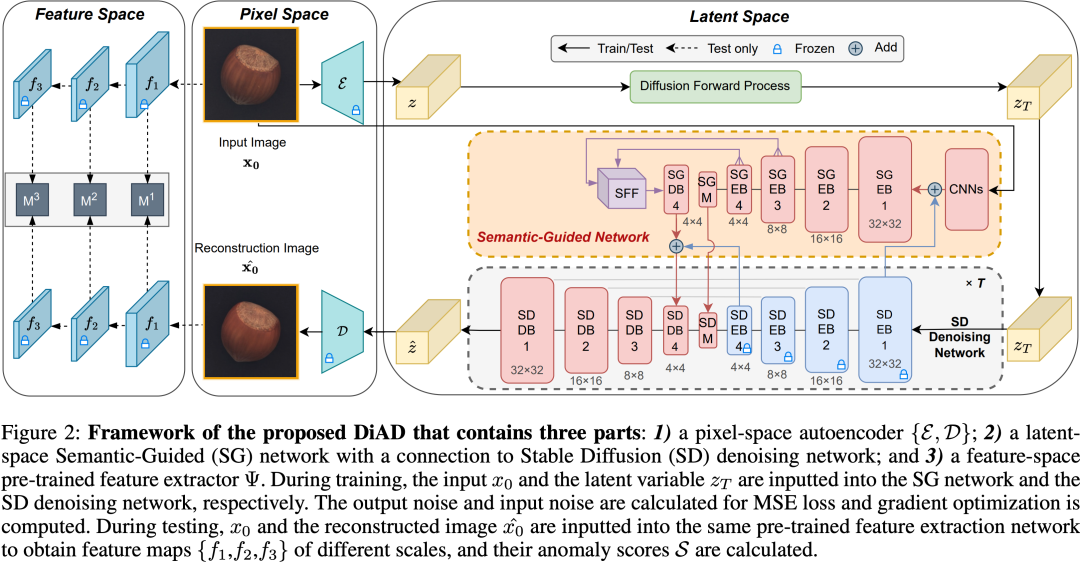
基于重构的方法在异常检测中取得了显著的成果。近期流行的扩散模型的卓越图像重构能力激发了研究人员利用它们来增强异常图像的重构的研究努力。然而,这些方法可能面临与保持图像类别和像素级结构完整性在更实际的多类设置中的挑战。为了解决上述问题,我们提出了一个基于扩散的异常检测(DiAD)框架,用于多类别异常检测,该框架包括一个像素空间的自编码器,一个与稳定扩散的去噪网络相连的潜在空间的语义引导(SG)网络,以及一个特征空间的预训练特征提取器。首先,SG网络被提出用于重构异常区域,同时保留原始图像的语义信息。其次,我们引入了空间感知特征融合(SFF)块,以在处理大量重构区域时最大化重构精度。第三,输入和重构的图像由预训练的特征提取器处理,以根据在不同尺度上提取的特征生成异常图。在MVTec-AD和VisA数据集上的实验证明了我们的方法的有效性,它超越了最先进的方法,例如,在多类别MVTec-AD数据集上分别达到了96.8/52.6和97.2/99.0(AUROC/AP)的定位和检测效果。
论文链接:
https://lewandofskee.github.io/projects/diad/
https://arxiv.org/abs/2312.06607
03
基于扩散模型的少样本异常图像生成
AnomalyDiffusion: Few-Shot Anomaly Image Generation with Diffusion Model
Teng Hu, Jiangning Zhang, Ran Yi, Yuzhen Du, Xu Chen, Liang Liu, Yabiao Wang, Chengjie Wang
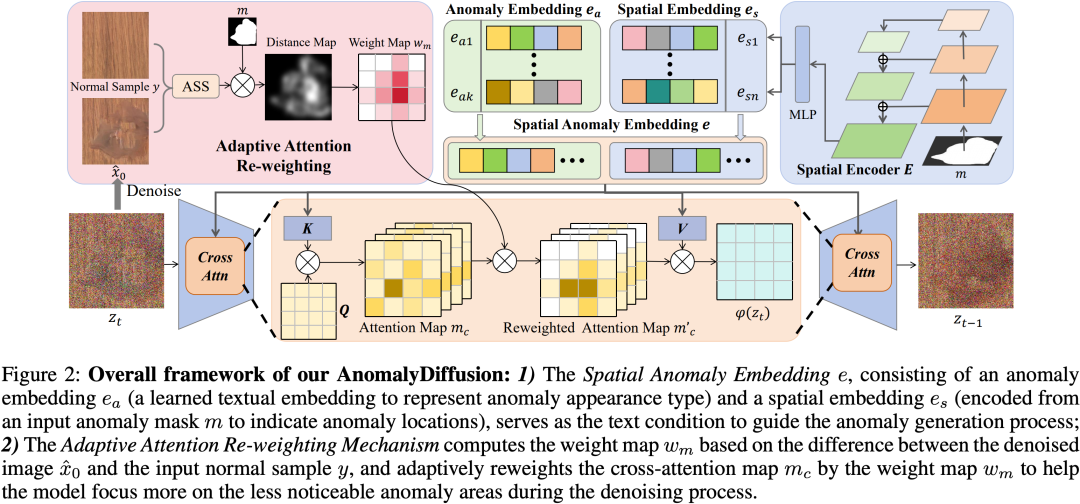
异常检查在工业制造中起着重要的作用。现有的异常检查方法由于异常数据不足而在性能上受到限制。尽管已经提出了异常生成方法来增加异常数据,但它们要么生成真实性差,要么生成的异常和掩模之间的对齐不准确。为了解决上述问题,我们提出了AnomalyDiffusion,这是一种新颖的基于扩散的少样本异常生成模型,它利用从大规模数据集中学习到的潜在扩散模型的强先验信息,以增强在少样本训练数据下的生成真实性。首先,我们提出了空间异常嵌入,它由一个可学习的异常嵌入和一个从异常掩模编码的空间嵌入组成,将异常信息解耦为异常外观和位置信息。此外,为了提高生成的异常和异常掩模之间的对齐,我们引入了一种新颖的自适应注意力重新加权机制。基于生成的异常图像和正常样本之间的差异,它动态地引导模型更多地关注生成的异常不太明显的区域,从而使得能够生成准确匹配的异常图像-掩模对。大量的实验表明,我们的模型在生成真实性和多样性方面显著优于最先进的方法,并有效地提高了下游异常检查任务的性能。
论文链接:
https://sjtuplayer.github.io/anomalydiffusion-page/
https://arxiv.org/abs/2312.05767
04
自监督似然估计与能量引导在城市场景异常分割中的应用
Self-supervised Likelihood Estimation with Energy Guidance for Anomaly Segmentation in Urban Scenes
Yuanpeng Tu, Yuxi Li, Boshen Zhang, Liang Liu, Jiangning Zhang, Yabiao Wang, Chengjie Wang, Cai Rong Zhao
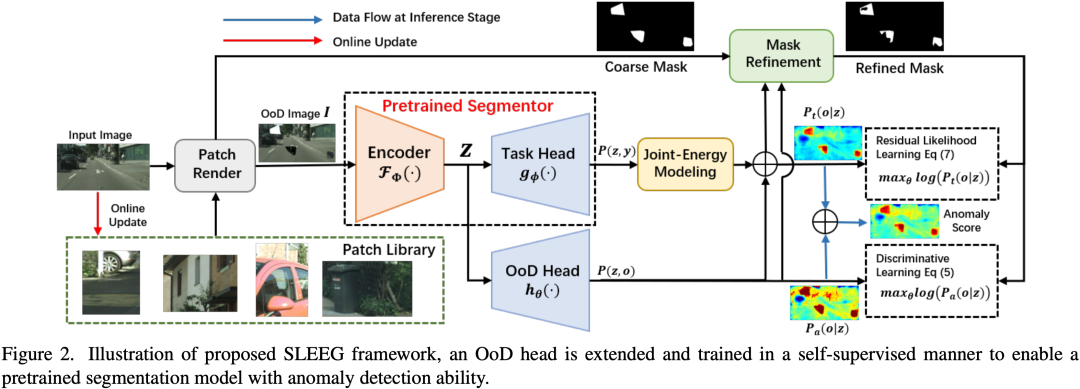
稳健的自动驾驶需要代理准确识别城市场景中的意外区域。为此,一些关键问题仍然悬而未决:如何设计合适的度量来衡量异常,以及如何正确生成异常数据的训练样本?以前的工作通常依赖于分类任务的不确定性估计和样本合成,这忽略了上下文信息,有时还需要具有细粒度注释的辅助数据集。相反,在本文中,我们利用分割任务的强上下文依赖性,设计了一个能量引导的自监督框架,用于异常分割,通过最大化自生成的异常像素的似然来优化异常头。为此,我们设计了两个异常似然估计器,一个是简单的任务无关的二元估计器,另一个将异常似然描述为任务导向能量模型的残差。基于所提出的估计器,我们进一步将我们的框架与似然引导的掩码细化过程结合,以提取有信息的异常像素进行模型训练。我们在具有挑战性的Fishyscapes和Road Anomaly基准上进行了广泛的实验,结果表明,即使没有任何辅助数据或合成模型,我们的方法仍然可以与其他SOTA方案实现竞争性能。
论文链接:
https://arxiv.org/abs/2302.06815
05
重新思考多模态异常检测的反向蒸馏
Rethinking Reverse Distillation for Multi-Modal Anomaly Detection
Zhihao Gu, Jiangning Zhang, Liang Liu, Xu Chen, Jinlong Peng, Zhenye Gan, Yabiao Wang, Annan Shu, Guannan Jiang, Lizhuang Ma
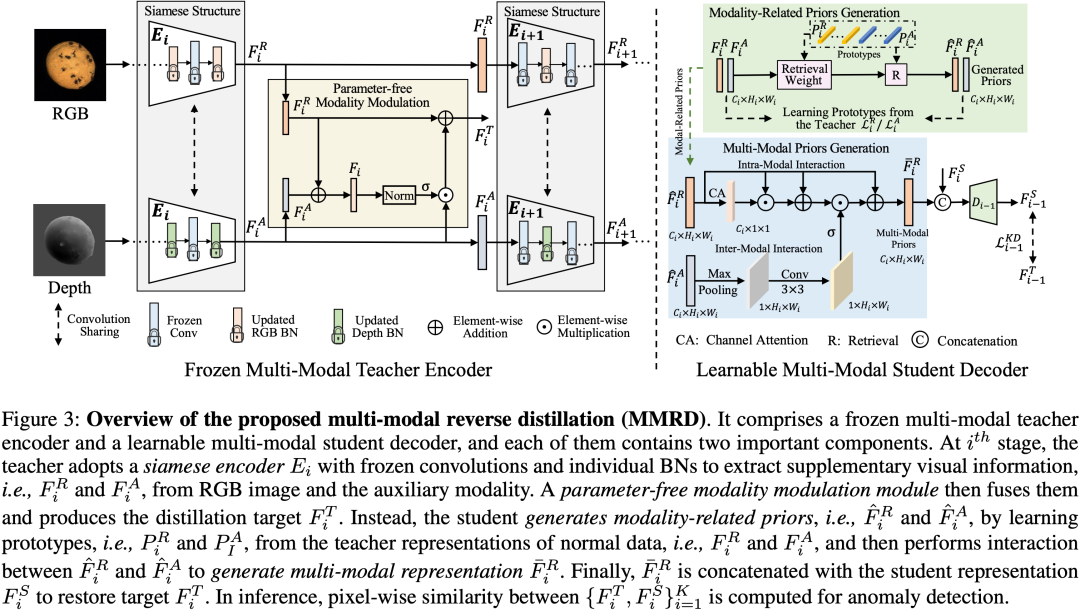
