
- 1vue 路由 router routhis.$route.params 获取值 和 get 请求 this.$route.query_this.$route.query能手动赋值吗
- 2HarmonyOS鸿蒙基于Java开发: Java UI 使用工具自动生成JS FA调用PA代码
- 3语音特征提取: 梅尔频谱(Mel-spectrogram)与梅尔倒频系数(MFCCS)_mel spectogram
- 4一文读懂人脸识别技术_人脸识别理论上需要多少个像素
- 5Docker 将容器重命名 | docker rename_docker -compose 命名
- 6干货 | 实用指南之fMRI表征相似性分析_rsa探照灯
- 7在 Linux 上手动安装 VMware Tools_linux虚拟机如何手动安装vmware tools
- 8【读书笔记】数据驱动业务--talkindata_talking data 缺点
- 9XLNet论文解读+部分代码解读_xlnet原论文
- 10小程序h5 实现全景图播放功能(如vr看房)_微信小程序实现全景vr
导数,偏导数,方向导数与梯度的定义与联系_偏导数 delta x/2
赞
踩
参考博客https://blog.csdn.net/baishuo8/article/details/81408369和知乎https://www.zhihu.com/question/36301367
一、导数(derivative)
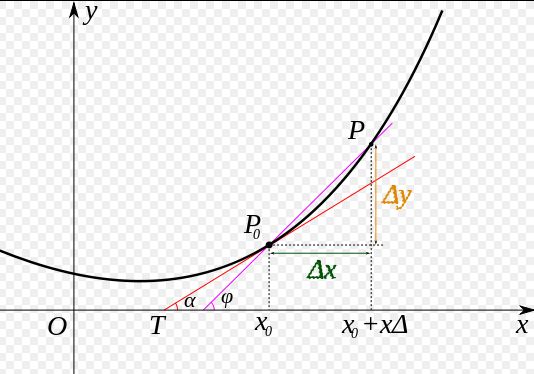
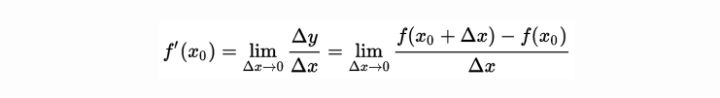
导数,是我们最早接触的一元函数中定义的,可以在 xy 平面直角坐标系中方便的观察。当 Δx→0时,P0处的导数就是因变量y在x0处的变化率,反映因变量随自变量变化的快慢;从几何意义来讲,函数在一点的导数值就是过这一点切线的斜率。
二、偏导数(partial derivative)
偏导数对应多元函数的情况,对于一个 n元函数 y=f(x1,x2,…,xn),在 ℝn 空间内的直角坐标系中,函数沿着某一条坐标轴方向的导数,就是偏导数。在某一点处,求 xi轴方向的导数,就是将其他维的数值看做常数,去截取一条曲线出来,这条曲线的导数可以用上面的导数定义求。求出来就是此点在这条轴方向上的偏导数。
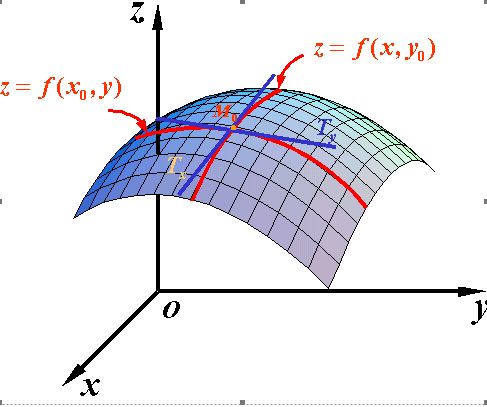
三、方向导数 (directional derivative)
很多时候,仅仅有了坐标轴方向上的偏导数是不够的,我们还想知道任意方向上的导数。函数在任意方向上的导数就是方向导数。而空间中任意方向,是一定可以用坐标轴线性组合来表示的,这就架起了偏导数和方向导数的桥梁:
令 ,
其中,α是由偏导数定义的向量A 与 我们自己找的单位方向向量 I之间的夹角。
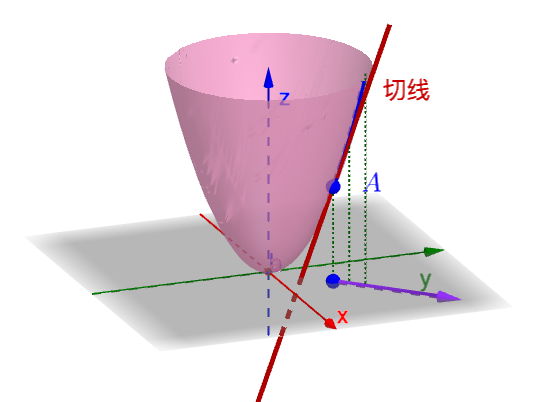
现在我们来讨论函数![]() 在一点
在一点![]() 沿某一方向的变化率问题.
