
- 1Linux如何将文件或目录打成rpm包? -- fpm打包详解_如何将包转成rpm
- 2[C++]Leetcode超高效刷题顺序及题目详解笔记(持续更新中)_c++刷题顺序
- 3【前端】HTML(常用的HTML标签)
- 4python使用selenium模拟人工操作
- 5Hive 分区表 & 数据加载_hive分区表load数据
- 6开启微软 Outlook 邮箱 POP, IMAP, SMTP 服务和获取服务密码(授权码)_imap/pop密码
- 7Git修改提交用户名称_修改git提交用户名
- 8IDEA git 操作中的Merge和Rebase_merge incoming changes
- 9JS逆向解析
- 10R读取一个txt中的列表为向量_r语言将txt转换为向量
NLP 自然语言处理实战
赞
踩
前言
自然语言处理 ( Natural Language Processing, NLP) 是计算机科学领域与人工智能领域中的一个重要方向。它研究能实现人与计算机之间用自然语言进行有效通信的各种理论和方法,用于分析理解机器与人之间的交互,常用的领域有:实体识别、文本纠错、情感分析、文本分类、关键词提取、自动摘要提取等方面。
本文将从分词、词频、词向量等基础领域开始讲解自然语言处理的原理,讲解 One-Hot、TF-IDF、PageRank 等算法及 LDA、LDiA、LSA 等语义分析的原理。
介绍 Word2vec、GloVe 等常用词嵌入及 NLTK、Jieba 等分词工具的应用。
目录
一、自然语言处理的概念
1.1 自然语言处理的起源
语言是人类社会发展过程的产物,是最能体现人类智慧和文明的证明,也是人类与动物最大的区别。它是一种人与人交流的载体,像计算机网络一样,我们使用语言相互传递知识。在人类历史的几千年,语言不断地繁衍发展。
在计算机兴趣的近几十年,科学界正在试图不断努力,把人类的语言演变成分析数据特征的依据。在1970年,有两位美国人 Richard Bandler 和 John Grinder 因不满于传统心理学派的治疗过程冗长,及其效果常反复不定,而集合各家所长以及他们独特的创见,在美国加州大学内(NLP的发源地)利用课余时间开始研究。经过三年多的实验与练习,终于逐渐形成NLP神经语法程式学的基础架构。
随着近年来人工智能的崛起,自然语言处理(NLP)更成为一种专业分析人类语言智能工具,被应用到了多个层面:
(1)机器翻译
机器翻译是利用计算机将某一种语言文本自动翻译成另一种语言文本的方法,它基于语言规则,利用统计的统计原理进度混合计算,得出最终结果。最常见于百度翻译、金山 iciba 翻译、有道翻译、google 翻译等。
(2)自动问答
自动问答通过计算机对人提出的问题的理解,利用自动推理等手段,在有关知识资源中自动求解答案并做出相应的回答。它利用语词提取、关键字分析、摘要分析等方式提取问题的核心主干,然后利用 NLP 分析数据选择出最合适的答案。常见的例子有在线问答 ask.com、百度知道、yahoo 回答等。
