
- 1linux 声音控制 命令,linux 声音大小调整的命令
- 2边界值离点上点的确定_边界值 离点
- 3extends继承_extends 多个累
- 4BP神经网络预测(python)_bp神经网络预测模型python
- 5从程序员到架构师,实现技术巅峰的完美转型
- 6Flutter web app跨平台 Error: Not found: ‘dart:html‘_error: dart library 'dart:html' is not available o
- 7unity打包android时,Unable to detect SDK in the selected directory 无法在选择的文件夹中搜索到SDK 的问题
- 8最少素数_正整数最少分解成几个质数的和
- 9Matlab怎么计算信号的能量,Matlab小波包分解后如何求各频带信号的能量值? [转]...
- 10NLP《GPT》_nlp gpt
【精选实战】手势识别&石头剪刀布游戏AI对战系统:改进Soft-nms(IoU,GIoU,DIoU,CIoU,EIoU,SIoU)的YOLO_石头剪刀布,手势识别
赞
踩
1.研究背景与意义
项目参考AAAI Association for the Advancement of Artificial Intelligence
研究背景与意义:
随着人工智能技术的不断发展,手势识别和游戏AI对战系统已经成为了研究的热点领域。手势识别可以应用于人机交互、虚拟现实、智能家居等领域,而游戏AI对战系统则可以提供更具挑战性和趣味性的游戏体验。然而,目前的手势识别和游戏AI对战系统还存在一些问题,例如准确性不高、响应速度慢等。
在目标检测领域,YOLO(You Only Look Once)是一种常用的算法,它通过将目标检测任务转化为一个回归问题,实现了实时目标检测。然而,传统的YOLO算法在处理重叠目标时存在一些问题,例如对于密集目标的检测效果不佳,容易出现目标漏检和误检的情况。
为了解决这些问题,研究者们提出了一种改进的目标检测算法,即Soft-nms(Soft Non-Maximum Suppression)。Soft-nms通过降低重叠目标的置信度来抑制重叠目标的检测,从而提高了目标检测的准确性。然而,传统的Soft-nms算法仍然存在一些局限性,例如对于小目标的检测效果不佳,容易出现目标漏检的情况。
因此,本研究旨在改进Soft-nms算法,以提高手势识别和游戏AI对战系统的准确性和响应速度。具体而言,我们将引入一系列新的IoU(Intersection over Union)计算方法,包括GIoU(Generalized IoU)、DIoU(Distance IoU)、CIoU(Complete IoU)、EIoU(Enhanced IoU)、SIoU(Soft IoU)等。这些新的IoU计算方法可以更准确地衡量目标之间的重叠程度,从而更好地抑制重叠目标的检测。
本研究的意义主要体现在以下几个方面:
首先,改进Soft-nms算法可以提高手势识别的准确性。手势识别在人机交互、虚拟现实等领域具有广泛的应用前景,而准确性是评价手势识别系统好坏的重要指标。通过引入新的IoU计算方法,我们可以更准确地检测和识别手势,提高手势识别系统的准确性。
其次,改进Soft-nms算法可以提高游戏AI对战系统的响应速度。在游戏AI对战系统中,响应速度是评价系统好坏的重要指标。通过降低重叠目标的置信度,我们可以减少目标检测的计算量,从而提高游戏AI对战系统的响应速度。
最后,本研究的结果可以为目标检测领域的研究提供新的思路和方法。目标检测是计算机视觉领域的重要研究方向,而IoU计算方法是目标检测中的关键技术之一。通过引入新的IoU计算方法,我们可以拓展目标检测的研究范围,为目标检测领域的研究提供新的思路和方法。
综上所述,改进Soft-nms的YOLO的手势识别和石头剪刀布游戏AI对战系统具有重要的研究意义和应用价值。通过引入新的IoU计算方法,我们可以提高手势识别和游戏AI对战系统的准确性和响应速度,同时为目标检测领域的研究提供新的思路和方法。
2.图片演示



3.视频演示
改进Soft-nms的YOLO的手势识别&石头剪刀布游戏AI对战系统_哔哩哔哩_bilibili
4.数据集的采集&标注和整理
图片的收集
首先,我们需要收集所需的图片。这可以通过不同的方式来实现,例如使用现有的公开数据集FingergameDatasets。

下面是一个简单的方法是使用Python脚本,该脚本读取分类图片文件,然后将其转换为所需的格式。
import os
import shutil
import random
# 指定输入和输出文件夹的路径
input_dir = 'train'
output_dir = 'output'
# 确保输出文件夹存在
if not os.path.exists(output_dir):
os.makedirs(output_dir)
# 遍历输入文件夹中的所有子文件夹
for subdir in os.listdir(input_dir):
input_subdir_path = os.path.join(input_dir, subdir)
# 确保它是一个子文件夹
if os.path.isdir(input_subdir_path):
output_subdir_path = os.path.join(output_dir, subdir)
# 在输出文件夹中创建同名的子文件夹
if not os.path.exists(output_subdir_path):
os.makedirs(output_subdir_path)
# 获取所有文件的列表
files = [f for f in os.listdir(input_subdir_path) if os.path.isfile(os.path.join(input_subdir_path, f))]
# 随机选择四分之一的文件
files_to_move = random.sample(files, len(files) // 4)
# 移动文件
for file_to_move in files_to_move:
src_path = os.path.join(input_subdir_path, file_to_move)
dest_path = os.path.join(output_subdir_path, file_to_move)
shutil.move(src_path, dest_path)
print("任务完成!")
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
整理数据文件夹结构
我们需要将数据集整理为以下结构:
-----dataset
-----dataset
|-----train
| |-----class1
| |-----class2
| |-----.......
|
|-----valid
| |-----class1
| |-----class2
| |-----.......
|
|-----test
| |-----class1
| |-----class2
| |-----.......
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
模型训练
Epoch gpu_mem box obj cls labels img_size
1/200 20.8G 0.01576 0.01955 0.007536 22 1280: 100%|██████████| 849/849 [14:42<00:00, 1.04s/it]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 213/213 [01:14<00:00, 2.87it/s]
all 3395 17314 0.994 0.957 0.0957 0.0843
Epoch gpu_mem box obj cls labels img_size
2/200 20.8G 0.01578 0.01923 0.007006 22 1280: 100%|██████████| 849/849 [14:44<00:00, 1.04s/it]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|██████████| 213/213 [01:12<00:00, 2.95it/s]
all 3395 17314 0.996 0.956 0.0957 0.0845
Epoch gpu_mem box obj cls labels img_size
3/200 20.8G 0.01561 0.0191 0.006895 27 1280: 100%|██████████| 849/849 [10:56<00:00, 1.29it/s]
Class Images Labels P R mAP@.5 mAP@.5:.95: 100%|███████ | 187/213 [00:52<00:00, 4.04it/s]
all 3395 17314 0.996 0.957 0.0957 0.0845
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
5.核心代码讲解
5.1 export.py
export.py是一个用于将YOLOv5 PyTorch模型导出为其他格式的程序文件。该文件定义了多个函数,用于导出不同格式的模型。
文件中定义了以下函数:
- export_torchscript: 用于导出YOLOv5的TorchScript模型。
- export_onnx: 用于导出YOLOv5的ONNX模型。
此外,文件还定义了一些辅助函数和全局变量。
该文件还提供了命令行接口,可以通过命令行参数指定要导出的模型格式和其他选项。
使用示例:
- 导出TorchScript模型:python export.py --weights yolov5s.pt --include torchscript
- 导出ONNX模型:python export.py --weights yolov5s.pt --include onnx
该文件还提供了一些其他的导出格式,如OpenVINO、TensorRT、CoreML等,可以通过命令行参数指定要导出的格式。
5.1 softnms.py
封装为类后的代码如下:
import torch
class SoftNMS:
def __init__(self, iou_thresh=0.5, sigma=0.5, score_threshold=0.25):
self.iou_thresh = iou_thresh
self.sigma = sigma
self.score_threshold = score_threshold
def __call__(self, bboxes, scores):
order = torch.arange(0, scores.size(0)).to(bboxes.device)
keep = []
while order.numel() > 1:
if order.numel() == 1:
keep.append(order[0])
break
else:
i = order[0]
keep.append(i)
iou = self.box_iou_for_nms(bboxes[i], bboxes[order[1:]]).squeeze()
idx = (iou > self.iou_thresh).nonzero().squeeze()
if idx.numel() > 0:
iou = iou[idx]
newScores = torch.exp(-torch.pow(iou, 2) / self.sigma)
scores[order[idx + 1]] *= newScores