近年来,利用彩色图像进行工业场景的异常检测已取得了显著的进展,但仅依靠RGB图像无法识别出所有的异常。作为补充,引入额外的模态,如深度和表面法线图,可以帮助检测这些异常。为此,我们提出了一种新颖的多模态反向蒸馏(MMRD)范式,该范式包括一个冻结的多模态教师编码器用于生成蒸馏目标,以及一个可学习的学生解码器,目标是从教师那里恢复多模态表示。具体来说,教师通过暹罗架构从不同的模态中提取互补的视觉特征,然后无参数地融合这些来自多个级别的信息作为蒸馏的目标。对于学生,它从正常训练数据的教师表示中学习模态相关的先验,并在它们之间进行交互,形成多模态表示以进行目标重构。大量的实验表明,我们的MMRD在MVTec-3D AD和Eyecandies基准上的异常检测和定位方面都超过了最近的最先进的方法。代码将在接受后提供。
06
面向主动域适应分割的密度感知core-set算法
Density Matters: Improved Core-set for Active Domain Adaptive Segmentation
Shizhan Liu*, Zhengkai Jiang*, Yuxi Li, Jinlong Peng, Yabiao Wang, Weiyao Lin
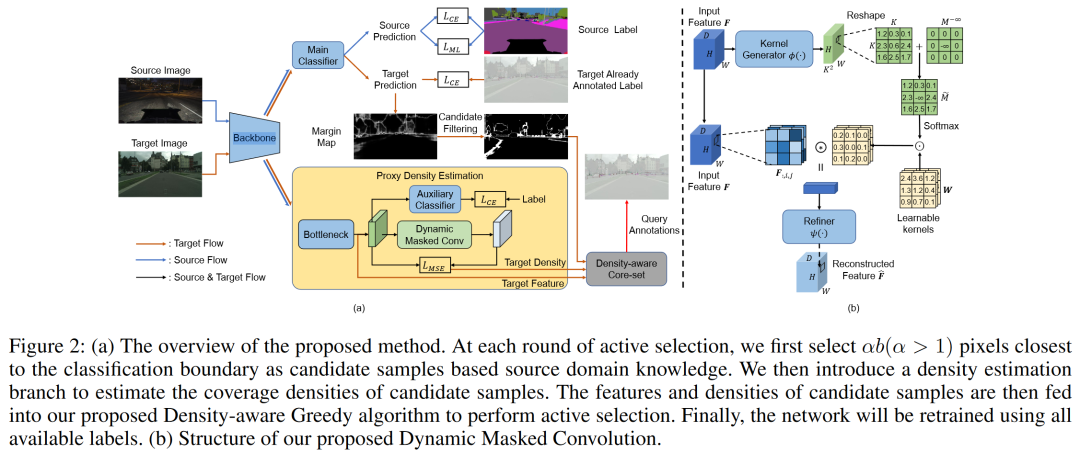
主动域适应已经成为在语义分割中平衡昂贵的标注成本和模型性能的解决方法。然而,现有的工作通常忽视了选定样本与其在特征空间中的局部上下文之间的关联,这导致了对标注预算的低效使用。在这项工作中,我们重新审视了经典core-set方法的理论界限,并确定模型性能与选定样本周围的局部样本分布密切相关。为了有效地估计局部样本的密度,我们引入了一个带有动态掩蔽卷积的局部密度估计器,并开发了一个密度感知贪婪算法来优化界限。大量的实验证明了我们方法的优越性。此外,即使只有很少的标签,我们的方案也能达到与完全监督情况下相当的结果。
论文链接:
https://arxiv.org/pdf/2312.09595.pdf
07
图像匹配和目标检测协作框架
MatchDet: A Collaborative Framework for Image Matching and Object Detection
Jinxiang Lai*, Wenlong Wu*, Bin-Bin Gao, Jun Liu, Jiawei Zhan, Congchong Nie, Yi Zeng, Chengjie Wang
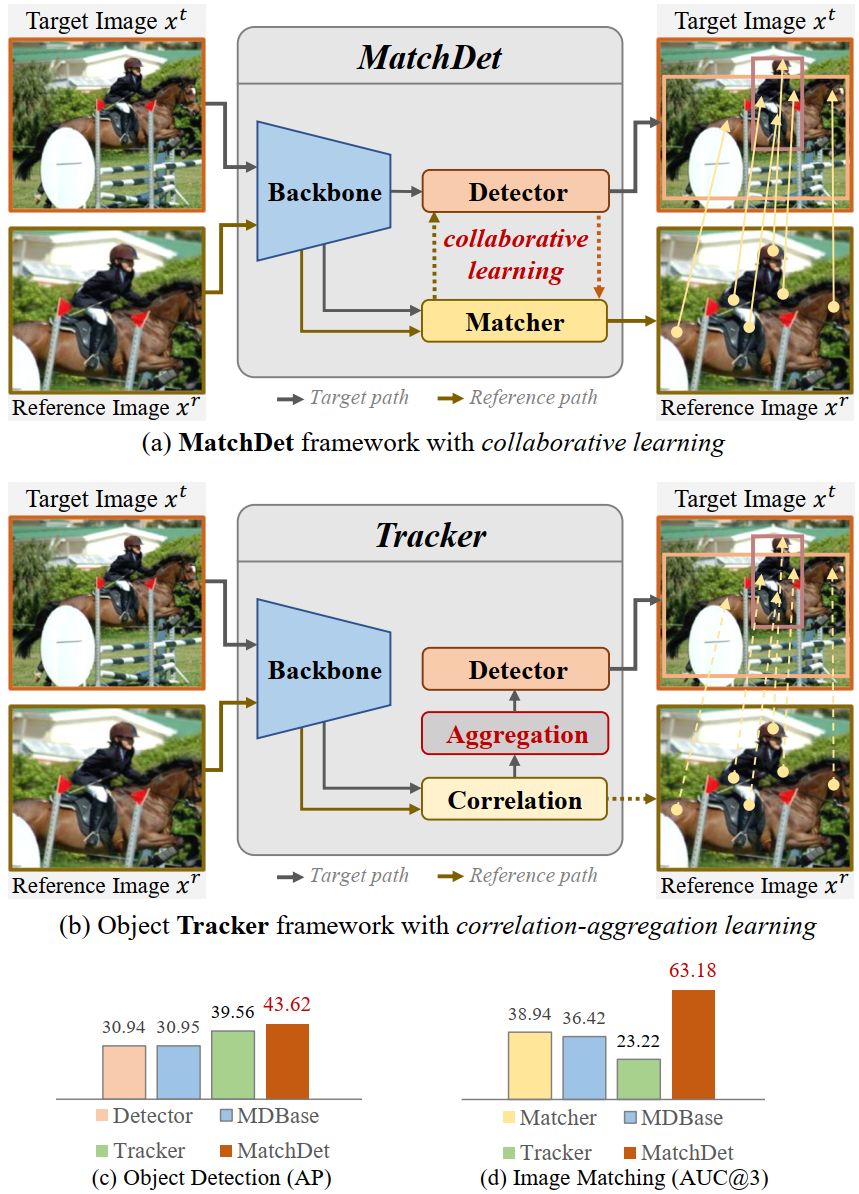
图像匹配和目标检测是两个基础且具有挑战性的任务,而许多相关应用将它们视为两个独立的任务(任务独立)。本文提出了一种名为MatchDet的协作框架(任务协作),可实现图像匹配和目标检测两个任务间的协作。为了实现这两个任务的协作学习,我们提出了三个新模块,包括用于检测器的空间注意力模块(WSAM),用于匹配器的权重注意力模块(WAM)和框过滤器。具体而言,WSAM突出显示目标图像的前景区域,以使后续的检测器受益;WAM增强了图像对的前景区域之间的相关性,以确保高质量的匹配;而框过滤器则减轻了错误匹配的影响。我们在Warp-COCO和miniScanNet这两个新基准数据集上进行评估。实验结果表明,我们的方法是有效的,并取得了有竞争力的性能提升。
论文链接:
https://arxiv.org/pdf/2312.10983.pdf
08
细粒度区域感知图像和谐化算法
FRIH: Fine-grained Region-aware Image Harmonization
Jinlong Peng, Zekun Luo, Liang Liu, Boshen Zhang
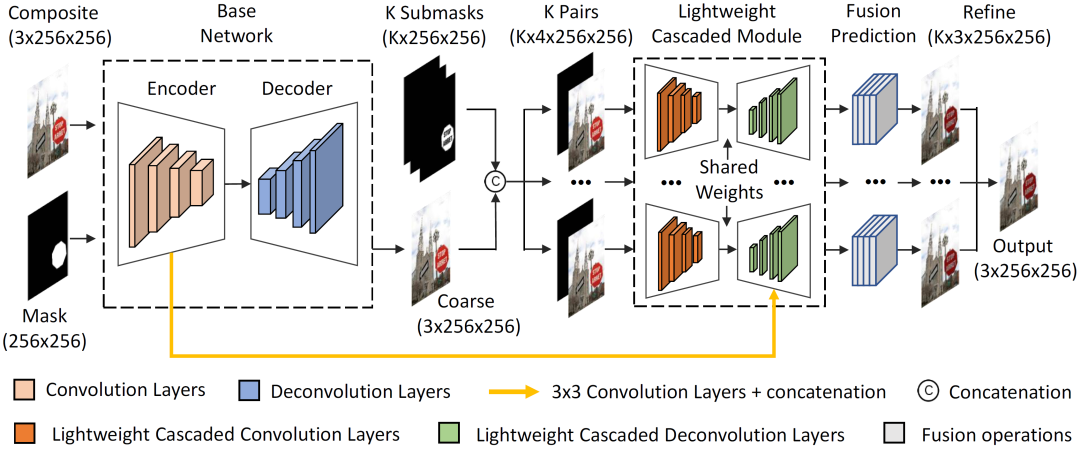
图像和谐化旨在为复合图像生成更真实的前景和背景外观。所有现有的方法都对整个前景执行相同的和谐化过程。然而,嵌入的前景通常包含不同的外观模式。现有的解决方案忽略了每个颜色块的差异,并丢失了一些特定的细节。因此,我们提出了一种新颖的全局-局部两阶段框架,用于细粒度区域感知图像和谐化(FRIH)。在第一阶段,整个输入前景掩码用于进行全局粗粒度的和谐化。在第二阶段,我们自适应地将输入前景掩码聚类为几个子掩码。每个子掩码和粗调整后的图像分别连接,并输入到一个轻量级级联模块中,以改进全局融合结果。此外,我们还设计了一个融合预测模块,综合利用不同程度的融合结果生成最终结果。我们的FRIH在iHarmony4数据集上通过轻量级的模型取得了有竞争性的性能。
论文链接:
https://arxiv.org/pdf/2205.06448.pdf
09
视觉幻觉提升多模态语音识别效果
Visual Hallucination Elevates Speech Recognition
Fang Zhang (USTC), Yongxin Zhu(USTC), Xiangxiang Wang, Huang Chen, Xing Sun, Linli Xu(USTC)
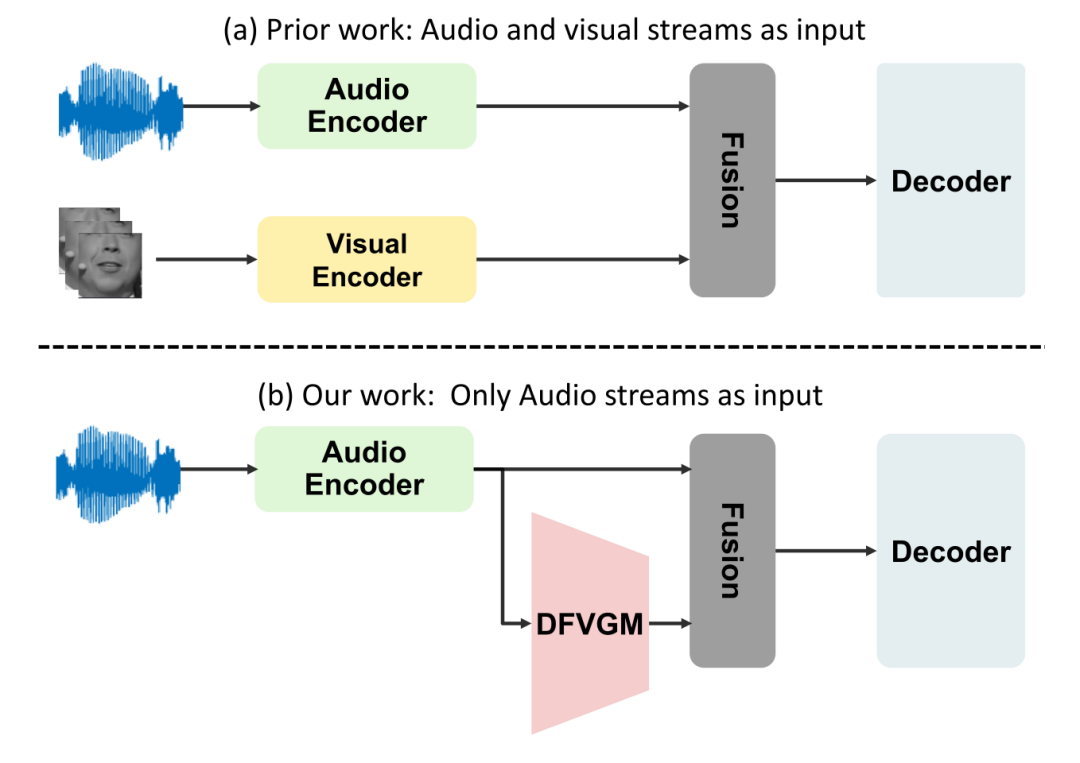
由于噪声对传统音频语音识别的影响,我们提出了一种结合音频和视觉信号的方法。然而,实际应用中并不总是能获取到配对的视频,这产生了视觉缺失模态的问题。为解决这一问题,我们提出了一种基于离散特征的视觉生成模型,该模型在训练中利用音频和视觉的语义对应关系,并在推理中生成视觉幻觉以代替真实视频。我们的方法在两个公开数据集上的实验表明,相比当前最先进的音频单独基线,我们的方法在词错误率上实现了显著的53%的相对降低,同时在不使用视频输入的音频-视觉设置下保持了相当的结果。