沿某一方向的变化率问题.
定义 设函数![]() 在点
在点![]()
![]() 的某一邻域
的某一邻域![]() 内有定义.自点
内有定义.自点![]() 引射线
引射线![]() .设
.设![]() 轴正向到射线
轴正向到射线![]() 的转角为
的转角为![]() (逆时针方向:
(逆时针方向:![]()
![]() 0;顺时针方向:
0;顺时针方向:![]()
![]() 0),并设
0),并设![]() '(
'(![]() +△
+△![]() ,
,![]() +△
+△![]() )为
)为![]() 上的另一点且
上的另一点且![]() '∈
'∈![]() .我们考虑函数的增量
.我们考虑函数的增量![]() (
(![]() +△
+△![]() ,
,![]() +△
+△![]() )-
)-![]()
![]() 与
与![]() 、
、![]() '两点间的距离
'两点间的距离![]() 的比值.当
的比值.当![]() '沿着
'沿着![]() 趋于
趋于![]() 时,如果这个比的极限存在,则称这极限为函数
时,如果这个比的极限存在,则称这极限为函数![]()
![]() 在点
在点![]() 沿方向
沿方向![]() 的方向导数,记作
的方向导数,记作![]() ,即
,即
![]() (1)
(1)
从定义可知,当函数![]()
![]() 在点
在点![]()
![]() 的偏导数
的偏导数![]() x、
x、![]() y存在时,函数在点
y存在时,函数在点![]() 沿着
沿着![]() 轴正向
轴正向![]()
![]() =
=![]() ,
,![]() 轴正向
轴正向![]() =
=![]() 的方向导数存在且其值依次为
的方向导数存在且其值依次为![]() x、
x、![]() y,函数
y,函数![]()
![]() 在点
在点![]() 沿
沿![]() 轴负向
轴负向![]() =
=![]() ,
,![]() 轴负向
轴负向![]() =
=![]() 的方向导数也存在且其值依次为-
的方向导数也存在且其值依次为-![]() x、-
x、-![]() y.
y.
关于方向导数![]() 的存在及计算,我们有下面的定理.
的存在及计算,我们有下面的定理.
定理 如果函数![]() 在点
在点![]()
![]() 是可微分的,那末函数在该点沿任一方向的方向导数都存在,且有
是可微分的,那末函数在该点沿任一方向的方向导数都存在,且有
![]()
![]() (2)
(2)
其中![]() 为
为![]() 轴到方向
轴到方向![]() 的转角.
的转角.
证 根据函数![]() 在点
在点![]()
![]() 可微分的假定,函数的增量可以表达为
可微分的假定,函数的增量可以表达为
![]()
两边各除以![]() ,得到
,得到
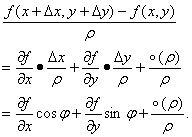
所以 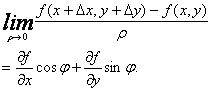
![]() 这就证明了方向导数存在且其值为
这就证明了方向导数存在且其值为
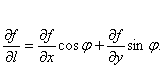
在训练神经网络时,我们都是通过定义一个代价函数(cost function),然后通过反向传播更新参数来最小化代价函数,深度神经网络可能有大量参数,因此代价函数是一个多元函数,多元函数与一元函数的一个不同点在于,过多元函数的一点,可能有无数个方向都会使函数减小。引申到数学上,我们可以把山这样的曲面看作一个二元函数z=f(x,y),二元函数是多元函数里最简单的情形,也是易于可视化直观理解的。前面提到一元函数导数的几何意义是切线的斜率,对于二元函数,曲面上的某一点(x0,y0,z0)会有一个切平面,切平面上的无数条直线都是过这一点的切线,这些切线的斜率实际上就是过这一点的无数个方向导数的值,和一元函数一样,方向导数的值实际反映了多元函数在这一点沿某个方向的变化率。
四、梯度 (gradient)与神经网络中的梯度下降
在上面的方向导数中,
- A是固定的
- |I|=1是固定的
- 唯一变化的就是 α
当 I与 A 同向的时候,方向导数取得最大,此时我们定义一个向量 ,其方向就是 A的方向,大小就是 A的模长,我们称这个向量就是此点的梯度。沿着梯度方向,就是函数增长最快的方向,那么逆着梯度方向,自然就是函数下降最快的方向。由此,我们可以构建基于梯度的优化算法。正如下山必然有一条最陡峭、最快的路径,方向导数也有一个最小值,在最小值对应的方向上,函数下降最快,而这个方向其实就是梯度的反方向。对于神经网络,在方向导数最小的方向更新参数可以使代价函数减小最快,因此梯度下降法也叫最速下降法。
向量(fx(x0,y0),fy(x0,y0))就是函数f(x,y)在点P0(x0,y0)的梯度,由此引出梯度的概念,梯度就是一个向量,这个向量的每个元素分别是多元函数关于每个自变量的偏导数。方向导数的值最大,多元函数增加最快,也就是说梯度的方向就是函数增加最快的方向,方向导数的值最小,多元函数减小最快,也就是在梯度相反的方向上,方向导数最小。
1.梯度的定义
与方向导数有关联的一个概念是函数的梯度.
