
热门标签
热门文章
- 1cocoapods导入三方库头文件找不到问题
- 2git远程仓库的创建(养成好的习惯,小马教你提交代码到远程仓库中)_git创建远程仓库
- 3十种预兆程序员被解雇的迹象
- 4微信小程序开发之原生小程序开发和uniapp开发的区别,两种开发方式语法上的区别_uniapp微信小程序和原生小程序区别
- 5k8s的网络优化(metallb)_metallb二层网络(1)
- 6STM32+OLED屏多级菜单显示(三)_stm32 oled菜单
- 7实用技巧:Linux上实现OpenGauss数据库远程连接,方便的跨网络数据操作_opengauss 远程连接
- 8华为S2700-9TP-EI-AC SSH登录错误处理_华为 s2700 ssh invalid ket length
- 9Sentence-Transformer的使用及fine-tune教程_distiluse-base-multilingual-cased
- 10centos7安装并启动多实例mysql数据库_centos mysql 多实例
当前位置: article > 正文
Embedding理解、Keras实现Embedding_keras embedding
作者:我家自动化 | 2024-04-24 16:39:59
赞
踩
keras embedding
@创建于:20210714
@修改于:20210714
1 Embedding介绍
Embedding 是一个将离散变量转为连续向量表示的一个方式。在神经网络中,embedding 是非常有用的,因为它不光可以减少离散变量的空间维数,同时还可以有意义的表示该变量。
1.1 embedding 有3 个主要目的
- 在 embedding 空间中查找最近邻,这可以很好的用于根据用户的兴趣来进行推荐。
- 作为监督性学习任务的输入。
- 用于可视化不同离散变量之间的关系。
1.2 图形化解释
one-hot 是无法考虑语义间的相互关系的,但embedding向量的训练是要借助one-hot的。one-hot把每一个单词映射成一个整数,但实际上这个整数就表示了50维向量中 1 所在的索引位置,用整数显示是为了更好理解和表示,而实际在网络中,它的形式可以理解为如下图(下面相当于one-hot向量为5维,输出embedding向量为3维)
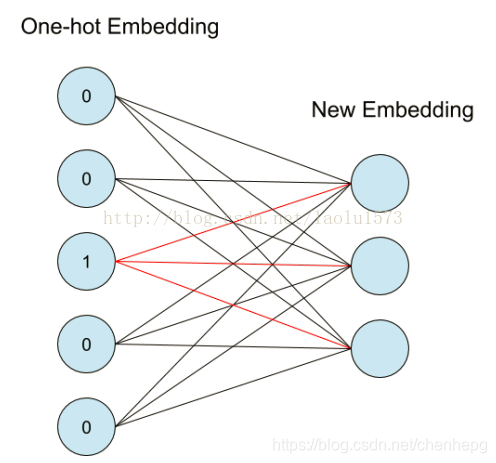
左边的神经元为one-hot输入,右边为得到的embedding表示,图中所对应的红线权重就是该单词对应的词向量,这一层神经元只能作为第一层嵌入,没有偏置和激活函数。它也可以被理解为如下的一个矩阵相乘,输出就是该单词的词向量。然后词向量再输入到下一层。这一层总的参数量就是这些权重,也是下面中间的矩阵。

2 包模块、方法介绍
包模块及方法如下,作用是将正整数(索引值)转换为固定尺寸的稠密向量。 例如: [[4], [20]] -> [[0.25, 0.1], [0.6, -0.2]]
该层只能用作模型中的第一层。ref:Docs » Layers » 嵌入层 Embedding
from tensorflow.keras.layers import Embedding
keras.layers.Embedding(input_dim, output_dim, embeddings_initializer='uniform', embeddings_regularizer=None, activity_regularizer=None, embeddings_constraint=None, mask_zero=False, input_length=None)
- 1
- 2
- 3
参数解释如下
input_dim: int > 0。词汇表大小,词汇表的维度(总共有多少个不相同的词)。 即最大整数 index + 1。
output_dim: int >= 0。词向量的维度(嵌入词空间的维度)。
embeddings_initializer: embeddings 矩阵的初始化方法 (详见 initializers)。
embeddings_regularizer: embeddings matrix 的正则化方法 (详见 regularizer)。
embeddings_constraint: embeddings matrix 的约束函数 (详见 constraints)。
mask_zero: 是否把 0 看作为一个应该被遮蔽的特殊的 "padding" 值。
这对于可变长的 循环神经网络层 十分有用。
如果设定为 True,那么接下来的所有层都必须支持 masking,否则就会抛出异常。
如果 mask_zero 为 True,作为结果,索引 0 就不能被用于词汇表中
(input_dim 应该与 vocabulary + 1 大小相同)。
input_length: 输入序列的长度(输入语句的长度)。
如果你需要连接Flatten 和 Dense 层,则这个参数是必须的
(没有它,dense 层的输出尺寸就无法计算)。
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
3 Keras实现Embedding
