- 1python编程人工智能小例子,python人工智能100例子_用python进行人工智能小案例
- 2linux命令查看系统日期,Linux系统查看当前时间的命令
- 3CentOS 7安装Nginx
- 4码云(Gitee)创建SSH KEY以及查看用户名密码_码云查看账号密码
- 5【RocketMQ专题】快速实战及集群架构原理详解_rocketmq集群架构
- 6数据结构与算法 - 基础:LinkedHashMap
- 7Spring系列第25篇:@Value【用法、数据来源、动态刷新】_spring @value 动态改变值
- 8WiFi模块调试问题:AT+CIPSTART="TCP","192.168.43.212",8080 ERROR CLOSED_at cipstart="tcp","192.168.29.38",8080
- 9UDP主要丢包原因及具体问题分析_udp丢包
- 10yolo可视化——loss、Avg IOU、P-R、mAP、Recall (没有xml文件的情况)_yolo评估指标box loss200
一篇文章学会写SQL_sql语句怎么写
赞
踩
本篇文章主要讲如何写SQL,虽然我在之前有篇文章中写到过数据库的操作和概念,其中有讲到数据库和表的操作语句以及有哪些函数和查询关键字(本篇不赘述),但毕竟理解概念和会实践书写是两码事。。
身为一名测试人员,我在工作中用到最多的sql语句是查询即select,于是用多了就发现写select 远不止想的这么简单,在实际场景中我们最好是能根据不同的需求写出多样的select ,从而提高自己的工作效率,还只会用select * from merchant 语句的已经out了,我们应该学习更多的关键字哦~
