
热门标签
热门文章
- 1鸿蒙开发套件申请,鸿蒙开发快速入门之:Hi3861 开发板(2)环境搭建
- 2公司小程序,公众号申请支付流程_小程序账号申请公众号
- 3第15.12节PyQt(Python+Qt)入门学习:可视化设计界面组件布局详解_pyqt 布局
- 4Web逆向、软件逆向、安卓逆向、APP逆向,关于网络安全这些你必须懂_软件逆向安全工程
- 5搭建本地大模型和知识库,最简单的方法_ollama本地知识库
- 6一文搞懂全链路监控:方案概述与比较 | 干货
- 7Qt6入门教程 5:添加资源和应用程序图标_pyqt6 resource compiler在哪里
- 8Android开发学习---repositories配置_android repositories
- 9跨端开发框架:一次编码,多端运行的终极解决方案
- 10Linux Mii management/mdio子系统分析之六 fixed-mii_bus分析(mac2mac分析)_mac-mac 模式下的 fixed-link
当前位置: article > 正文
朴素贝叶斯算法实现文本分析_基于朴素贝叶斯算法的文本评价
作者:不正经 | 2024-04-06 09:06:47
赞
踩
基于朴素贝叶斯算法的文本评价
朴素贝叶斯算法实现文本分析
最近在公司做的一个用户发言分析的项目中用到了文本分析,就产生一个对之前所学的文本分析方法做一个总结,今天主要想讲一讲朴素贝叶斯算法实现的文本分析.
朴素贝叶斯:
在学习机器学习算法之前,必须明确的一点就是,任何一个算法都是基于一定的统计学方法对一个事件进行预估,并按照最大概率假设这件事的结果.朴素贝叶斯算法或者说朴素贝叶斯分类器就是基于朴素贝叶斯定理来实现的.
贝叶斯定理:贝叶斯定理是描述两个事件(事件A, 事件B)之间条件概率的定理.
有一个公式说明了这个定理:
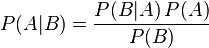
简单来说,这个公式说明了在事件B发生的前提下,事件A发生的概率,可以用 事件A发生的前提下事件B发生的概率 乘以 事件A发生的概率 除以 事件B发生的概率得出.
来认识几个名词:
先验概率: P(A), P(B) 被称为先验概率, 这是因为其只考虑单事件的各方因素而忽略其他事件的影响而得出的.
后验概率:P(A|B), P(B|A)分别被称为A和B的后验概率,其综合了两个事件之间的联系而得出.
朴素贝叶斯分类:
在了解贝叶斯定理之后,朴素贝叶斯分类的实现也就不难理解了.
朴素贝叶斯分类是基于贝叶斯定理的,首先它是一个监督学习算法,也就是说,类别已经事先规定好,分类器需要做的事就是,计算该样本发生的情况下在各类别中出现的概率,然后对其进行排序,取概率最大的分类作为最后的结果.我们规定训练集中的每个样本必须唯一,因此 只需要计算p(B|A)XP(A)即可.
文本分析代码实现:
sklearn 是一个实现机器学习算法的第三方库,在此,我就直接借此库展示朴素贝叶斯算法实现的文本分析:
from sklearn.model_selection import train_test_split from sklearn.feature_extraction.text import TfidfVectorizer from sklearn.naive_bayes import MultinomialNB import pandas as pd def verify(): data = pd.read_excel('question.xlsx', index_col=0).head(120) x_train, x_test, y_train, y_test = train_test_split(data['questions'], data['flags'], test_size=0.2, random_state=23) # 特征工程 transfer = TfidfVectorizer() x_train = transfer.fit_transform(x_train) x_test = transfer.transform(x_test) # 朴素贝叶斯算法预估器 estimator = MultinomialNB() estimator.fit(x_train, y_train) # 模型评估 score = estimator.score(x_test, y_test) print(score) # 预测 y1_predict = estimator.predict(x_test) data = pd.read_excel('question.xlsx', index_col=0).fillna('haha') x_predict = transfer.transform(data.iloc[120:, 0]) y_predict = estimator.predict(x_predict) print(y_predict)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/不正经/article/detail/370984
推荐阅读
相关标签

