
- 1层与特征融合_每日一读:融合词性的双注意力 BiLSTM 情感分析
- 2多通路fpga 通信_【论文精选】基于FPGA的EtherCAT从站通信链路分析与验证
- 3手机访问电脑文件_【手机篇】巧借局域网,便捷实现手机电脑间的文件传输
- 4基于ERNIEPRO的文本分类与命名实体识别
- 5centos7使用rpmbuild制作rpm包_centos7 rpmbuild
- 6window 上跑hadoop问题之java.lang.UnsatisfiedLinkError: org.apache.hadoop.io.nativeio.NativeIO$Windows._windows hadoop start_all.cmd java.lang.unsatisfied
- 7雷电模拟器一直android正在启动,雷电安卓模拟器启动后没反应、无法启动、闪退的3种解决办法-针对2020年4月4号出现的...
- 8等保2.0 MySQL数据库测评_等保测评mysql数据库
- 9布隆过滤器C语言代码_bloom_filter_init(
- 10基于FPGA状态机设计实现EtherCAT从站基本通信链路并验证_基于fpga的ethercat从站通信
在Windows 10上部署ChatGLM2-6B:掌握信息时代的智能对话_chatglm 支持哪些操作系统
赞
踩
随着当代科技的快速发展,我们进入了一个数字化时代,其中信息以前所未有的速度传播。在这个信息爆炸的时代,我们不仅面临着巨大的机遇,还面临着挑战。为了更好地应对和充分利用这一趋势,我们需要掌握一些关键技能和工具。本文将向您介绍如何在Windows 10专业版22H2 x64操作系统上部署ChatGLM2-6B,这是一个强大的自然语言处理模型,用于智能对话。
本文面向的操作系统为 window10 专业版 22H2 x64,基于GPU的运算
硬件环境
| 名称 | 参数 |
|---|---|
| PC | HP Elite Tower 880 G9 |
| CPU | 16G |
| GPU | NVIDIA RTX3060 |
| 处理器 | 12th Gen Intel® Core™i7-12700 2.10GHz |
| 操作系统 | window 10 专业版 22H2 x64 |
ChatGLM2-6B的量化模型最低GPU配置说明
| 名称 | 参数 | 显存要求 |
|---|---|---|
| ChatGLM2-6B | FP16 | 13G |
| ChatGLM2-6B | INT4 | 6G |
| ChatGLM2-6B-32K | FP16 | 20G |
| ChatGLM2-6B-32K | INT4 | 13G |
注意:如果仅使用CPU部署,则ChatGLM2-6B的量化模型最低CPU 32G
准备工作
在部署ChatGLM2-6B之前,您需要进行一些准备工作
- 安装Git和Git LFS: 您可以从Git官方网站下载Git,并在安装时务必选择安装Git LFS选项,以支持大型文件的版本控制。
# window版Git安装时注意勾选git LFS选项即可
# Linux系统在安装完Git后,需额外安装git LFS
# 验证git是否正常: 出现版本信息为正常
git --version
# 验证git lfs是否正常:出现Git LFS initalized为正常
git lfs install
- 1
- 2
- 3
- 4
- 5
- 6
- 安装CUDA: CUDA是NVIDIA的并行计算平台,用于加速深度学习任务。您需要确保安装了与您的NVIDIA显卡驱动程序兼容的CUDA版本【CUDA下载地址】
# 查看NVIDIA CUDA version 和 Driver Version,一定要注意相关版本信息
nvidia-smi