1. sql中关键字的书写顺序
首先我们要知道SQL语句中的关键字是有固定顺序的,只有关键字的位置写对了,我们才能写出正确的sql。如下就是最常用select 语句:
select distinct(去重) 需查询的字段名或者函数 (查询展示全部字段可用*)
from 表名(这里的表名和前面的字段名 可以取别名使用)
left/right join 要连接查询的表名 on 连接条件的等值判断
where 子查询的字段过滤条件,不能包含聚合函数的条件
group by 分组的依据 having 分组后信息的过滤条件,可包含聚合函数的条件
order by 排序的字段 limit 限制展示行数
select语句书写及执行结果示例:
简单查询语句:
#查询merchant表并展示全部字段
select * from merchant;
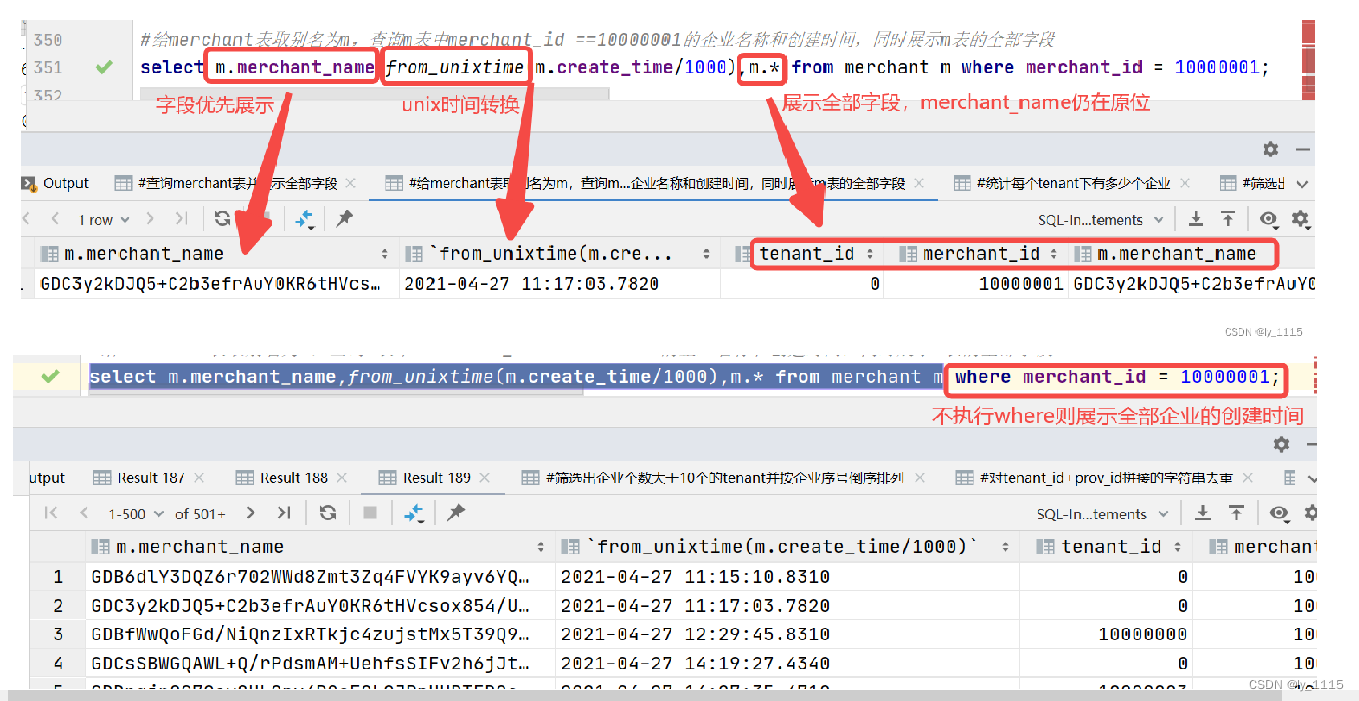
#给merchant表取别名为m,查询m表中merchant_id ==10000001的企业名称和创建时间,同时展示m表的全部字段
select m.merchant_name,from_unixtime(m.create_time/1000),m.* from merchant m where merchant_id = 10000001;
- 1
- 2
- 3
- 4
- 5
使用聚合函数和group by + hanving (后文有讲聚合函数和分组查询
#统计每个tenant下有多少个企业
select tenant_id,count(merchant_id) from merchant group by tenant_id;