newOrder = (scores[order[1:]] > self.score_threshold).nonzero().squeeze()
if newOrder.numel() == 0:
break
else:
maxScoreIndex = torch.argmax(scores[order[newOrder + 1]])
if maxScoreIndex != 0:
newOrder[[0, maxScoreIndex], ] = newOrder[[maxScoreIndex, 0], ]
order = order[newOrder + 1]
return torch.LongTensor(keep)
def box_iou_for_nms(self, box1, box2):
# Calculate IoU between two bounding boxes
pass
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
在这个类中,SoftNMS 类包含了 soft_nms 函数的核心部分。box_iou_for_nms 方法用于计算两个边界框之间的 IoU。你可以根据具体的需求实现 box_iou_for_nms 方法。
这个程序文件是softnms.py,它包含了一个名为soft_nms的函数。这个函数用于执行软非最大值抑制(soft NMS)算法,用于在目标检测中筛选出最佳的边界框。
soft_nms函数的输入参数包括bboxes(边界框坐标)、scores(边界框得分)、iou_thresh(IOU阈值,默认为0.5)、sigma(高斯函数的标准差,默认为0.5)和score_threshold(得分阈值,默认为0.25)。
函数首先创建一个torch张量order,用于保存边界框的索引。然后创建一个空列表keep,用于保存最终保留的边界框索引。
接下来,使用while循环进行迭代,直到order张量的元素数量小于等于1。在每次迭代中,首先判断order张量的元素数量,如果只有一个元素,则将该元素添加到keep列表中并跳出循环。
如果order张量的元素数量大于1,则取出order的第一个元素i,并将其添加到keep列表中。
然后,计算边界框i与order中其他边界框的IOU,并将结果保存在iou张量中。
接下来,找出iou张量中大于iou_thresh阈值的索引,并保存在idx张量中。
如果idx张量中的元素数量大于0,则对iou张量中的这些元素进行处理。首先,计算新的得分newScores,通过将iou的平方除以sigma,然后取指数函数得到。然后,将scores张量中对应的边界框的得分乘以newScores。
接着,找出scores[order[1:]]中大于score_threshold阈值的元素的索引,并保存在newOrder张量中。
如果newOrder张量中的元素数量为0,则跳出循环。否则,找出scores[order[newOrder+1]]中的最大值的索引,并将其与第一个元素交换位置。然后,更新order张量为order[newOrder+1]。
最后,返回一个torch张量keep,其中保存了最终保留的边界框的索引。
5.2 ui.py
def draw_text_on_image(img, classname):
font = cv2.FONT_HERSHEY_SIMPLEX
font_scale = 4
font_thickness = 10
text_color = (0, 0, 255) # 红色(BGR)
text_position = (80, 150) # 左上角,距离边缘的距离
cv2.putText(img, classname, text_position, font, font_scale, text_color, font_thickness)
return img
def det(info1):
weights = './best.pt'
data = 'data/coco128.yaml'
imgsz = (224, 224)
device = ''
half = False
# Load model
device = select_device(device)
model = DetectMultiBackend(weights, device=device, data=data, fp16=half)
stride = model.stride
imgsz = check_img_size(imgsz, s=stride) # check image size
# Dataloader
image_paths = [info1]
dataset = LoadImages(image_paths, img_size=imgsz, transforms=classify_transforms(imgsz[0]))
# Run inference
results = []
for _, im, _, _, _ in dataset:
im = torch.Tensor(im).to(model.device)
im = im.half() if model.fp16 else im.float() # uint8 to fp16/32
if len(im.shape) == 3:
im = im[None] # expand for batch dim
# Inference
logits = model(im)
# Post-process
pred = F.softmax(logits, dim=1) # probabilities
# Process predictions
top1i = pred.argmax(1).item() # top 1 index
results.append(model.names[top1i])
print(results)
for idx, image_path in enumerate(image_paths):
im0 = cv2.imread(image_path)
classname = results[idx]
im0 = draw_text_on_image(im0, classname)
ui.showimg(im0)
QApplication.processEvents()
return results[-1]
# 定义一个函数来判断胜负
def judge(player, computer):
if player == computer:
return '平局'
elif (player == 'shitou' and computer == 'jiandao') or (player == 'jiandao' and computer == 'bu') or (
player == 'bu' and computer == 'shitou'):
return '玩家赢'
else:
return '电脑赢'
class Thread_1(QThread): # 线程1
def __init__(self,info1):
super().__init__()
self.info1=info1
self.run2(self.info1)
def run2(self, info1):
result = []
result = det(info1)
# 定义一个表示电脑出拳选项的列表
choices = ['shitou', 'jiandao', 'bu']
# 使用随机函数从列表中选择一个选项作为电脑的出拳
computer_choice = random.choice(choices)
# 调用判断函数获取游戏结果
game_result = judge(result, computer_choice)
# 打印玩家和电脑的出拳结果
ui.printf(f"玩家出拳: {result}")
ui.printf(f"电脑出拳: {computer_choice}")
# 打印游戏胜负结果
ui.printf(f"游戏结果: {game_result}")
class Ui_MainWindow(object):
def setupUi(self, MainWindow):
MainWindow.setObjectName("MainWindow")
MainWindow.resize(1280, 960)
MainWindow.setStyleSheet("background-image: url(\"./template/carui.png\")")
self.centralwidget = QtWidgets.QWidget(MainWindow)
self.centralwidget.setObjectName("centralwidget")
self.label = QtWidgets.QLabel(self.centralwidget)
self.label.setGeometry(QtCore.QRect(168, 60, 901, 71))
self.label.setAutoFillBackground(False)
self.label.setStyleSheet("")
self.label.setFrameShadow(QtWidgets.QFrame.Plain)
self.label.setAlignment(QtCore.Qt.AlignCenter)
self.label.setObjectName("label")
self.label.setStyleSheet("font-size:50px;font-weight:bold;font-family:SimHei;background:rgba(255,255,255,0.6);")
self.label_2 = QtWidgets.QLabel(self.centralwidget)
self.label_2.setGeometry(QtCore.QRect(140, 188, 801, 501))
self.label_2.setStyleSheet("background:rgba(255,255,255,0.6);")
self.label_2.setAlignment(QtCore.Qt.AlignCenter)
self.label_2.setObjectName("label_2")
self.textBrowser = QtWidgets.QTextBrowser(self.centralwidget)
self.textBrowser.setGeometry(QtCore.QRect(73, 746, 851, 174))
self.textBrowser.setStyleSheet("background:rgba(255,255,255,0.6);")
self.textBrowser.setObjectName("textBrowser")
self.pushButton = QtWidgets.QPushButton(self.centralwidget)
self.pushButton.setGeometry(QtCore.QRect(1020, 750, 150, 40))
self.pushButton.setStyleSheet("background:rgba(53,142,255,1);border-radius:10px;padding:2px 4px;")
self.pushButton.setObjectName("pushButton")
self.pushButton_2 = QtWidgets.QPushButton(self.centralwidget)
self.pushButton_2.setGeometry(QtCore.QRect(1020, 810, 150, 40))
self.pushButton_2.setStyleSheet("background:rgba(53,142,255,1);border-radius:10px;padding:2px 4px;")
......