10
学习任务感知的语言-图像表征用于类增量目标检测
Learning Task-Aware Language-Image Representation for Class-Incremental Object Detection
Hongquan Zhang*, Bin-Bin Gao*, Yi Zeng, Xudong Tian (ECNU), Xin Tan (ECNU), Zhizhong Zhang (ECNU), Yanyun Qu (XMU), Jun Liu, Yuan Xie (ECNU)
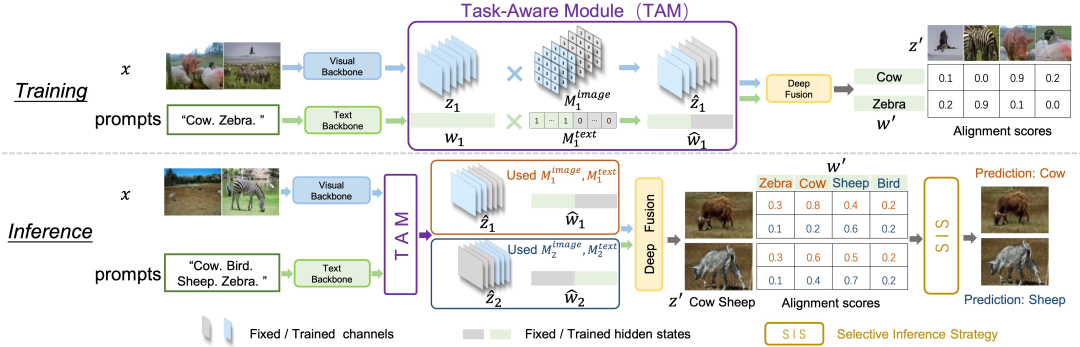
类增量物体检测要求目标检测器能够持续适应新任务的同时不能忘记已学习的旧任务,在实际应用中是迫切需要的能力,其主要挑战在于检测器对已学习的旧任务的灾难性遗忘。许多基于蒸馏和回放的方法已被提出来缓解这个问题。然而,它们通常在纯视觉架构上进行学习,忽视了文本线索的强大表征能力,这在某种程度上限制了它们的性能。在本文中,我们提出了任务感知的语言-图像表征来缓解灾难性遗忘,为基于语言-图像的类增量目标检测引入了新的范式。首先,我们展示了语言-图像检测器在缓解灾难性遗忘方面的显著优势。其次,我们提出了一种学习任务感知的语言-图像表征方法,克服了直接利用语言-图像检测器进行类增量目标检测的缺点。具体来说,通过在训练阶段采用特征隔离方式学习不同任务的语言-图像表征,而在推理阶段使用由任务特定语言-图像表征来对齐预测得分。提出的方法使的语言-图像检测器可以更实用于类增量目标检测任务。在COCO 2017和Pascal VOC 2007上的大量实验证明在各种类增量目标检测的设置下,提出的方法都能达到当前最好的结果。
11
弱半监督医学图像分割
Combinatorial CNN-Transformer Learning with Manifold Constraints for Semi-Supervised Medical Image Segmentation
Huimin Huang, Yawen Huang, Shiao Xie, Lanfen Lin, Ruofeng Tong, Yen-Wei Chen, Yuexiang Li, Yefeng Zheng
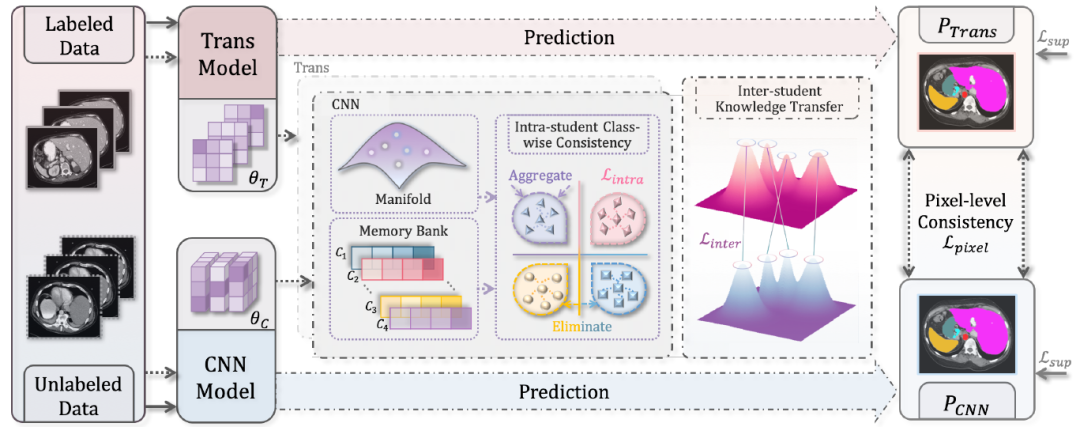
半监督学习(Semi-supervised Learning,SSL)作为主导方法之一,旨在利用未标记的数据来解决监督学习中的标注困境,这在医学图像分割领域引起了广泛关注。大多数现有的方法通过卷积神经网络(CNN)使用单一网络,并通过对输入或模型应用小的扰动来强制保持预测的一致性。然而,这种学习范式的缺点在于:(1)基于CNN的模型对全局学习施加了严重的限制;(2)丰富和多样的类级分布被抑制。在本文中,我们提出了一种新的CNN-Transformer学习框架,用于半监督医学图像分割的流形空间。首先,在学生内部级别,我们提出了一种新颖的类别一致性损失,以促进目标特征表示的判别性和紧凑性学习。然后,在学生之间的级别上,我们使用基于原型的最优传输方法对齐CNN和Transformer特征。大量实验表明,我们的方法在三个公共医学图像分割基准测试中优于先前的最先进方法。
12
使用模态特异编码器和多模态锚点的个性化联邦学习用于脑肿瘤分割
Federated Modality-specific Encoders and Multimodal Anchors for Personalized Brain Tumor Segmentation
Qian Dai (厦门大学), Dong Wei, Hong Liu , Jinghan Sun, Liansheng Wang (厦门大学), Yefeng Zheng
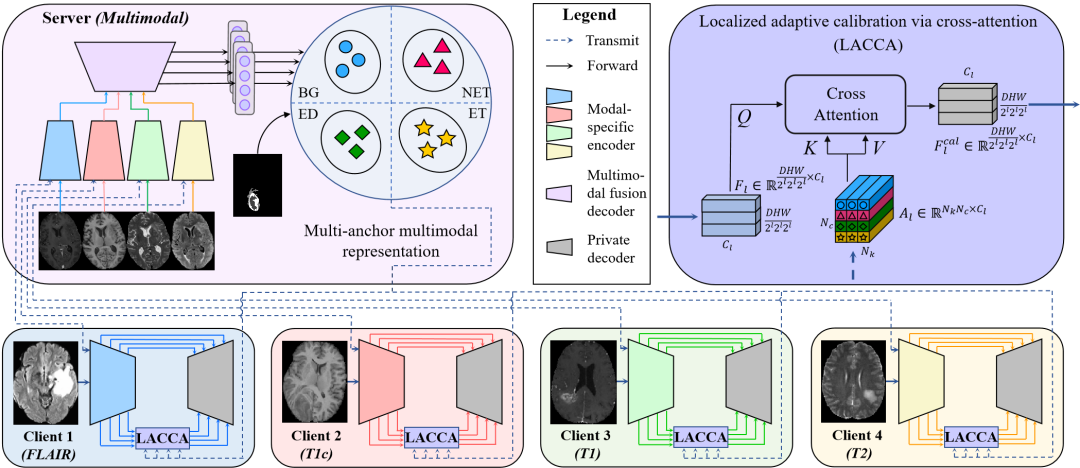
现有的医学图像分析联邦学习(FL)方法大多只考虑了模态内异质性,限制了其在多模态成像应用中的适用性。实际中,有些FL参与者只拥有完整成像模态的子集,这给在所有参与者数据上有效训练全局模型带来了跨模态异质性的挑战。此外,在这种情况下,每个参与者都希望从FL中获得适合其本地数据特性的个性化模型。在这项工作中,我们提出了一种新的FL框架,其中包括联邦模态特定编码器和多模态锚点(FedMEMA),以同时解决这两个问题。首先,FedMEMA为每种模态使用独立的编码器来解决跨模态异质性问题。同时,虽然编码器是由参与者共享的,但解码器是个性化的,以满足个体需求。具体而言,具有完整模态数据的服务器使用融合解码器来融合所有模态特异的编码器的表示,并通过反向传播来优化编码器之间的模态关系。同时,从融合的多模态表示中提取多个锚点,并将其与编码器参数一起分发给客户端。另一方面,具有不完整模态的客户端通过缩放点积交叉注意力机制将其缺失模态的表示校准到全局完整模态锚点,弥补了由于缺失模态而导致的信息损失,同时调整了本地模态的表示。FedMEMA在BraTS 2020多模态脑肿瘤分割基准数据集上进行验证。结果表明,它在多模态和个性化FL方面优于各种最新方法,并且其新颖设计是有效的。
13
使用语义锚点进行约束的表征学习