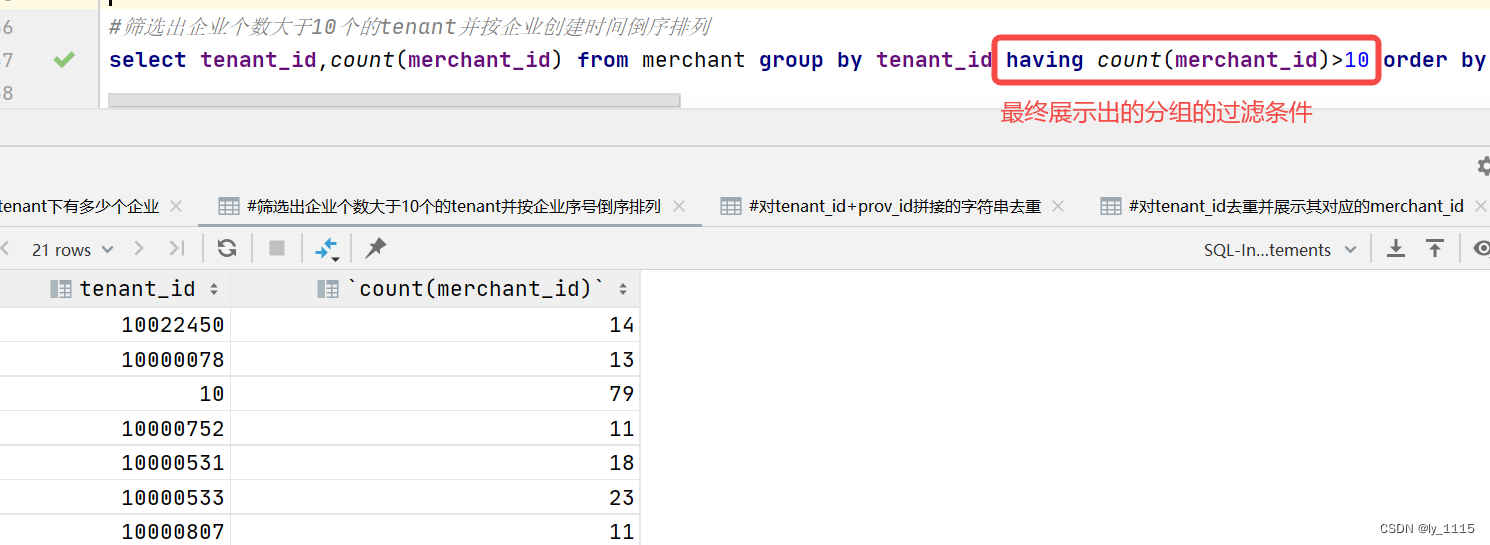
#筛选出企业个数大于10个的tenant并按企业创建时间倒序排列
select tenant_id,count(merchant_id) from merchant group by tenant_id having count(merchant_id)>10 order by create_time desc;
- 1
- 2
- 3
- 4
- 5
使用distinct去重((后文有讲去重查询
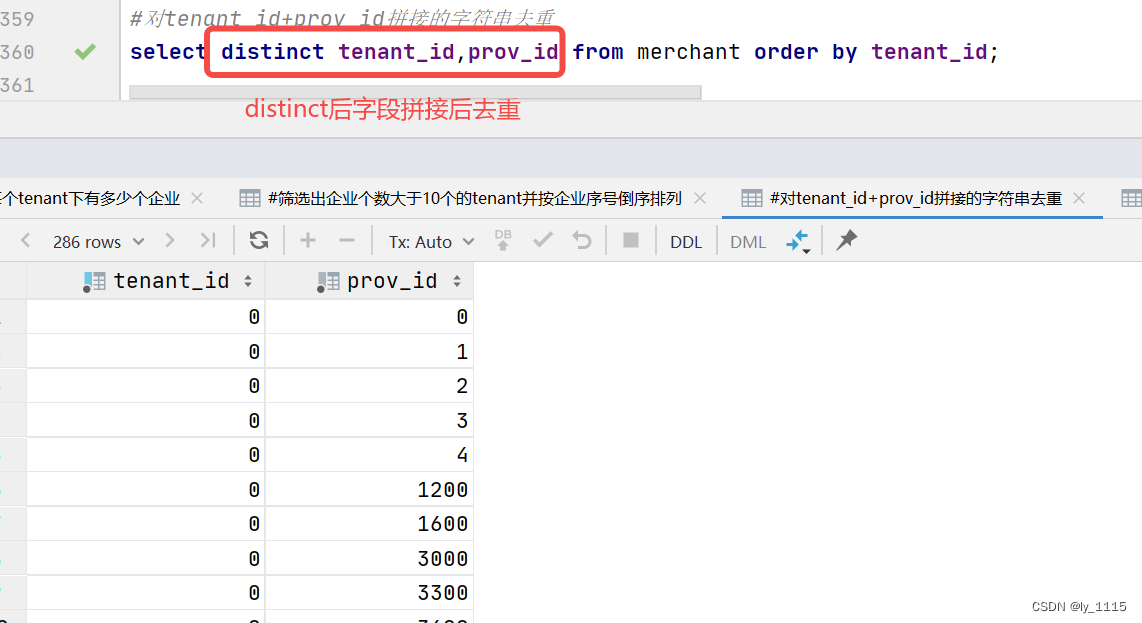
#对tenant_id+prov_id拼接的字符串去重
select distinct tenant_id,prov_id from merchant order by tenant_id;
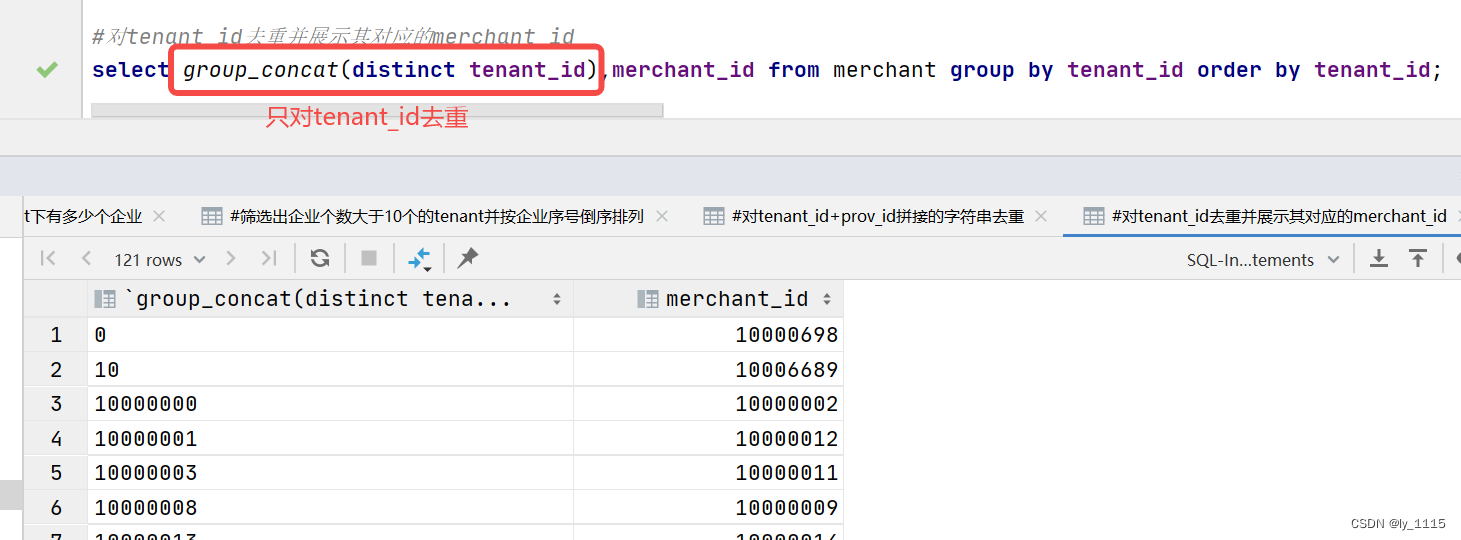
#对tenant_id去重并展示其对应的merchant_id
select group_concat(distinct tenant_id),merchant_id from merchant group by tenant_id order by tenant_id;
- 1
- 2
- 3
- 4
- 5
我相信记住了select语句中使用的上述关键字的顺序和用法,大家都能很顺利的写出符合心意的sql语句啦,赶快自己试着写起来吧~
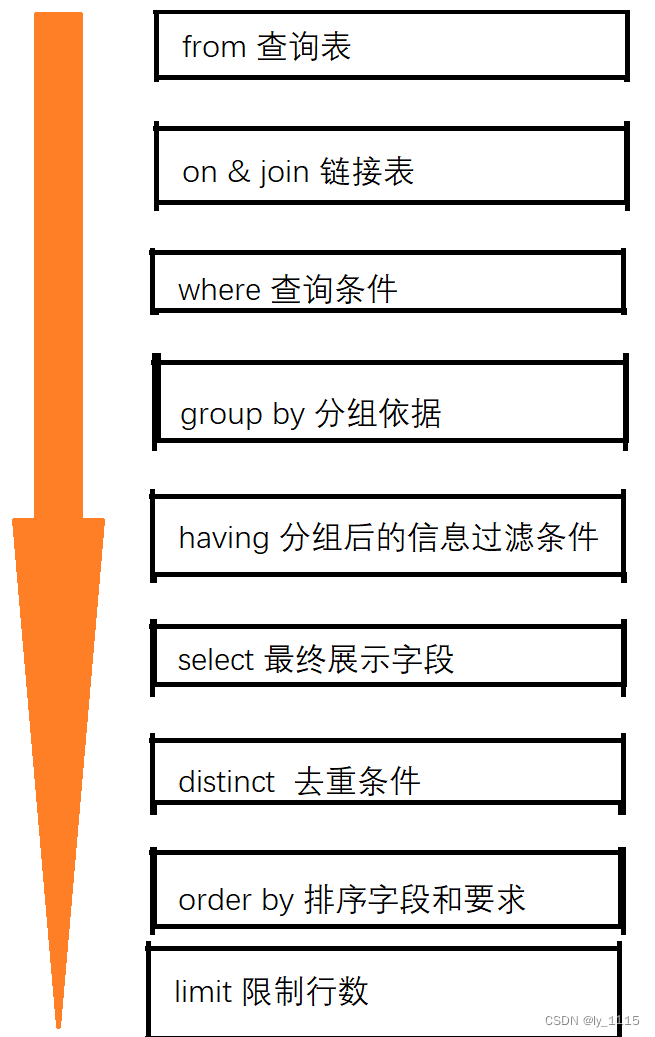
2. sql中关键字的执行顺序
我们知道sql中关键字的书写顺序,我们还需清楚sql中关键字的执行顺序,才能更好的理解sql的使用。如下是执行顺序:
3. sql中的聚合函数
聚合函数概念:函数作用于一组数据,并返回一个值。
3.1 AVG 和 SUM :适用于数值类型
例如:select avg(salary),sum(salary)*2 from employees;
3.2 MIN 和 MAX :适用于数值型,字符串型,日期时间类型
例如:select min(salary),max(hire_date) from employees;
3.3 COUNT :用于统计个数或者行数
例如:select count(id) from employees;
- 注意:统计总数的方法总共有三种,其中count(*) 和 count(1) 都可以正确的统计总条数,但count(字段名)统计的总数可能有误差,因为在count(字段名)在统计时不计算NULL值。
3.4 搭配聚合函数使用的关键字
group by:
其中select子句中的字段必须来自group by 后的分组字段。
例如:
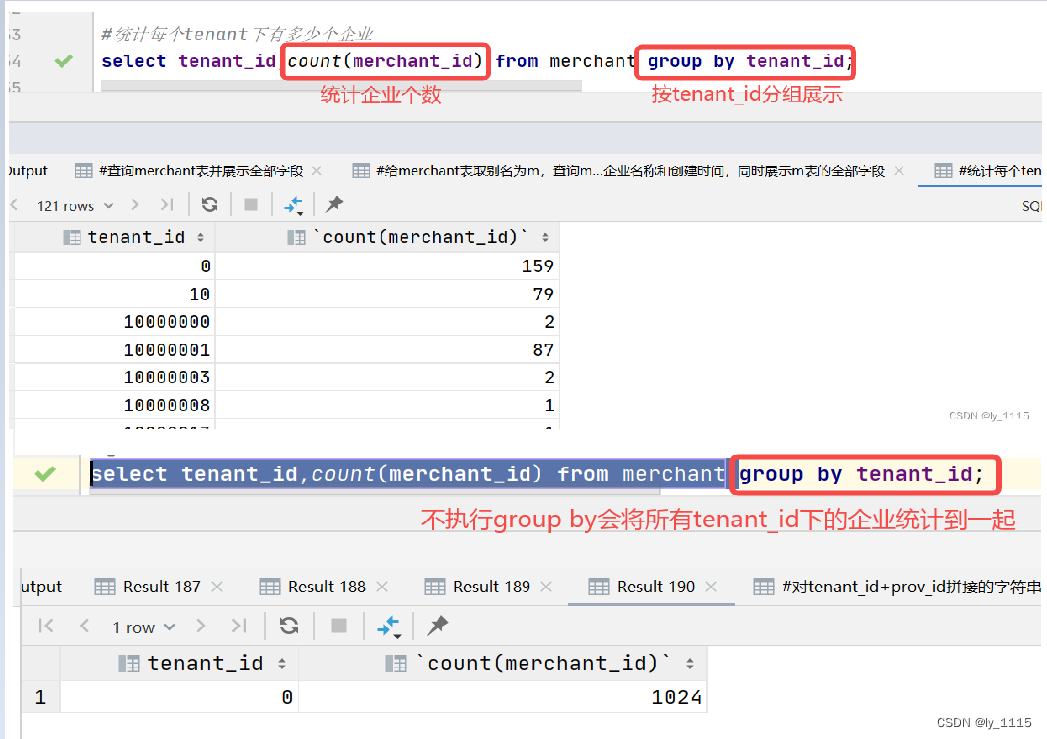
#统计每个tenant下有多少个企业
select tenant_id,count(merchant_id) from merchant group by tenant_id;
having:
只能声明在group by的后面,且having的字段/函数来源于select子句中。
例如:
筛选出企业个数大于10个的tenant并按企业创建时间倒序排列
select tenant_id,count(merchant_id) from merchant group by tenant_id having count(merchant_id)>10 order by create_time desc;
