
- 1基于深度学习、机器学习,神经网络,OpenCV,图像处理,卷积神经网络计算机毕业设计题目大全_基于神经网络的毕设题目
- 2使用python计算RMSR、MRE和R方、MAE_python实现rmse
- 3关于QWidget里的Widget::paintEvent (QPaintEvent * event)显示图片的问题(即qpainter.drawPixmap)_widget中paintevent无效
- 420240326 每日AI必读资讯_gatekeep ai 网址
- 5微信小程序的N种页面跳转方式(2024最新)_微信小程序页面跳转
- 6YOLOv8-seg 分割代码详解(一)Predict
- 7MATLAB 线性拟合直线示例 + MATLAB线性拟合中文文档(决定系数R^2公式与解释 与 带惩罚项的修改R^2)_matlab拟合直线
- 8爬虫实战——中国天气网数据_爬取天气预报的目的
- 9paddleocr的基本使用_paddleocr zlibwapi.dll
- 10word2vec原理详解及实战_word2vec原理与实战详解(一)
NLP自然语言处理学习笔记_nlpqi
赞
踩
前言
开始基础:具备基础的编程能力,了解机器学习的基本概念,但是没有NLP领域的实践经历。
目的/目标:理解NLP的逻辑和原理,掌握文本分类/情感分析及相关的实践能力,能运用在实际问题的解决中。
阶段一
目标:学习NLP的基本概念,理解NLP工程实践的过程,并动手操作,依葫芦画瓢。
特点:大量输入、消化吸收,间接经验为主。
1.数据处理
使用机器学习模型,计算机只能处理数值信息,计算机语言是0和1。
1.1 数值化信息 Categorical Features & Numerical Features
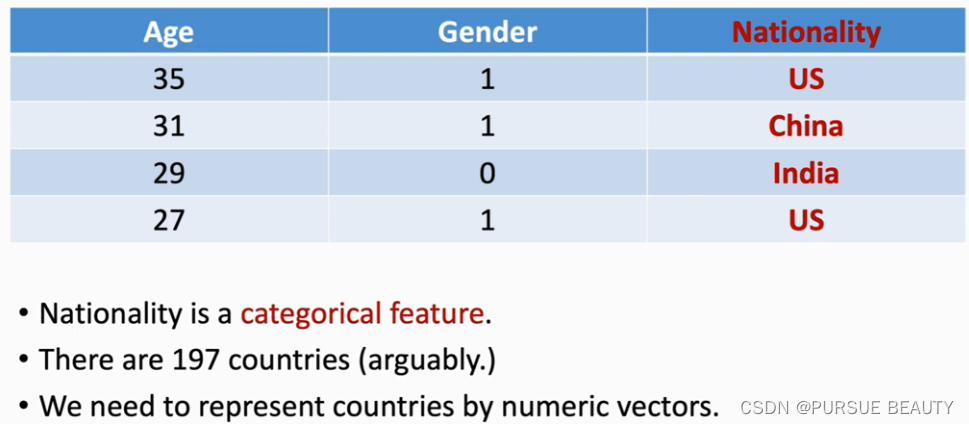
用机器学习的方法处理自然语言,首先就需要将我们所使用的自然语言转换成计算机可以处理的数值信息。我们将数据分类为具有Categorical Features和Numerical Features两类,例如性别中的“男”、“女”具有Categorical Features,而年龄如25具有Numerical Features。因此,我们在处理数据时,需要将Categorical Features的数据映射成Numerical Features类别。
举例,将国籍信息转为数值向量。
- 建立一个字典,将国籍映射为整数indices(从1开始计数,保留0用来表示缺失数据)
美国——1
中国——2
印度——3
……
但是以上这样编码会造成一个问题,美国+中国 = 1+2 =3 那不就等于印度了?因此这样的编码是不合理的,两个国家之间运算不能等于另外一个国家。可见,不能用标量来表示Categorical Features信息,因为求和之后会没有意义。因此我们需要跟进一步。- 做one-hot encoding独热编码,用一个197维的向量来表示一个国家。

那么自然语言处理中,如何处理文本信息,将其数值化呢?