Beyond Prototypes: Semantic Anchor Regularization for Better Representation Learning
Yanqi Ge*, Qiang Nie*, Ye Huang, Yong Liu, Feng Zheng, Chengjie Wang, Wen Li, Lixin Duan

表示学习的最终目标之一是在类内实现紧凑性,并在类间实现良好的可分性。针对这一目标,已经提出了许多基于度量和原型的杰出方法遵循期望最大化范式。然而,它们不可避免地会引入偏差到学习过程中,特别是在长尾分布的训练数据中。在本文中,我们揭示了类原型不一定需要从训练特征中派生,并提出了一种新的视角,使用预定义的类锚点作为特征中心来单向引导特征学习。然而,预定义的锚点可能与像素特征存在较大的语义距离,这使得它们无法直接应用。为了解决这个问题并生成与特征学习无关的特征中心,我们提出了一种简单而有效的语义锚点正则化(SAR)。SAR通过在训练过程中使用分类器感知的辅助交叉熵损失来确保语义空间中语义锚点的类间可分性,并与特征学习解耦。通过将学习到的特征拉向这些语义锚点,可以获得几个优势:1)类内紧凑性和自然的类间可分性,2)可以避免特征学习引入的偏差或错误,3)对长尾问题具有鲁棒性。所提出的SAR可以以即插即用的方式应用于现有模型中。大量实验证明,SAR在语义分割等视觉任务中的性能甚至优于复杂的原型方法。
14
无监督持续异常检测
Unsupervised Continual Anomaly Detection with Contrastively-learned Prompt
Jiaqi Liu*, Kai Wu*, Qiang Nie, Ying Chen, Bin-Bin Gao, Yong Liu,Jinbao Wang, Chengjie Wang, Feng Zheng
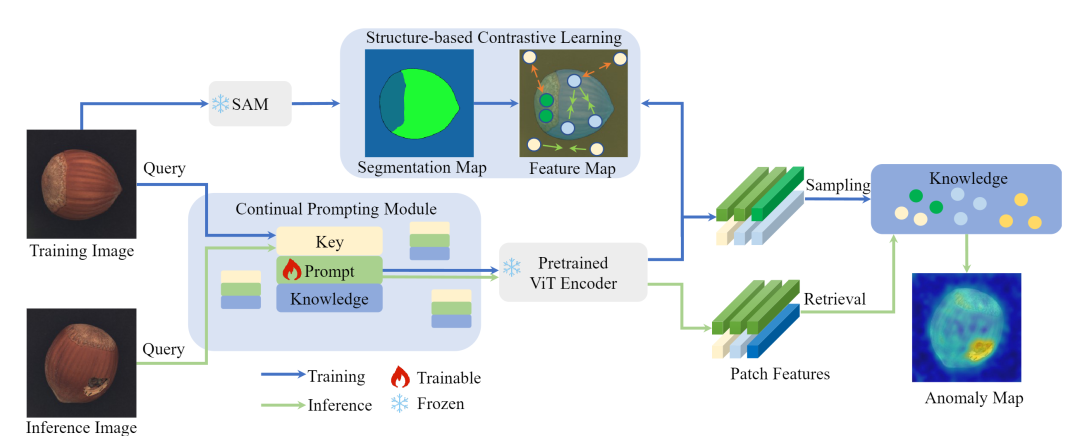
在工业制造中,具有增量训练的无监督异常检测(UAD)至关重要,因为无法获得足够的标记数据来应对不可预测的缺陷。然而,当前的持续学习(CL)方法主要依赖于监督注释,而在UAD中的应用受限于缺乏监督。目前的UAD方法会按顺序为不同的类别训练单独的模型,导致灾难性遗忘和沉重的计算负担。为了解决这个问题,我们引入了一种名为UCAD的新型无监督持续异常检测框架,通过对比学习的提示赋予UAD持续学习能力。在提出的UCAD中,我们设计了一个持续提示模块(CPM),利用简洁的键-提示-知识存储库来引导任务无关的“异常”模型预测,使用任务特定的“正常”知识。此外,我们设计了基于结构的对比学习(SCL),并结合分割任意模型(SAM)来改进提示学习和异常分割结果。具体而言,通过将SAM的掩码视为结构,我们将同一掩码内的特征拉近,并将其他特征推开,以获得通用的特征表示。我们进行了全面的实验,并在无监督持续异常检测和分割方面设定了基准,证明我们的方法在异常检测方面明显优于其他方法,即使使用了回放训练。
15
SoftCLIP: 更柔和的跨模态对齐使CLIP更强大
SoftCLIP: Softer Cross-modal Alignment Makes CLIP Stronger
Yuting Gao*, Jinfeng Liu*, Zihan Xu*, Tong Wu, Enwei Zhang, Wei Liu, Jie Yang, Ke Li, Xing Sun
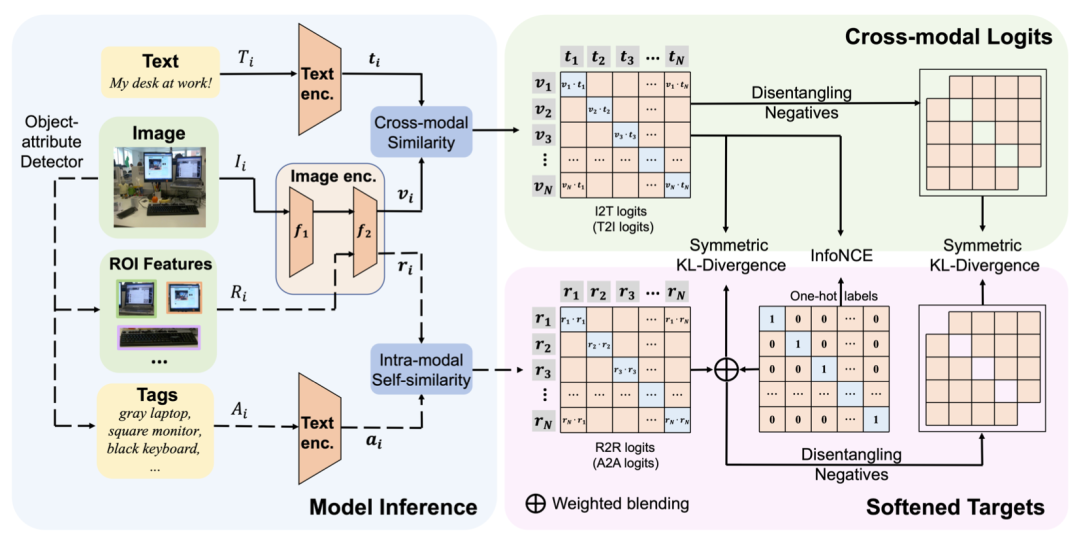
在过去的两年里,视觉-语言预训练在多个下游任务中取得了显著的成功。然而,获取高质量的图像-文本对,仍然是一项具有挑战性的任务,且常用数据集中存在噪声。为解决这个问题,我们提出了一种名为SoftCLIP的新方法,通过引入细粒度模态内自相似性生成软化目标,放宽了严格的一对一约束。软标签可以使两对图文对之间存在一些局部相似性,并在两种模态之间建立多对多的关系。此外,由于在软化标签中,正样本仍然占有主导地位,我们将正负样本进行了解耦,以进一步提升跨模态学习中的负样本关系对齐。大量的实验证明了SoftCLIP的有效性,特别是在ImageNet零样本分类任务中,使用CC3M/CC12M作为预训练数据集,SoftCLIP相比于CLIP基线,带来了6.8%/7.2%的top-1准确率提升。
论文链接:
https://arxiv.org/pdf/2303.17561.pdf
16
COOPER:面向复杂对话目标的专业代理协调方法
COOPER: Coordinating Specialized Agents towards a Complex Dialogue Goal
Yi Cheng (The Hong Kong Polytechnic University), Wenge Liu (Baidu), JianWang (The Hong Kong Polytechnic University), Chak Tou Leong (The Hong Kong Polytechnic University),Yi Ouyang, Wenjie Li (The Hong Kong Polytechnic University), Xian Wu, Yefeng Zheng
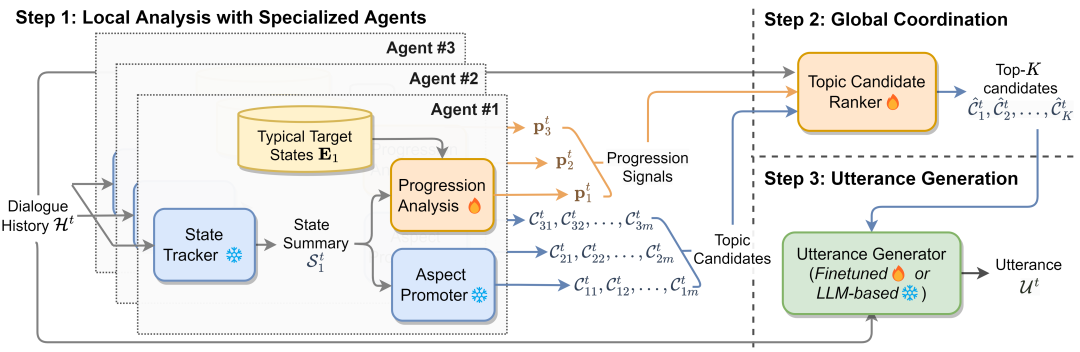