4. sql中三种去重查询方法
去重查询顾名思义就是指在查询结果中不展示重复的数据项,对原有数据未做任何删除哦。
4.1 distinct关键字
- 注意:distinct关键字只能用在SELECT 语句中,且必须写在查询语句第一个参数的位置。
- 用法一:如果distinct后面只有一个字段,则只对该字段去重,并展示这个字段下不重复的所有值;如果distinct后面有多个字段,则会对多个字段拼接后的字符串进行去重,展示多个字段组合后不重复的所有值(即多个字段的关系是&&(逻辑与)关系,当只看某一字段时仍可能有重复的值)。
例如:
select distinct tenant_id,prov_id from merchant order by tenant_id;
select id,distinct tenant_id from merchant order by tenant_id; //distinct位置书写错误
- 用法二:如果查询需要展示多个字段,但只想对其中一个字段去重,则可通过
group_concat(distinct 字段名)实现只对括号的distinct里的字段进行去重处理。
例如:
select group_concat(distinct tenant_id),merchant_id from merchant group by tenant_id order by tenant_id;
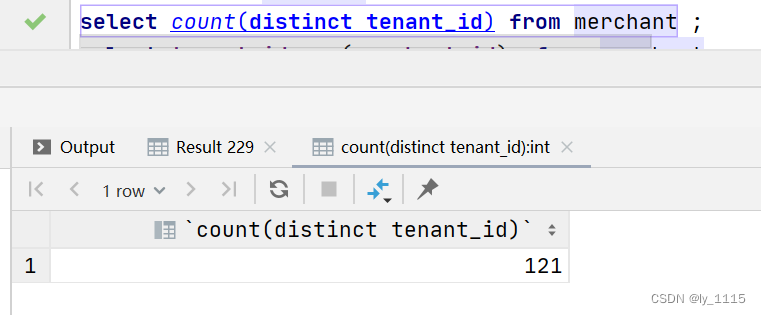
- 用法三:配合count使用,可以统计去重后的条数。
例如:
select count(distinct tenant_id) from merchant ;
- 用法四:与order by一起用时,排序依据的字段最好在distinct中。
例如:
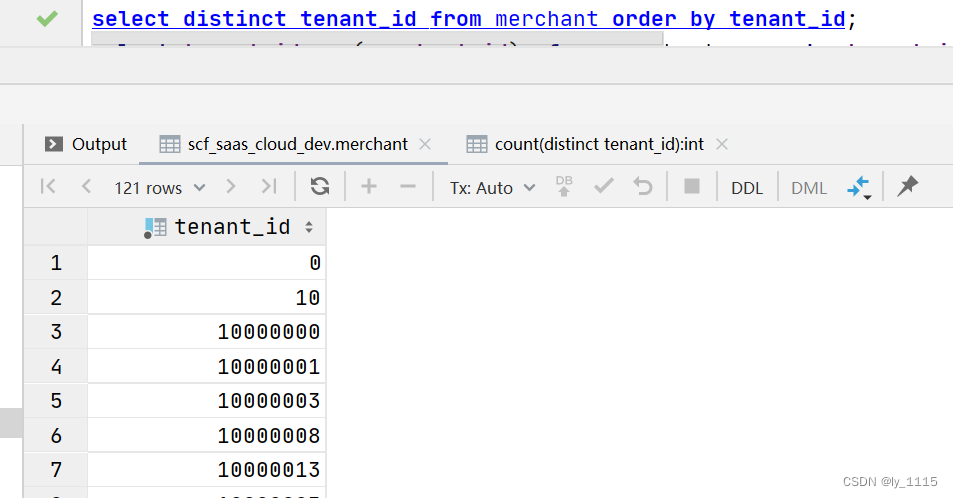
select distinct tenant_id from merchant order by tenant_id;
select tenant_id from merchant order by tenant_id; //错误写法,tenant_id未去重,无法依据该字段进行排序
若不使用Distinct关键字,则order by后面的字段不需要放在seletc中
例如:select * from merchant order by tenant_id;
4.2 group by 去重
- 注意项:group by实际是根据一个或多个列对结果集进行分组,从而实现相同的字段值最终只显示一个(未分组的字段只显示分组中的第一行)。
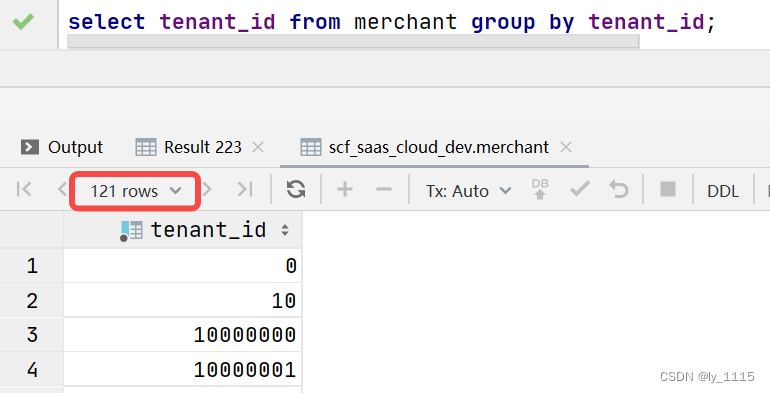
- 用法一:根据某个字段进行分组。
例如:
select tenant_id from merchant group by tenant_id; //只有tenant_id 一列,字段值为不重复的tenant_id
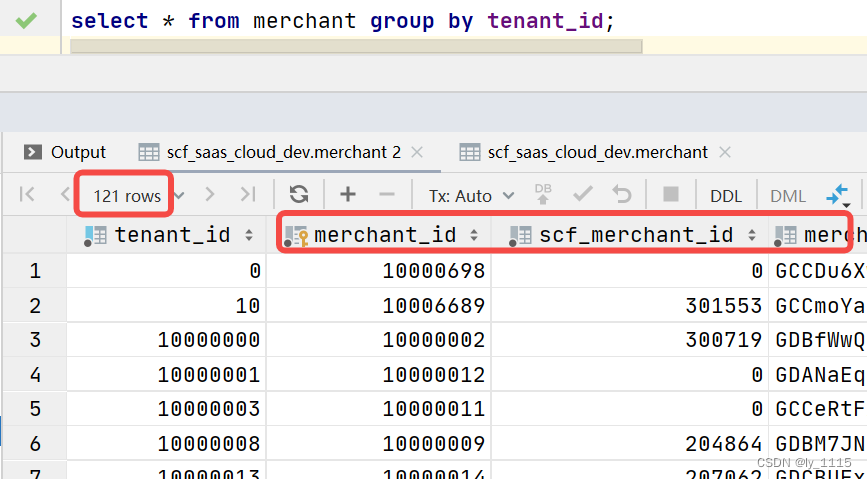
select * from merchant group by tenant_id; //展示有多列时,tenant_id字段值不重复,其他字段值只显示分组中的第一行
以上两条语句,无论最终展示几个字段,但查询结果的条数是相同的
