
- 1项目经理所应具备的八项素质:_项目经理基本安全素养八个必须
- 2传统行业的it程序员_传统行业 程序员
- 3最长子字符串的长度(一)【华为OD机试JAVA&Python&C++&JS题解】_华为od机试 - 最长子字符串的长度(一)(java & js & python & c & c++
- 4数据挖掘算法与现实生活中的应用案例
- 5【一次性看懂fastqc和multiqc的运行代码】输出成功的结果判定、常见报错大赏_multiqc报错了如何解决
- 600 【哈工大_操作系统】Bochs 汇编级调试方法及指令
- 7在mac上安装好python开发环境(pyenv、pyenv-virtualenv、docker-desktop、mysql5.7),一文解决环境问题
- 8unity基础(五)地形详解_unity创建地形山草树水房子
- 9Android视频开发进阶-关于视频的那些术语,美团架构师深入讲解Android开发
- 10调用大模型api返回输出结果--LLM
综述阅读:A guide to deep learning in healthcare_a guide to deep learning in healthcare.
赞
踩
综述阅读:A guide to deep learning in healthcare
来源:2019 nature medicine
下载地址:https://www.researchgate.net/publication/330203264_A_guide_to_deep_learning_in_healthcare
Abstract
在这里,我们将介绍用于医疗保健的深度学习技术,重点讨论计算机视觉、自然语言处理(only)、强化学习和通用方法中的深度学习。 我们描述了这些计算技术如何影响医学的几个关键领域,并探索如何构建端到端系统。 我们对计算机视觉的讨论主要集中在医学成像上,我们描述了自然语言处理在电子健康记录数据等领域的应用。 同样,在机器人辅助手术的背景下讨论了强化学习,并回顾了基因组学的通用深度学习方法。
Computer Vision
略
Natural Language Processing
自然语言处理 (NLP) 侧重于分析文本和语音以从单词中推断含义。 递归神经网络 (RNN)(现在Transformer?)——有效处理顺序输入(如语言、语音和时间序列数据)的深度学习算法——在该领域发挥着重要作用。NLP 的显着成功包括机器翻译、文本生成和图像字幕。在医疗保健领域,序列深度学习和语言技术为电子健康记录 (EHR) 等领域的应用提供动力。
EHR 正迅速变得无处不在。 大型医疗机构的 EHR 可以在十年内记录超过 1000 万患者的医疗交易。 仅一次住院治疗通常会产生约 150,000 条数据。从这些数据中获得的潜在好处是巨大的。 总的来说,这种规模的 EHR 代表了 20 万年的医生智慧和 1 亿年的患者结果数据,涵盖了大量罕见的疾病。 因此,将深度学习方法应用于 EHR 数据是一个快速扩展的领域。
图 3 概述了为 EHR 构建深度学习系统的技术步骤。 首先跨机构汇总原始数据,以确保建立一个通用的系统。然后对数据进行标准化,并在时间和患者之间进行解析,这使得它们适合深度学习训练。由此,我们可以推断出高级医学问题的答案,例如“过去的病史与患者当前的诊断相关吗?”、“患者当前的问题列表是什么?”、“有哪些机会进行干预?“
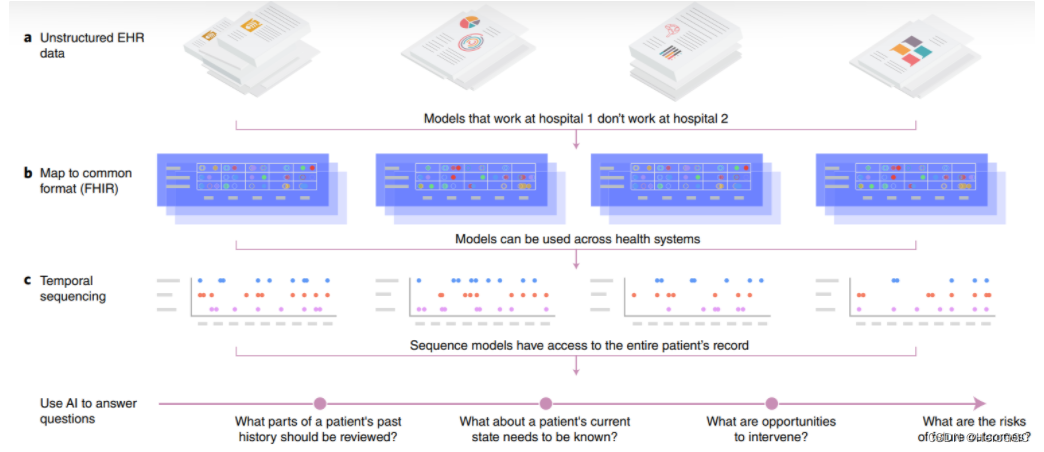
图 3 | 使用 EHR 进行预测。 a,非结构化 EHR 数据。 医疗记录以特殊的数据结构和格式存储,因此基于给定医院记录构建的模型不一定适用于来自不同医院的数据。 b,数据标准化。 通过将来自多个站点的数据映射到基于 FHIR 的单一格式,数据被标准化为同质格式。 c,测序。 通过将所有数据按时间排序到患者时间线中,基于时间的深度学习技术可以应用于整个 EHR 数据集,以对单个患者进行预测。
在进行预测时,迄今为止,大多数工作都对有限的结构化数据集使用监督学习,包括实验室结果、生命体征、诊断代码和人口统计数据。 为了解释 EHR 中包含的结构化和非结构化数据,研究人员开始采用无监督学习方法,例如自动编码器——首先训练网络通过压缩然后重建未标记的数据来学习有用的表示——来预测特定的诊断。 最近使用深度学习模型使用卷积和循环神经网络对患者记录中发生的结构化事件的时间序列进行建模,以预测未来的医疗事件。 这项工作的大部分集中在重症监护医学信息 (MIMIC) 数据集(例如,用于预测败血症),其中包含来自单个中心的重症监护病房 (ICU) 患者。 虽然 ICU 患者比非 ICU 患者产生更多的 EHR 数据,但他们的数量明显高于非 ICU 患者。 因此,仍然不确定从这些数据得出的技术将如何推广到更广泛的人群。
下一代自动语音识别和信息提取模型可能会开发临床语音助手来准确转录患者就诊。 医生很容易在 11 小时的工作日中花费 6 小时来处理 EHR 中的文档,这会导致倦怠并减少与患者相处的时间。 自动转录将缓解这种情况并促进更好的转录服务。 考虑基于 RNN 的语言翻译,它使用端到端技术将一种语言的语音直接翻译成另一种语言的文本。 该技术适用于 EHR,可以将患者与提供者的对话直接翻译成转录的文本记录。 关键挑战在于从对话中对每个医疗实体的属性和状态进行分类,同时准确地总结对话。 尽管在早期的人机交互实验中很有前景,但这些技术尚未广泛应用于医疗实践。
未来的工作可能会集中在开发算法上,以更好地利用 EHR 中一些信息丰富但非结构化的数据。 例如,在开发预测系统时,临床记录经常被省略或编辑。 在这里,大规模 RNN 开始通过以半监督方式结合结构化和非结构化数据来展示令人印象深刻的预测结果。这种数据组合使他们能够从更广泛的人群中学习更多样化的数据类型,在包括死亡率、再入院、住院时间和诊断预测在内的任务中优于其他技术。
Reinforcement Learning
略
Generalized Deep Learning
略