近年来,人们对探索具有更复杂目标的对话越来越感兴趣,例如谈判、说服和情绪支持,这些都超越了传统的服务型对话系统。除了需要更复杂的策略性推理和沟通技巧外,这些任务的一个重大挑战在于,它们的目标实现难以以可量化的方式客观衡量,这使得现有的研究难以直接优化对话过程以实现这些目标。在我们的工作中,我们强调复杂对话目标的多面性,并认为通过全面考虑并共同推动其不同方面,更有可能实现这些目标。为此,我们提出了一个新的对话框架,COOPER,它协调多个专门的代理,每个代理分别致力于特定的对话目标方面,以接近复杂的目标。通过这种分而治之的方式,我们使复杂的对话目标更易于接近,并通过各个代理的协作引发更大的智能。在说服和情绪支持对话的实验中,我们的方法对比基线能达到更好的性能。
17
基于域幻化更新的多域人脸活体检测
Domain-Hallucinated Updating for Multi-Domain Face Anti-spoofing
Chengyang Hu (Shanghai Jiao Tong University), Ke-Yue Zhang, Taiping Yao, Shice Liu, Shouhong Ding, Xin Tan (East China Normal University), Lizhuang Ma (Shanghai Jiao Tong University)
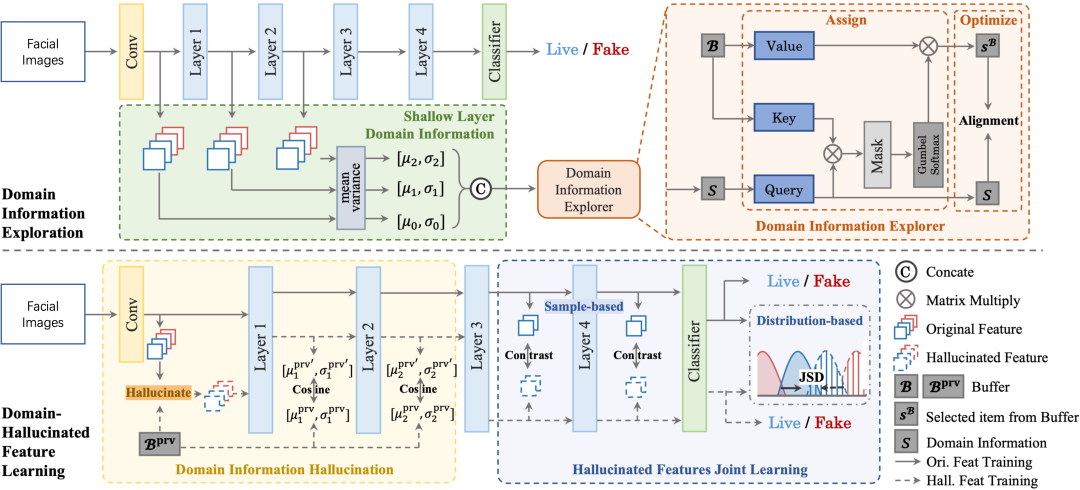
多域人脸活体检测 (MD-FAS) 旨在仅使用新域数据更新新域的模型,同时确保不会忘记从旧域获得的知识。现有方法利用模型的特征来表示旧域知识或将不同的域映射到单独的特征空间中以防止遗忘。然而,由于域差距的存在,新数据的特征不如之前数据的准确。此外,如果没有先前数据提供监督,分离的特征空间可能会在新域上更新时被破坏,从而导致灾难性遗忘。受到缺乏旧域数据所带来的挑战的启发,我们从一个新的角度解决了这个问题,即幻化出旧域数据来更新 FAS 模型。为此,我们提出了一种新颖的域幻化更新(DHU)框架来促进数据的幻化。具体地,域信息浏览器学习旧域的代表性域信息。然后,域信息幻化模块将新域数据幻化成伪旧域数据。此外,提出了幻化特征联合学习模块,通过双级别不对称地对齐真实样本的新域数据和伪旧域数据,以学习更通用的特征,从而促进所有域的结果。我们的实验结果和可视化结果表明,所提出的方法在有效性方面优于最先进的竞争对手。
18
基于预训练在线对比学习的保险欺诈检测方法
Pre-trained Online Contrastive Learning for Insurance Fraud Detection
Rui Zhang (Tongji University, Shanghai AI Lab), Dawei Cheng (Tongji University, Shanghai AI Lab), Jie Yang (Tongji University), Yi Ouyang, Xian Wu, Yefeng Zheng, Changjun Jiang (Tongji University, Shanghai AI Lab)
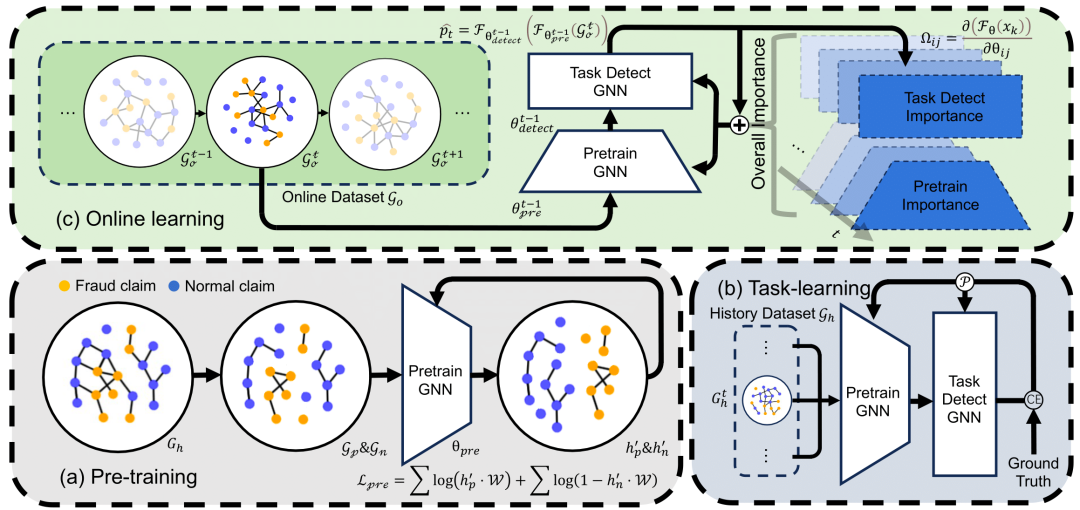
医疗保险反欺诈是医疗行业领域的一个重要研究问题。现有的欺诈检测模型主要关注离线学习场景。然而,欺诈模式不断演变,使得基于过去数据训练的模型难以检测新出现的欺诈模式,这给医疗欺诈检测带来了严重的挑战。此外,当前的增量学习模型主要用于解决灾难性遗忘问题,但在欺诈检测中的表现往往不尽如人意。为了解决这一挑战,本文提出了一种创新的在线学习方法,用于医疗保险欺诈检测。该方法将对比学习预训练与在线更新策略相结合。在预训练阶段,我们利用对比学习预训练在历史数据上进行无监督学习,实现深度特征学习并获得丰富的风险表示。在在线学习阶段,我们采用时间记忆感知突触在线更新策略,使模型能够根据不断涌现的新数据进行增量学习和优化。这确保了模型及时适应欺诈模式,减少了对过去知识的遗忘。我们的模型在真实世界的保险欺诈数据集上进行了大量的实验和评估。结果表明,与现有的基线方法相比,我们的模型在准确性方面具有显著优势,同时还表现出较低的运行时间和空间消耗。
19
VMT-Adapter: 面向多任务密集场景理解的高效参数迁移学习
VMT-Adapter: Parameter-Efficient Transfer Learning for Multi-Task Dense Scene Understanding
Yi Xin, Junlong Du, Qiang Wang, Zhiwen Lin, Ke Yan
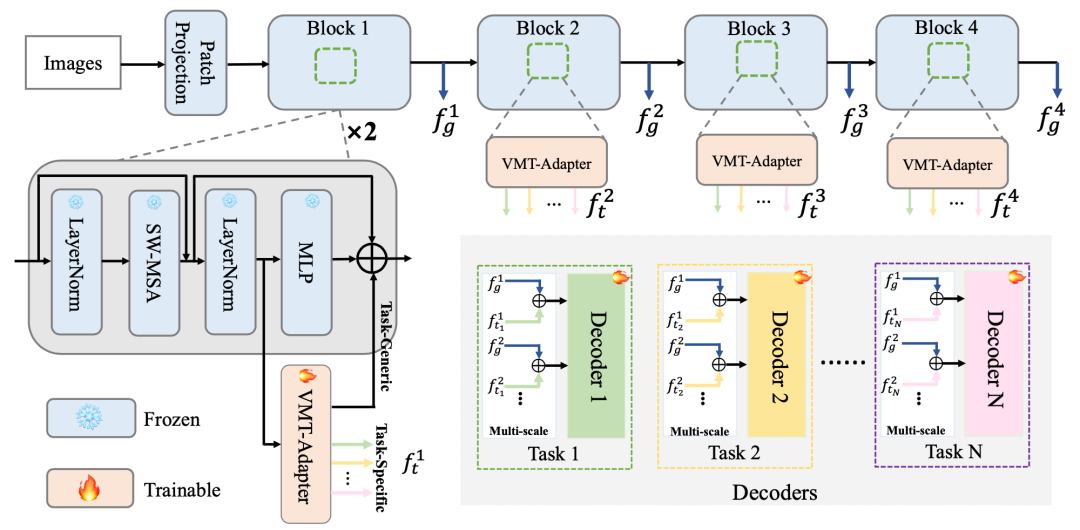
近期,大规模预训练模型在多种视觉下游任务中取得了显著提升,然而对预训练模型进行全量参数微调提升了模型的计算和存储成本。在自然语言处理领域的启发下,参数高效微调方法(PETL)在视觉任务中得到成功的应用,但现有技术主要聚焦于单任务的适配,如何更好地将参数高效微调方法应用于视觉多任务学习中仍是一个挑战。本文提出了一种“once-for-all”的视觉多任务适配方法(VMT-Adapter),具有极高的训练和推理效率,在任务数上具有O(1)的时间复杂度,这使得VMT-Adapter可以利用极少的参数处理几乎任意数量的任务。VMT-Adapter不仅通过参数共享实现了跨任务信息交互,同时还为每个任务单独设置了知识提取模块来保留任务的特定知识。本文在包含4个密集场景理解任务的数据集上验证了方法的有效性:VMT-Adapter仅利用预训练模型1%的参数量,便可以取得3.96%的显著提升。