(3)语音处理
语言处理(speech processing)可以把将输入语音信号自动转换成书面文字或计算机命令,然后对任务进行操作处理。常见的应用场景有汽车的语言识别、餐厅智能点餐、机场火车站的智能预订航班、智能机器人等。
(4)情感分析
从大量文档中检索出用户的情感方向,对商品评价、服务评价等的满意进行分析,对用户进行商品服务推荐。在京东、淘宝等各大的购物平台很常用。
1.2 自然语言处理的阶段
自然语言实现一般都通过以下几个阶段:文本读取、分词、清洗、标准化、特征提取、建模。首先通过文本、新闻信息、网络爬虫等渠道获取大量的文字信息。然后利用分词工具对文本进行处理,把语句分成若干个常用的单词、短语,由于各国的语言特征有所区别,所以NLP也会有不同的库支撑。对分好的词库进行筛选,排除掉无用的符号、停用词等。再对词库进行标准化处理,比如英文单词的大小写、过去式、进行式等都需要进行标准化转换。然后进行特征提取,利用 tf-idf、word2vec 等工具包把数据转换成词向量。最后建模,利用机器学习、深度学习等成熟框架进行计算。
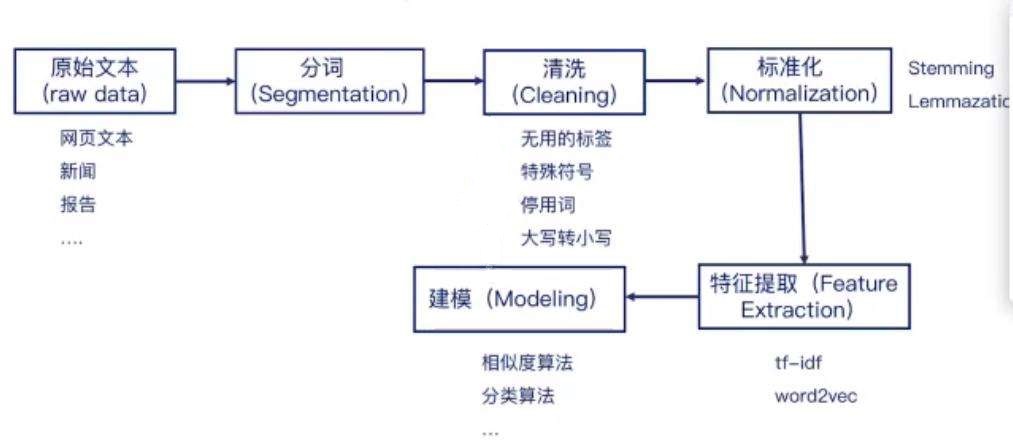
下面将对这几个处理流程进行逐一介绍。
二、分词器的原理及应用
| 2.1 分词器的基本原理 在自然语言处理的过程中,把切分文件是流水线的第一步,它能够把文本拆分为更小的文本块或词语片段多块信息,每块信息都可以被看成是一个元素,这此元素出现的频率可以直接被看作为文本的向量。 data='NLP stands for Natural Language Processing.' data.split() 结果 ['NLP', 'stands', 'for', 'Natural', 'Language', 'Processing.'] 你可能已经看到,直接对语句进行拆分可以会把标点符号 ‘ . ’ 也带进数组。还有一些无用的操作符 ‘. ?!’ 等,最后势必会影响输出的结果。想要实现这类最简单的数据清洗,可以使用正则表达式来解决。 data='NLP is the study of excellent communication–both with yourself, and with others.' data=re.split(r'[-\s.?,!]',data) 当想去除一些无用的停用词(例如 'a,A' )、对词库进行标准化处理(例如词干还原,把进行式 building 转化成 build,把过去式 began 转化为 begin) 还有大小写转换时,可以使用成熟的库来完成。 多国的语言都有差异,所以分词器的处理方式也有区别,下面将介绍英语单词与中文词汇比较常用的分词器 NLTK 和 Jieba 。 |
|
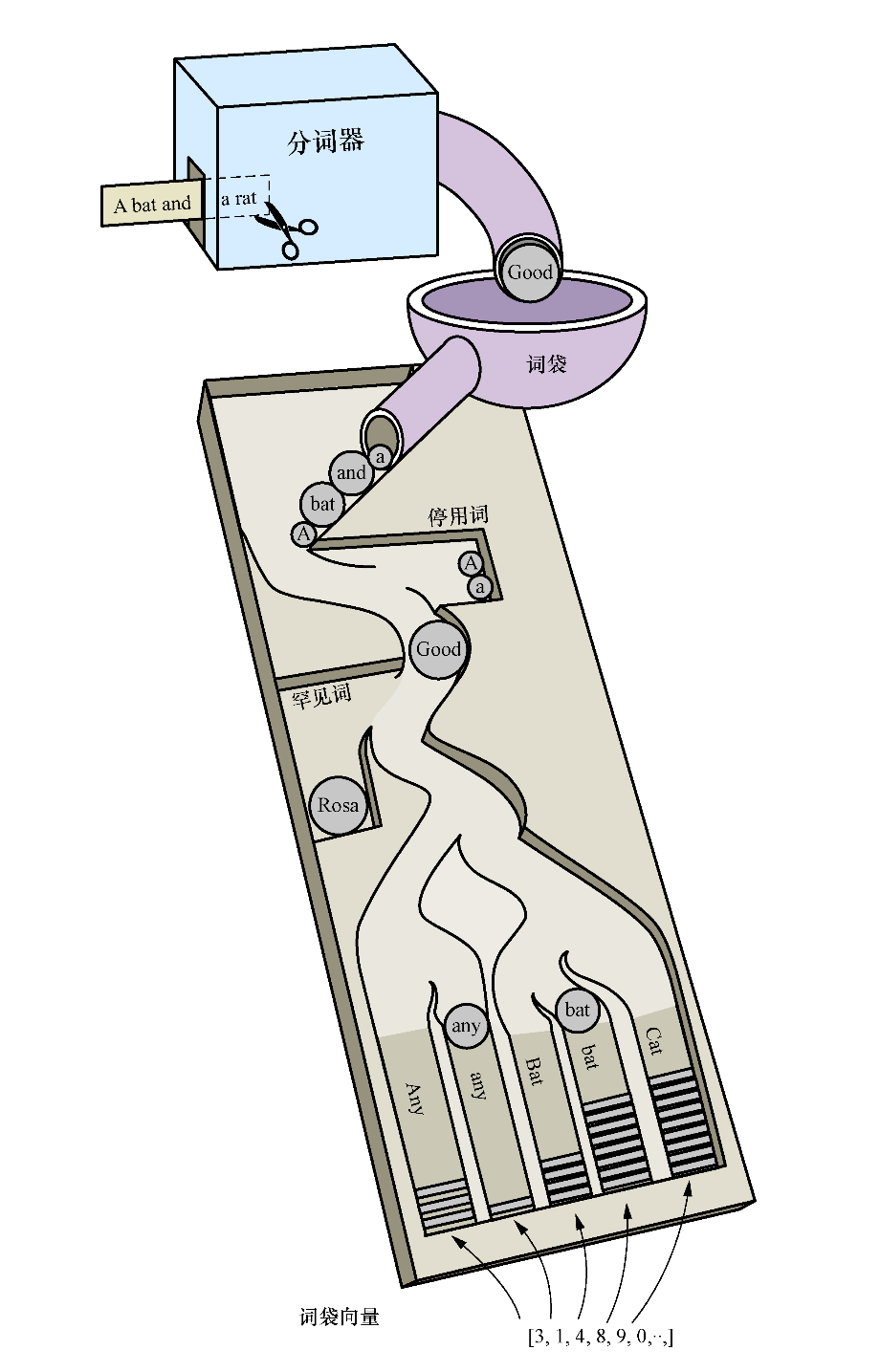
2.2 NLTK 库基础功能介绍
NLTK 使用 Python 程序编写,它提供了一套用于分类,标记化,词干化,标记,解析和语义推理的文本处理库,相关的模块如下。