# 在下载页面选择相关版本和信息后,下载安装包进行安装即可
- 1
- 2
- 3


- 安装Python【下载地址】: 安装Python,建议使用Python 3.10.10版本,并在安装时勾选将Python添加到系统变量PATH中。
注意:无需下载最新版本,本文选用python v3.10.10
更据安装包进行即可,注意勾选将python添加至系统变量PATH
- 安装PyTorch【下载地址】: 根据您的CUDA版本选择合适的PyTorch版本,并使用pip安装。确保PyTorch与CUDA版本兼容。
# 注意pytorch的版本,保证其和CUDA版本兼容
# 选择stable版,其余更据自己系统和情况选择,本文使用CUDA 11.8为最新版本(虽然CUDA版本为12.2,但是其支持向下兼容)
# 复制红框内容,在命令行中进行安装,等待完成
# 验证pytorch是否正常:进入命令行或PowerShell
python
>>> import torch
>>> print(torch.cuda.is_available())
>>> True
# 返回True即为正常
>>> quit()
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10

ChatGLM2-6B安装部署
- 下载仓库代码: 使用Git克隆ChatGLM2-6B仓库并安装依赖。
git clone https://github.com/THUDM/ChatGLM2-6B.git
cd ChatGLM2-6B
pip install -r requirements.txt
- 1
- 2
- 3
- 下载ChatGLM2-6B模型: 在项目目录下创建一个名为“model”的文件夹,并下载ChatGLM2-6B的模型文件。
mkdir model && cd model
git clone https://huggingface.co/THUDM/chatglm2-6b
git clone https://huggingface.co/THUDM/chatglm2-6b-int4
git clone https://huggingface.co/THUDM/chatglm2-6b-32k
git clone https://huggingface.co/THUDM/chatglm2-6b-32k-int4
- 1
- 2
- 3
- 4
- 5
请确保您下载了标记为LFS(Large File Storage)的文件,以获取完整的模型文件。
ChatGLM2-6B运行模式
在部署ChatGLM2-6B时,您可以选择不同的运行模式,包括Gradio网页模式、Streamlit网页模式、命令行模式和API模式。以>下是每种模式的简要说明:
Gradio网页模式
- 准备工作
# 进入项目目录
cd ChatGLM2-6B
# 复制一份web_demo.py
copy web_demo.py web_demo_bak.py
- 1
- 2
- 3
- 4
2.模型参数调整
tokenizer = AutoTokenizer.from_pretrained("model\\chatglm2-6b", trust_remote_code=True)
model = AutoModel.from_pretrained("model\\chatglm2-6b", trust_remote_code=True).cuda()
- 1
- 2

3.服务参数调整
# demo.queue().launch(share=False, inbrowser=True)
# concurrency_count: 表示可以同时使用网页的人数,超过就需要排队等候
# server_name: 开启局域网访问
# server_port: 指定端口访问
demo.queue(
