
热门标签
热门文章
- 1利用JavaScript重构数组的unshift方法 实现底层逻辑_js中unshift底层函数
- 2DBSyncer安装_配置postgresql和mysql_sqlserver_oracel全量增量同步---数据全量增量同步之DBSyncer001
- 3SQL Server 2005性能排错白皮书(Part 1)---From MS Customer Support Service部门 _a time out occurred while waiting to optimize the
- 4Windows端部署Stable Diffusion完整教程
- 5引出抽象类的原因是什么???_抽象类存在的理由试什么
- 6接受广播BroadcastReceiver_广播实质上是一个intent对象,接受广播实际上就是接受什么对象?
- 7linux安装jdk11_jdk11.tar.gz
- 8Springcloud基础运用流程_spring cloud使用流程
- 9C/C++中静态全局变量与静态局部变量_c++ 静态变量可以是全局也可以是局部
- 10Embedding理解、Keras实现Embedding_keras embedding
当前位置: article > 正文
集群小文件太多问题(spark-sql优化)_conf spark.sql.shuffle.partitions=10。
作者:不正经 | 2024-04-23 15:27:22
赞
踩
conf spark.sql.shuffle.partitions=10。
hive外部分区表,每个分区下有200个小文件

某张表有三个分区字段(partition_brand, partition_date, partition_rssc)
则生成小文件个数:2 * 26 * 8 * 200 = 83,200
这个表还算一般,如果按照年月日进行分区的话,小文件就太多了
先查看集群动态资源配置:

再查看执行spark程序配置资源:
--driver-memory 30g \
--executor-memory 12g \
--num-executors 12 \
--executor-cores 3 \
- 1
- 2
- 3
- 4
12executor3个core =36 cores
12executor12 + 30 =174G
然而是实际运行过程
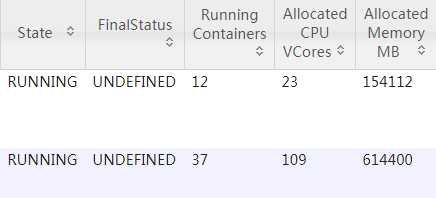
看来是集群动态分配资源,然而分配资源对生成文件数并没影响。。
最终发现默认文件生成数和表文件存储的个数有关,但是上游表存储个数不是我们下游能控制的,只能自己想办法处理小文件了
方法一:新增配置信息:
--conf spark.sql.shuffle.partitions=10 \
--conf spark.default.parallelism=10 \
- 1
- 2

执行结果ok,但是运行时间增加了10min.

方法二:repartition函数
//合并成一个文件
df.repartition(10).createOrReplaceTempView("table1")
hiveContext.sql("INSERT overwrite TABLE wd_part_test partition(partition_brand, partition_date, partition_rssc) select * from table1")
- 1
- 2
- 3
执行结果ok,同样运行时间增加了10min。
最后深入分析之后,采用distribute by方式:
INSERT overwrite TABLE asmp.wd_part_test partition(partition_brand, partition_date)
select
c.rssc_code,
c.rssc_name,
b.sst_code,
b.sst_name,
b.sst_code p1,
regexp_replace(substr(te.fkdat,1,7), '-', '') p2
from tt_part_test
distribute by p1,p2
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
执行结果ok,同样运行时间几乎没有增加。
注:
(1)测试采用一年的数据量大约50G(1亿条)
(2)distribute by 控制map输出结果的分发,相同字段的map输出会发到一个reduce节点去处理;sort by为每一个reducer产生一个排序文件。cluster by = distribute by + sort by,默认只能是升序。
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/不正经/article/detail/474615
推荐阅读

相关标签