定义 设函数![]() 在平面区域
在平面区域![]() 内具有一阶连续偏导数,则对于每一点
内具有一阶连续偏导数,则对于每一点![]()
![]()
![]() ,都可定出一个向量
,都可定出一个向量
![]()
这向量称为函数![]() =
=![]() 在点
在点![]()
![]() 的梯度,记作
的梯度,记作![]()
![]()
![]() ,即
,即
![]()
![]()
![]() =
= ![]()
如果设![]() 是与方向
是与方向![]() 同方向的单位向量,则由方向导数的计算公式可知
同方向的单位向量,则由方向导数的计算公式可知
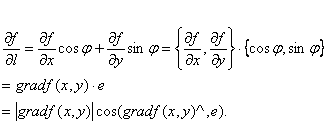
这里,(![]()
![]()
![]() ^,e)表示向量
^,e)表示向量![]()
![]()
![]() 与
与![]() 的夹角.由此可以看出,就是梯度在射线
的夹角.由此可以看出,就是梯度在射线![]() 上的投影,当方向
上的投影,当方向![]() 与梯度的方向一致时,有
与梯度的方向一致时,有
![]() (
(![]()
![]()
![]() ^,
^,![]() )
) ![]() 1,
1,
从而![]() 有最大值.所以沿梯度方向的方向导数达到最大值,也就是说,梯度的方向是函数
有最大值.所以沿梯度方向的方向导数达到最大值,也就是说,梯度的方向是函数![]()
![]() 在这点增长最快的方向.因此,我们可以得到如下结论:
在这点增长最快的方向.因此,我们可以得到如下结论:
函数在某点的梯度是这样一个向量,它的方向与取得最大方向导数的方向一致,而它的模为方向导数的最大值.
由梯度的定义可知,梯度的模为
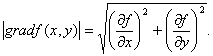
当![]() 不为零时,那么
不为零时,那么![]() 轴到梯度的转角的正切为
轴到梯度的转角的正切为
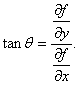
我们知道,一般说来二元函数![]() 在几何上表示一个曲面,这曲面被平面z=c(c是常数)所截得的曲线
在几何上表示一个曲面,这曲面被平面z=c(c是常数)所截得的曲线![]() 的方程为
的方程为
![]()
这条曲线![]() 在
在![]() 面上的投影是一条平面曲线
面上的投影是一条平面曲线![]() (图8―10),它在
(图8―10),它在![]() 平面直角坐标系中的方程为
平面直角坐标系中的方程为
![]()
对于曲线![]() 上的一切点,已给函数的函数值都是
上的一切点,已给函数的函数值都是![]() ,所以我们称平面曲线
,所以我们称平面曲线![]() 为函数
为函数![]() 的等高线.
的等高线.
由于等高线![]() 上任一点
上任一点![]() 处的法线的斜率为
处的法线的斜率为
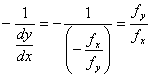 ,
,
所以梯度 ![]()
为等高线上点![]() 处的法向量,因此我们可得到梯度与等高线的下述关系:函数
处的法向量,因此我们可得到梯度与等高线的下述关系:函数![]() 在点
在点![]()
![]() 的梯度的方向与过点
的梯度的方向与过点![]() 的等高线
的等高线![]() 在这点的法线的一个方向相同,且从数值较低的等高线指向数值较高的等高线(图8―10),而梯度的模等于函数在这个法线方向的方向导数.这个法线方向就是方向导数取得最大值的方向.
在这点的法线的一个方向相同,且从数值较低的等高线指向数值较高的等高线(图8―10),而梯度的模等于函数在这个法线方向的方向导数.这个法线方向就是方向导数取得最大值的方向.
2、解释方向导数只有一个最小值:

具有一阶连续偏导数,意味着可微。可微意味着函数 在各个方向的切线都在同一个平面上,也就是切平面。所有的切线都在一个平面上,就好像光滑的笔直的玻璃上,某一点一定有且只有一个最陡峭的地方,因为方向导数是切线的斜率,方向导数最大也就意味着最陡峭。
3、解释最大值在哪个方向?
最大值的方向是梯度的方向。演示参照https://www.matongxue.com/madocs/222.html
五、小结
- 导数、偏导数和方向导数衡量的都是函数的变化率;
- 梯度是以多元函数的所有偏导数为元素的向量,代表了函数增加最快的方向;
- 在梯度反方向上,多元函数的方向导数最小,函数减小最快;在神经网络中,在梯度反方向更新参数能最快使代价函数最小化,所以梯度下降法也叫最速下降法。