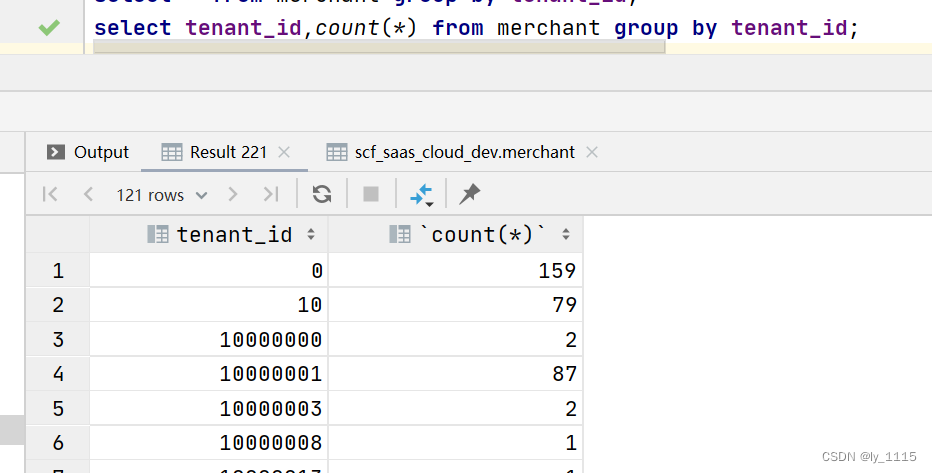
- 用法二:配合count使用,可以统计重复字段值的条数。
例如:
select tenant_id,count(*) from merchant group by tenant_id; //重复的tenant_id数目
- 用法三:可以与 COUNT, SUM, AVG等聚合函数一起使用。
例如:
select tenant_id,min(merchant_id) from merchant group by tenant_id; //显示每个tenant_id下最小的merchant_id
select tenant_id,max(merchant_id) from merchant group by tenant_id; //与上面的tenant_id相同但merchant_id更大
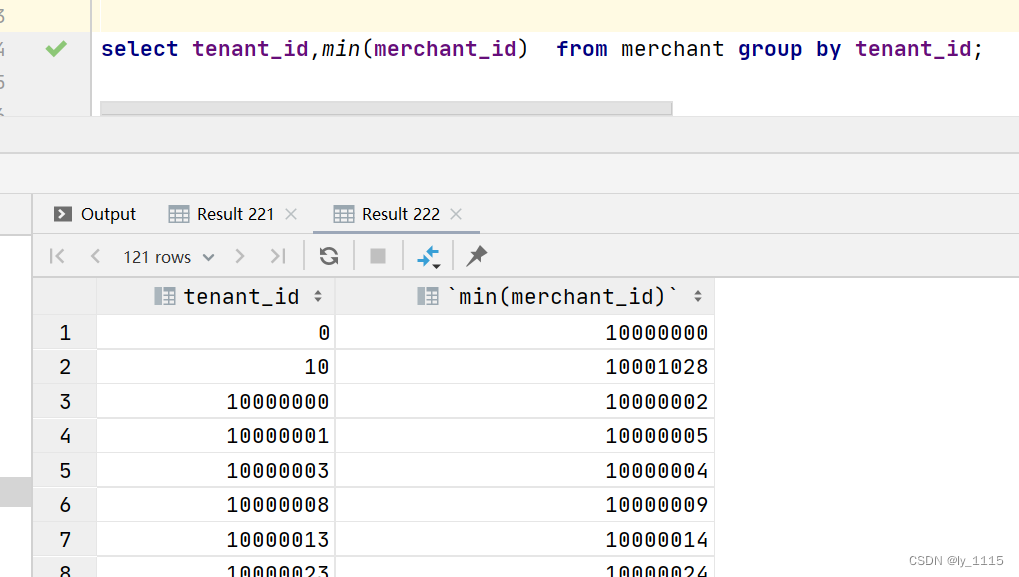
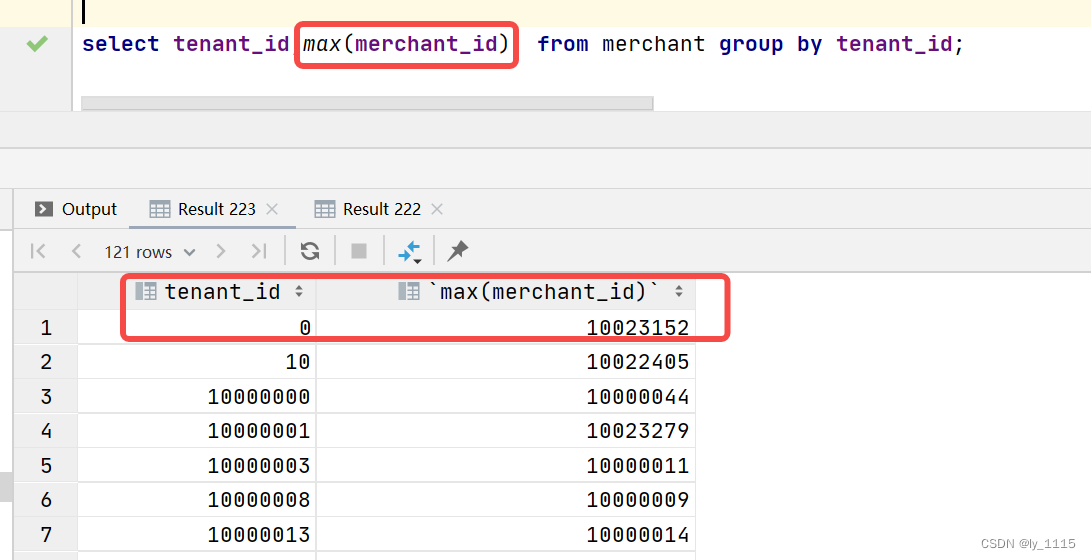
4.3 row_number() over (parttion by 分组列 order by 排序列)
- 去重原理:先根据重复列进行分组,分组后再进行排序,不同的组序号为1,相同的组序号为2,排除为2的就达到了去重效果。
5. join+on 连表查询
连表查询的关键字 join对使用过数据库的人来说应该很熟悉了,但是大多数人并不能熟练的使用。这里我就介绍一下join操作(必须有on)。
首先 我们知道 join的分类有很多,但我们常用的只有以下4类。下面我将对挨个进行详解。
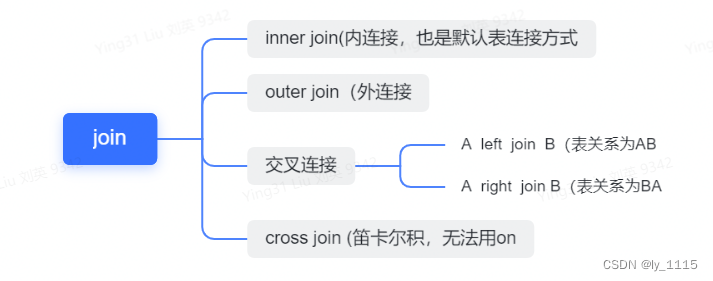