1.2 文本处理 Tokenization
目标:将文本(自然语言)映射成字符串(数值)
Tokenization:把文本变成单词列表。(在此单词是最小的编码单元)
举例:
一段文本“…To be or not to be, It is a question…"
- 分割成单词列表[…, “to”, “be”, “or”, “not”, ”it"," “is”, “a”, “question”, …]
- 统计单词出现的频率,每个单词都有一个频数
- 按频率从高到底,将单词映射为indices
- 设定词典大小,做one-hot encoding,one-hot vector的维度叫做Vocabulary,表示词典的大小(所含单词数量)
1.3 词嵌入Word Embedding
其实经过独热编码后的文本已经转换成计算机可以处理的数值向量了,但是一门语言的词汇量是很巨大的,比如英文如今的总词汇量已突破100万个。庞大的词汇量就导致我们在构建词典将单词映射为数值向量时,维度过高,虽不至于有100万维,但也维度惊人,带来难以承受的计算量。为解决词向量维度过高的问题,我们采用词嵌入Word Embedding的方法。
实操案例1:对IMDB网站的电影评论(英文)进行情感分类
电影评论:用户对电影进行打分(10分制)以及评价
任务:通过用户的电影评论文本,来判断评价是正面还是负面
数据:现成的50k条数据-下载链接
数据库介绍:用于情感二分类的影评数据,标记好的训练集和测试集各25k条,共50k条数据。也保有未标记的数据,详情见README文件。下载后如下:
【在实际问题的解决过程中,通常需要我们自己去收集整理数据,这部分的工作量也不小。比如这个网站的电影评论,就需要你通过爬虫获得,并进行数据清洗和标注。但新手阶段刚上手,有现成的数据可以省时省力,学习目标更聚焦。】
(1/)Text to Sequence
在Word Embedding 和输入机器学习模型之前,要先将文本转成Sequence。在此,我们首先理解文本转序列的四个步骤(Tokenization, Build Dictionary, One-hot Encoding, Align Sequence),然后通过Keras框架来实现。
Text processing in Keras
实验环境设置:
遇到的困难
1. 数据读取之os模块的使用
概括:通过os.path.join和os.listdir读取文件形成评论列表。
在做自然语言处理要将文本序列化,比如用Keras框架文本处理中的Tonkenizer模块,
tokenizer.fit_on_texts(texts_train) # 基于训练数据建立的字典
- 1
在此输入的参数类型需要是一个文本列表。首先看一下下载到本地数据集的文件结构:
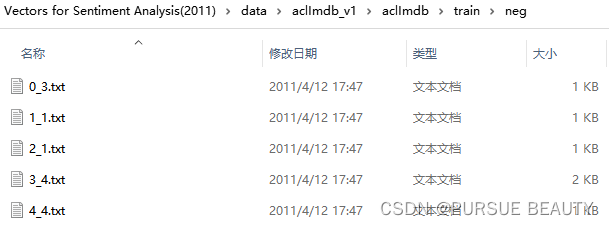
可见,每一条评论都存放在一个txt文件中。因此我们需要将训练集train中的所有评论数据都读取成一个文本列表texts_train。那么如何用os模块来实现呢?这里主要用到了os模块中的两个方法(最终实现的代码附后)。
OS module in Python provides functions for interacting with the operating system. OS comes under Python’s standard utility modules. This module provides a portable way of using operating system dependent functionality. os.path module is sub-module of OS module in Python used for common pathname manipulation.
- os.path.join() method in Python join one or more path components intelligently. This method concatenates various path components with exactly one directory separator (‘/’) following each non-empty part except the last path component. If the last path component to be joined is empty then a directory separator (‘/’) is put at the end.
os.path.join()有两个路径参数,并将这两个路径进行拼接。
比如os.path.join(r"data\aclImdb_v1\aclImdb\train", ‘pos’) 得到的路径就是"data\aclImdb_v1\aclImdb\train\pos",ps.路径参数前面加r是为了防止将路径分隔符理解为转义字符。 - os.listdir() method in python is used to get the list of all files and directories in the specified directory. If we don’t specify any directory, then list of files and directories in the current working directory will be returned.
将指定目录base_path下的所有文件或文件夹(“Files and directories”)都返回成一个列表的形式。如果没有指定目录base_path,就默认为当前文件所在目录。
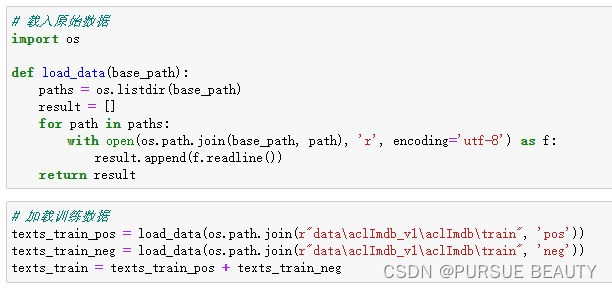
最终实现的代码:
总结:
我是怎么使用的?有什么共性的经验?
我首先是发现使用Keras框架的Tokenizer,知道它要实现的功能,这是我需要的,它可以帮我实现这个事情,接着我需要了解Tokenizer的输入和输出,输出是我想要的,但是它的输入有啥要求呢?于是查阅Tokenizer的文档,看示例,原来是需要一个文本序列。
接下来,就是我如何将我已经有的本地数据集文件读取成Tokenizer需要的输入参数的形式。于是我搜索,”本地aclimdb数据集的加载“,想知道别人是如何读取这个数据集进行使用的,发现可以采用os模块,因为最直观。并且发现他们主要是采用os模块的两个方法,os.path.join和os.listdir。最后我通过两种途径来理解学习并实现了我的目标,一是跟着别人分享的代码,一小部分地运行看看,属于探索,有个直观的感受。二是找专业/官方的文档,对这两个函数以及os模块的介绍,进行学习。
跟进一步总结。原理-框架-函数-参数-数据
理解NLP处理的思想原理
了解可以用来处理这一问题的工具,从最高层次往下,比如框架、模块、方法/函数、参数。
从函数的输入和输出入手,最基本的是对数据结构的处理,读取和存写。