from tensorflow.keras.layers import Dense, Flatten, Input from tensorflow.keras.layers import Embedding from tensorflow.keras.models import Model, Sequential from tensorflow.keras.preprocessing.sequence import pad_sequences from tensorflow.keras.preprocessing.text import one_hot import numpy as np # define documents docs = ['Well done!', 'Good work', 'Great effort', 'nice work', 'Excellent!', 'Weak', 'Poor effort!', 'not good', 'poor work', 'Could have done better.'] # define class labels labels = np.array([1, 1, 1, 1, 1, 0, 0, 0, 0, 0]) # integer encode the documents vocab_size = 50 # one_hot编码到[1,n],不包括0 encoded_docs = [one_hot(d, vocab_size) for d in docs] print(encoded_docs) # pad documents to a max length of 4 words max_length = 4 padded_docs = pad_sequences(encoded_docs, maxlen=max_length, padding='post') print(padded_docs) # define the model model = Sequential() # 这一步对应的参数量为50*8 model.add(Embedding(input_dim=vocab_size, output_dim=8, input_length=max_length, input_shape=(4, ))) model.add(Flatten()) model.add(Dense(1, activation='sigmoid')) # compile the model model.compile(optimizer='adam', loss='binary_crossentropy', metrics=['acc']) # summarize the model print(model.summary()) # fit the model model.fit(padded_docs, labels, epochs=100, verbose=0) # evaluate the model loss, accuracy = model.evaluate(padded_docs, labels, verbose=0) # loss_test, accuracy_test = model.evaluate(padded_docs, labels, verbose=0) print('Accuracy: %f' % (accuracy * 100)) # test the model test_doc = 'good thing' encoded_test = [one_hot(test_doc, vocab_size)] padded_test = pad_sequences(encoded_test, maxlen=max_length, padding='post') print(padded_test) label_test = model.predict(padded_test) print(label_test)

- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
输出结果
[[49, 15], [43, 6], [34, 44], [14, 6], [14], [8], [21, 44], [5, 43], [21, 6], [23, 35, 15, 47]] [[49 15 0 0] [43 6 0 0] [34 44 0 0] [14 6 0 0] [14 0 0 0] [ 8 0 0 0] [21 44 0 0] [ 5 43 0 0] [21 6 0 0] [23 35 15 47]] Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param # ================================================================= embedding (Embedding) (None, 4, 8) 400 _________________________________________________________________ flatten (Flatten) (None, 32) 0 _________________________________________________________________ dense (Dense) (None, 1) 33 ================================================================= Total params: 433 Trainable params: 433 Non-trainable params: 0 _________________________________________________________________ None 2021-07-14 13:56:11.459951: I tensorflow/compiler/mlir/mlir_graph_optimization_pass.cc:176] None of the MLIR Optimization Passes are enabled (registered 2) Accuracy: 89.999998 [[43 5 0 0]] [[0.61304027]]
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
4 参考链接
Embedding理解与代码实现 !对原文代码有改动
声明:本文内容由网友自发贡献,不代表【wpsshop博客】立场,版权归原作者所有,本站不承担相应法律责任。如您发现有侵权的内容,请联系我们。转载请注明出处:https://www.wpsshop.cn/w/我家自动化/article/detail/480483
推荐阅读
相关标签