concurrency_count=5,
).launch(share=False, inbrowser=True, server_name="0.0.0.0", server_port=8080)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 启动
python web_demo.py
- 1
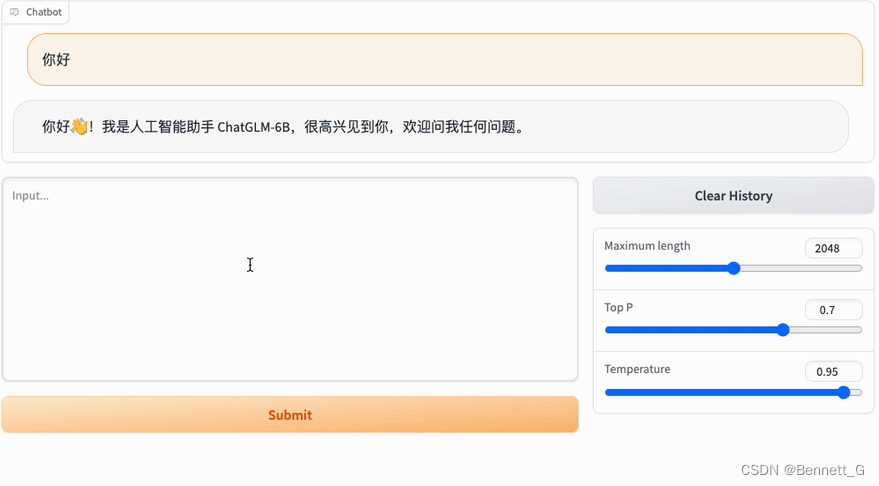
Streamlit网页
# 同Gradio配置类似,进行调整web_demo2.py
# 启动
streamlit run web_demo2.py
# 此命令会开启局域网服务,端口:8501
- 1
- 2
- 3
- 4
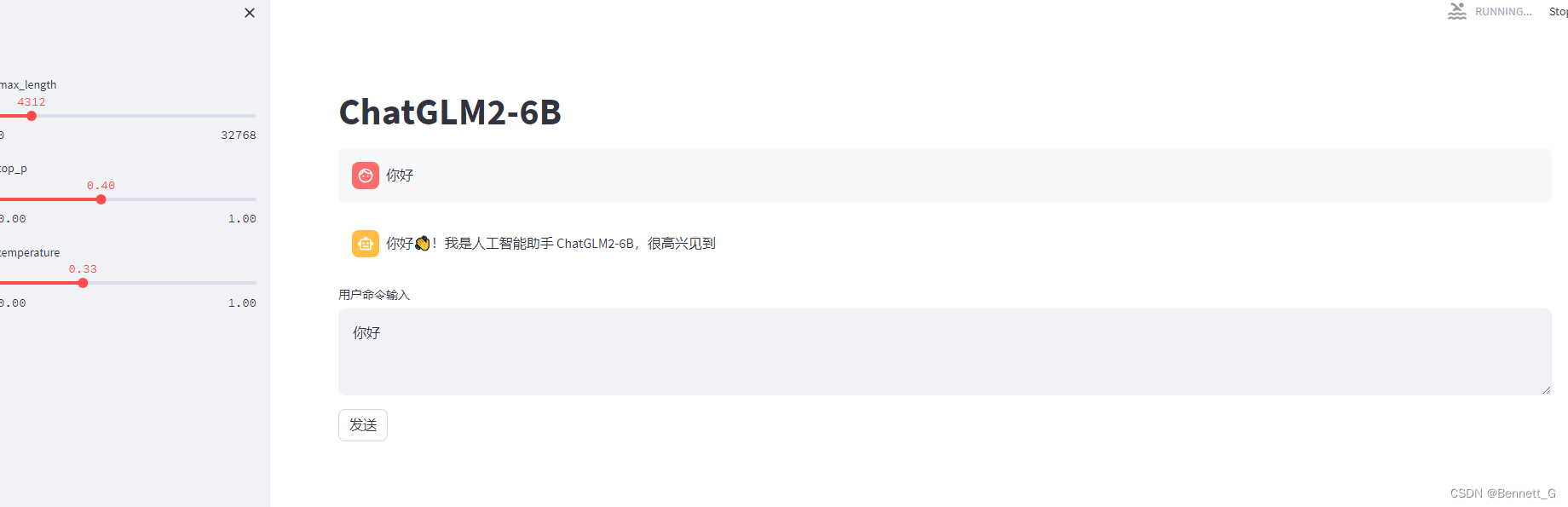
CLI模式
# 配置一致,调整cli_demo.py
# 启动
python cli_demo.py
# 命令行中输入只是并回车即可生成回复,输入clear:清空对话历史;输入stop:终止程序
- 1
- 2
- 3
- 4
API模式
# 安装fastapi uvicorn依赖
pip install fastapi uvicorn
# 配置api.py
python api.py
# 补充:可设置ip和端口
# api.py
...
uvicorn.run(app, host='x.x.x.x', port=8000, workers=1)
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
访问接口: http://x.x.x.x:8000/; 请求方式:POST

特别说明: 如果显存不足,可使用量化方式加载模型
# int4
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True).quantize(4).cuda()
# int8
model = AutoModel.from_pretrained("THUDM/chatglm2-6b", trust_remote_code=True).quantize(8).cuda()
- 1
- 2
- 3
- 4
解决问题
在部署过程中,可能会遇到一些问题。以下是一些常见问题和解决方法:
运行web_demo.py报错:AssertionError:Torch not compiled with CUDA enabled(torch和CUDA版本不匹配)
# 首先检查cuda能否使用
python -c "import torch; print(torch.cuda.is_availabled())"
# 返回False, 说明torch版本与CUDA不匹配
# 使用指令 nvidia-smi查看CUDA版本,然后到pytorch官方网站下载相应的CUDA安装
# 先卸载原torch
pip uninstall torch
# 安装指定CUDA版本的torch
pip install --pre torch --index-url https://download.pytorch.org/whl/nightly/cu121
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
gcc不是内部或外部命令
安装TDM-GCC,注意勾选 openmp 【TDM-GCC下载】
总结
通过按照以上步骤进行操作,您将能够成功在Windows 10上部署ChatGLM2-6B,从而掌握信息时代的智能对话能力。这将为您提供一个有趣而强大的工具,用于与ChatGLM2-6B进行智能对话,并深入了解自然语言处理的潜力。希望本文能帮助您充分利用信息时代的机遇,同时也能够解决可能出现的问题。