2.2.1 分句 SentencesSegment
例如有一段文本里面包含三个句子,希望把它分成一个一个的句子。此时可以使用NLTK中的 punktsentencesegmenter。
1 sent_tokenizer = nltk.data.load('tokenizers/punkt/english.pickle')
2 paragraph = "The first time I heard that song was in Hawaii on radio. ”+
3 "I was just a kid, and loved it very much! What a fantastic song!"
4 sentences = sent_tokenizer.tokenize(paragraph)
5 print(sentences)
运行结果
['The first time I heard that song was in Hawaii on radio.',
'I was just a kid, and loved it very much!',
'What a fantastic song!']
2.2.2 分词 WordPunctTokenizer
1 from nltk.tokenize import WordPunctTokenizer 2 sentence = "Are you old enough to remember Michael Jackson attending ”+ 3 “the Grammys with Brooke Shields and Webster sat on his lap during the show?" 4 words = WordPunctTokenizer().tokenize(sentence) 5 print(words)
运行结果
['Are', 'you', 'old', 'enough', 'to', 'remember', 'Michael', 'Jackson', 'attending',
'the', 'Grammys', 'with', 'Brooke', 'Shields', 'and', 'Webster', 'sat', 'on', 'his',
'lap', 'during', 'the', 'show', '?']
2.2.3 正则表达式 RegexpTokenizer
最简单的方法去掉一些从文档中存在的 \n \t 等符号
1 from nltk.tokenize import RegexpTokenizer 2 sentence='Thomas Jefferson began \n building \t Monticello at the age of 26.' 3 tokenizer=RegexpTokenizer(r'\w+|$[0-9.]+|\S+') 4 print(tokenizer.tokenize(sentence))
运行结果
['Thomas', 'Jefferson', 'began', 'building', 'Monticello', 'at', 'the', 'age', 'of', '26', '.']
2.2.4 分词 TreebankWordTokenizer
TreebankWordTokenizer 拥有比 WordPunctTokenizer 更强大的分词功能,它可以把 don't 等缩写词分为[ "do" , " n't " ]
1 from nltk.tokenize import TreebankWordTokenizer 2 sentence="Sorry! I don't know." 3 tokenizer=TreebankWordTokenizer() 4 print(tokenizer.tokenize(sentence))
运行结果
['Sorry', '!', 'I', 'do', "n't", 'know', '.']
2.2.5 词汇统一化
2.2.5.1 转换大小写
词汇统一化最常用的就是把大小进行统一化处理,因为很多搜索工具包都会把大小写的词汇例如 City 和 city 视为不同的两个词,所以在处理词汇时需要进行大小写转换。当中最简单直接的方法就是直接使用 str.lower() 方法。
2.2.5.2 词干还原
当单词中存在复数,过去式,进行式的时候,其词干其实是一样的,例如 gave , giving 词干都是 give 。相同的词干其实当中的意思是很接近的,通过词干还原可以压缩单词的数据,减少系统的消耗。NLTK 中提供了 3 个常用的词干还原工具:porter、lancaster、snowball ,其使用方法相类似,下面用 porter 作为例子。可以 playing boys grounded 都被完美地还原,但对 this table 等单词也会产生歧义,这是因为被原后的单词不一定合法的单词。
1 from nltk.stem import porter as pt 2 3 words = [ 'wolves', 'playing','boys','this', 'dog', 'the', 4 'beaches', 'grounded','envision','table', 'probably'] 5 stemmer=pt.PorterStemmer() 6 for word in words: 7 pt_stem = stemmer.stem(word) 8 print(pt_stem)
运行结果