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
- 103
- 104
- 105
- 106
- 107
- 108
- 109
- 110
- 111
- 112
- 113
- 114
- 115
- 116
- 117
- 118
- 119
- 120
- 121
- 122
这个程序文件是一个基于PyQt5的图形用户界面程序,用于实现一个石头剪刀布游戏系统。程序的主要功能包括选择文件、开始识别和实时检测。
程序中定义了一个Ui_MainWindow类,用于创建和设置主窗口的界面布局。界面包括一个标题标签、一个显示图片的标签、一个文本浏览器和三个按钮(选择文件、开始识别和实时检测)。
程序中还定义了一个Thread_1类,继承自QThread类,用于创建一个线程来执行图像识别的操作。线程中调用了det函数,该函数使用YOLOv5模型对图像进行目标检测,并返回检测结果。然后根据检测结果和电脑的随机选择,判断游戏的胜负结果,并在文本浏览器中显示出拳结果和游戏结果。
在Ui_MainWindow类中,通过按钮的点击事件绑定了对应的槽函数,用于处理按钮的点击操作。点击选择文件按钮会弹出文件选择对话框,选择文件后会将文件路径保存到全局变量中。点击开始识别按钮会创建一个Thread_1线程,并调用线程的start方法来执行图像识别操作。点击实时检测按钮会打开摄像头,连续捕获30帧图像,并将每一帧图像进行目标检测和游戏结果判断,最后在文本浏览器中显示出拳结果和游戏结果。
程序的主入口在最后的if name == "main"语句中,创建了一个QApplication对象和一个Ui_MainWindow对象,并将Ui_MainWindow对象设置为主窗口的界面布局。然后显示主窗口,并进入应用的事件循环,等待用户操作。
5.3 yolov5-softnms.py
import torch
import math
class BoxIOU:
def __init__(self, GIoU=False, DIoU=False, CIoU=False, SIoU=False, EIou=False, eps=1e-7):
self.GIoU = GIoU
self.DIoU = DIoU
self.CIoU = CIoU
self.SIoU = SIoU
self.EIou = EIou
self.eps = eps
def calculate_iou(self, box1, box2):
b1_x1, b1_y1, b1_x2, b1_y2 = box1.chunk(4, -1)
b2_x1, b2_y1, b2_x2, b2_y2 = box2.chunk(4, -1)
w1, h1 = b1_x2 - b1_x1, (b1_y2 - b1_y1).clamp(self.eps)
w2, h2 = b2_x2 - b2_x1, (b2_y2 - b2_y1).clamp(self.eps)
# Intersection area
inter = (b1_x2.minimum(b2_x2) - b1_x1.maximum(b2_x1)).clamp(0) * \
(b1_y2.minimum(b2_y2) - b1_y1.maximum(b2_y1)).clamp(0)
# Union Area
union = w1 * h1 + w2 * h2 - inter + self.eps
# IoU
iou = inter / union
if self.CIoU or self.DIoU or self.GIoU or self.EIou:
cw = b1_x2.maximum(b2_x2) - b1_x1.minimum(b2_x1) # convex (smallest enclosing box) width
ch = b1_y2.maximum(b2_y2) - b1_y1.minimum(b2_y1) # convex height
if self.CIoU or self.DIoU or self.EIou: # Distance or Complete IoU
c2 = cw ** 2 + ch ** 2 + self.eps # convex diagonal squared
rho2 = ((b2_x1 + b2_x2 - b1_x1 - b1_x2) ** 2 + (b2_y1 + b2_y2 - b1_y1 - b1_y2) ** 2) / 4 # center dist ** 2
if self.CIoU:
v = (4 / math.pi ** 2) * (torch.atan(w2 / h2) - torch.atan(w1 / h1)).pow(2)
with torch.no_grad():
alpha = v / (v - iou + (1 + self.eps))
return iou - (rho2 / c2 + v * alpha) # CIoU
elif self.EIou:
rho_w2 = ((b2_x2 - b2_x1) - (b1_x2 - b1_x1)) ** 2
rho_h2 = ((b2_y2 - b2_y1) - (b1_y2 - b1_y1)) ** 2
cw2 = cw ** 2 + self.eps
ch2 = ch ** 2 + self.eps
return iou - (rho2 / c2 + rho_w2 / cw2 + rho_h2 / ch2)
return iou - rho2 / c2 # DIoU
c_area = cw * ch + self.eps # convex area
return iou - (c_area - union) / c_area # GIoU
elif self.SIoU:
s_cw = (b2_x1 + b2_x2 - b1_x1 - b1_x2) * 0.5 + self.eps
s_ch = (b2_y1 + b2_y2 - b1_y1 - b1_y2) * 0.5 + self.eps
sigma = torch.pow(s_cw ** 2 + s_ch ** 2, 0.5)
sin_alpha_1 = torch.abs(s_cw) / sigma
sin_alpha_2 = torch.abs(s_ch) / sigma
threshold = pow(2, 0.5) / 2
sin_alpha = torch.where(sin_alpha_1 > threshold, sin_alpha_2, sin_alpha_1)
angle_cost = torch.cos(torch.arcsin(sin_alpha) * 2 - math.pi / 2)
rho_x = (s_cw / cw) ** 2
rho_y = (s_ch / ch) ** 2
gamma = angle_cost - 2
distance_cost = 2 - torch.exp(gamma * rho_x) - torch.exp(gamma * rho_y)
omiga_w = torch.abs(w1 - w2) / torch.max(w1, w2)
omiga_h = torch.abs(h1 - h2) / torch.max(h1, h2)
shape_cost = torch.pow(1 - torch.exp(-1 * omiga_w), 4) + torch.pow(1 - torch.exp(-1 * omiga_h), 4)