20
MmAP: 面向跨域多任务学习的多模态对齐提示
MmAP : Multi-modal Alignment Prompt for Cross-domain Multi-Task Learning
Yi Xin, Junlong Du, Qiang Wang, Ke Yan, Shouhong Ding
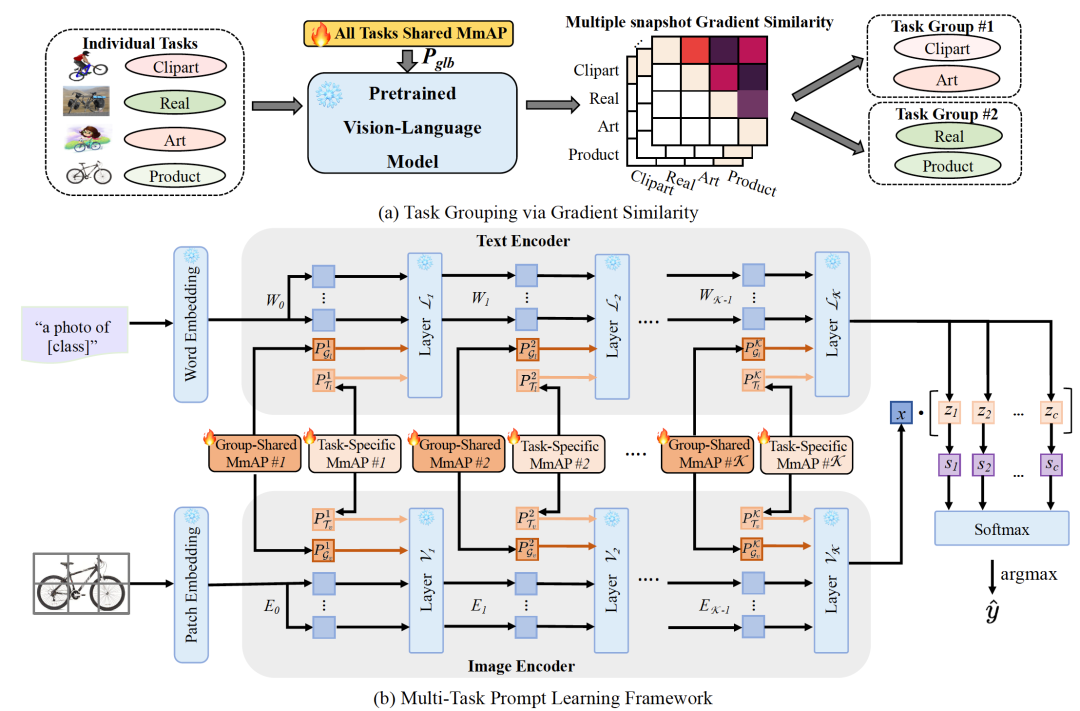
多任务学习(MTL)旨在同时训练多个相关任务,并提高各个子任务的效果。面向多任务学习的网络结构通常会为每一个任务设置独立的解码器(decoder)结构,因此,解码网络的计算复杂度会随着任务数量的增加而线性增加。为了解决这个问题,本文将图文预训练模型CLIP引入跨域多任务学习中,利用提示学习实现了一种“decoder-free”的多任务学习框架。本文认为,尽管针对CLIP的提示学习已经在多个视觉任务中表现出优越的性能,但是现有方法仅对CLIP的单一模态(文本或视觉)进行微调,破坏了CLIP的模态对齐。因此,本文首先提出了一种针对CLIP的多模态对齐提示(MmAP),以实现对文本和视觉模态的同时调整,保持CLIP的模态对齐特性。在MmAP基础上,本文设计了一种新颖的多任务提示学习框架。一方面,我们利用梯度驱动的任务分组方法,实现高相似性任务之间互补性的最大化;另一方面,我们为每个任务分配特定的MmAP,以保留任务的特有信息。在两个大型多任务学习数据集上,相比于全量参数微调,本文提出的方法在仅利用约0.09%的可训练参数的情况下,实现了显著的性能提升。
21
PCE-Palm:基于手掌折痕能量的两阶段拟真掌纹生成
PCE-Palm: Palm Crease Energy based Two-stage Realistic Pseudo-palmprint Generation
Jianlong Jin(HUT/Tencent), Lei Shen, Ruixin Zhang, Jingyun Zhang, Ge Jin, Chenglong Zhao, Shouhong Ding, Yang Zhao(HUT), Wei Jia(HUT)
*本文由腾讯优图实验室、腾讯微信支付33号实验室、合肥工业大学共同完成
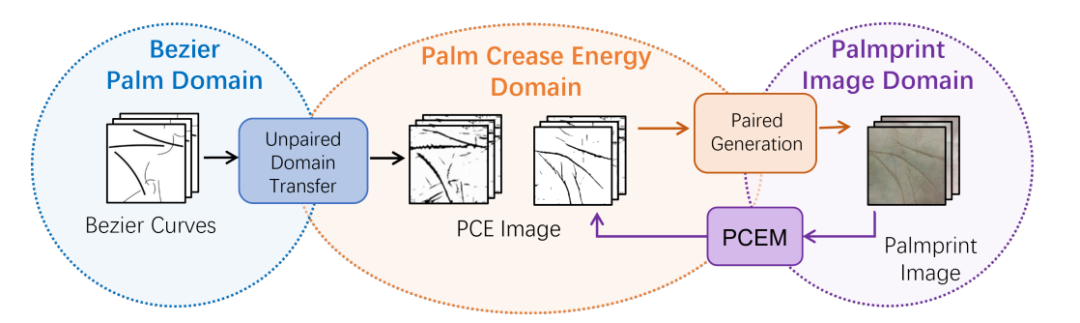
大规模数据的缺乏严重阻碍了掌纹识别的发展。近期方法提出基于贝塞尔曲线生成大规模拟真掌纹来解决这个问题。然而,贝塞尔曲线和真实掌纹之间的显着差异限制了它们的有效性。在本文中,我们将贝塞尔曲线到真实掌纹的差异分为折痕差异和纹理差异,通过分拆降低生成难度。具体来说,我们引入了一种新的手掌折痕能量(PCE)域作为从贝塞尔曲线到真实掌纹的桥梁,并提出了一个两阶段生成模型。第一阶段从贝塞尔曲线生成 PCE 图像(拟真折痕),第二阶段以 PCE 图像作为输入输出真实的掌纹(拟真纹理)。此外,我们还设计了一个轻量级的即插即用线路特征增强块,以方便域转移并提高识别性能。大量的实验结果表明,我们提出的方法超越了最先进的方法。在极少的数据设置下(如 40 个 ID,仅占总训练集的 2.5%),在TAR@FAR=1e-6条件下,我们的方法相对RPG-Palm 提升 29%,相对100%训练集的 ArcFace 提升6%。
22
HDMixer:基于可扩展Patch与层级依赖的多元时间序列预测
HDMixer: Hierarchical Dependency with Extendable Patch for Multivariate Time Series Forecasting
Qihe Huang(USTC/Tencent), Lei Shen, Ruixin Zhang, Jiahuan Cheng, Shouhong Ding, Zhengyang Zhou (USTC) , Yang Wang (USTC)
*本文由腾讯优图实验室、中国科学技术大学共同完成
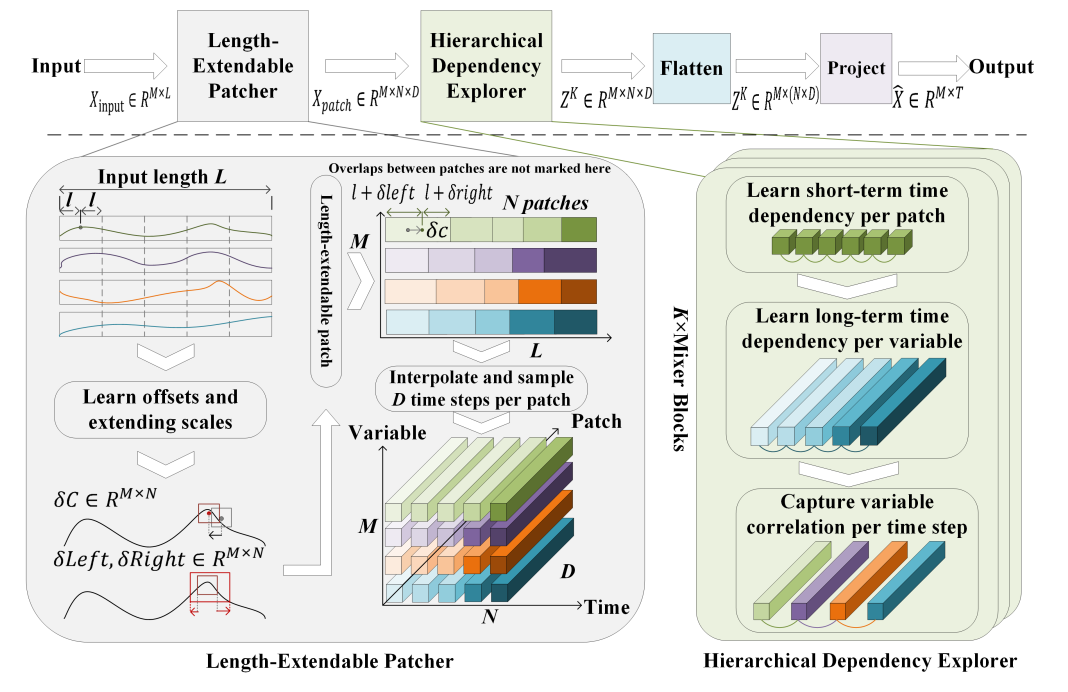
多元时间序列(MTS)预测已广泛应用于各种场景。最近,一些方法采用patch来增强局部语义并提高模型性能。然而,长度固定的patch很容易丢失时间边界信息,例如完整的峰值和周期。此外,现有方法主要侧重于对patch之间的长期依赖性进行建模,而很少关注其他维度(例如patch内的短期依赖性以及跨变量patch之间的复杂交互)。为了解决这些挑战,我们提出了一种纯基于 MLP 的 HDMixer,旨在通过有效地建模分层交互来获取具有更丰富语义信息的patch。具体来说,我们设计了一个针对 MTS 的长度可扩展patch(LEP),它丰富了patch的边界信息并减轻了系列中的语义不连贯。随后,我们设计了一个基于纯 MLP 的分层依赖关系展示器(HDE)。该展示器可以有效地模拟patch内的短期依赖关系、patch之间的长期依赖关系以及patch之间的复杂交互。对 9 个真实世界数据集的广泛实验证明了我们方法的优越性。
23
弱监督开放词汇目标检测
Weakly Supervised Open-Vocabulary Object Detection