5.1 INNER JOIN -内连接
inner join即内连接的inner可以省略,因为这是数据库使用join时默认的表连接方式。
该方式连接的两张表,通过on等值判断后取两表的交集;所以我们在使用该方式时,最好保证两表的值都对应存在。
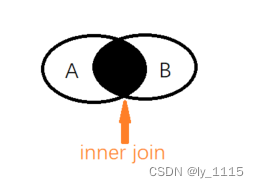
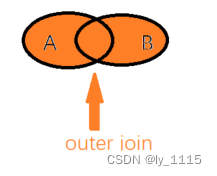
5.2 OUTER JOIN -外连接
outer join是外连接,使用时outer必须写。
该方式连接的两张表,通过on等值判断后取两表的并集;若附表中无主表需要的字段值时,默认填写null。
5.3 交叉连接
交叉连接又分为left join 和 right join,下面分别介绍。
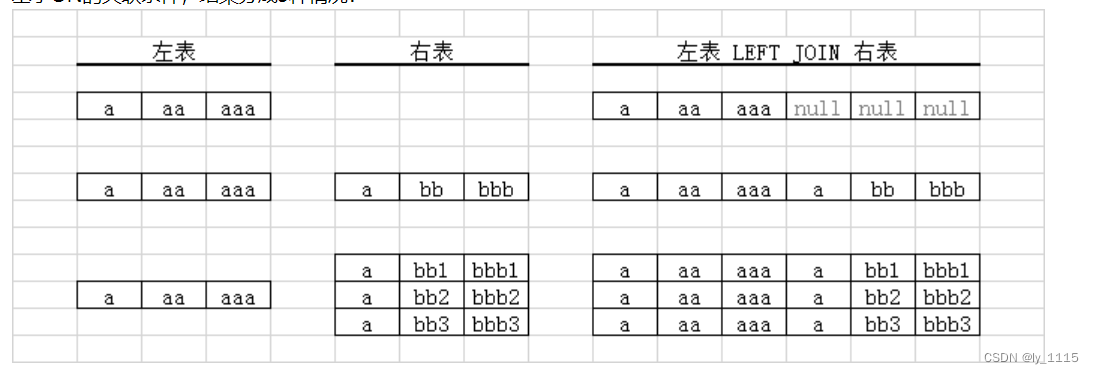
LEFT JOIN
A left join B是左连接,即将A连在B表的左边。
该方式连接的两张表,通过on等值判断后,取A表全部值并将B表的值对应补充上;若B表中无对应值默认填写null。
RIGHT JOIN
A right join B是右连接,即将A连在B表的右边。
该方式连接的两张表,通过on等值判断后,取B表全部值并将A表的值对应补充上;若A表中无对应值默认填写null。
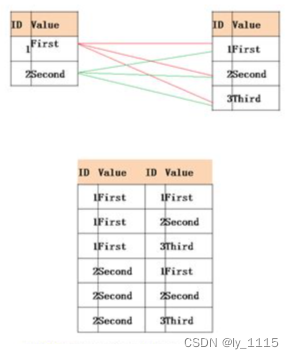
left join使用示例 -共三种场景:
5.4 CROSS JOIN - 笛卡尔积连接
cross joincross join 连接方式,不需要任何连接条件故无需也不能用on。
这种方式会把两个表的的数据进行笛卡尔积操作。如图