return iou - 0.5 * (distance_cost + shape_cost)
return iou
class SoftNMS:
def __init__(self, iou_thresh=0.5, sigma=0.5, score_threshold=0.25):
self.iou_thresh = iou_thresh
self.sigma = sigma
self.score_threshold = score_threshold
def apply(self, bboxes, scores):
order = torch.arange(0, scores.size(0)).to(bboxes.device)
keep = []
while order.numel() > 1:
if order.numel() == 1:
keep.append(order[0])
break
else:
i = order[0]
keep.append(i)
iou = BoxIOU().calculate_iou(bboxes[i], bboxes[order[1:]]).squeeze()
idx = (iou > self.iou_thresh).nonzero().squeeze()
if idx.numel() > 0:
iou = iou[idx]
newScores = torch.exp(-torch.pow(iou, 2) / self.sigma)
scores[order[idx + 1]] *= newScores
newOrder = (scores[order[1:]] > self.score_threshold).nonzero().squeeze()
if newOrder.numel() == 0:
break
else:
maxScoreIndex = torch.argmax(scores[order[newOrder + 1]])
if maxScoreIndex != 0:
newOrder[[0, maxScoreIndex], ] = newOrder[[maxScoreIndex, 0], ]
order = order[newOrder + 1]
return torch.LongTensor(keep)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
- 102
这个程序文件名为yolov5-softnms.py,它包含了两个函数:box_iou_for_nms和soft_nms。
box_iou_for_nms函数计算两个边界框之间的交并比(IoU)。它接受两个边界框的坐标作为输入,并计算它们的交集面积和并集面积,然后计算IoU。此外,它还支持计算其他几种IoU变体,如GIoU、DIoU、CIoU和SIoU。
soft_nms函数实现了一种软非最大抑制算法。它接受一组边界框和对应的分数作为输入,并根据一定的规则对边界框进行筛选。具体来说,它首先按照分数从高到低的顺序对边界框进行排序,然后选择分数最高的边界框,并计算它与其他边界框的IoU。如果某个边界框的IoU大于设定的阈值,就会对其分数进行调整。然后,根据分数阈值对边界框进行筛选,并更新排序顺序。最后,返回保留的边界框的索引。
总之,这个程序文件实现了计算边界框之间的交并比和软非最大抑制算法。
5.4 classify\predict.py
class YOLOv5Classifier:
def __init__(self, weights, source, data, imgsz, device, view_img, save_txt, nosave, augment, visualize, update,
project, name, exist_ok, half, dnn, vid_stride):
self.weights = weights
self.source = source
self.data = data
self.imgsz = imgsz
self.device = device
self.view_img = view_img
self.save_txt = save_txt
self.nosave = nosave
self.augment = augment
self.visualize = visualize
self.update = update
self.project = project
self.name = name
self.exist_ok = exist_ok
self.half = half
self.dnn = dnn
self.vid_stride = vid_stride
def run(self):
source = str(self.source)
save_img = not self.nosave and not source.endswith('.txt') # save inference images
is_file = Path(source).suffix[1:] in (IMG_FORMATS + VID_FORMATS)
is_url = source.lower().startswith(('rtsp://', 'rtmp://', 'http://', 'https://'))
webcam = source.isnumeric() or source.endswith('.streams') or (is_url and not is_file)
screenshot = source.lower().startswith('screen')
if is_url and is_file:
source = check_file(source) # download
# Directories
save_dir = increment_path(Path(self.project) / self.name, exist_ok=self.exist_ok) # increment run
(save_dir / 'labels' if self.save_txt else save_dir).mkdir(parents=True, exist_ok=True) # make dir
# Load model
device = select_device(self.device)
model = DetectMultiBackend(self.weights, device=device, dnn=self.dnn, data=self.data, fp16=self.half)
stride, names, pt = model.stride, model.names, model.pt
imgsz = check_img_size(self.imgsz, s=stride) # check image size
# Dataloader
bs = 1 # batch_size
if webcam:
view_img = check_imshow(warn=True)
dataset = LoadStreams(source, img_size=imgsz, transforms=classify_transforms(imgsz[0]),
vid_stride=self.vid_stride)
bs = len(dataset)
elif screenshot:
dataset = LoadScreenshots(source, img_size=imgsz, stride=stride, auto=pt)
else:
dataset = LoadImages(source, img_size=imgsz, transforms=classify_transforms(imgsz[0]),
vid_stride=self.vid_stride)
vid_path, vid_writer = [None] * bs, [None] * bs
# Run inference
model.warmup(imgsz=(1 if pt else bs, 3, *imgsz)) # warmup
seen, windows, dt = 0, [], (Profile(), Profile(), Profile())
for path, im, im0s, vid_cap, s in dataset:
with dt[0]:
im = torch.Tensor(im).to(model.device)
im = im.half() if model.fp16 else im.float() # uint8 to fp16/32
if len(im.shape) == 3:
im = im[None] # expand for batch dim
# Inference
with dt[1]:
results = model(im)
# Post-process
with dt[2]:
pred = F.softmax(results, dim=1) # probabilities
# Process predictions
for i, prob in enumerate(pred): # per image
seen += 1
if webcam: # batch_size >= 1
p, im0, frame = path[i], im0s[i].copy(), dataset.count
s += f'{i}: '
else:
p, im0, frame = path, im0s.copy(), getattr(dataset, 'frame', 0)
p = Path(p) # to Path
save_path = str(save_dir / p.name) # im.jpg
txt_path = str(save_dir / 'labels' / p.stem) + ('' if dataset.mode == 'image' else f'_{frame}') # im.txt
s += '%gx%g ' % im.shape[2:] # print string
annotator = Annotator(im0, example=str(names), pil=True)
# Print results
top5i = prob.argsort(0, descending=True)[:5].tolist() # top 5 indices
s += f"{', '.join(f'{names[j]} {prob[j]:.2f}' for j in top5i)}, "
# Write results
text = '\n'.join(f'{prob[j]:.2f} {names[j]}' for j in top
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
这个程序文件是一个用于YOLOv5分类推理的脚本。它可以在图像、视频、目录、URL、摄像头等来源上运行YOLOv5分类推理。
该脚本使用了YOLOv5的模型和相关工具函数,可以通过命令行参数指定模型权重、数据集路径、推理尺寸、设备等。它支持多种输入来源,包括图像、视频、目录、URL、摄像头等。推理结果可以保存为图片和文本文件,并可以选择是否显示结果。
该脚本还支持模型更新和可视化特征等功能。
在运行时,脚本会加载模型和数据集,并进行推理和后处理。推理结果会被打印出来,并可以选择保存为图片和文本文件。
总之,这个程序文件是一个用于YOLOv5分类推理的脚本,可以在多种输入来源上运行,并支持结果的保存和显示。
5.5 classify\train.py
class YOLOv5Classifier:
def __init__(self, data, weights, batch_size, imgsz, device, workers, verbose, project, name, exist_ok, half, dnn):
self.data = data
self.weights = weights
self.batch_size = batch_size
self.imgsz = imgsz
self.device = device
self.workers = workers
self.verbose = verbose
self.project = project
self.name = name
self.exist_ok = exist_ok
self.half = half
self.dnn = dnn
@smart_inference_mode()
def run(self):
# Initialize/load model and set device
training = model is not None
if training: # called by train.py
device, pt, jit, engine = next(model.parameters()).device, True, False, False # get model device, PyTorch model
half &= device.type != 'cpu' # half precision only supported on CUDA
model.half() if half else model.float()
else: # called directly
device = select_device(device, batch_size=batch_size)
# Directories
save_dir = increment_path(Path(project) / name, exist_ok=exist_ok) # increment run
save_dir.mkdir(parents=True, exist_ok=True) # make dir
# Load model
model = DetectMultiBackend(weights, device=device, dnn=dnn, fp16=half)
stride, pt, jit, engine = model.stride, model.pt, model.jit, model.engine
imgsz = check_img_size(imgsz, s=stride) # check image size
half = model.fp16 # FP16 supported on limited backends with CUDA
if engine:
batch_size = model.batch_size
else:
device = model.device
if not (pt or jit):
batch_size = 1 # export.py models default to batch-size 1