Jianghang Lin ( Xiamen University ),Yunhang Shen ( Tencent ),Bingquan Wang ( Xiamen University ),Shaohui Lin ( East China Normal University ) ,Ke Li ( Tencent ),Liujuan Cao ( Xiamen University )
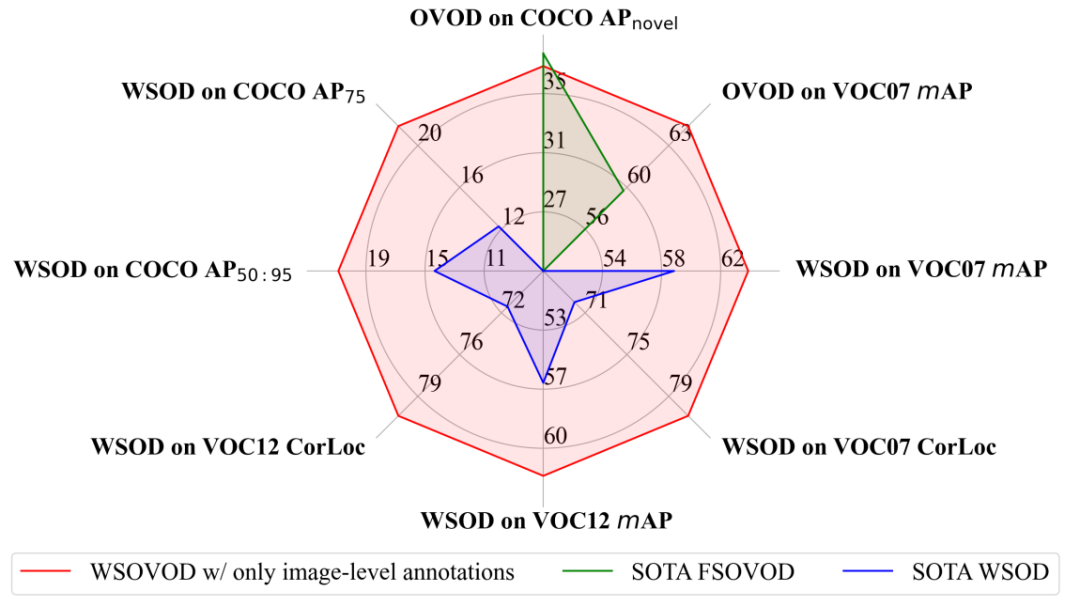
尽管弱监督目标检测(WSOD)是避免使用实例级别标注的有前途的方法,但其能力仅限于单个训练数据集中的封闭集类别。在本文中,我们提出了一种新颖的弱监督开放词汇目标检测框架,即WSOVOD,将传统的WSOD扩展为检测新概念,并利用只有图像级别注释的不同数据集。为了实现这一目标,我们探索了三种关键策略,包括数据集级别的特征适应,图像级别的显著目标定位,以及区域级别的视觉语言对齐。首先,我们进行数据感知特征提取,以产生输入条件的系数,该系数被利用到数据集属性原型中以识别数据集偏差并帮助实现跨数据集泛化。其次,我们提出了一个定制的位置导向的弱监督候选区域网络,以利用来自类别无关的分割任何模型的语义布局来区分目标边界。最后,我们引入了一种候选区域概念同步的多实例网络,即目标挖掘和与视觉语义对齐的细化,以发现与概念文本嵌入匹配的目标。在Pascal VOC和MS COCO上的大量实验表明,所提出的WSOVOD在封闭集目标定位和检测任务中都比之前的WSOD方法更好,并取得了新的最先进水平结果。同时,WSOVOD实现了弱监督下的跨数据集和开放词汇学习,并且取得了与全监督开放词汇目标检测(FSOVOD)相当甚至更好的效果。
论文链接:
https://arxiv.org/abs/2312.12437
24
SPD-DDPM:对称正定空间中的去噪扩散概率模型
SPD-DDPM: Denoising Diffusion Probabilistic Models in the Symmetric Positive Definite Space
Yunchen Li ( East China Normal University ),Zhou Yu ( School of Statistics, East China Normal University ),Gaoqi He ( East China Normal University ) ,Yunhang Shen ( Tencent ),Ke Li ( Tencent ) ,Xing Sun ( Tencent ),Shaohui Lin ( East China Normal University )
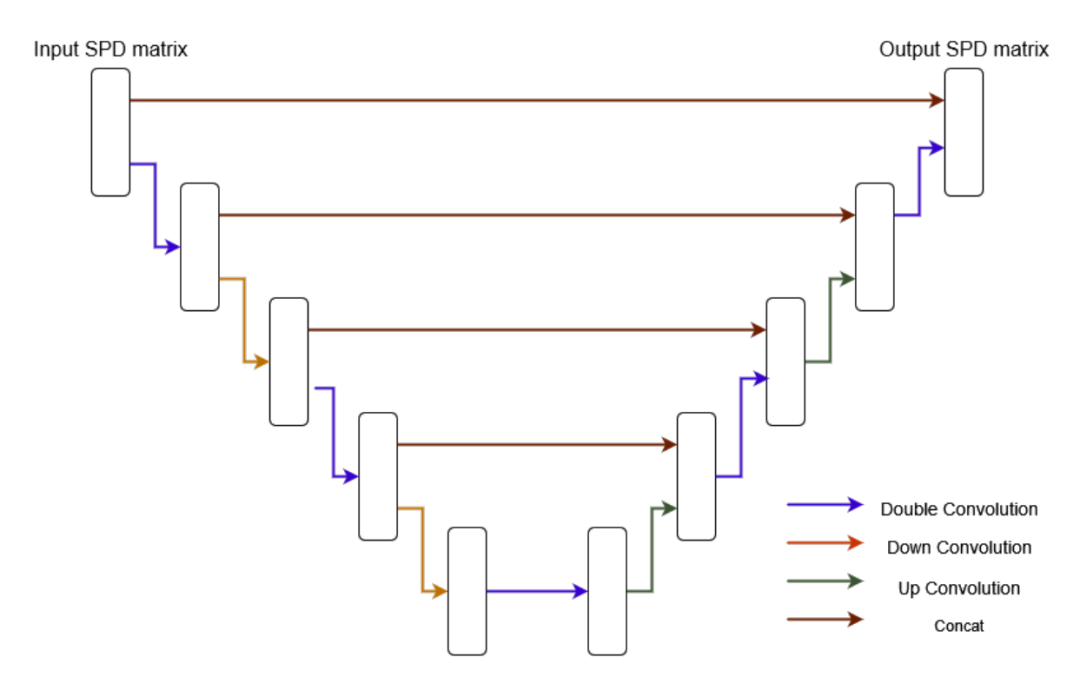
对称正定(SPD)矩阵在统计和机器学习领域(如fMRI分析和交通预测)中已经显示出重要的价值和应用。之前的SPD矩阵工作主要集中在判别模型上,其中预测是对E(X|y)的直接进行,其中y是一个向量,X是一个SPD矩阵。然而,这些方法在大规模数据处理中具有挑战性,因为它们需要访问和处理整个数据。在本文中,受到去噪扩散概率模型(DDPM)的启发,我们通过在SPD空间中引入高斯分布来估计E(X|y),从而提出了一种新的生成模型,称为SPD-DDPM。此外,我们的模型能够在不需要给定的情况下无条件且灵活地估计p(X)。一方面,该模型有条件地学习p(X|y),并利用样本均值获得E(X|y)作为预测。另一方面,该模型无条件地学习数据概率分布p(X)并生成符合该分布的样本。此外,我们还提出了一种新的SPD网络,它比之前的网络更深,并且允许包含条件因素。在玩具数据和真实出租车数据上的实验结果表明,我们的模型有效地拟合了无条件以及有条件的数据分布,并且提供了准确的预测。
论文链接:
https://arxiv.org/abs/2312.08200
25
通过知识蒸馏和增量学习进行半监督的盲图像质量评估
Semi-Supervised Blind Image Quality Assessment through Knowledge Distillation and Incremental Learning
Wensheng Pan ( Xiamen University ),Timin Gao ( Xiamen University ) ,Yan Zhang ( Xiamen University ),Xiawu Zheng ( Peng Cheng Laboratory ),Yunhang Shen ( Tencent ) ,Ke Li ( Tencent ) ,Runze Hu ( Beijing Institute of Technology ),Yutao Liu ( Ocean University of China ) ,Pingyang Dai ( Xiamen University )
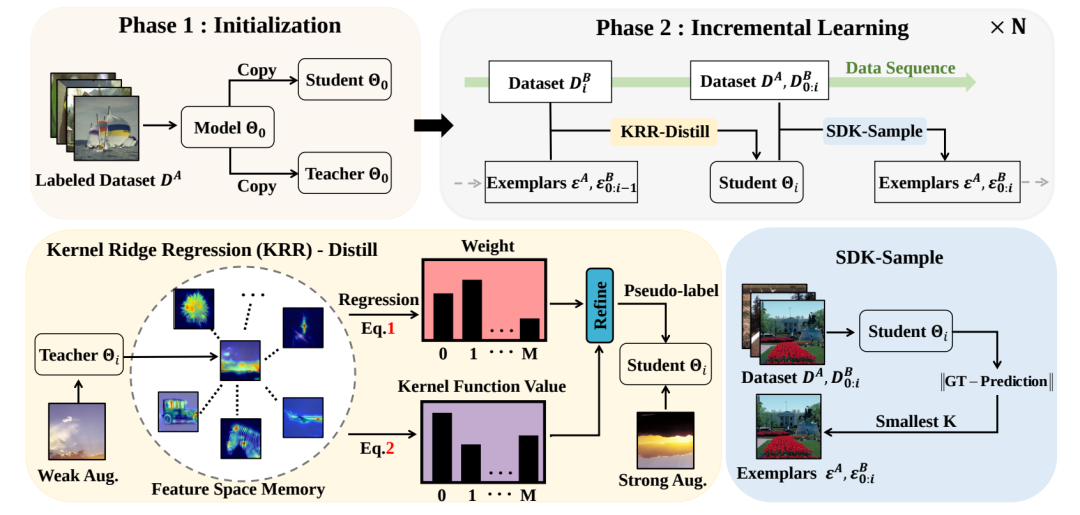
