
- 1am命令基本知识_am start
- 2ccfcsp201312-2 ISBN号码
- 3分享 GitHub 上的敏感词汇工具类:sensitive-word_sensitive word 开源
- 4MK+Sen趋势检验(长时间栅格数据)_遥感影像theil-sen趋势分析mk检验
- 5【BUG解决】vscode debug python launch.json添加args不起作用_launch.json args
- 6Java多线程面试题_java面试 多线程
- 7检测和解决 SQL Server 2000 SP 4 中的延迟和阻塞 I/O 问题_sql server has encomtered 3 ocurence of i/o reques
- 8【论文泛读】4. 机器翻译:Neural Machine Translation by Jointly Learning to Align and Translate_src_train_data和trg_train_data
- 9redis设置缓存时间一般多少_redis缓存涉及到商品时时间控制多久
- 10VM虚拟机 Linux网络配置(Center os 6.8)。_vm虚拟机 linux6.8更改网络配置
text to image(二):《Generative Adversarial Text to Image Synthesis》_generative adversarial text-to-image synthesis
赞
踩
继续介绍文本生成图像的工作,本文给出的是发表于ICML 2016的文章《Generative Adversarial Text to Image Synthesis》。这篇文章的源码是用torch写的,不是很熟悉,所以就不配合源码解析了.这篇博客主要是参考https://zhuanlan.zhihu.com/p/32326260给出的部分文章翻译,加一些自己的理解.
论文地址:https://arxiv.org/abs/1605.05396
源码地址:https://github.com/reedscot/icml2016
一、相关工作
续作《Learning What and Where to Draw》相关理解:https://blog.csdn.net/zlrai5895/article/details/81411273
对GAN的相关理解:https://blog.csdn.net/zlrai5895/article/details/80648898
二、基本思想及成果
将人工编写一句描述性文本直接转换成为图像(分辨率比较低 64*64)
需要注意的是,实验中在训练文本编码器的时候使用到了Caltech-UCSD Birds的标签(鸟的类别)。但是现实生活中大多图片(COCO数据集)不会给每张图片中的场景配一个标签。所以一方面该模型有一定的局限性,另一方面,生成的图像分辨率也比较低(64*64)
三、 数据集
本次实验使用的数据集是加利福尼亚理工学院鸟类数据库-2011(CUB_200_2011)。
四、模型结构:

1、文本编码器和图像编码器
我们通过优化下面这个损失来得到最终的sentence embedding。


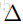
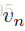

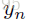
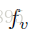
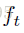

可以看到它们最终的输出是预测的标签。


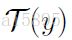

论文图像编码器用的是GoogLeNet,文本编码器用的是预训练好的hybrid character-level convolutional-recurrent neural network(char-CNN-RNN,来自《Learning Deep Representations of Fine-Grained Visual Descriptions》)。
2、生成器
由于是条件GAN,所以生成器的输入不止有随机采样的噪声z∼N(0,1),更有一个text feature(即图中蓝色部分)。这个text feature是由text encoder 生成的,如果text query为 t 则这个text feature就是
。
通常需要将描述文本使用一个全连接层压缩到一个较小维度之后(一般是128维),并使用leaky ReLU再与噪声向量z拼接在一起,作为生成器的整体的输入。
紧接着,后续的前向推断过程就是一个卷积网络:即一张合成的图片x̂ 通过x̂ ←G(z,ϕ(t))被生成出来。
3、鉴别器
判别器D。前面几层使用了stride-2卷积层并使用了leaky ReLU和spatial batch normalization。并且 仍然像以前一样使用一个全连接层接上一个rectifier来减少描述文本embedding
的维度。当判别器的维度是4×4时,将这个描述文本的embedding复制多份,并在深度上与图片进行拼接(如图中绿蓝相接部分)。然后在拼接之后的新tensor上继续执行一个1x1卷积然后进行纠正,然后4x4卷积再计算得分。整个卷积网络都有BN层。
4、 Matching-aware discriminator (GAN-CLS)
训练条件GAN的最直接的方法就是将图片和description embedding看作是联合的样本,通过观察判别器判断“生成的图片+文本”这个整体是真的还是假的。不过这个方法有些naive:并没有在训练中给判别器提供“是否按照描述正确生成了图像”的信息。
我们以鉴别器的视角来看,它的输入也是图片+text_embedding,那么可能是 真实的图片+配套的文本,或者真实的图片+不配套的文本,或者生成的图片+文本。因此需要分开记录这两种不同的错误来源:不真实的图片(配上任何文本),以及真实图片但条件信息匹配错误。
作者修改了GAN的训练算法来将这两种不同的错误分开。除了real/fake这两种输入以外,作者又增加了第三种输入“真实的图片配上错误的文本”,而判别器也必须要能把这种错误给区分出来。

5、Learning with manifold interpolation (GAN-INT)
对于根据描述去生成图片的问题,文本描述数量相对较少是限制合成效果(多样性)的一个重要因素。作者在不同的text_embedding( t1,t2)之间插值来生成大量新的文本描述。但是这些插值出来的结果并没有标签,
无法直接对应到人工文本标注上的,所以这一部分数据时不需要标注的。想要利用这些数据,只需要在生成器的目标函数上增加这样一项:
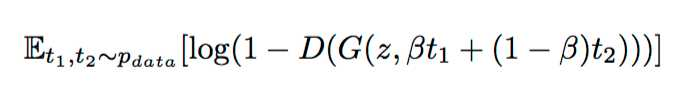
这个公式相当于综合考虑了两个text embedding t1和t2的插值点。通常在实际应用中使用β=0.5效果就不错了。
五、实验结果及其他
GAN和GAN-CLS生成的图像与文本内容比较接近,但是图片真实度不够。而GAN-INT和GAN-INT-CLS生成的图片虽然看上去更真实,但是可能只匹配部分文本信息。在花的数据集上的效果方法看上去效果都比较好,可能是因为对于D来说,鸟的结构比较强,更容易判断出假的图片。