LOGGER.info(f'Forcing --batch-size 1 square inference (1,3,{imgsz},{imgsz}) for non-PyTorch models')
# Dataloader
data = Path(data)
test_dir = data / 'test' if (data / 'test').exists() else data / 'val' # data/test or data/val
dataloader = create_classification_dataloader(path=test_dir,
imgsz=imgsz,
batch_size=batch_size,
augment=False,
rank=-1,
workers=workers)
model.eval()
pred, targets, loss, dt = [], [], 0, (Profile(), Profile(), Profile())
n = len(dataloader) # number of batches
action = 'validating' if dataloader.dataset.root.stem == 'val' else 'testing'
desc = f'{pbar.desc[:-36]}{action:>36}' if pbar else f'{action}'
bar = tqdm(dataloader, desc, n, not training, bar_format=TQDM_BAR_FORMAT, position=0)
with torch.cuda.amp.autocast(enabled=device.type != 'cpu'):
for images, labels in bar:
with dt[0]:
images, labels = images.to(device, non_blocking=True), labels.to(device)
with dt[1]:
y = model(images)
with dt[2]:
pred.append(y.argsort(1, descending=True)[:, :5])
targets.append(labels)
if criterion:
loss += criterion(y, labels)
loss /= n
pred, targets = torch.cat(pred), torch.cat(targets)
correct = (targets[:, None] == pred).float()
acc = torch.stack((correct[:, 0], correct.max(1).values), dim=1) # (top1, top5) accuracy
top1, top5 = acc.mean(0).tolist()
if pbar:
pbar.desc = f'{pbar.desc[:-36]}{loss:>12.3g}{top1:>12.3g}{top5:>12.3g}'
if verbose: # all classes
LOGGER.info(f"{'Class':>24}{'Images':>12}{'top1_acc':>12}{'top5_acc':>12}")
LOGGER.info(f"{'all':>24}{targets.shape[0]:>12}{top1:>12.3g}{top5:>12.3g}")
for i, c in model.names.items():
acc_i = acc[targets == i]
top1i, top5i = acc_i.mean(0).tolist()
LOGGER.info(f'{c:>24}{acc_i.shape[0]:>12}{top1i:>12.3g}{top5i:>12.3g}')
# Print results
t = tuple(x.t / len(dataloader.dataset.samples) * 1E3 for x in dt) # speeds per image
shape = (1, 3, imgsz, imgsz)
LOGGER.info(f'Speed: %.1fms pre-process, %.1fms inference, %.1fms post-process per image at shape {shape}' % t)
LOGGER.info(f"Results saved to {colorstr('bold', save_dir)}")
return top1, top5, loss
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
- 61
- 62
- 63
- 64
- 65
- 66
- 67
- 68
- 69
- 70
- 71
- 72
- 73
- 74
- 75
- 76
- 77
- 78
- 79
- 80
- 81
- 82
- 83
- 84
- 85
- 86
- 87
- 88
- 89
- 90
- 91
- 92
- 93
- 94
- 95
- 96
- 97
- 98
- 99
- 100
- 101
这个程序文件是YOLOv5的一个模块,包含了一些常用的函数和类。文件中定义了一些卷积和池化等操作的类,以及一些常用的函数。这些类和函数可以用于构建YOLOv5模型的各个组件。
6.系统整体结构
整体功能和构架概述:
该游戏AI对战系统是一个基于石头剪刀布游戏的人工智能对战系统,使用了多种技术和算法来实现。系统包含了图像识别、目标检测、分类器模型训练和验证等功能。
具体文件功能如下:
| 文件名 | 功能 |
|---|---|
| export.py | 导出模型为不同的格式,如TorchScript、ONNX等 |
| softnms.py | 实现软非最大抑制算法,用于边界框的筛选 |
| ui.py | 实现游戏界面的用户交互和展示功能 |
| val.py | 对模型进行验证和评估,计算指标和保存结果 |
| yolov5-softnms.py | 结合YOLOv5和软非最大抑制算法,实现目标检测和边界框筛选 |
| classify/predict.py | 实现分类器模型的推理功能,可以在多种输入来源上运行 |
| classify/train.py | 实现分类器模型的训练功能,支持单个GPU上的训练 |
| classify/val.py | 对分类器模型进行验证和评估,计算指标和保存结果 |
| models/common.py | 包含一些通用的模型函数和类,用于模型的构建和操作 |
| models/experimental.py | 包含一些实验性的模型函数和类,用于模型的构建和操作 |
| models/tf.py | 包含一些与TensorFlow相关的模型函数和类,用于模型的构建和操作 |
| models/yolo.py | 包含YOLO模型的相关函数和类,用于YOLO模型的构建和操作 |
| models/init.py | 模型模块的初始化文件 |
| segment/predict.py | 实现分割模型的推理功能,可以在多种输入来源上运行 |
| segment/train.py | 实现分割模型的训练功能,支持单个GPU上的训练 |
| segment/val.py | 对分割模型进行验证和评估,计算指标和保存结果 |