盲图像质量评估(BIQA)旨在复制人类对图像失真的评估。因此,它对标注数据的需求很大,而在实践中远远不够。一些研究人员利用无监督方法来避免这个问题,但很难模拟人类主观系统。为此,我们提出了一个统一的半监督增量学习框架来解决上述问题。具体来说,当训练数据不足时,需要半监督学习来推断大量无标签数据。同时,多次半监督学习很容易导致灾难性遗忘问题,因此需要增量学习。更具体地说,我们采用知识蒸馏为无标签数据提供伪标签,以保留分析能力,从而实现半监督学习。同时,我们利用增量学习在多次半监督学习中选择代表性示例来修正先前数据,从而确保我们的模型不会退化。实验结果表明,所提出的算法在多个基准数据集上实现了最先进的性能。在经过TID2013数据集的训练后,所提出的方法可以直接转移到另一个数据集,与监督方法的忽略性能下降(-0.013)相比,同时优于无监督方法。总的来说,我们的方法表明了它在解决实际生产过程挑战方面的潜力。
26
基于去相关特征查询的域泛化医学图像分割方法
Learning Generalized Medical Image Segmentation from Decoupled Feature Queries
Qi Bi ( Tencent/Wuhan University ),Jingjun Yi ( Tencent/Wuhan University ),Hao Zheng ( Tencent ),Wei Ji ( University of Alberta ),Yawen Huang ( Tencent ),Yuexiang Li ( Guangxi Medical University ),Yefeng Zheng ( Tencent )
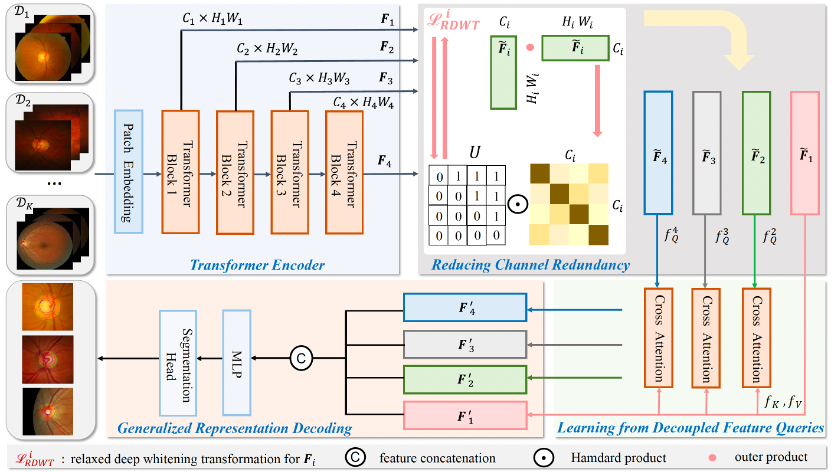
域泛化医学图像分割场景指模型在多个源域上训练,并在未见过的目标域上测试其泛化能力。由于收集自不同医院的图像可能使用不同的成像设备和扫描参数,不同中心的数据分布会有显著区别。理想的高泛化性特征在同一通道内对跨域图像具有相似的模式响应。然而,在应对显著的分布差异时,网络倾向于通过多个通道来捕获各源域图像上的同一模式,并允许同一通道中在跨域图像上表现出不同的激活模式。对此,我们提出以最小化跨域医学图像之间的通道相关性来消除特征冗余并最大化每个通道的表达能力。首先,我们提出了一种新的白化变换,更加高效地完成通道间的解耦。由于特征去相关并不能保证来自不同域的医学图像在同一通道内具有相似的激活模式,我们进一步基于自注意机制引入一种隐藏的约束。我们将解耦的深层特征作为查询,去相关的浅层特征作为键和值。解耦的深层特征与浅层特征之间的内在依赖要求跨域表达具有一致性,提升了模型的域泛化分割能力。
27
通过输入-输出协同蒸馏的联邦学习
Federated Learning via Input-Output Collaborative Distillation
Xuan Gong ( Harvard Medical School ) ,Shanglin Li ( Beihang University ) ,Yuxiang Bao ( Beihang University ) ,Barry Yao ( Virginia Tech ) ,Yawen Huang ( Tencent ) ,Ziyan Wu ( United Imaging Intelligence ) ,Baochang Zhang ( Beihang University ) ,Yefeng Zheng ( Tencent ) ,David Doermann ( University at Buffalo )
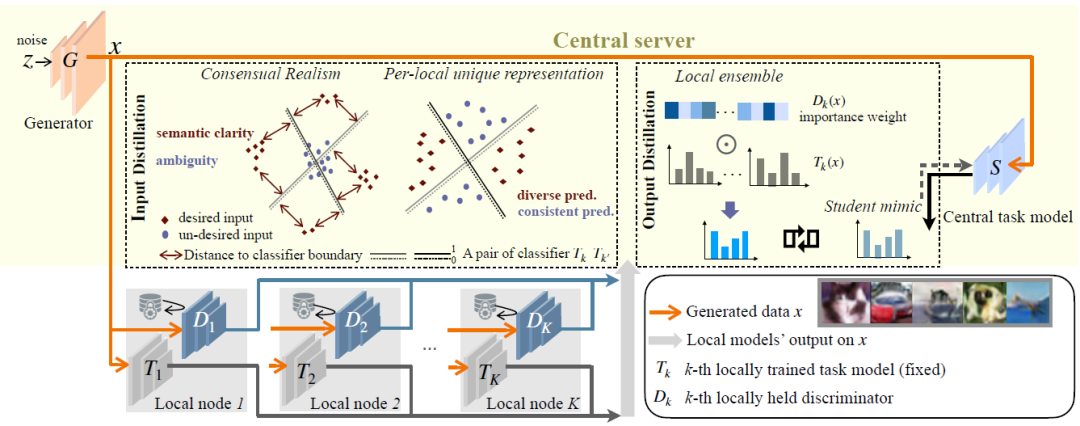
联邦学习(FL)是一种机器学习范式,其中分布式的本地节点协同训练一个中心模型,而无需共享各自持有的私有数据。现有的FL方法要么迭代共享本地模型参数,要么部署共同蒸馏。然而,前者极易导致私有数据泄露,后者的设计依赖于任务相关真实数据的前提条件。相反,我们提出了一个基于本地到中心协同蒸馏的无数据FL框架,直接利用输入和输出空间。我们的设计消除了递归本地参数交换或辅助任务相关数据传递知识的任何需求,从而直接将隐私控制权交给本地用户。特别是,为了应对本地之间固有的数据异质性,我们的技术学会在每个本地模型产生一致而独特结果的输入上进行蒸馏,以代表每个专业知识。我们通过在图像分类、分割和重建任务上的大量实验,证明了我们提出的FL框架在自然和医学图像的各种真实世界异质联邦学习设置下,实现了最先进的隐私-效用权衡。
CVPR / ICCV 2023论文和代码下载
后台回复:CVPR2023,即可下载CVPR 2023论文和代码开源的论文合集
后台回复:ICCV2023,即可下载ICCV 2023论文和代码开源的论文合集- 计算机视觉和Transformer交流群成立
- 扫描下方二维码,或者添加微信:CVer444,即可添加CVer小助手微信,便可申请加入CVer-计算机视觉或者Transformer 微信交流群。另外其他垂直方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch、TensorFlow和Transformer、NeRF等。
- 一定要备注:研究方向+地点+学校/公司+昵称(如目标检测或者Transformer+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群
- ▲扫码或加微信号: CVer444,进交流群
- CVer计算机视觉(知识星球)来了!想要了解最新最快最好的CV/DL/AI论文速递、优质实战项目、AI行业前沿、从入门到精通学习教程等资料,欢迎扫描下方二维码,加入CVer计算机视觉(知识星球),已汇集近万人!
-
- ▲扫码加入星球学习
▲点击上方卡片,关注CVer公众号