2.2.5.3 词形并归
想要对相同语义词根的不同拼写形式都做出统一回复的话,那么词形归并工具就很有用,它会减少必须要回复的词的数目,即语言模型的维度。例如可以 good、goodness、better 等都归属于同一处理方式。通过wordnet.lemmatize(word,pos) 方法可指定词性,与常用的英语单词类似,n 为名词 v为动词 a为形容词等等。指定词性后还可以通过posterStemmer.stem() 还原词干。
1 stemmer=PorterStemmer()
2 wordnet=WordNetLemmatizer()
3 word1=wordnet.lemmatize('boys',pos='n')
4 print(word1)
5
6 word2=wordnet.lemmatize('goodness',pos='a')
7 word2=stemmer.stem(word2)
8 print(word2)
运行结果

2.2.6 停用词
在词库中往往会存在部分停用词,使用 nltk.corpus.stopwords 可以找到 NLTK 中包含的停用词
1 stopword=stopwords.raw('english').replace('\n',' ')
2 print(stopword)
运行结果

通过对比可以对文件中的停用词进行过滤
1 words = [ 'the', 'playing','boys','this', 'dog', 'a',]
2 stopword=stopwords.raw('english').replace('\n',' ')
3 words=[word for word in words if word not in stopword]
4 print(words)
运行结果
['playing', 'boys', 'dog']
2.2.3 把词汇扩展到 n-gram
上面例子中基本使用单个词作用分词的方式,然而很多短语例如:ice cream,make sense,look through 等都会多个单词组合使用,相同的单词在不同的短语中会有不同的意思。因此,分词也需要有 n-gram 的能力。针对这个问题 NTLK提供了 ngrams 函数,它可以按实现 2-gram、3-gram等多类型的元素划分。
1 sentence='Build the way that works best for you '+\ 2 'with support for all your go-to integrations '+\ 3 'including Slack Jira and more.' 4 words=sentence.split() 5 print(list(ngrams(words,2)))
运行结果

2.3 Jieba 库基础功能介绍
NLTK 库有着强大的分词功能,然而它并不支中文,中文无论从语法、格式、结构上都有很大的差别,下面介绍一个常用的中文库 Jieba 的基础功能。
2.3.1 分词 jieba.cut
jieba.cut 是最常用的分词方法,返回值为 generator。jieba.lcut 与 jieba.cut 类似,区别在于 jieba.lcut 直接返回 list。在数据量比较大时,jieba.cut 会更节省内存。
1 def cut(self, sentence, cut_all=False, HMM=True, 2 use_paddle=False):
- sentence 可为 unicode 、 UTF-8 字符串、GBK 字符串。注意:不建议直接输入 GBK 字符串,可能无法预料地错误解码成 UTF-8。
- 当 cut_all 返回 bool,默认为 False。当 True 则返回全分割模式,为 False 时返回精准分割模式。
- HMM 返回 bool,默认为 True,用于控制是否使用 HMM 隐马尔可夫模型。
- use_paddle 返回 bool, 默认为 False, 用来控制是否使用paddle模式下的分词模式,paddle模式采用延迟加载方式,利用PaddlePaddle深度学习框架,训练序列标注(双向GRU)网络模型实现分词,同时支持词性标注。
使用例子
1 sentence='嫦娥四号着陆器地形地貌相机对玉兔二号巡视器成像' 2 word1=jieba.cut(sentence,False) 3 print(list(word1)) 4 word2=jieba.cut(sentence,True) 5 print(list(word2))
运行结果