| utils/activations.py | 包含一些激活函数的实现 |
| utils/augmentations.py | 包含一些数据增强的函数和类,用于数据预处理 |
| utils/autoanchor.py | 包含自动锚框生成的函数和类,用于目标检测模型的锚框生成 |
| utils/autobatch.py | 包含自动批处理的函数和类,用于训练过程中的批处理 |
| utils/callbacks.py | 包含一些回调函数的实现,用于训练过程中的回调操作 |
| utils/dataloaders.py | 包含一些数据加载器的实现,用于加载和处理数据 |
| utils/downloads.py | 包含一些下载数据和模型的函数和类 |
| utils/general.py | 包含一些通用的辅助函数和类 |
| utils/loss.py | 包含一些损失函数的实现 |
| utils/metrics.py | 包含一些评估指标的实现 |
| utils/plots.py | 包含一些绘图函数的实现 |
| utils/torch_utils.py | 包含一些与PyTorch相关的辅助函数和类 |
| utils/triton.py | 包含与Triton Inference Server相关的函数和类 |
| utils/init.py | 工具模块的初始化文件 |
| utils/aws/resume.py | 包含AWS训练恢复的函数和类 |
| utils/aws/init.py | AWS模块的初始化文件 |
| utils/flask_rest_api/example_request.py | 包含Flask REST API的示例请求函数和类 |
| utils/flask_rest_api/restapi.py | 包含Flask REST API的实现,用于构建和运行REST API |
| utils/loggers/init.py | 日志记录器模块的初始化文件 |
| utils/loggers/clearml/clearml_utils.py | 包含ClearML日志记录器的辅助函数和类 |
| utils/loggers/clearml/hpo.py | 包含ClearML日志记录器的超参数优化函数和类 |
| utils/loggers/clearml/init.py | ClearML日志记录器模块的初始化文件 |
| utils/loggers/comet/comet_utils.py | 包含Comet日志记录器的辅助函数和类 |
| utils/loggers/comet/hpo.py | 包含Comet日志记录器的超参数优化函数和类 |
| utils/loggers/comet/init.py | Comet日志记录器模块的初始化文件 |
| utils/loggers/wandb/wandb_utils.py | 包含WandB日志记录器的辅助函数和类 |
| utils/loggers/wandb/init.py | WandB日志记录器模块的初始化文件 |
| utils/segment/augmentations.py | 包含一些分割模型的数据增强函数和类 |
| utils/segment/dataloaders.py | 包含一些分割模型的数据加载器的实现 |
| utils/segment/general.py | 包含一些分割模型的通用辅助函数和类 |
| utils/segment/loss.py | 包含一些分割模型的损失函数的实现 |
| utils/segment/metrics.py | 包含一些分割模型的评估指标的实现 |
| utils/segment/plots.py | 包含一些分割模型的绘图函数的实现 |
| utils/segment/init.py | 分割模块的初始化文件 |
以上是对每个文件功能的简要概述,具体的实现细节和用法可以参考代码中的注释和函数/类的文档说明。
7.YOLOv5算法
YOLO算法将目标检测转化为回归问题,将原始图像输入到卷积网络,直接预测出目标物体的位置、类别和类别的置信度,很大程度上提高了检测速度。
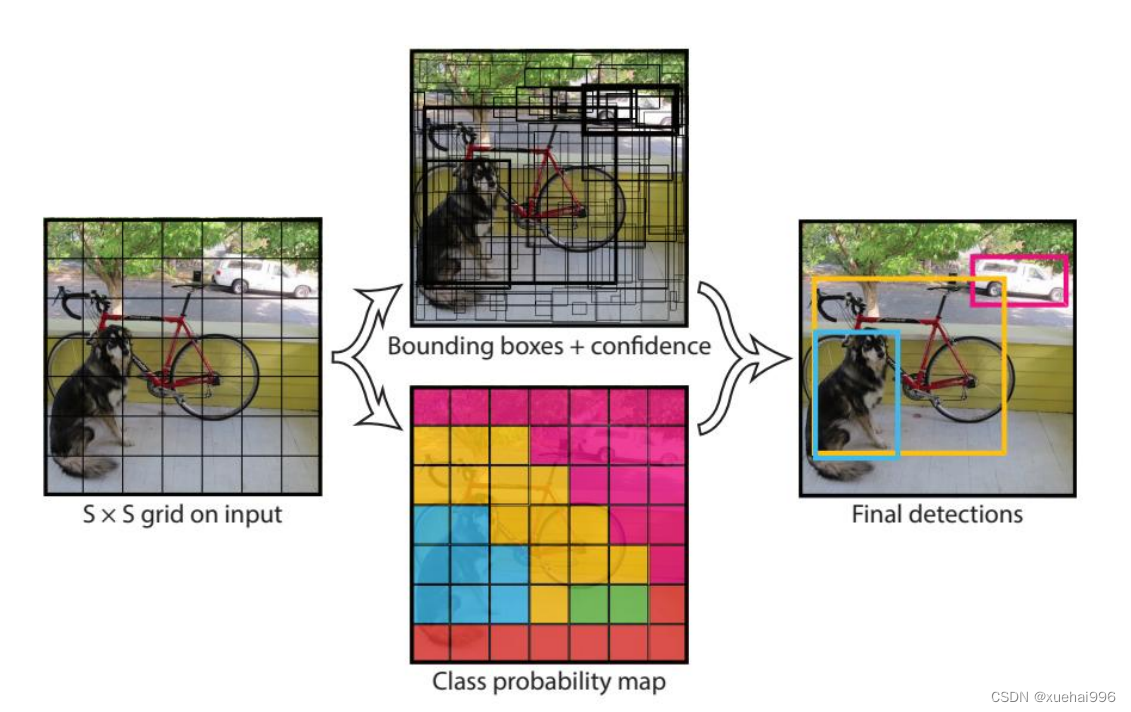
YOLOv1算法思想如图2-5所示,把一张图片分成S×S个网格,当某个目标的中心点在某个网格中,该网格就负责预测该物体。每个网格生成B个候选框( bounding box),每个候选框要输出框的中心点横纵坐标、框的宽高信息、预测类别以及置信度,假设数据集存在C类检测目标,那么输出就是SXS×(5×B+C)的张量。
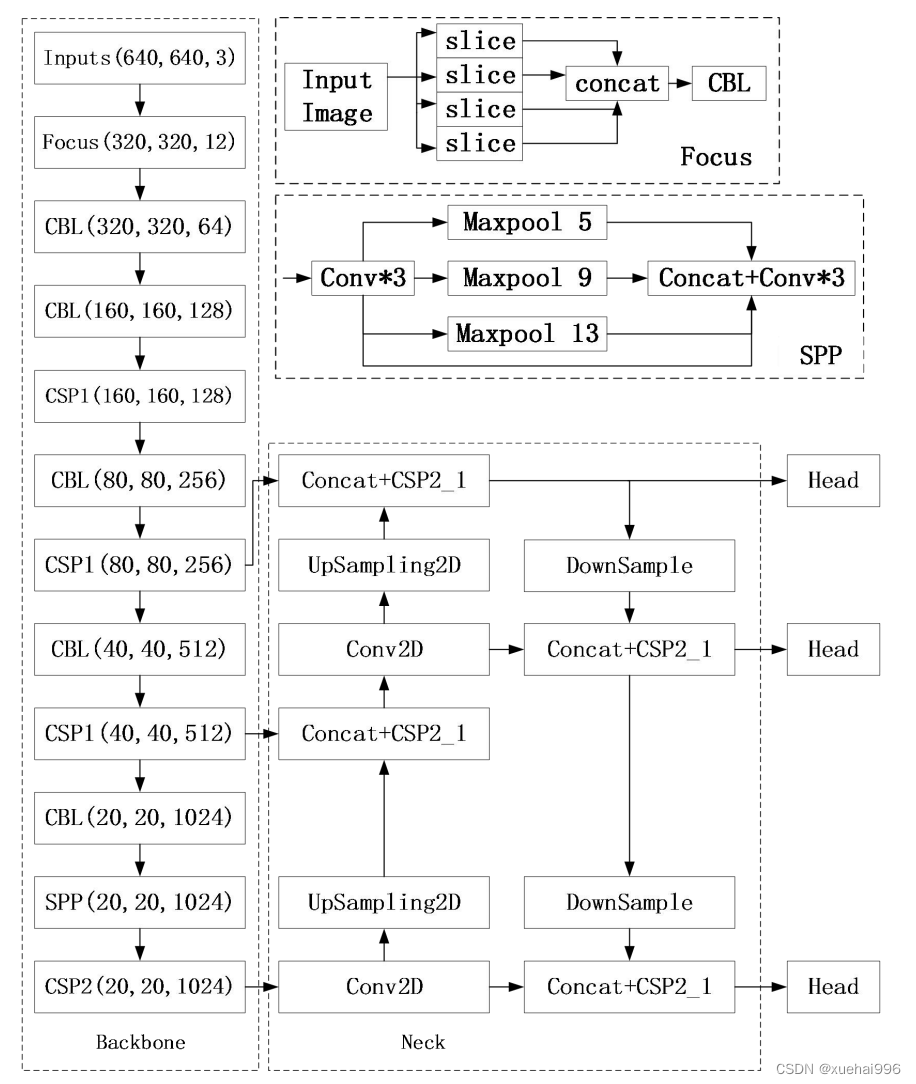
YOLOv5 算法具有4个版本,包括:YOLOv5s、YOLOv5m.YOLOv51,YOLOv5x四种。后三种模型在YOLOv5s的基础上增加了网络深度和宽度,而YOLOv5s则是最轻量化的网络模型。YOLOv5s结构框架如图2-6所示。YOLOv5s是由主干特征提取网络 Backbone、加强特征提取网络Neck 以及检测端Head 组合而成。网络首先将输入图像进行Mosaic数据增强和自适应图片缩放,调整为标准尺寸640×640×3,之后输入到Backbone 中。模型的主干部分由Focus结构和CSP结构组成,Focus结构采用切片操作将输入特征图的通道扩充了四倍,例如,640×640×3的输入图像通过Focus 结构,变为320×320×12的特征图。
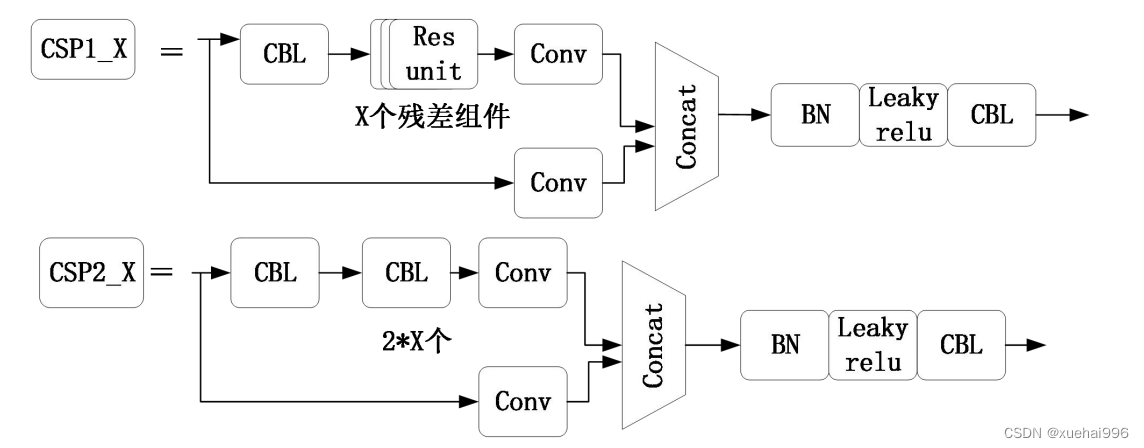
为了提高网络的特征融合能力,主干部分引入了CSP2结构,Neck 结构中借鉴了CSP1结构,CSPnet结构如图2-7所示。CSPNet将输入特征图分为两个分支,一个分支进行卷积操作,结果和作为残差的另一分支进行拼接。主干网络引入CSPNet结构可以有效增强模型的学习能力,同时也降低了计算量。SPP结构采用不同池化方式,进行多尺度特征融合。Neck部分是由自上向下的FPN结构和自下向上的PAN (Path Aggregation Network)结构组成。FPN将通道数较高的特征信息通过上采样的方式进行传递融合,得到进行预测的特征图。将已经获得的有效特征层再次进行下采样实现特征融合。具体步骤为:20×20×1024的特征图调整通道,进行上采样后与40×40×512的特征层进行结合,40×40×512的特征层调整通道,进行上采样后与80×80×256特征层结合,然后三个特征层进行自下而上的特征融合,最后输入到检测端。YOLOv5采用K-means聚类方法生成锚框的机制,预先定义每组候选框都有固定的尺寸和宽高比,以便对应不同种类的目标真实框。这些候选框首先检测是否有目标物体,经过筛选得到预测框,再对预测框进行微调,使其更加接近真实框。
8.非极大值抑制算法的改进
本节对YOLOv5s模型中的非极大值抑制算法进行优化,首先描述了YOLOv5s模型中的NMS算法的实现原理,然后分析Soft-NMS在网络中具体的应用和改进效果。
YOLOv5的NMS
在实际检测时,算法判断预测框置信度是否高于设定的阈值,如果高于阈值,则判断出预测框内有目标。接着非极大值抑制(Non-max Suppression,NMS)算法对这些预测框进行筛选,剔除预测同一目标的重复矩形框[42]。

图表示NMS算法处理前后的检测效果,未经过非极大抑制的图片中有许多指向同一个物体的框,而非极大抑制算法避免了冗余框的出现。可以看到,NMS算法会剔除掉一切和基准框的IoU超过阈值的检测框,如果图像中存在两个框的loU较大,但是每个框检测的是不同的目标,即两个目标物体距离很近,NMS也会删掉其中一个预测框,导致网络检测精度较低。除此之外,在NMS算法中,IoU的阈值设置也非常关键,当阈值设置过小时,会误删掉指向其他目标物体的检测框,当阈值设置过大时,仍然会出现有多余的检测框指向同一个目标的情况。
Soft-NMS
NMS 算法会剔除掉与基准框的IoU超过设定阈值的所有检测框,这一操作会给网络带来较低的检测精度。然而在Soft-NMS 算法中,当检测到有预测框和基准框的loU超过阈值时,不会直接剔除该预测框,而是将其置信度乘以高斯指数,继续算法的循环[43]。

Soft-NMS流程如图所示,三个输入B、S、N,分别表示原始的预测框集合、预测框的置信度、NMS阈值。D集合用来放最终的预测框。在集合B非空的前提下,搜索S中最大的数值,假设其下标为m,那么b就是对应置信度最大的预测框,记为M。然后将M和D集合合并,并从B集合中去除M。再循环集合B中的每个预测框。对于传统的NMS操作,若B中预测框和M 的IoU值大于阈值N,,
那么就从B和S中去除该预测框和对应的置信度s,计算公式如式3-12。但在Soft-NMS 中,先计算B中的预测框和M的IoU,然后该IoU值作为函数f)的输入,最后和预测框b,的置信度s,相乘,作为最终的置信度分数,计算公式如式所示。因此,Soft-NMS算法与传统NMS 算法的不同之处在于处理之后s,的取值不同。
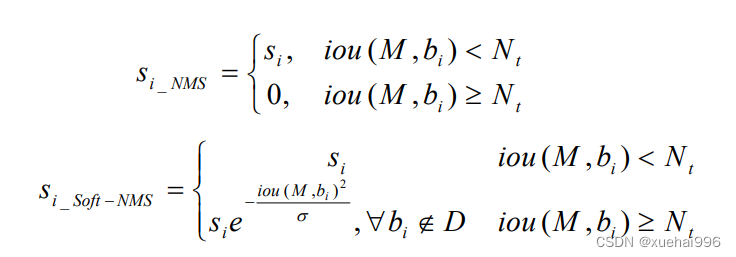
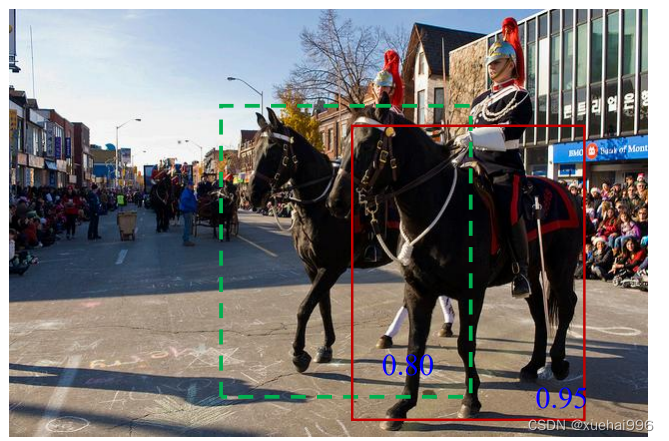
在图中,算法输出了两匹马的检测框,红框检测到马的置信度是0.95,绿框检测另一匹马的置信度是0.80,绿色框和红色框有明显重叠。NMS 算法思想是取置信度最大的框为基准,当检测到有任何与基准框的IoU超过阈值时,则说明两框较为相似并且可能指向一个物体,因此若红绿两框的IoU大于设定阈值,NMS算法则会将绿色矩形框剔除掉,而Soft-NMS 算法用稍低的置信度取代原来绿色框的置信度,最终避免去除掉绿色框,由此看来,Soft-NMS 算法更有效一些。
9.训练结果可视化分析
评价指标
训练和测试损失:在训练和测试过程中损失如何随时间推移而减少,表明模型最小化错误的能力。
准确度(Top-1 和 Top-5):模型正确预测手势的准确度,其中 top-1 准确度表示正确预测手势的比例,top-5 准确度可以显示正确手势是否在前 5 个预测之内。
学习率调整:学习率的变化如何影响模型在各个时期的性能。
训练结果可视化
我将为这些方面创建可视化,然后进行详细分析。让我们从可视化开始。
import matplotlib.pyplot as plt
import seaborn as sns
# Setting up the aesthetic style for the plots
sns.set(style="whitegrid")
# Plotting the training and testing loss
plt.figure(figsize=(12, 6))
plt.plot(data['epoch'], data['train/loss'], label='Training Loss')
plt.plot(data['epoch'], data['test/loss'], label='Testing Loss')
plt.title('Training and Testing Loss Across Epochs')
plt.xlabel('Epochs')
plt.ylabel('Loss')
plt.legend()
plt.show()
# Plotting the accuracy (Top-1 and Top-5)
plt.figure(figsize=(12, 6))
plt.plot(data['epoch'], data['metrics/accuracy_top1'], label='Top-1 Accuracy')
plt.plot(data['epoch'], data['metrics/accuracy_top5'], label='Top-5 Accuracy')
plt.title('Top-1 and Top-5 Accuracy Across Epochs')
plt.xlabel('Epochs')
plt.ylabel('Accuracy')
plt.legend()
plt.show()
# Plotting the learning rate adjustments
plt.figure(figsize=(12, 6))
plt.plot(data['epoch'], data['lr/0'])
plt.title('Learning Rate Adjustments Across Epochs')
plt.xlabel('Epochs')
plt.ylabel('Learning Rate')
plt.show()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
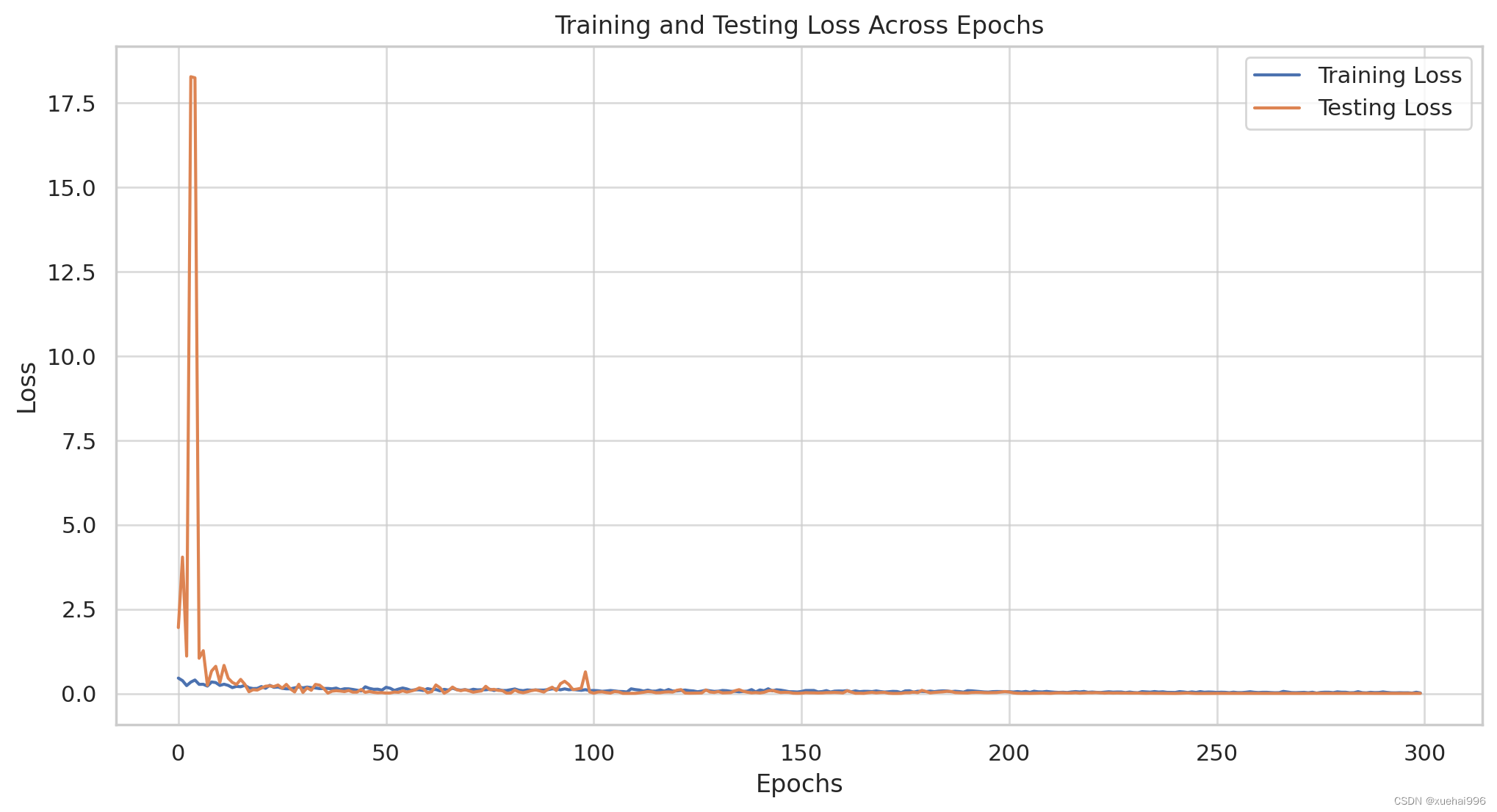
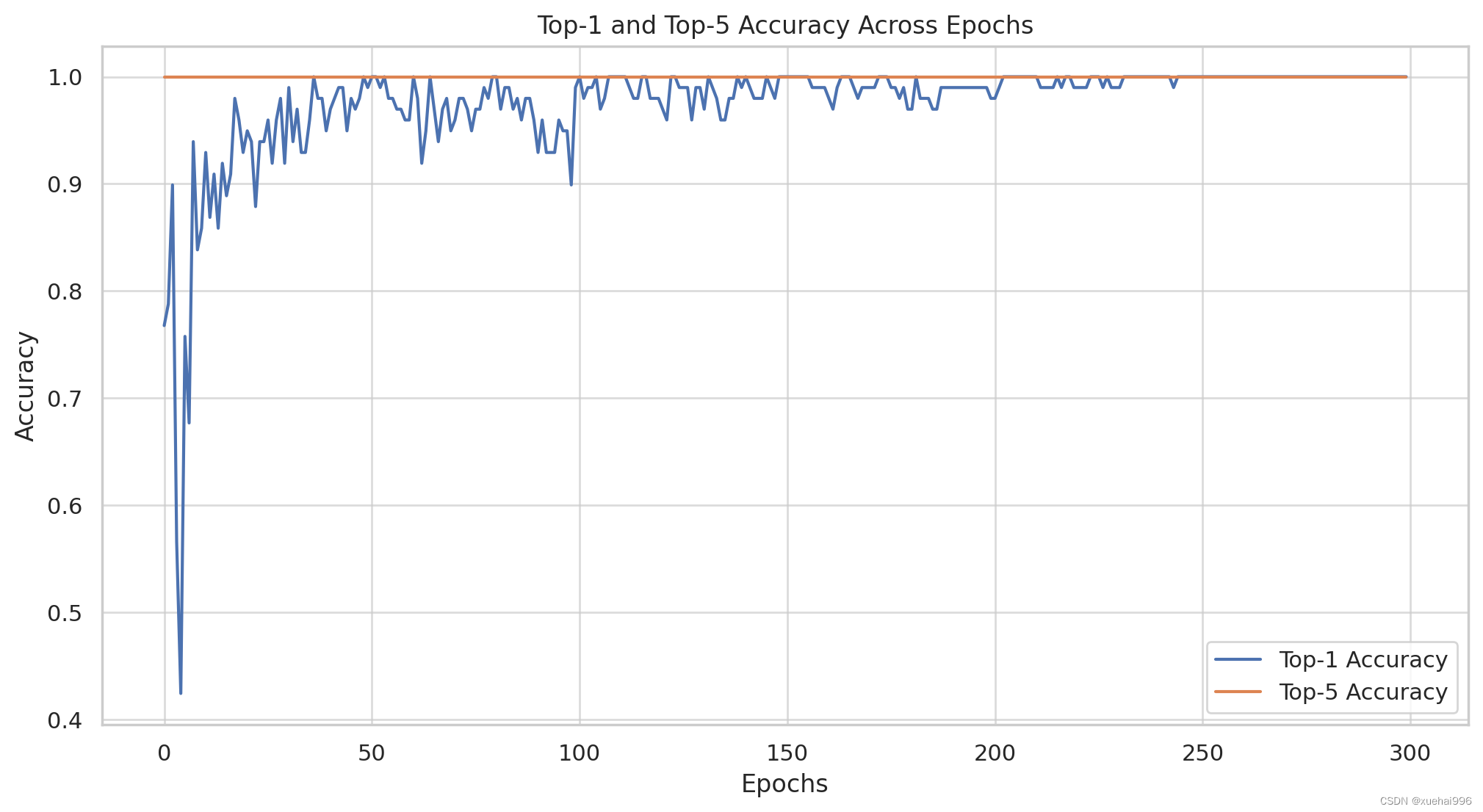
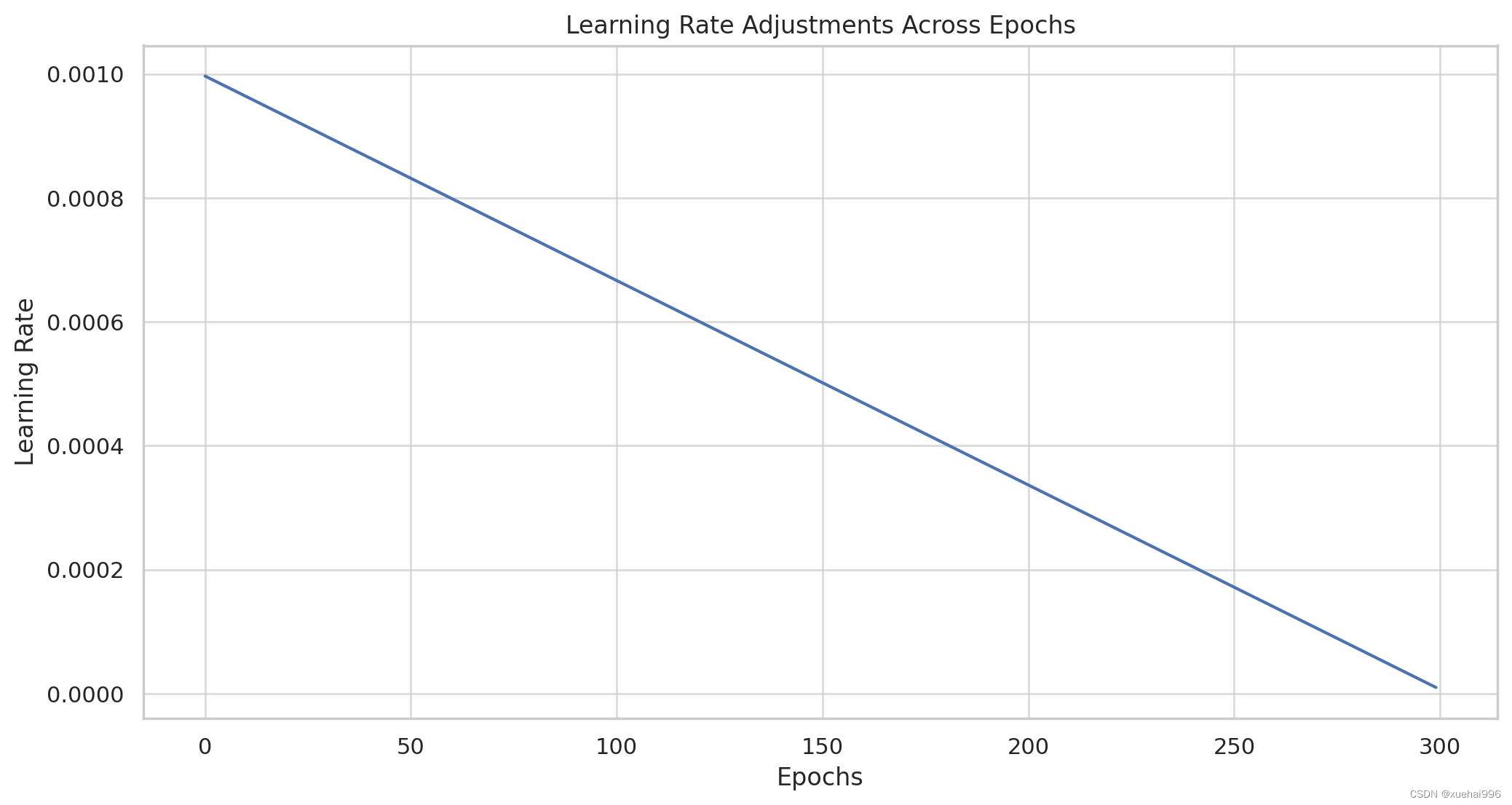
可视化提供了手势识别人工智能系统的性能和训练动态的清晰概述。现在,我们来详细分析一下:
训练和测试损失
观察:训练和测试损失图显示了模型的错误率如何随时间变化。
分析:理想情况下,训练和测试损失都应稳步下降,表明模型正在有效学习并且能够很好地推广到新数据。这两者之间的任何显着差异,特别是如果测试损失增加或波动很大,都可能表明过度拟合。
准确率(Top-1 和 Top-5)
观察:这些指标衡量模型正确识别手势的能力。
分析:
Top-1 Accuracy:显示模型第一选择正确的次数比例。在历元内提高 top-1 准确率是可取的,因为它表明精度提高了。
Top-5 准确度:如果分类问题具有大量类别或存在相似的手势类型,则此指标尤其相关。较高的前 5 名准确率可能表明正确答案通常位于模型的前 5 名预测中,即使它不是首选。
学习率调整
观察:学习率对于训练效率和收敛性至关重要。
分析:
稳定性和收敛性:学习率过高可能导致模型过快收敛到次优解,或者振荡而不稳定。相反,学习率太低会减慢训练过程或导致模型陷入局部最小值。
自适应学习率:如果学习率在历元内发生变化(如可视化所示),则表明采用自适应方法,可能会根据训练进度调整学习率。
进一步的分析考虑
过度拟合与泛化:寻找过度拟合的迹象,例如训练损失减少而测试损失增加。
一致性和趋势:在损失减少和准确性增加方面历代以来的持续改进是积极的迹象。突然的变化或不稳定的趋势需要进一步调查。
Epoch-wise 分析:某些 epoch 可能会表现出性能的显着改进或下降。这些点对于理解模型行为至关重要。
与基线模型的比较:将这些结果与基线模型或之前的迭代进行比较以衡量改进是很有帮助的。
外部因素:考虑可能影响训练的外部因素,例如数据质量、多样性和代表性。
10.系统整合
下图[完整源码&数据集&环境部署视频教程&自定义UI界面]

参考博客《改进Soft-nms的YOLO的手势识别&石头剪刀布游戏AI对战系统(IoU,GIoU,DIoU,CIoU,EIoU,SIoU)》