2.3.2 搜索分词 jieba.cut_for_search
jieba.cut_for_search 与 jieba.cut 精确模式类似,只是在精确模式的基础上,对长词再次切分,提高召回率,适合用于搜索引擎分词,返回值为 generator。jieba.lcut_for_search 与 jieba.cut_for_search 类似,但返回值为 list。
1 def cut_for_search(self, 2 sentence: Any, 3 HMM: bool = True) -> Generator[str, Any, None]
- sentence 可为 unicode 、 UTF-8 字符串、GBK 字符串。
- HMM 返回 bool,默认为 True,用于控制是否使用 HMM 隐马尔可夫模型。
使用例子
1 word1=jieba.cut_for_search('尼康Z7II是去年底全新升级的一款全画幅微单相机',False)
2 print(list(word1))
3 word2=jieba.cut_for_search('尼康Z7II是去年底全新升级的一款全画幅微单相机',True)
4 print(list(word2))
运行结果

2.2.3 载入新词 jieba.load_userdict
通过此方法可以预先载入自定义的用词,令分词更精准。文本中一个词占一行,每一行分三部分:词语、词频(可省略)、词性(可省略),用空格隔开,顺序不可颠倒。
例如:设定 word.txt 文本
阿里云 1 n
云计算 1 n
1 word1=jieba.cut('阿里云是全球领先的云计算及人工智能科技公司')
2 print(list(word1))
3 jieba.load_userdict('C://Users/Leslie/Desktop/word.txt')
4 word2=jieba.cut('阿里云是全球领先的云计算及人工智能科技公司')
5 print(list(word2))
运行结果

2.2.4 动态调节词典
通过 jieba.add_word 和 jieba.del_word 这两个方法也可以动态地调节词典
1 def add_word(self, word, freq=None, tag=None):
jieba.add_word 可以把自定义词加入词典,当中 freq 为词频,tag 为词性。
1 def del_word(self, word):
相反,通过 jieba.del_word 可以动态删除加载的自定义词
1 word1=jieba.cut('阿里云是全球领先的云计算及人工智能科技公司')
2 print(list(word1))
3 jieba.add_word('阿里云')
4 jieba.add_word('云计算')
5 word2=jieba.cut('阿里云是全球领先的云计算及人工智能科技公司')
6 print(list(word2))
7 jieba.del_word('阿里云')
8 word3=jieba.cut('阿里云是全球领先的云计算及人工智能科技公司')
9 print(list(word3))
运行结果

2.2.5 词节词频 jieba.suggest_freq
此方法可调节单个词语的词频,使其能(或不能)被分出来。注意:自动计算的词频在使用 HMM 新词发现功能时可能无效。
1 def suggest_freq(self, segment, tune=False):
下面的例子就是把 “阿里云” 这个词拆分的过程
word1=jieba.cut('阿里云是全球领先的云计算及人工智能科技公司')
print(list(word1))
jieba.suggest_freq('阿里云',True)
word2=jieba.cut('阿里云是全球领先的云计算及人工智能科技公司',False,False)
print(list(word2))
jieba.suggest_freq(('阿里','云'),True)
word3=jieba.cut('阿里云是全球领先的云计算及人工智能科技公司',False,False)
print(list(word3))
运行结果

2.2.6 标注词性 jieba.posseg
通过 posseg.cut 可以查看标注词性,除此以外还可以 jieba.posseg.POSTokenizer 新建自定义分词器
1 words=jieba.posseg.cut('阿里云是全球领先的云计算及人工智能科技公司')
2 for word,flag in words:
3 print(word,flag)
运行结果
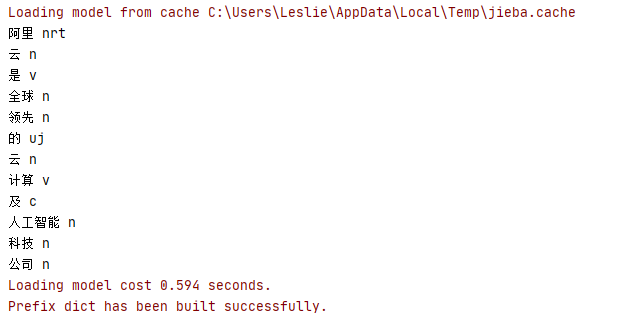
2.2.7 使用 jieba 计算词频</

